人工智能代理:研究与应用
这篇文章深入探讨了自主AI代理的概念,特别是基于大型语言模型(LLM)的代理在各个领域中的应用,包括游戏、治理、科学和机器人技术。文章详细介绍了代理的架构、记忆系统、感知能力、推理与规划,以及它们如何在复杂环境中动态互动和决策。通过多代理系统的框架,研究了如何利用这些代理实现智能协作和优化任务执行,同时也提出了在代理智能的发展中需要面对的伦理和社会问题。

近年来,在多个领域,包括哲学、游戏和人工智能,代理(agent)的概念变得越来越重要。在传统意义上,代理指一个实体自主行动、做出选择并行使意图的能力,这些特征历史上与人类相关联。
最近在人工智能领域,代理的概念已演变得更加复杂。随着自主代理的出现,这些代理可以观察、学习并独立地在其环境中行动,曾经抽象的代理概念如今被具体化为计算系统。这些代理在最小的人类监督下操作,并表现出尽管是计算而非意识的意图水平,使它们能够做出决策、从经验中学习,并以越来越复杂的方式与其他代理或人类互动。
本文探讨了自主代理的新兴生态,特别是基于大型语言模型(LLM)的代理,以及它们在游戏、治理、科学、机器人等各种领域的影响。基于基础的代理原则,本文考察了人工智能代理的架构和应用。通过这一分类法,我们能够深入了解这些代理如何执行任务、处理信息并在其特定操作框架内演变。
本文的目标有两个:
-
提供关于人工智能代理及其架构基础的结构化概述,重点关注内存、感知、推理和规划等组件。
-
考察人工智能代理研究的最新趋势,突出代理重新定义可能性的应用。
订阅
旁注:由于本文的长度,我想强调强调侧栏中有一份目录,以方便导航。
代理研究的趋势
基于LLM的代理的发展代表了人工智能研究的一个重要里程碑,反映了通过符号推理、反应系统、强化学习和自适应学习技术等一系列范式的进步。每个阶段都贡献了不同的原则和方法,塑造了现在的基于LLM的方法。
符号代理
符号代理源于早期的人工智能研究,依赖于符号人工智能,使用逻辑规则和结构化知识表示来模拟人类推理。这些系统以结构化且可解释的方式进行推理,类似于人类的逻辑。一个突出的例子是基于知识的专家系统,旨在通过将领域专业知识编码到基于规则的框架中来解决特定问题(例如,医学诊断或棋类引擎)。
符号代理在决策中提供高度的可解释性和表现力,允许清晰地解释行动。然而,在应用于复杂、动态环境时,它们在不确定性和可扩展性方面面临局限。它们的计算需求通常在需要适应性和速度的现实场景中妨碍了效率。
反应代理
反应代理标志着从复杂的符号推理转向更快、更简单的模型,以便进行实时交互。这些代理通过感知-行动循环操作,感知环境并立即做出响应,避免深层推理或规划。这里的重点在于效率和响应能力,而不是认知复杂性。
反应代理在计算上是轻量级的,使它们在快速响应至关重要的环境中显得理想。然而,它们的简单性限制了它们执行更高层次任务的能力,例如规划、目标设定或适应复杂的多步骤问题。这限制了它们在需要持续、目标导向行为的应用中的有效性。
基于强化学习的代理
计算能力的提升和数据的可用性使强化学习(RL)成为前沿,允许代理在复杂环境中表现出适应性行为。RL代理通过试验和错误进行学习,互动环境并根据奖励调整行为。Q-learning和SARSA等技术引入了策略优化,而深度强化学习则结合神经网络来处理高维数据(例如,图像、游戏)。AlphaGo就是这种方法的典范,通过这些方法击败了围棋人类冠军。
RL代理能够在动态环境中自主管理表现而无需人类监督,在游戏、机器人和自主系统等应用中具有重要价值。然而,RL面临着如训练周期漫长、样本效率低和稳定性问题等挑战,特别是在更复杂的场景中。
基于LLM的代理
LLM的出现重新定义了人工智能代理的设计,使LLM成为这些代理的“大脑”,能够以高准确性和灵活性理解和生成自然语言。LLM结合了符号推理、反应反馈和自适应学习的元素,利用链式思维(Chain-of-Thought, CoT)提示和问题分解等方法。这使得结构化推理的同时保持了响应能力。
基于LLM的代理还展示了小样本(few-shot)和零样本(zero-shot)学习的能力,使它们能够在只有最少示例的情况下跨新任务进行泛化。它们的多样性涵盖从软件开发到科学研究和自动化的各种应用。它们自然且适应性强地与其他代理互动,导致新兴的社会行为,包括合作和竞争,使其适合协作环境。
此外,基于LLM的代理能够在不需要参数更新的情况下进行多领域任务切换,增强了它们在复杂、动态环境中的有用性。通过结合可解释性、自适应学习和自然语言处理,它们为现代人工智能应用提供了一个平衡且高度可行的框架。
本文其余部分将专注于基于LLM的代理的架构、能力和局限性。
代理架构
现代代理架构可以理解为由多个模块组成的合成体。在下面,我们将根据 A Survey on Large Language Model based Autonomous Agents 和 The Rise and Potential of Large Language Model Based Agents: A Survey 提供的框架考虑代理架构的一般分类。
个人资料
在自主代理设计中,个人资料模块对于指导代理行为至关重要,通过分配特定的角色(如教师、编码员或领域专家)或个性来实现。这些个人资料影响代理响应的一致性和适应性。个人资料模块本质上作为行为支架,设置参数,帮助代理在后续交互中与其指定角色或个性保持一致。这种指导对于基于角色的表现表现和响应生成的连贯性至关重要,以及在需要持续个性特征的应用中。
