Python量化实战:从零构建预测市场交易机器人
文章详细介绍了如何使用 Python 构建事件驱动的回测系统。相比向量化回测,该方法能更真实地模拟交易佣金、滑点和仓位管理。核心内容包括:实现 Portfolio 类管理资产状态、通过网格搜索进行参数优化、利用向前走分析(Walk-Forward Analysis)防止过拟合,以及引入凯利准则(Kelly Criterion)进行科学的仓位管理。

事件驱动回测与参数优化
在上一篇文章中,我们构建了一个向量化回测,并在真实 BTC 数据上比较了三种策略。速度快、简洁,而且实用。但这种方法有局限:它不能正确处理手续费,不能建模滑点,也不支持复杂的仓位管理规则。
在本文中,我们将进入下一个阶段:事件驱动回测。我们将逐 bar 处理数据——这也是它在实盘交易中实际发生的方式。我们将加入手续费和滑点,通过网格搜索进行参数优化,学习如何用 walk-forward 分析对抗过拟合,并了解用于仓位管理的 Kelly Criterion。
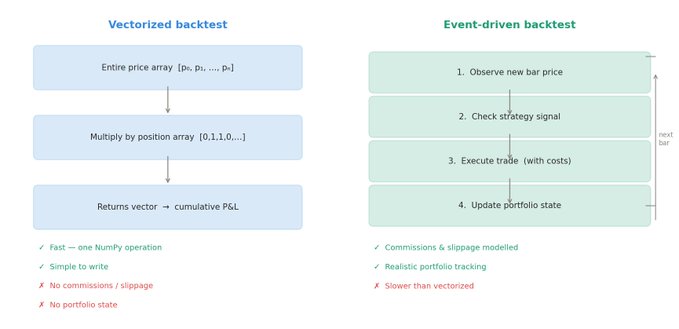
事件驱动 vs 向量化回测
在向量化回测中,我们一次性对整个数据数组进行操作。它很快,但这意味着没有“状态”这个概念——我们只是简单地把两个数组相乘并得到收益。
在事件驱动回测中,我们一次一个 bar 地遍历数据,就像我们正处于那个时间点里一样。在每个 bar:
- 我们观察新数据。
- 我们检查策略条件。
- 我们做出决策:买入、卖出,或者什么都不做。
- 我们更新组合状态:现金余额、仓位和交易历史。
它更慢,但它能让我们准确建模现实:每笔交易都会扣除手续费,滑点会侵蚀利润,仓位大小会影响净值曲线。
构建事件驱动回测
让我们从一个简单但完整的实现开始。我们需要三个组件:
- Portfolio:一个跟踪状态的对象(手头现金、当前仓位、交易历史)。
- execute_trade():一个模拟订单执行并考虑手续费和滑点的函数。
- run_backtest():主循环,逐 bar 遍历并调用策略。
Portfolio 类
class Portfolio:
"""
跟踪交易账户状态。
"""
def __init__(self, initial_cash=10_000.0, commission=0.001, slippage=0.0005):
"""
参数:
initial_cash -- 初始资金,单位 USDT
commission -- 每笔交易手续费 (0.001 = 0.1%)
slippage -- 滑点 (0.0005 = 0.05%)
"""
self.initial_cash = initial_cash
self.cash = initial_cash
self.position = 0.0 # 持仓中的 BTC 数量
self.commission = commission
self.slippage = slippage
self.trades = [] # 交易历史
self.equity_curve = [] # 净值曲线
def buy(self, price, date):
"""使用全部可用现金开多仓。"""
if self.position > 0:
return # 已经持仓
# 滑点:我们以略高于价格的水平买入
exec_price = price * (1 + self.slippage)
# 扣除手续费
commission_cost = self.cash * self.commission
btc_amount = (self.cash - commission_cost) / exec_price
self.position = btc_amount
self.cash = 0.0
self.trades.append({
"date": date,
"action": "BUY",
"price": exec_price,
"amount": btc_amount,
"cost": commission_cost,
})
def sell(self, price, date):
"""平仓。"""
if self.position == 0:
return # 没有可平的仓位
# 滑点:我们以略低于价格的水平卖出
exec_price = price * (1 - self.slippage)
proceeds = self.position * exec_price
commission_cost = proceeds * self.commission
self.cash = proceeds - commission_cost
self.position = 0.0
self.trades.append({
"date": date,
"action": "SELL",
"price": exec_price,
"amount": 0,
"cost": commission_cost,
})
def total_equity(self, current_price):
