Libra白皮书技术解读
- Sunrye
- 发布于 2019-08-07 22:48
- 阅读 12486
Libra白皮书技术解读
Libra白皮书技术解读
简介
Libra目前是一个联盟链的组织形式,他的去中心化体现在,由多个validator来共同处理交易以及区块链中的状态,但是随着时间的推移,Libra也计划朝着公有链的方向发展。
对于Libra,我们可以将其看做是一个通过Libra协议管理的带加密认证的数据库,通过LibraBFT共识算法,可以保证每个诚实节点中数据库的数据是一致的。与以太坊相似,Libra也有智能合约和账户的概念,但是不同的是,Libra将合约和资源是分开存储的,这个会在后续详细展开。
下面这个图是Libra协议中两种角色:客户端client,验证器validator。validators就像是元老会,会轮流着产生提议者,用来将当前的交易定序、打包形成区块,并且共同维护着数据库的一致性。client就是负责发起提交交易,查询信息等,比如钱包就是一个典型的client。
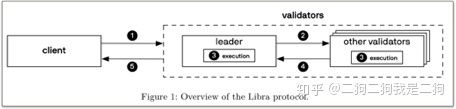
这里简单介绍上图的流程,当用户通过钱包(client)发起了一笔转账交易后,钱包就会将这笔经过用户签名的交易通过grpc发送给validator(过程1)。节点在收到client提交的交易后,首先会对交易进行预检验,只有有效的交易才会被validator节点转发给当前轮次下的leader,leader是validator集合中在某个轮次下有提议权利的节点,leader从本地的交易池中获取若干条有效的交易,对其定序打包后,转发给其他validator(过程2)。validator(包括leader)可以理解为是一个状态机,每个validator在收到leader广播的block后,会执行其中的所有交易(过程3)。由于validator存在作恶的可能性,因此每个validator在执行完交易后不能直接将结果写入storage中,Libra的共识要求他们对执行完的结果进行投票,只有达成共识的结果才能写入到storage中(过程4)。在交易被提交成功后,validator不仅会将交易,以及结果写入到storage,还会生成一个当前交易版本下整个数据状态的签名(其实就是Merkle Accumulator),client在进行一些只读的查询时可以从这个数据结构里进行查询(过程5)。
数据的逻辑结构
相比于以太坊(ethereum),Libra弱化了区块(block)的概念,只是把它当做是交易(transaction)的载体,实际的最小执行单位是交易。对于Libra,我们可以看做是一个带版本号的数据库,这里的版本其实就是交易$$T_i$$的序号 $$i$$ ,这个序号是严格递增的。在版本号为 $$i$$ 时,数据库会保存元组 $$(T_i, O_i, S_i)$$ 数据,这里的 $$T_i$$ 表示序号为 $$i$$ 的交易, $$O_i$$ 表示执行完交易 $$T_i$$ 后的输出结果, $$S_i$$ 表示账本状态。当我们执行某个程序,过程的大致可以表述为,在某个状态下,程序代码按照给定的参数执行。例如validator收到了一笔序号为 $$i$$ 的交易$$Ti$$ ,当validator执行时交易时,他的状态是基于上一个版本$$S(i-1)$$,输入参数则是接收到的交易$$T_i$$,而需要执行的代码,其实在 $$T_i$$ 中指定了需要执行的合约。所以,按照数学归纳法的推导,如果validator的最初状态都是一致,并且是诚实的节点(即诚实的执行),那么只要他们的输入是一致的,这些validator的账本状态也将是一致的。
通过这种带版本号的数据库,可以方便的查询在各个版本下的账本数据。例如,我们需要查询在版本号为10下某个账户的余额信息。
但是随之而来的问题是,我们如何判断上述的交易、状态数据等是有效和没有被篡改的?Libra针对上述情况,设计了Ledger History数据结构。
账本状态
Libra和以太坊一样,采用了账户模型,这里之所以没有采用UTXO,主要是因为UTXO模型不适合用于复杂的合约。
以太坊的账户地址是由公钥衍生出来的,Libra也是一样,不过Libra在创建用户的时候会生成两对公私钥:验证、签名(vk,sk)公私钥对。其中Libra的账户地址是由vk的公钥经过哈希后生成的。之所以要区分vk和sk是为了安全起见,Libra用户可以在不更换地址的情况下,更换新的签名公私钥对。
关于账户状态,Libra和以太坊的区别比较大。在以太坊中,账户下面会存放余额、合约、nonce等信息。Libra的账户状态主要包含了两部分:module、resource。module类似于以太坊中的合约,resource则是module中定义好的资源。module和resource的归属权是分开来的,如下图所示。方框表示的是module,椭圆表示的是resource。例如对于账户0x56来说,他发布了一个Currency的module(合约),那么这个module是存储在其0x56的目录下的,如果另外一个账户0x12也拥有了Currency.T这个资源,那么该资源是存储在0x12的目录下的,相当于是将代码段和数据段分开来了。