正如在 从角色到个性化:基于角色的语言代理综述 中探讨的,基于LLM的代理中的角色可以分为三种主要类型:
-
人口统计角色:这种角色代表人口统计学的特征,例如职业、年龄或个性类型。人口统计角色通常用于社会模拟或旨在提升输出相关性和背景准确性的应用中。例如,代理可能采用数据科学家的特征,以提供有针对性的技术见解。
-
角色角色:在这里,代理体现一个虚构角色或公众人物,通常出于娱乐、游戏(例如,非玩家角色)或陪伴的目的。这种类型在对话式AI和虚拟伴侣中被广泛使用,代理的角色增加了用户体验的沉浸感和参与感。
-
个性化角色:代理被定制以反映某个特定个体的行为、偏好和独特特征,类似于个性化助手。这种角色类型通常用于代理充当个人的代理或在代理作为助手的场景中,根据特定用户的偏好和行为进行适应。
 来自《从角色到个性化》的论文
来自《从角色到个性化》的论文
这些角色已被证明在多种任务中增强了代理的表现和推理能力。例如,基于角色的方法使得LLM在具备某一专业类别时,能够提供更深入且与上下文相关的响应。此外,在如 ChatDev 和 MetaGPT 的多代理系统中,角色的使用通过将代理行为与任务特定角色对齐,促进了合作问题解决,有利于任务完成和互动质量。
个人资料创建的方法
在基于LLM的代理中使用了多种方法来构建和完善个人资料,每种方法都有其优势和考虑:
-
手动创建:个人资料由人手动定义,具体细节由人类输入。例如,用户可能将代理配置为“内向”或“外向”以反映特定的个性特征。
-
LLM生成:在这种方法中,个人资料由LLM自动生成,从少量的示例开始。此方法允许高效扩展和适应。例如,RecAgent 生成包含年龄、性别和个人兴趣等属性的初始个人资料,使用ChatGPT将这些个人资料扩展到大范围用户群中。
-
数据集对齐:从现实世界数据集(如人口统计研究)派生的个人资料,可以使代理模拟现实社会行为。这种方法通过将代理行为锚定在经验数据上,增强了交互的真实性。
内存
内存是LLM-based代理的基础组件,存储从环境中获取的信息,以实现自适应计划和决策。与人类内存类似,代理内存在处理序列任务和制定策略中发挥着关键作用。
内存结构
LLM-based代理中的内存结构受到认知科学的启发,特别是源自感官输入到短期和长期保留的人类记忆模型。在人工智能代理中,内存通常分为两种主要类型:
统一内存
统一内存模拟了短期内存系统,聚焦于最近的观察,它们可以直接融入提示中,以便立即响应。这种方法实现简单,能够有效增强代理对最近、上下文敏感信息的感知。然而,统一内存在变换模型固有的上下文窗口大小上基本受到限制。
为了管理上下文窗口的限制,已经开发出几种技术:
-
文本截断和分段输入:这些方法选择性地压缩或分割传入信息以适应上下文限制。
-
内存总结:互动中的关键数据被提炼成简洁的总结,然后重新引入到代理中,以保持相关性而不压倒上下文窗口。
-
注意机制修改:自定义的注意机制可以帮助模型优先考虑相关的最近信息。
尽管统一内存简洁,但被当前LLMs的有限上下文窗口所约束,这可能限制在处理大量信息时的可扩展性和效率。
混合内存
混合内存结合了短期内存和长期内存结构。在这里,短期内存作为暂时缓冲,捕获代理瞬时环境,长期内存则在外部数据库中存储反思或有用的见解,以便后续检索。
长期内存存储的常见实施方法是使用向量数据库,其思想被编码为嵌入。这种方法能够通过相似性搜索提取,允许代理有效回忆过去的互动。
内存格式
内存可以采用多种格式进行存储,每种格式适用于不同的应用程序。一些常见的格式包括:
-
自然语言:内存作为原始文本存储,提供灵活性和丰富的语义内容。像 Reflexion 和 Voyager 等代理使用自然语言存储反馈和技能。
-
嵌入:内存被编码为向量,提高了语境相似内存的检索和搜索的效率。像 MemoryBank 和 ChatDev 等工具将内存片段存储为嵌入,便于快速访问。
-
结构化列表:内存也可以以列表或层次结构存储。例如,GITM 将子目标组织为行动列表,而 RET-LLM 将句子转换为用于高效内存存储的三元组。
内存操作
内存操作对于代理互动存储的知识至关重要。这些操作包括:
-
内存读取:该操作涉及从内存中检索相关信息,受最近性、相关性和重要性的指导。提取有意义数据的能力能够提升代理在过去行动基础上做出明智决策的能力。
-
内存写入:将新信息存储到内存中是一个复杂的过程,必须管理重复项并防止内存溢出。例如,Augmented LLM 整合冗余数据以简化内存,而 RET-LLM 使用固定大小的缓存,用于覆盖旧条目,以避免饱和。
-
内存反思:反思使代理能够总结过去的经历并得出高层次的见解。在 Generative Agents 中,代理反思最近的经历,形成更广泛的结论,增强其抽象推理能力。
 来自 Generative Agents 论文
来自 Generative Agents 论文
研究意义与挑战
尽管内存系统显著提升了代理能力,但它们也带来了若干研究挑战和未解问题:
-
可扩展性与效率:提升内存系统以支持大量信息,同时保持快速检索是一个关键挑战。混合内存系统提供了有希望的解决方案,但在不妨碍性能的情况下优化长期记忆检索仍然是研究的重点。
