无状态性:基于键值对的见证数据方案
- EthFans
- 发布于 2021-01-22 12:07
- 阅读 4593
键值对见证数据(KV witness)是什么样的,与当前被提议的、基于操作码的见证数据格式有何区别? 键值对见证数据与操作码见证数据相比,有什么优点和缺点? 从网络带宽的角度看,键值对见证数据方案的效率如何?
无状态以太坊运动当前提议了一种区块见证数据(witness)的格式,详述见此处。这套区块见证方案是基于操作码(opcode)的,你可以理解为一种小型的编程语言,可以使用少数几个命令来生成 “默克尔多值证明” (中文译本)。
本文研究了另一种区块见证数据的建构方法,它基于一个键值对的列表,语义也更简单。
在本文中我将尝试回答下列问题:
- 键值对见证数据(KV witness)是什么样的,与当前被提议的、基于操作码的见证数据格式有何区别?
- 键值对见证数据与操作码见证数据相比,有什么优点和缺点?
- 从网络带宽的角度看,键值对见证数据方案的效率如何?
(见证数据方案需满足的)前提
所有的区块见证数据方案都必须满足下列要求:
- 正确(correctness)。保证节点可以执行来自以太坊主网的任意区块。
- 效率(efficiency)。转移见证数据所需花费的网络带宽尽可能小。
- 默克尔化(Merkelization)。必须支持合约代码默克尔化(中文译本)。
- 无视状态树的格式(Arity-agnostic)。既支持十六进制默克尔树,也支持二进制默克尔树(中文译本)。
语义
这一部分我先讲讲键值对见证格式的语义,还不会谈到具体的数据布局(byte layout)。
后面,我再讲解我用在测试中的数据格式。
witness ::= header, body, proofs
header ::= version : byte, trie_arity : byte
body ::= array of [ { type: byte key : []byte, value : []byte } ]
proofs ::= map { <type>: [ { prefix : []byte, hash : []byte } ] }见证数据 数据体
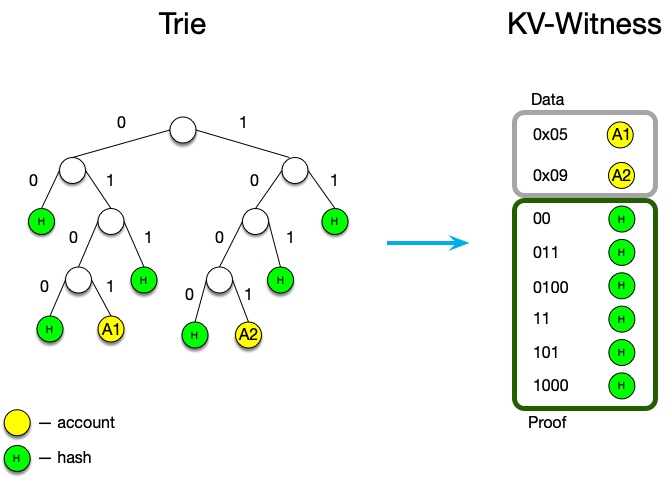
见证数据的数据体由两个元素构成:
- 数据
“键”(key)可以是:账户的地址,storage key 或者 code key;而 “值”(value)可以是:账户、storage item 或者相应的代码分块(code chunk)。这一部分的数据体与用于验证正确性的默克尔树的格式完全无关。而且,即使用其它方式来验证正确性,这一部分也不会改变。
- 证据。
键是默克尔路径,而值是一个哈希值。证据的形式依赖于状态树的格式,所以十六进制树和二进制树下的证据将有所不同。这一语义使得我们能在同一个见证中包含多种类型的多值证明。所以,理论上来说,我们可以创建出一种既能支持十六进制状态树、又能支持二进制状态树的见证数据格式。
数据体按 key 的字典顺序排序、存储,以确保:
- 更短的键在列表中总是排得前一些(在自顶向下重建默克尔树时候会有用)
- 当两个数据的键相同时(账户地址可能和 code key 相同),总是把账户相关数据排在前面。
解析算法
- 检查见证数据的版本,以及证据所用的默克尔树格式(以确保证据的格式与区块所需的状态树格式相匹配)
- 验证见证数据的哈希值(如果有 “canonical witness” 的概念的话)
- 使用正确的格式创建一棵空的默克尔树
- 遍历数据,按读取数据的顺序为这棵空默克尔树插入数据(见证数据也应该以字典顺序存储)
- 插入证据到树中
- 验证根哈希值(应该与上一区块的根哈希值一致)
好处 & 缺点
对比一下键值对见证格式与当前的操作码见证格式的优缺点。
优点:
- 与 flat DB 数据库机构相匹配,所以如果 canonical witness 哈希值是有效的,就可以立即插入(不需要验证默克尔根值)
- 可以用于快照同步(snapshot sync)
- witness 中的数据独立于我们所选的验证证据的方法:无论是默克尔树,还是多项式承诺,还是别的方法,都不会影响我们需要添加的数据。
缺点:
- 在二进制状态树下,可能会因为字节对齐(byte alignment)而需要占用更高的带宽(例如,证据的键为
0b01,只是两个比特,却需要占用一个字节的存储空间) - 解析起来可能更慢
网络效率研究
KV Witness 的实现案例
我们首先必须证明这种格式能够实现正确性。它必须能执行以太坊主网上的所有区块。
为此,我在 turbo-geth 代码库的一个分支里面实现了这种见证方案:kv-witness-research。
这一实现是在谷歌云里面测试的,执行的是块高从 500 万到 800 万的以太坊主网区块。
如何重复我的实验?
你需要至少 200 GB 的可用硬盘空间,和至少 32GB 的内存(因为代码还在概念验证阶段,没怎么优化)。
1)复制 turbo-geth 客户端(commit 号为 aa6b4dc609b3d871c778597a71ac08601f17de53)的 kv-witness-research 分支
2)同步主网的区块头和区块体:go run ./cmd/geth --syncmode staged --datadir ~/stateless-chaindata/ (我花了一天时间)
3)以同步所得的数据运行无状态客户端的原型(我花了 17 天)
go run ./cmd/state stateless --blockSource ~/stateless-chaindata/geth/chaindata --statefile ~/kv_witness_statefile --witnessInterval 5000000 --statsfile ~/stats_kv_witness.csv 2>&1 | tee debug.log如此,在 stats_kv_witness.csv 文件中,你就能得出跟我在本文中所示的一模一样的结果。
见证数据的格式
见证数据的开头是一个单字节的数据头(header),包含其版本信息。
然后就是数据体(body),由大小信息和元素(elements)本身组成;大小信息会占用 1~4 个字节,具体要看元素的数量。
每一个元素都以一个字节的类型(type)开头,然后是键(key)字段,是一个长度任意的字节数组;键字段的前缀是大小信息,然后是实际数据(就像数据体的布局一样)。
数据的形式取决于元素的类型:
- 对于 storage 叶子节点,数据是任意长度的字节数组,前缀是其长度信息(size bytes);
- 对代码叶子节点,数据也是任意长度的字节数组,以长度信息为前缀;
- 对于证据,数据是一个定长的,32 字节的哈希值,不包含任何前缀信息。
以账户为键的数据则更复杂一些,但主要的数据包括:
- flag (辨识该账户元素是否具有默认值)
- nonce(如果不为零),需要 8 个字节
- 余额(如果不为零),任意长度的字节数组,前缀为其长度
- 存储根哈希值(如果不为空),32 个字节,定长的字节数组
- 代码哈希值(如果不为空),32 个字节,定长的字节数组
最终,见证数据看起来会长这样:
[<header> <witness_elements_count> <element1_type> <element1_key_size> <element1_key_byte1> ... <element1_value_size> ... <element2_type> ...]
[<数据头> <元素数量> <元素1_类型> <元素1_键长度> <元素1_键_字节1> ... <元素1_值长度> ... <元素2_类型> ...]