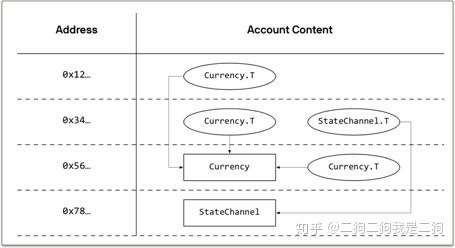
而以太坊的合约并不是这样的,例如我们发布了一个ERC20的合约,我们会定义一个map结构mapping (address => uint256) public balanceOf; 该结构会存储某个账户在这个合约中包含有多少ERC20的token。也就是说,以太坊中的合约是将数据段和代码段混合在一起的。
Libra之所以这样做,主要是为了保证资源的所属权,从而保证其安全性。
交易
交易中有个program字段,包含了需要执行的脚本以及参数,或者需要部署的module字节码。由于Libra采用LibraBFT的共识,当validator接收到block,并不意味着这轮的共识结束了,所以validator在执行完接收到的交易后,并不会马上将执行后的状态写入到分布式账本状态(Ledger state)中,只有当大部分的节点关于该交易执行的结果投票达成共识后才会更改Ledger state。
交易 $$T_i$$ 执行完后,除了会生成新的状态 $$S_i$$ 外,还会额外产生一个交易输出 $$O_i$$ 。交易输出可以类比于以太坊的交易收据,包括了gas使用、执行状态、event等。这里的执行状态是指虚拟机的执行状态,并不是具体合约的业务执行状态。例如,执行状态是成功,表示虚拟机在执行过程中没有出现gas不足或者导致执行异常的触发条件。
为了能够清晰的了解合约执行的执行过程,Libra参考了以太坊,加入了event事件。event就像是我们在开发中采用print方法打印某些日志数据以此判断代码的执行逻辑。事实上,在以太坊的ERC20中,开发者为了判断token转账是否成功,会在transfer函数执行成功后,加上一个Transfer event,一旦交易执行完成后,抛出了Transfer类型的event,那么开发者就可以认为此次合约转账是成功的(除去分叉的概率外)。

账本历史
账本历史(Ledger History)存储了已经执行并提交(达成共识)的交易,以及event信息等。这些信息对于validator执行交易来说是不需要的,之所以存储了上述信息,主要的目的是为了保证validator的可信度。client通过查询validator的数据,以此监督validator在正确的执行交易。
交易执行
再来看一下Libra区块链的交易执行,Move语言会在后续通过实际编写和部署合约的时候仔细介绍。
在Libra中,能够触发状态变化的只能是通过执行交易,目前Libra的测试网络还不允许普通用户发布合约,并且能够调用的脚本也是有限的,下面是Libra中config的配置信息,Locked表示不允许普通用户发布和调用非白名单里外的脚本。

不过最新的Libra代码,在testnet分支中已经将该限制打开了,普通用户可以在本地进行合约的部署。
交易执行的条件
对于区块链中每个诚实validator节点,我们可以把它当做一个状态机,他会在当前的状态下,按照既定的逻辑诚实的执行输入。
那么在最初的时刻,这个初始状态是如何确定的呢?我们用以太坊来进行对比。下面是以太坊的genesis.json,这个文件确定了以太坊网络最初的状态,比如在alloc中设定了两个地址的初始eth数量,以及最初的难度值等信息。

Libra对genesis的处理与以太坊的不同,正如Libra在白皮书中说的,能够改变状态的唯一方式是交易的执行,而genesis作为初始状态的输入,其实也是一个交易,只不过这个交易的序号是0($$T_0$$)。这个交易相比于其他交易的特殊点在于,这个交易是一个writeset类型的,我们暂时可以将其理解为是一个写入类型的交易,不需要执行。另外,writeset类型的交易只能在genesis阶段运行发布。
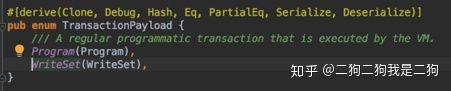
既然genesis作为 $$T_0$$ 交易,那么必然需要满足他的发送者有足够的费用支付交易费用,同时由于Libra是联盟链,因此 $$T_0$$ 会指明当前的validator集合以及他们的验证信息等,另外由于Libra的token是通过合约发布的,因此在 $$T_0$$ 中还会部署上Libra的account和coin两个合约,如果大家有兴趣可以查看下genesis.blob来验证下,不过genesis.blob有部分是乱码,但是基本上足够支撑上述的论点了。这里之所以这么关注genesis,是因为通过了解这个方便我们可以自己搭建Libra的测试网络。
另外,白皮书提到了确定性,这个比较好理解,如果无法保证确定性,那么意味着不同validator对同一个交易的执行结果是不同的,那么就无法达成一致,分叉就开始了。Libra的gas机制与以太坊的比较相似,例如:
- 影响gas的是gas price和实际消耗的gas cost;
- 一旦交易执行中的gas使用超过了gas limit,那么就会立马halt,并且将数据回滚到上一个版本,虽然该交易没有执行成功,但是还是会出现在block中。