-
应对上下文限制:当前的LLMs受到有限上下文窗口的约束,这限制了它们处理广泛记忆的能力。对动态造影机制和总结技术的研究继续探索扩展有效内存处理的方法。
-
长期记忆中的偏差与漂移:内存系统容易受到偏差的影响,某些类型的信息可能相对于其他信息受到青睐,可能导致记忆漂移。定期更新内存内容并实施偏差校正机制对于确保代理行为的平衡和可靠性至关重要。
-
灾难性遗忘:内存型代理系统中最显著的挑战之一是灾难性遗忘,代理因新数据覆盖旧的,但仍有价值的知识而失去关键的信息。当内存存储受到限制时,这个问题尤为突出,迫使代理选择性地保留信息。正在探索的解决方案包括经验重播,即定期回顾过去信息,以及记忆巩固技术,灵感来源于人类神经过程,旨在巩固关键学习。
感知
正如人类和动物依赖视觉、听觉和触觉等感官输入与周围环境互动一样,LLM-based代理通过处理多样化的数据来源来增强其理解和决策能力。多模态感知整合各种感官模式,丰富了代理的意识,使其能够执行更加复杂和上下文敏感的任务。
本节概述了关键输入类型——文本、视觉、听觉和新兴感官模式——使代理能够在范围广泛的环境和应用中进行操作。
文本输入
文本是LLM-based代理中知识交流和沟通的基础模态。尽管代理在语言能力上有了进步,但理解指令背后的含蓄或上下文含义仍然是研究领域。理解用户指令的微妙性,如信念、愿望和意图,使得代理需要超越字面解释,分辨潜在含义。
-
隐含理解:为了解释含蓄意义,通常会采用强化学习技术,使得代理能够根据反馈将响应与用户偏好对齐。这种方法使代理能够更好地处理模糊、间接请求和推断意图。
-
零样本和小样本能力:在现实场景中,代理经常遇到不熟悉的任务。经指令调整后的LLM表现出的零样本和小样本理解能力,使其能够在没有额外训练的情况下准确响应新任务。这些能力对适应用户特定上下文和不同的互动风格尤其有用。
视觉输入
视觉感知使代理能够解释物体、空间关系和场景,为其周围环境提供上下文信息。
-
图像到文本转换:处理视觉数据的简单方法是生成标题或描述,代理可将其视为文本。尽管有益,但该方法存在局限性,如保真度降低和潜在的细节视觉信息丢失。
-
基于转换器的编码:受自然语言处理转换器模型的启发,研究人员已调整相似架构,如 视觉转换器(ViT),将图像编码为与LLMs兼容的标记。这种方法允许代理以更结构化的方式处理视觉数据,从而更有效分析详细图像特征。
-
桥接工具:像 BLIP-2 和 InstructBLIP 的工具使用中间层(例如Q-Former)将视觉和文本模态桥接起来。这些模型通过将视觉数据与文本输入对齐,减少计算需求,缓解灾难性遗忘。对于视频输入,像 Flamingo 的工具通过采用掩蔽机制来维持时间一致性,能够帮助代理准确地解析随时间变化的序列。
听觉输入
听觉感知增强了代理的意识,使其能够处理声音、检测语音并对听觉提示作出响应。这种能力对于参与互动或高风险环境的代理至关重要,声音提供了关键的实时上下文。
-
语音识别和合成:通过工具使用能力的整合,基于LLM的代理可以利用专业音频模型。例如, AudioGPT 结合了诸如Whisper的语音识别和FastSpeech的文本到语音转换,使代理能够有效地处理语音到文本和反之的转换。
-
声谱图处理:一些方法将音频声谱图视作2D图像,允许使用视觉编码技术,如音频声谱变换器。这种方法利用现存的视觉处理架构,使代理更有效地解析听觉信号。
新兴输入模态
除了文本、视觉和音频之外,额外的感官输入正开始拓展基于LLM代理的互动能力,使其能够进行更丰富的环境感知行为。
-
触觉和环境传感器:代理可能融合温度、湿度和光亮度等触觉传感器。
-
手势和眼动追踪:技术如 InternGPT 使用户能够通过手势与图像互动,而眼动追踪和身体动作捕捉则扩展了代理解读复杂人类行为的能力。这些模态在增强现实和虚拟现实应用中尤其有前景,精确的用户输入提升了参与感和控制。
-
空间意识:利用激光雷达(Lidar)生成的三维点云,帮助代理检测物体并理解空间维度。结合GPS和惯性测量单元(IMU),代理能够获得实时对象跟踪能力,从而实现与移动实体的动态交互。有效将数据整合进LLM的高级对齐机制至关重要。
多模态感知中的研究挑战与考虑
虽然多模态感知增强了代理功能,但它也带来了一些研究挑战和技术考量:
-
数据对齐与集成:整合多样化的感官数据需要对齐机制,能够将文本、视觉和听觉输入有机地结合。模态之间的不对齐会导致感知和响应上的错误。研究人员正在探索诸如多模态变换器和交叉注意层等技术,以改善数据集成的无缝性。
-
可扩展性和效率:多模态处理显著提高了计算需求,特别是在处理高分辨率图像、视频帧和连续音频时,开发能够高效处理多模态数据的可扩展模型是当前的研究重点。
-
灾难性遗忘:正如内存系统一样,对于需要处理多输入类型的多模态代理,灾难性遗忘也是一种风险。检索必要信息的同时容纳新数据需要创新策略,例如优先重放和持续学习框架,以在不淹没模型的情况下保留关键感官知识。
-
上下文敏感的响应生成:生成恰当地反映多模态输入的响应是复杂的,因为代理必须根据上下文优先考虑相关的感官数据。例如,在拥挤的听觉环境中,声音线索可能要优先考虑,而在视觉重的场景中,空间数据可能更加关键。上下文驱动的响应生成仍然是一个活跃的研究领域,以提升代理的适应性。