"""当前组合价值:现金 + 按当前价格计算的仓位价值。"""
return self.cash + self.position * current_price
def record(self, date, current_price):
"""将当前状态记录到净值曲线中。"""
self.equity_curve.append({
"date": date,
"equity": self.total_equity(current_price),
})
主回测循环
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from data_loader import fetch_btc_data, add_returns
from strategies import sma_crossover_strategy, momentum_strategy, mean_reversion_strategy
def run_backtest(df_strategy, initial_cash=10_000.0, commission=0.001, slippage=0.0005):
"""
事件驱动策略回测。
"""
portfolio = Portfolio(initial_cash, commission, slippage)
data = df_strategy.dropna(subset=["position"]).copy()
for date, row in data.iterrows():
price = row["close"]
position = row["position"]
if position == 1:
portfolio.buy(price, date)
elif position == 0:
portfolio.sell(price, date)
portfolio.record(date, price)
equity_df = pd.DataFrame(portfolio.equity_curve).set_index("date")
return portfolio, equity_df
## 执行示例
df = fetch_btc_data(interval="1d", lookback="2 years ago UTC")
df = add_returns(df)
df_sma = sma_crossover_strategy(df, fast=20, slow=50)
portfolio, equity_df = run_backtest(df_sma, initial_cash=10_000)
print(f"起始资金: ${portfolio.initial_cash:,.0f}")
print(f"最终资金: ${equity_df['equity'].iloc[-1]:,.0f}")
print(f"交易次数: {len(portfolio.trades)}")
print(f"总手续费: ${sum(t['cost'] for t in portfolio.trades):,.2f}")
手续费和滑点
让我们看看交易成本如何改变结果。我们用不同设置运行同一个回测:
configs = [
{"commission": 0.0, "slippage": 0.0, "label": "无成本"},
{"commission": 0.001, "slippage": 0.0, "label": "仅手续费 (0.1%)"},
{"commission": 0.001, "slippage": 0.0005, "label": "手续费 + 滑点"},
{"commission": 0.002, "slippage": 0.001, "label": "高成本"},
]
results = {}
for cfg in configs:
_, eq = run_backtest(df_sma,
commission=cfg["commission"],
slippage=cfg["slippage"])
results[cfg["label"]] = eq
fig, ax = plt.subplots(figsize=(12, 5))
for label, eq in results.items():
ax.plot(eq.index, eq["equity"], label=label, linewidth=1.2)
ax.set_title("手续费和滑点对收益的影响 (SMA 20/50)")
ax.set_ylabel("资金 (USDT)")
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
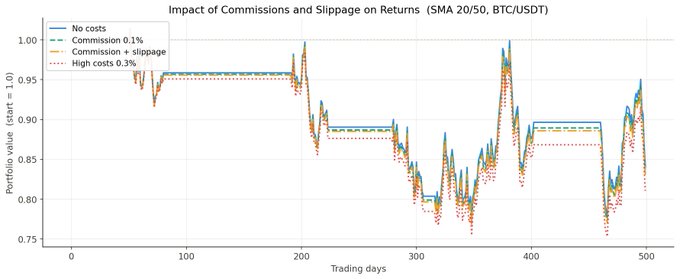
对于每年 8-12 笔交易的 SMA 交叉策略,差异很小。但对于每月有几十笔交易的策略来说,这种影响就很显著了。一定要考虑交易成本;它们可能把一个有盈利的策略变成亏损的策略。