优化:删除重复键前缀
键是一个由半字节(nibble)组成的默克尔路径,不是由字节组成的。对于十六进制默克尔树而言,一个半字节的长度是 4 个比特,对二进制默克尔树来说则是 1 个比特。因此,有时候键的字节长度并不是整数(举个例子,12 比特是 8.5 个字节)。
键被编码为 []byte,这样就是字节对齐的(所以如果有一个键的长度在 4 个字节到 5 个字节之间,它总是会被补齐为 5 个字节)。同样地,可以加入一个额外的 “面罩” 在开头,指明在最后一个字节中,哪些比特是 1。
- 键
0xFF(1 byte): [00001000 11111111] - 数据和证据将共同按字典顺序排序和存储 -
数据头的前 4 个比特将用来说明前一个键的字节偏移量(The highest 4 bits of a header byte mean a byte offset of a previous key.)。
因为在我们的语意中,键是排过序的,我们可以使用前 4 个字节来说明下列情况:
- 本键与前一个键相同,整个键因此可以压缩到 1 个字节:
[10000000] - 本键与前一个键无任何一个字节是相同的(
[0000xxxx xxxxxxxx ...]) - 本键与前一个键共享至多 14 个作为前缀的字节 (
[????xxxx xxxxxxxx ...]): 开头的 “?” 号表示 big-endian 编码的数字,从 1 (001) 到 14 (1110) ) - 本键与前一个键共享超过 15 个字节:([1111xxxx ???????? xxxxxxxx ...]),而中间的 ”疑问号“ 是对超过数量的说明
- 如果恰好是 15 个字节,那就是
[1111xxxx 00000000 ... ](15 + 0) - 如果是 16 个字节,那就是
[1111xxxx 00000001 ... ](15 + 1) - 如果是 32 个字节,那就是
[1111xxxx 00010001 ... ](15 + 17)
- 如果恰好是 15 个字节,那就是
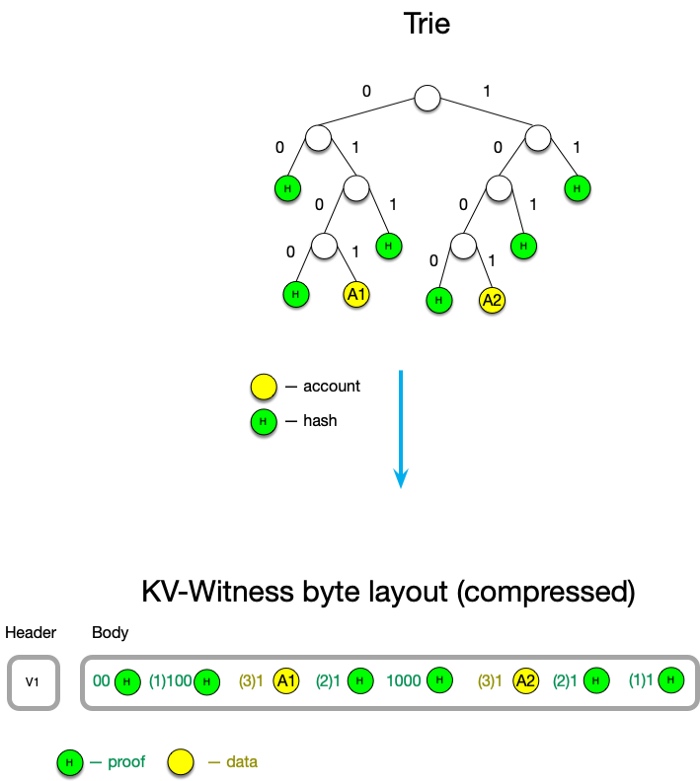 <center> KV-Witness 压缩。括号中的数字表示要从前一个键中重用多少个比特 </center>
<center> KV-Witness 压缩。括号中的数字表示要从前一个键中重用多少个比特 </center>
网络效率研究结果