推理与规划
推理与规划模块使人工智能代理能够通过将复杂任务分解为更小的、可管理的步骤来应对复杂问题,类似于人类应对复杂问题的方式。该模块增强了代理创建结构化计划的能力,可以通过事先形成全面计划或者根据新反馈实时调整。
在人工智能中,规划方法通常按使用的反馈类型和程度分类。一些代理在开始时构建完整计划,遵循单一路径或探索多个选项而不在执行过程中更改计划;其他代理在动态环境中操作,根据来自环境、人类或其他模型的反馈不断调整策略,从而实现持续改进和适应。
旁注:有一份有用的提示技术指南可在论文 The Prompt Report: A Systematic Survey of Prompting Techniques 中找到。
无反馈规划
在无反馈规划中,代理在开始时创建完整计划,并保持不变。这一方法包括单一路径和多路径两种方法。单一路径规划简单明确,每个步骤直接通向下一个步骤。多路径规划则同时探索不同选择,让代理选择最佳路径。这些策略帮助代理即使在没有调整的情况下,依然能始终如一并有效地完成任务。
单路径推理
单路径推理将任务分解为简单的、顺序的步骤。每个步骤直接通向下一个,类似于沿单一链条行进。
示例:
-
链式思维(Chain of Thought, CoT):通过提示LLM以少量示例来鼓励逐步解决问题。这种技术已被证明显示出显著提高模型输出质量,甚至与经过微调、特定应用模型相比。
-
零样本链式思维(Zero-Shot-CoT):在没有预定义示例的情况下,通过诸如“逐步思考”的提示启动逐步推理。这种方法与CoT表现相近,且更具普适性,适用于零样本学习。
-
重新提示(RePrompting):一种算法,通过使用问答对自动发现有效的CoT提示,无需人工输入。
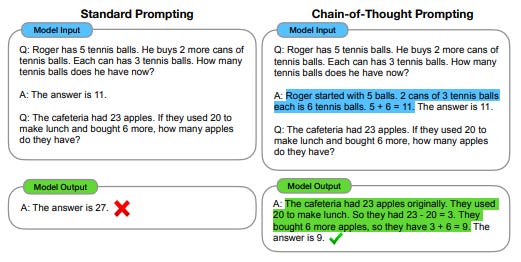 来自 CoT 论文
来自 CoT 论文
多路径推理
与单路径推理相反,多路径推理允许代理同时探索多个步骤,生成多个潜在解决方案并进行评估,以选择最佳路径。这种方法适用于复杂的问题解决,多个可能的方式存在时特别有效。
示例:
-
自一致链式思维(Self-consistent CoT, CoT-SC):通过从CoT提示的输出中采样生成多个推理路径,并选择出现频率最高的步骤。这种想法可以被认为是对单一模型的“自集成”。
-
思维树(Tree of Thoughts, ToT):将每个逻辑步骤存储在树结构中,使得语言模型可以评价每个“想法”如何贡献于解决方案。ToT可以使用诸如广度优先搜索(BFS)或深度优先搜索(DFS)等搜索启发式进行系统性导航。
-
思维图(Graph of Thoughts, GoT):将ToT概念展开到图结构中,将思维视为顶点,依赖视为边,允许更加灵活和相互关联的推理。
-
通过规划推理(Reasoning via Planning, RAP):使用蒙特卡罗树搜索(MCTS)模拟多个计划,LLM既充当代理(创建推理树),又充当世界模型(提供反馈和奖励)。
外部规划者
当LLM面临特定领域的规划挑战时,外部规划者提供专业支持,整合LLM可能缺乏的任务特定知识。
示例:
-
LLM+P:将任务转换为规划域定义语言(PDDL),并通过外部规划者解决这些任务。这种方法已经被证明能够使LLMs完成复杂任务,如通过将自然语言指令翻譯为可执行计划的机器人操作。
-
CO-LLM:这一方法涉及模型合作,通过逐个Token生成文本,生成的每个Token在模型之间交替选择。每一步哪个模型生成哪个Token被视为持续变量,而不根据步骤提供明确的注册,这使得每个任务的最佳协作模式从数据中自然产生,将规划责任根据需要委派给特定领域模型。
有反馈规划
有反馈规划使代理能够适应环境中的变化。当代理执行任务时,可以根据周围环境的新信息、人类互动或其他模型的反馈来调整自身计划。这种动态方法对于处理不可预测或复杂的场景至关重要,因为初始计划可能需要在执行过程中进行微调。
环境反馈
在代理与周围环境或虚拟环境交互时,可以根据来自对世界的感知的实时反馈调整计划。如果遇到障碍或不可预见的挑战,策划模块会修订其方法。这种响应能力帮助代理保持正常运行。
示例:
-
ReAct:结合推理轨迹和基于行动的提示,使得代理在与环境交互时能够创造高层的、可适应的计划。
-
描述、解释、计划和选择(DEPS):用于任务规划(例如,Minecraft控制器),DEPS在遇到错误时修订规划。当子目标未实现时,描述模块总结情况,解释模块识别错误,策划模块则修订并重试任务。
-
SayPlan:利用场景图和从模拟环境中转变的状态来完善其策略,确保对任务完成的更上下文敏感的方法。
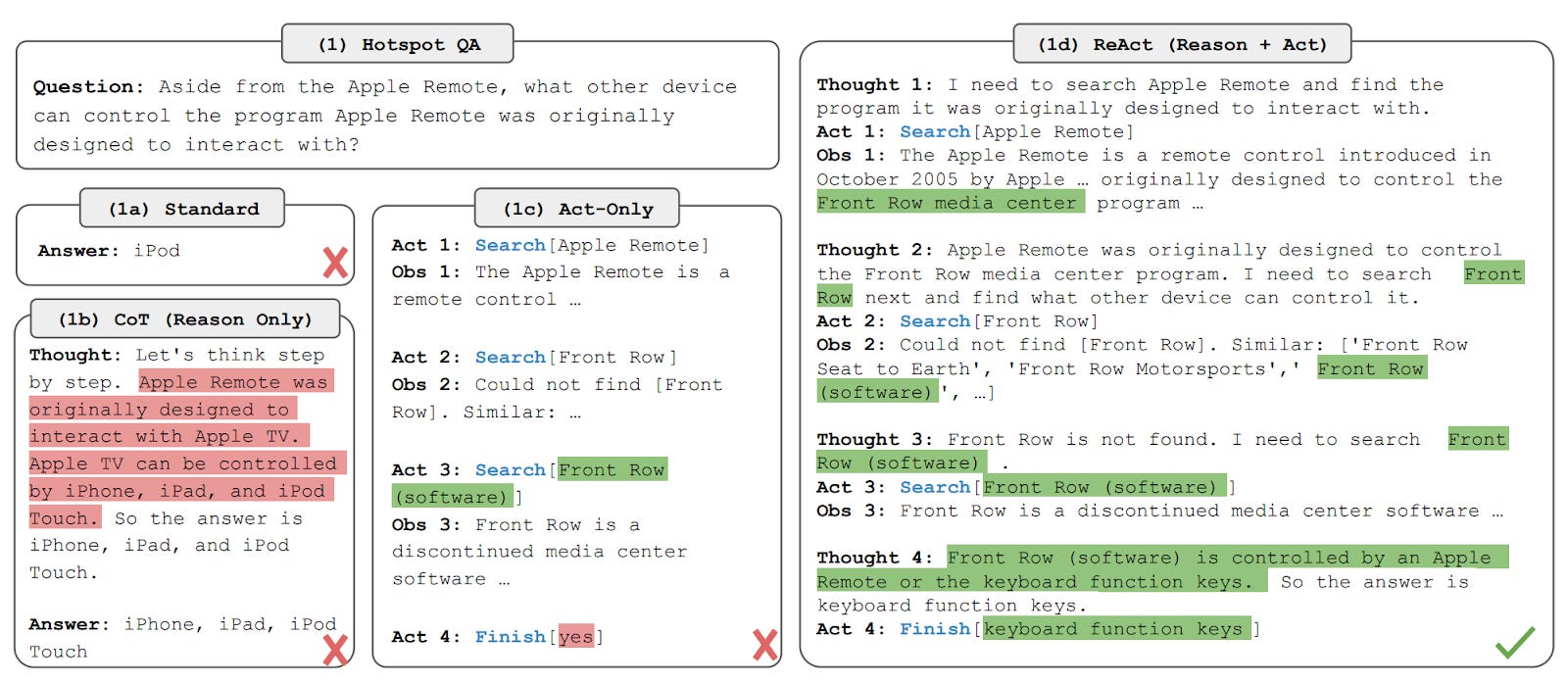 来自 ReAct 论文
来自 ReAct 论文
人类反馈
人类互动可以帮助代理对齐人类价值观,避免错误。
示例:
- 内心独白(Inner Monologue):收集场景描述并将人类反馈整合到代理的规划过程中,使代理的行动符合人类的预期。
模型反馈
来自预训练模型的内部反馈使得代理能够自我检查和完善其推理链和行动。
示例:
-
自检(SelfCheck):一种零样本逐步检查器,用于自我识别生成的推理链中的错误。SelfCheck利用LLM检查条件的正确性,基于前面的步骤,结果用于形成正确性估计。