参数优化:网格搜索
每个策略都有参数。对于 SMA 交叉来说,这些参数就是快周期和慢周期。网格搜索可以让我们尝试每一种组合并选出最优的。
def grid_search_sma(df, fast_range, slow_range, commission=0.001):
"""
遍历所有 SMA 交叉参数组合。
"""
results = []
for fast in fast_range:
for slow in slow_range:
if fast >= slow:
continue
df_strat = sma_crossover_strategy(df, fast=fast, slow=slow)
portfolio, equity_df = run_backtest(df_strat, commission=commission)
final_equity = equity_df["equity"].iloc[-1]
total_return = (final_equity / portfolio.initial_cash) - 1
# Sharpe ratio
daily_returns = equity_df["equity"].pct_change().dropna()
sharpe = (daily_returns.mean() / daily_returns.std()) * np.sqrt(252) \
if daily_returns.std() > 0 else 0
# 最大回撤
rolling_max = equity_df["equity"].cummax()
max_drawdown = ((equity_df["equity"] - rolling_max) / rolling_max).min()
results.append({
"fast": fast,
"slow": slow,
"total_return": total_return,
"sharpe": sharpe,
"max_drawdown": max_drawdown,
"trades": len(portfolio.trades),
})
return pd.DataFrame(results)
## 运行搜索
fast_range = range(5, 51, 5) # 5, 10, 15, ... 50
slow_range = range(10, 201, 10) # 10, 20, 30, ... 200
grid_results = grid_search_sma(df, fast_range, slow_range)
结果热力图
让我们可视化 Sharpe ratio 在参数空间中的变化:
import seaborn as sns
pivot = grid_results.pivot(index="slow", columns="fast", values="sharpe")
fig, ax = plt.subplots(figsize=(12, 8))
sns.heatmap(pivot, annot=False, fmt=".2f", cmap="RdYlGn",
center=0, ax=ax, cbar_kws={"label": "Sharpe ratio"})
ax.set_title("Sharpe Ratio: SMA 交叉 (fast vs slow)")
ax.set_xlabel("快 SMA (天)")
ax.set_ylabel("慢 SMA (天)")
plt.tight_layout()
plt.show()
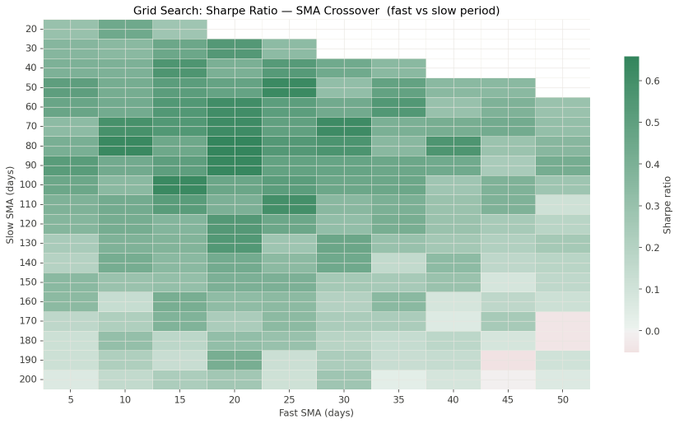
热力图显示,并不存在一个单一的“最佳”参数组合——存在整片策略表现良好的区域。这是一个好信号;如果好的结果只集中在某一个非常狭窄的位置,那就会是过拟合的明显信号。
过拟合与 Walk-Forward 分析
网格搜索的陷阱在于:如果你在用于评估结果的同一份数据上调参,那么你最终得到的策略会完美贴合过去。这被称为过拟合。
经典的解决方案是将数据按时间顺序分成三部分:
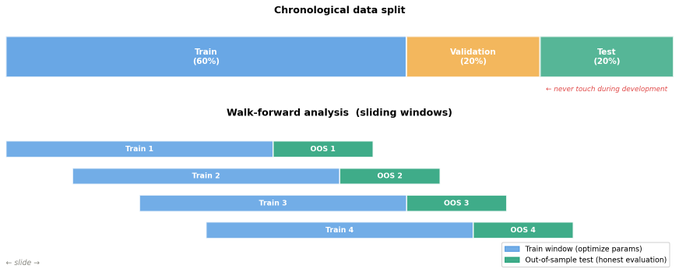
- 训练集:在这里优化参数。
- 验证集:检查是否过拟合。
- 测试集:在未接触的数据上做最终评估。
Walk-Forward 分析
Walk-forward 分析是这一原则更现实的版本。我们在数据上滑动一个窗口:
- 取一个训练窗口(例如 1 年)。
- 在其上优化参数。
- 在下一个窗口(例如 3 个月)上测试——这就是样本外。
- 将两个窗口向前移动并重复。
def walk_forward_analysis(df, fast_range, slow_range,
train_months=12, test_months=3,
commission=0.001):
results_oos = []