Libra和以太坊关于gas的最大区别是,Libra设定gas的主要目的是为了防止DDoS,而以太坊的gas除了这个目的外,还将gas作为激励的一部分给miner。之所以有这个区别,是因为以太坊是公有链,简单说,你要吸引miner来挖矿执行交易,必然需要激励。但是Libra是强联盟链, 不太需要这种激励模式。
交易结构
Libra的交易结构与以太坊的比较相似,对于一个已经签名的交易,他的结构如下:
sender address:很好理解,就是这笔交易发起者地址。
sender public key:表示交易发起者的公钥,这里之所以还要额外再增加这个,是因为Libra的账户有两对公私钥(vk,sk),sk用来签名,因此为了验证交易是否被篡改,需要表明sk的公钥。
program:这个就和以太坊的data字段一样,用来存放需要执行的script或者需要部署的module。
gas price:和以太坊的一样。
maximum gas amout:就是以太坊的gas limit。
sequence number:就是以太坊的nonce,防止双花的。
交易执行
交易执行表示在VM中执行阶段,他的行为不会对外部有影响,只有达成共识后,该交易执行的结果才会反应到账本状态。在虚拟机中执行交易一共分6个步骤。
-
验证签名。根据交易的签名数据以及交易的字段中的
sender public key来验证内容是否被篡改。 -
前置校验。一些执行前的前置条件的检验,主要有:
- 身份认证:签名验证确保了数据没有被篡改,这块验证发送者的身份。具体的做法是读取账户的authentication key,判断和交易中的sender public key相同。这个信息在LibraAccount module中被定义了。
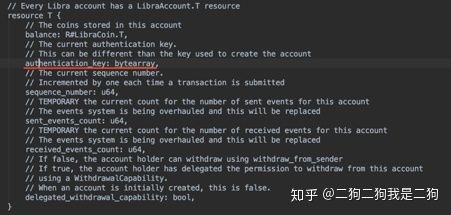
- 检验gas是否足够:因为交易执行过程需要gas,确保账户有足够的余额来执行交易。通过判断gas_price * max_gas_amount <= sender_account_balance 来检查。
- seq检查:检查当前用户的seq与交易的seq是否一致,防止双花。这个seq也是在LibraAccount module中定义好的。
-
验证
script和module。这个步骤是Libra特有的,以太坊在做完上述检查后就直接进入到了执行步骤。由于Libra主打move,他的特性就是资源的所有权,因此为了保证能够安全的操作这些资源,Libra相当于做了一个在线的编译器(bytecode verifier),在执行前先做静态分析,确保module或script对资源的操作是安全。对于这个,有些人认为做成线下的 bytecode verifier在性能上会更加友好,但是一旦线下的话,Libra主打的安全其实也就失效了。不过,既然都是validator执行交易,那么能否设计成,validator放出官方的bytecode verifier,用户的script、module需要线下经过官方bytecode verifier验证并签名后,才可以发布,此时对于Libra来说只需要验证这些script、module是否经过官方签名即可,这样也避免影响了Libra网络的性能。不过这种方式听起来不是很去中心化,似乎不太符合大家对区块链的理解。我倒是觉得,能够避免一家独大,各家能够充分博弈,这才是比较符合现状。去中心化并不银弹。 -
发布合约。就是将module部署到这个账户下面,注意同一个账户下是不允许发布同名的module的。
-
执行脚本。这块展开的内容比较多,后续会作为重点来讲。这里就认为VM根据program的script执行对应的逻辑。
-
扫尾工作。在执行完后,就会对账户seq自增,以及扣减实际消耗的gas等操作。
Move语言
Move是Libra面向其合约开发者的编程语言,通过move可以实现:
- 我们可以创建script从而让交易能执行更多地逻辑;
- 允许用户按照实际的业务逻辑来自定义数据类型和代码,并发布到链上。
- 允许配置和扩展Libra的协议(包括Libra的token铸币,validator管理等)。
Move最大的一个特性就是,将resource(资源)当做了一等公民,并且可以自定义resource。例如上面贴出的LibraAccount中的resource T,就定义了账户的一些基本属性。
Libra一共有三种编写Move程序的方式:source code,intermediate representation(IR),byte code。对应起来就是,高级语言(C语言),汇编语言,字节码。现在Libra还没提供高级语言。
和以太坊一样,Libra的虚拟机也是基于栈的,基于栈的虚拟机的好处是指令比较精简,不像基于基于寄存器的,指令集满天飞。基于栈的虚拟机是没有堆区的,所有的局部变量和入参以及返回值等都是加载到栈中,每次函数调用完成后,栈的高度应该是和调用前相同的,Libra基于这个特性做了一个stack depth检测,从而增加了交易执行的安全性。
欢迎关注我的知乎专栏