-
反思(Reflexion):代理通过将反馈信号记录到情节记忆缓冲区,强化长期学习和错误更正,通过内部反思进行。
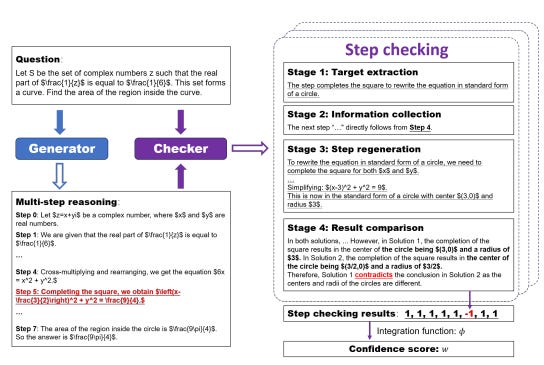 来自 SelfCheck 论文
来自 SelfCheck 论文
推理与规划中的挑战与研究方向
尽管推理和规划模块极大地提高了代理功能,但仍然存在若干挑战:
-
可扩展性与计算需求:多路径推理,特别是使用复杂方法如ToT或RAP,需要大量计算资源。确保这些规划技术能够高效扩展仍然是一个活跃的研究挑战。
-
反馈获得的复杂性:有效地整合来自动态或多来源环境的反馈是复杂的。设计能够优先考虑相关反馈,避免信息淹没的方法,是提高代理适应性而不牺牲性能的关键。
-
决策中的偏差:如果代理优先考虑某些反馈来源或路径,可能导致偏倚,造成歪斜或次优的决策。将偏倚缓解技术和多样的反馈来源结合进来对于实现均衡规划至关重要。
行动
行动模块是人工智能代理决策过程的最终阶段,其根据规划和内存执行行动以与环境互动并产生结果。此模块包括四个关键子类别:行动目标、行动生成、行动空间和行动影响。
行动目标
人工智能代理可以为多种目标行动。一些代表性示例包括:
-
任务完成:行动实现特定目标,如在Minecraft中制作工具或在软件开发中完成功能。
-
沟通:代理与人类或其他代理互动以分享信息。例如,ChatDev代理通过交流完成编程任务。
-
环境探索:代理探索新环境以获得见解,例如在Voyager中,代理试验和完善新技能。
行动生成
代理通过回忆内存或遵循计划生成行动:
-
基于内存的行动:代理利用存储的信息来指导决策。例如,生成代理在每个行动之前检索相关的记忆。
-
基于计划的行动:代理执行预定义计划,除非被干扰和信号中断。例如,DEPS代理遵循计划直至完成。
行动空间
行动空间分为两大类:内部知识与外部工具。
许多代理依赖于LLMs天生的能力,这一能力在基于LLM的实践中已经非常成功地基于LLM的预训练知识生成行动。但在某些区域中,代理可能需要依赖外部工具以实现行动。在这些情况下,代理也可以考虑使用API、数据库或外部模型:
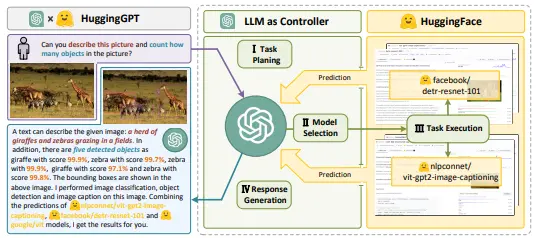
- API:例如,HuggingGPT 使用HuggingFace模型执行复杂任务。ToolFormer 利用LLMs将工具转换成新格式,而 RestGPT 则将代理连接到RESTful API进行现实世界应用。
- 外部模型:代理可能依靠超出API的模型处理专项任务。例如,ChemCrow 借助多个模型进行药物发现和材料设计,而 MemoryBank 则使用两种模型增强文本检索。
行动影响
行动的影响分类:
-
环境改变:行动可能直接改变环境。在 Voyager 和 GITM 中,代理通过收集资源或构建结构来修改其周围环境(例如,砍伐木材导致其从环境中消失并出现在库存中)。
-
自我影响:行动可以更新记忆、形成新计划或增加知识,正如在生成代理的记忆流中所见。
-
任务链连:某些行动引发其他行动,例如,Voyager在收集资源后才开始建造结构。
扩展行动空间
设计有效的人工智能代理不仅需要坚实的架构,还需要有效的特定任务技能与经验。这些“能力”可以被视为推动代理在各种场景下表现出色的“软件”。本节探讨两种主要策略:经过微调的能力获取和未经过微调的能力获取。
经过微调的能力获取
微调通过使用专门的数据集来调整模型参数,从而提升代理的性能。这些数据集可以来源于人类注释、LLM生成的数据或现实世界的收集。
使用人类注释数据集进行微调
这涉及到招募人类工作者为特定任务注释数据集。
示例:
-
RET-LLM : 微调LLMs以通过使用人类创建的“三元组-自然语言”对将自然语言转换为结构化内存。
-
EduChat : 增强LLMs的教育技能,使用涵盖教学、论文评估和情感支持场景的专家注释数据。
使用LLM生成的数据集进行微调
LLMs生成数据集,降低人类注释的成本。虽然并不完美,但这些数据集在生成成本较低时能够覆盖更多示例。最显著的例子是 ToolBench,它使用ChatGPT生成各种现实世界API使用说明,从而微调LLaMA,以改善工具执行效果。
使用现实世界数据集进行微调
代理使用从现实世界应用中收集的数据集进行训练。例如,MIND2WEB 微调LLMs,使用来自137个网站的2000多项开放性任务,提升其在订票和找电影等任务中的表现。作为另一个示例,SQL-PaLM 使用一个庞大的文本到SQL数据集(Spider),以便微调LLMs应对数据库查询任务。
未经过微调的能力获取
在微调不可行的场景中,代理可以通过 提示工程和 机制工程 来获取能力。
提示工程
提示工程通过巧妙设计提示来提高代理性能,引导LLM的行为。
示例:
-
链式思维(CoT) : 在提提示中引入中间推理步骤,使复杂问题得以解决。
-
社会AGI : 使用自我意识提示帮助代理使其交流与用户和听众的心理状态保持一致。
-
Retroformer : 在提示中整合对过去失败的反思,从而通过迭代的口头反馈提高未来决策质量。
机制工程
机制工程利用特定规则和机制,超越提示操作增强代理能力。以下是一些关键战略:
-
试错法:
-