start = df.index[0]
end = df.index[-1]
window_start = start
while True:
train_end = window_start + pd.DateOffset(months=train_months)
test_end = train_end + pd.DateOffset(months=test_months)
if test_end > end:
break
df_train = df[window_start:train_end]
df_test = df[train_end:test_end]
# 在训练集上优化
best_sharpe = -np.inf
best_fast, best_slow = 20, 50
for fast in fast_range:
for slow in slow_range:
if fast >= slow: continue
df_s = sma_crossover_strategy(df_train, fast=fast, slow=slow)
_, eq = run_backtest(df_s, commission=commission)
if len(eq) < 5: continue
dr = eq["equity"].pct_change().dropna()
sharpe = (dr.mean() / dr.std()) * np.sqrt(252) if dr.std() > 0 else 0
if sharpe > best_sharpe:
best_sharpe, best_fast, best_slow = sharpe, fast, slow
# 样本外测试
df_s_test = sma_crossover_strategy(df_test, fast=best_fast, slow=best_slow)
_, eq_test = run_backtest(df_s_test, commission=commission)
if len(eq_test) > 0:
oos_return = (eq_test["equity"].iloc[-1] / eq_test["equity"].iloc[0]) - 1
results_oos.append({
"period_start": train_end.date(),
"period_end": test_end.date(),
"oos_return": oos_return,
})
window_start += pd.DateOffset(months=test_months)
return pd.DataFrame(results_oos)
Kelly Criterion:仓位大小
Kelly Criterion 决定了你每笔交易应该拿出多少比例的资金来承担风险,以最大化长期增长。
二元结果下的 Kelly 公式: f = (p * b - (1 - p)) / b
其中:
f:投入资金比例。p:胜率(获胜概率)。b:平均盈利与平均亏损之比。
在实践中,交易者通常使用半 Kelly。它能获得大约 75% 的最大增长,但波动和回撤只有一半。
def kelly_fraction(trades_df):
wins = trades_df[trades_df["pnl"] > 0]["pnl"]
losses = trades_df[trades_df["pnl"] < 0]["pnl"].abs()
if len(wins) == 0 or len(losses) == 0:
return 0.0
p = len(wins) / len(trades_df)
b = wins.mean() / losses.mean()
kelly_f = (p * b - (1 - p)) / b
return max(0.0, min(kelly_f, 1.0))
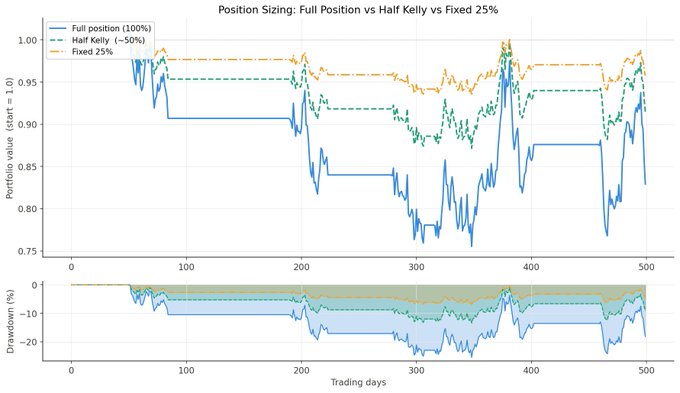
适度的仓位管理可以降低波动,并让策略在心理上更容易长期坚持。
最终脚本
"""
backtest_event.py -- 带手续费、网格搜索和 Kelly 的事件驱动回测
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from data_loader import fetch_btc_data, add_returns
from strategies import sma_crossover_strategy
class Portfolio:
def __init__(self, initial_cash=10_000.0, commission=0.001, slippage=0.0005):
self.initial_cash = initial_cash
self.cash = initial_cash
self.position = 0.0
self.commission = commission