本结果的原始数据可以在此 GitHub 仓库中找到:https://github.com/mandrigin/ethereum-mainnet-kv-witness-data 。
为了在网络效率角度得出一个全面的图景,我比较了 3 种见证数据格式,统一用十六进制默克尔树来运行:
1)基于操作码的见证数据,就是现有的这个。(数据沿用自我的上一次实验)
2)基于键值对的见证数据(未压缩):没有删除重复的键前缀
3)基于键值对的见证数据(压缩后)
测试的范围是区块高度从 500 万到 800 万的区块。
绝对大小比较
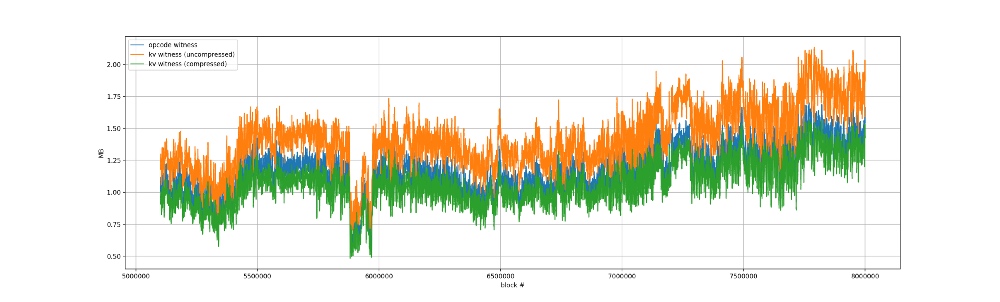 <center>绝对大小的比较。 压缩后的 KV witness 与 opcode witness 表现非常相似。</center>
<center>绝对大小的比较。 压缩后的 KV witness 与 opcode witness 表现非常相似。</center>
量化分析
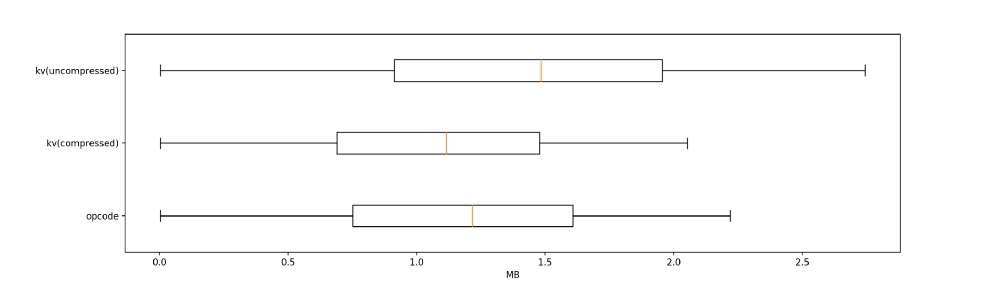
| 平均值 | 中值 | 90 分位值 | 95 分位值 | 99 分位值 | 最大值 | |
|---|---|---|---|---|---|---|
| 基于操作码的见证数据 | 1.16 | 1.22 | 1.87 | 2 | 2.22 | 12.9 |
| 基于键值对的见证数据(未压缩) | 1.42 | 1.48 | 2.28 | 2.45 | 2.74 | 5.58 |
| 基于键值对的见证数据(压缩后) | 1.07 | 1.11 | 1.72 | 1.84 | 2.05 | 4.91 |
结论
删除重复的键前缀为 KV witness 带来了相当大的提升。有了这个功能,它与基于操作码的方案的带宽消耗就几乎相同了。
而基于键值对的方案还有许多优点。
最重要的优点是:简洁。为一种数据格式(本质上就是一个字典)撰写详述,要比为一个几乎是编程语言一样的方法撰写详述简单得多。
第二大优势是,证据在语义上与数据是独立的,所以,当我们想要改变状态树的形式(从十六进制转为二进制)、或者想要完全改变证据的机制时,KV-Witness 方法所需的变更要小得多。
我认为,KV-witness 方案是见证数据标准的有力竞争者。
(完)
原文链接: https://medium.com/@mandrigin/kv-witness-8985168537f9 作者: Igor Mandrigin 翻译: 阿剑