描述、解释、计划和选择(DEPS) : 通过在执行过程中融入进程描述、自我解释的反馈来加强对LLM生成的计划的错误修正,并引入可训练的目标选择模块,对候选子目标进行排名,基于估计的完成步骤优化和修正计划。
-
RoCo : 代理基于环境检查(如碰撞检测)来调整其多机器人协作计划。
-
-
众包法:
- 争辩机制(Debate Mechanism) : 代理协同合作,迭代修正其解决方案,直到达成共识,通过群体智慧实现目标。
-
经验积累:
-
自驱动进化:- LMA3 : 通过支持已达成目标的重标记器、将高层目标分解为已掌握的子目标的目标生成器以及进行目标评估的奖励函数,LMA3使得代理能够在一个任务无关的文本环境中获取广泛的技能,而无需依赖手动编写的目标表示或预定义课程。
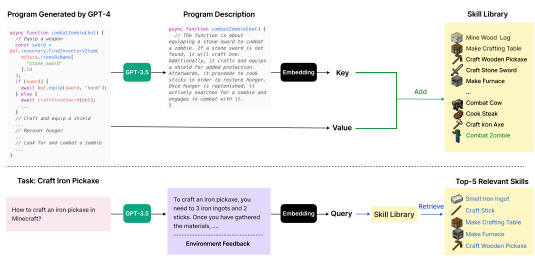 来自 Voyager 论文
来自 Voyager 论文
微调提供强大的任务特定性能提升,但需要开源模型并且资源密集。提示工程和机制工程均可与开源和闭源模型一起使用,但受限于输入上下文窗口,并且需要精心设计。
订阅
多代理架构

多代理架构将任务分配给多个代理,每个代理专注于问题的不同方面。这种设计允许多个代理独立朝着各自的目标工作,使用专业工具。
多代理系统在鲁棒性和适应性方面提供了显著的优势。代理之间的协作使它们能够互相提供反馈,从而改善整体执行并防止个别代理陷入困境。此外,这些系统可以动态调整,根据任务不断变化的需求分配或移除代理。
然而,这种架构面临协调挑战。代理之间有效的沟通至关重要,以确保重要信息不会丢失或被误解,因为每个代理只能对整体目标拥有部分知识。
纵向与横向组织
为了促进多个代理之间的交叉沟通和协调,研究主要集中在两种类型的组织结构上:横向和纵向。
在横向结构中,群组中的所有代理分享并细化各自的决策,群体决策通过将这些独立输入结合使用一个函数(如汇总或集成技术)形成。这种民主的方法在咨询或工具使用等多样输入有益的场景中效果良好。
相比之下,纵向结构则涉及一个层次化的过程,其中一个代理,“求解器”,提出一个初步解决方案,其他代理对此反馈。求解器根据这些反馈细化决策,直到达成共识或完成预设的修订次数。这种结构适合需要单一、精炼解决方案的任务,例如数学问题解决或软件开发。
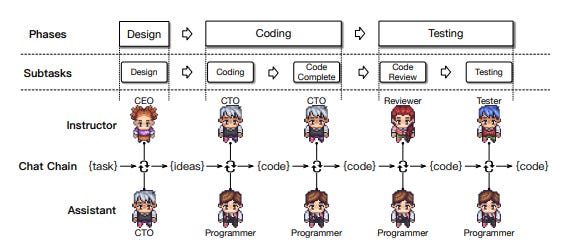 来自 ChatDev 论文
来自 ChatDev 论文
混合组织
另外,将纵向和横向结构组合成混合方法也是可能的,这在**DyLAN** 论文中得以体现。
DyLAN将代理组织成一个多层前馈网络,其中代理在同层级别进行互动。这一结构使它们能够在每一层内横向协作,并跨时间步交换信息,类似于横向协作架构,因为代理可以独立运行且与任务无关。
然而,DyLAN还引入了一个排名模型和一个代理重要性评分系统,在代理之间Creating a layer of hierarchy. 排名模型动态评估并选择最相关的代理(前k个代理)以继续协作,而表现较差的代理则被停用。这在横向协作框架内引入了纵向层次结构,因为更高层次的代理影响任务的完成和团队的组成。
合作多代理框架
除了层级结构外,多代理框架还可以被讨论为是合作的或对抗性的。
在合作多代理系统中,代理通过共享信息和调整行为以最大化效率进行协作。合作交互专注于每个代理的优点,确保它们彼此补充,以实现最佳结果。
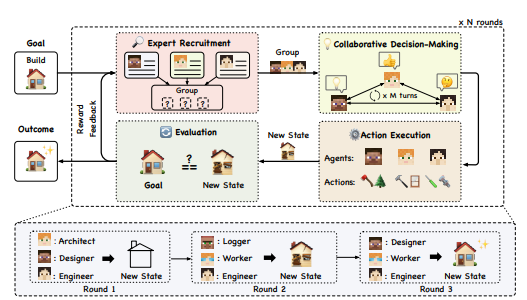 来自 Agentverse 论文
来自 Agentverse 论文
我们可以将合作交互分为两种关键类型:
无序合作
在无序合作中,多个代理不遵循固定的顺序或工作流程自由互动。这类似于头脑风暴会议,每个代理开放地提供反馈、意见和建议。像 ChatLLM这样的系统通过将代理建模为神经网络中的互联节点而展现了这种方法。每个代理处理来自其他代理的输入,并将信息传播出去,从而允许迭代完善然而,无序合作可能会变得混乱,因为大量反馈可能会对系统造成压倒性的影响。
为了解决这些挑战,框架通常会引入一个协调代理,负责整合输入和整理响应。在某些情况下,采用多数投票机制来帮助系统达成共识。尽管其潜力巨大,但无序合作需要高级策略以有效管理信息流并提取有意义的洞察。
有序合作
在有序合作中,代理按顺序互动,遵循结构化流程。每个代理只关注前一代理的输出,从而创建一个简化高效的通信渠道。这种模式在双代理系统中很常见,例如**CAMEL**,一个代理充当用户给出指令,另一个代理则作为提供解决方案的助手。通过遵循一系列定义的步骤,有序合作确保迅速完成任务并最大程度地减少混淆。
这种方法与软件开发方法论密切相关,其中任务通过不同阶段逐步推进。像**MetaGPT这样的框架遵循瀑布模型,代理的输入和输出被标准化为工程文档。这种结构减少了歧义,确保任务的系统性完成。然而,即便是在有序系统中,缺乏适当约束也可能导致小错误(如幻觉)的放大,从而导致不良结果。结合交叉验证**或及时的人类干预帮助预防这些陷阱。
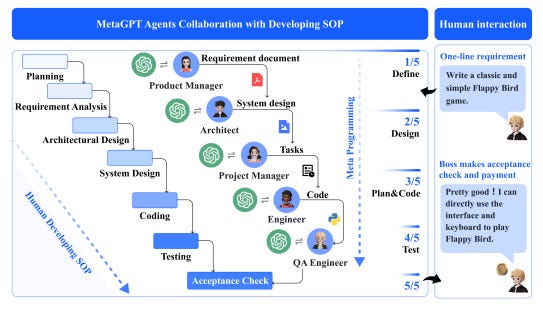 来自 MetaGPT 论文
来自 MetaGPT 论文
对抗性多代理框架
虽然合作方法提供效率和协同效应,但对抗性框架却引入了竞争的边缘,挑战代理,推动其演变。受到博弈论的启发,对抗性交互允许代理参与辩论和竞争任务。这种方法促进了适应性,鼓励代理通过不断的反馈和批判性反思来完善其行为。