self.slippage = slippage
self.trades = []
self.equity_curve = []
def buy(self, price, date):
if self.position > 0: return
exec_price = price * (1 + self.slippage)
commission_cost = self.cash * self.commission
self.position = (self.cash - commission_cost) / exec_price
self.cash = 0.0
self.trades.append({"date": date, "action": "BUY", "price": exec_price, "cost": commission_cost})
def sell(self, price, date):
if self.position == 0: return
exec_price = price * (1 - self.slippage)
proceeds = self.position * exec_price
commission_cost = proceeds * self.commission
self.cash = proceeds - commission_cost
self.position = 0.0
self.trades.append({"date": date, "action": "SELL", "price": exec_price, "cost": commission_cost})
def record(self, date, price):
self.equity_curve.append({"date": date, "equity": self.cash + self.position * price})
def run_backtest(df_strategy, initial_cash=10_000.0, commission=0.001, slippage=0.0005):
portfolio = Portfolio(initial_cash, commission, slippage)
data = df_strategy.dropna(subset=["position"]).copy()
for date, row in data.iterrows():
if row["position"] == 1:
portfolio.buy(row["close"], date)
elif row["position"] == 0:
portfolio.sell(row["close"], date)
portfolio.record(date, row["close"])
return portfolio, pd.DataFrame(portfolio.equity_curve).set_index("date")
if __name__ == "__main__":
df = fetch_btc_data(interval="1d", lookback="2 years ago UTC")
df = add_returns(df)
df_sma = sma_crossover_strategy(df, fast=20, slow=50)
portfolio, equity_df = run_backtest(df_sma)
print(f"最终资金: ${equity_df['equity'].iloc[-1]:,.0f}")
练习
- 对动量策略(window=20)运行事件驱动回测。手续费起到了多大作用?
- 对动量策略(window 5 到 60)运行网格搜索。哪个 window 给出了最佳 Sharpe ratio?
- 实现 70/30 的训练/测试切分。在训练集上优化,然后在测试集上运行。结果是否仍然成立?
- 为 SMA 交叉计算 Kelly fraction,并比较满仓与半 Kelly 下的净值曲线。
总结
在本文中,我们构建了完整的事件驱动回测:
- 构建了
Portfolio类来模拟带手续费和滑点的真实交易。 - 实现了事件驱动循环,逐 bar 处理数据。
- 使用网格搜索和 walk-forward 分析来优化参数并对抗过拟合。
- 应用 Kelly Criterion 进行专业的仓位管理。
免责声明
算法交易涉及真实的金融风险。本系列内容仅用于教育。它将教你如何构建交易机器人,但不能保证盈利。良好的回测结果并不意味着在真实市场中也会有良好结果。
下一步
在第 7 篇文章中,我们将加入机器学习。我们会使用历史 BTC 数据,从技术指标中构建特征,并训练模型来判断是否有可能比随机猜测更好地预测价格方向。
- 原文链接: x.com/sopersone/status/2...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