对抗性系统的一个典型例子是强强化学习代理**AlphaGo Zero,它通过自我对弈获得突破,随着每次迭代精炼策略。同样,针对 LLM 的对抗性多代理系统利用辩论提高输出。在这种环境中,代理表达竞争性论点,进行“以牙还牙”的交流。这种方式揭示了推理中的缺陷。例如,ChatEval**利用多个代理相互批评各自的输出,确保评估水平与人类审稿人相当。
这些辩论迫使代理放弃僵化的假设,通过深思熟虑的发展出更细致的回应。然而,对抗性模型引入了独特的挑战,例如增加计算开销和代理收敛于错误结论的风险。没有适当的保护措施,竞争性交互可能会在多个代理中放大小错误,使得达成可靠的结果变得困难。
多代理系统中的浮现行为
有趣的是, AgentVerse 论文描述了在多代理组织中观察到的浮现行为。
志愿者行为 表现为代理愿意超出分配任务贡献额外的时间、资源或帮助。例如,代理可能在早期完成任务并主动帮助他人,而不是闲坐。这种“时间贡献”可以通过动态分享努力加速任务的完成。代理还经常表现出“资源贡献”,在与同事分享物品或资源时促进集体进展。此外,代理表现出“援助贡献”,帮助在特定任务上挣扎的其他代理,使团队能够朝着共同目标有序推进。
一致性行为则表现为代理调整行动以对齐团队目标。例如,如果一个代理偏离其任务,其他代理可能会提供反馈或信号,督促它重新聚焦。这种行为增强了合作,确保所有代理保持与团队目标一致,类似于在人类群体中的社会规范。一致性行为提升了任务结果的稳定性,因为代理不断调整其行动以与团队不断变化的目标同步,并在系统中保持一致性。
破坏性行为虽然不那么频繁,但在代理追求捷径或采取激烈行动以实现任务完成时也会出现。这些行为包括为了获取资源而伤害其他代理或攻击环境,例如在 Minecraft 中破坏村庄图书馆以获取书籍,而不是制作书籍。破坏性行为通常源于在限制条件下最大化效率的尝试,高亮显示类似行为在现实应用中的潜在安全隐患。识别和减少破坏性行为至关重要,因为它们可能破坏群体稳定性并对工作与人类代理同行的场景造成风险。
后续我们还将讨论生成代理论文,该论文展示了其他在社会模拟期间的浮现社会行为。
基准测试与评估
基准测试对于评估自主代理和多代理系统的性能和有效性至关重要。随着 LLM 和自主代理的进步,基准允许研究人员在多个领域测试这些系统,使用标准化的指标和协议测量关键特征如推理、协作、安全、社会意识和适应性。有效的基准提供了对代理优缺点的关键见解,指导它们的开发和完善。本节强调了一些用于评估基于 LLM 代理的显著基准和框架。
核心能力的模拟环境
模拟环境是最流行的基准之一,提供了受控环境以测试代理交互、规划和任务表现。平台如下所示:
-
ALFWorld、IGLU 和 Minecraft 使代理能够参与模拟环境,帮助研究人员评估其解决问题和互动的能力。
-
Tachikuma 使用桌面角色扮演游戏 (TRPG) 的游戏日志来评估代理推断角色与物体之间复杂交互的能力,从而为推理和创造力提供了现实测试。
-
AgentBench 引入了一个全面框架,用于在现实场景中测试基于 LLM 的代理,成为评估 LLM 在多种环境中表现的第一个系统基准。
社会能力与沟通评估
一些基准评估代理的社会能力,侧重于理解情感、幽默、可信度和更细致的人类样互动能力:
-
SocKET 对 58 个社会任务中的 LLM 进行评估,测量代理对情感、幽默和社会线索的理解。
-
EmotionBench 考察代理对特定情境的情感反应能力。它收集超过 400 个场景,比较代理和人类的情感反应。
-
RocoBench 在合作机器人中测试代理的多代理合作,重点关注沟通和协调策略。
工具使用与特定问题基准
其他基准侧重于工具使用和专业问题解决环境,帮助评估代理适应现实挑战的能力:
-
ToolBench 提供一个开放源代码的平台以支持具有通用工具使用能力的 LLM 的开发,评估它们学习和部署工具的有效性。
-
GentBench 评估代理如何使用工具解决复杂任务,关注推理、安全性和效率。
-
WebShop 测量代理执行产品搜索和检索的能力,使用一个包含 118 万个真实物品的数据集。
-
Mobile-Env 提供一个可扩展的环境以评估代理进行多步交互的能力,测试记忆和规划。
端到端和专业基准
一些框架评估代理在端到端场景或特定利基应用中的完整性能:
-
WebArena 提供一个复杂的多领域环境,以评估代理的端到端任务完成和准确性。
-
ClemBench 通过对话游戏测试 LLM,评估其在作为积极参与者的决策和会话能力。
-
PEB 专注于代理在渗透测试场景中的表现,反映现实挑战,涵盖 13 个不同目标及其难度。
-
E2E 提供端到端基准以评估聊天机器人,测试其准确性及其响应的实用性。
客观与主观评估
客观基准提供系统测量代理性能和能力的量化指标,为改进提供了重要见解。然而,主观评估——如人类对互动质量的评价——通过捕捉数字无法测量的细微差异来补充这些指标。结合客观与主观策略确保对代理的全面评估,同时考虑绩效和用户体验。
应用
在接下来的部分中,我们将探讨支持基于 LLM 代理广泛应用的研究。虽然这不是一个详尽的调查——鉴于潜在使用案例数量庞大——但它旨在提供足够的背景以展示这一技术的广泛适用性。
游戏
\ 本节我们将主要参考 基于大型语言模型的游戏代理调查 和 大型语言模型与游戏:调查与路线图 \
体现意识假说 从人类婴儿智能的发展中寻求灵感。它提出,代理的智能通过观察和与环境的互动而涌现。为了促进类人智能的发展,代理必须沉浸在一个整合了身体、社交和语言体验的世界中。
数字游戏被视为理想的人工智能代理训练场,因为它们提供了复杂性、多样性、可控性、安全性和可重复性——这些都是实验和开发的重要元素。从经典游戏如棋类和扑克到更现代的视频游戏(如星际争霸 II、Minecraft 和 DOTA II),都在推动人工智能研究的边界上发挥了重要作用。
虽然 RL 代理专注于通过以行为驱动的策略最大化奖励,基于 LLM 的游戏代理旨在利用认知能力深入洞察游戏玩法。这种认知方法与追求 AGI 的长期追求更为一致,因为它重视更复杂的推理而非简单的奖励优化。
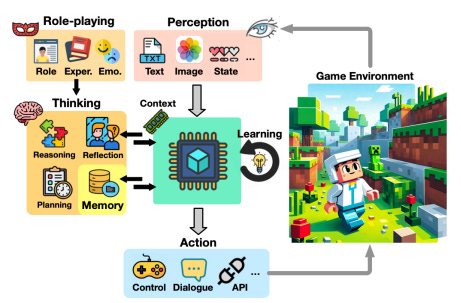 来自 《基于大型语言模型的游戏代理调查》 论文
来自 《基于大型语言模型的游戏代理调查》 论文
游戏中的代理感知
对于视频游戏,感知模块在使代理能够感知游戏状态方面发挥了关键作用。将感知模块映射到游戏的三种主要方式如下:
状态变量访问
某些游戏环境提供内部 API 以访问符号状态变量(例如,一个宝可梦的种类、状态或招式),这消除了对视觉信息的需求。Minecraft 的 Mineflayer API 例如,允许访问方块位置和库存等元素。然而,这种符号方式对于丰富的视觉元素的游戏(如荒野大镖客 2 或 星际争霸 II)可能具有限制,因为视觉对于理解游戏玩法至关重要。
外部视觉编码器
当游戏没有 API 提供状态数据时,视觉编码器帮助将视觉输入转换为文本。CLIP 等工具识别物体并生成描述,帮助人工智能系统理解游戏环境。例如,MineCLIP 针对 Minecraft 和 ClipCap 用于生成简短的文本序列,可作为更大语言模型(例如 GPT-2)的输入。
多模态语言模型
然而,视觉编码器对新情况或未见情境的应对能力较弱,因为它们依赖于预定义描述。MLLMs(如 GPT-4V)通过将视觉和文本数据集成到一个统一模型中改善了泛化能力。这些模型在 Doom、RDR2 和 Minecraft 等游戏中用于决策。然而,它们通常需要环境的错误修正来完善输出。一些特定于游戏的 MLLMs,比如**GATO** 或 SteveEye,通过多模态指导进行学习,而其他模型,如**Octopus**,则通过具有反馈的强化学习进行改进。
游戏代理案例研究
与其直接调查各种游戏类型,不如通过特定示例评估基于代理的玩法类型。
Cradle(冒险)
冒险游戏是一种叙事驱动的体验,玩家通过解决难题、探索环境和与角色互动以推动故事进展。这些游戏通常需要玩家理解复杂的对话、管理库存、根据上下文线索做出决策,并在开放或半开放的世界中导航。
对于基于 LLM 的代理,冒险游戏呈现出几个挑战:
-
上下文理解:代理必须解读细致入微的故事情节、角色动机和游戏背景,缺乏深刻叙事理解时这一过程会比较困难。
-
谜题和逻辑:许多谜题要求创造性问题解决、模式识别或理解隐藏连接,这可能不符合 LLM 的文本推理。
-
探索与视觉输入:开放环境要求空间意识和视觉解释,这对 LLM 来说困难,除非有高级多模态能力的支持。
-
处理模糊性:冒险游戏中通常有开放的任务或选择,要求代理处理不确定性并选择有意义的行动。
-
库存和状态管理:在时间上跟踪物品、任务进展和角色互动增加了复杂性,可能使基于 LLM 系统的记忆和规划能力受到压力。
这些方面使得没有强而有力的多模态支持、动态记忆和决策能力,LLM 代理在冒险游戏中导航困难重重。
已经有多个尝试针对复杂冒险游戏开发代理,但一个显著的限制是依赖于通过 API 访问状态变量和预定义的语义动作,这限制了通用性。此外,像 SIMA 这样的原则,其训练具身代理在 10 个不同的 3D 视频游戏中完成 10 秒的任务,依赖于人类专家的游戏数据进行行为克隆,因此扩展成本显著。
因此,通用代理的圣杯是通用计算控制(GCC)。通过 GCC,代理理论上可以通过接收屏幕和音频输入以及输出键盘和鼠标操作来掌握任何计算任务。相较于其他研究方法,GCC 是一种改进,像本体只能操作 HTML 代码和 DOM 树的网页代理,或者通常依赖于屏幕快照作为输入并提供可用 API 的多模态代理,限制了其通用性。
Cradle 是一个努力通过基于 LLM 的代理实现 GCC 的具体框架。在不加深框架具体细节的情况下,GCC 最显著的组成部分是在行动生成阶段,使用 LLM 生成代码以弥合语义动作与操作系统级动作(如键盘和鼠标控制)之间的分歧。
Cradle 是第一个展示能在《荒野大镖客 2》中完成 40 分钟故事任务的代理框架,还能在《城市:天际线》中创建一个拥有 1000 人的城市,在《星露谷物语》中种植和收获大头菜,以及在《经销商的生活 2》中每周交易利润达到 87%。此外,它能够正常运行代码如 Chrome、Outlook 和 CapCut。
尽管这些成就是基于 LLM 的代理的确令人印象深刻,但仍然存在挑战。例如,在 RDR2 中实时战斗任务和物品搜索任务,由于 GPT4-0 的空间感知能力较差,受到限制。
CICERO(沟通)
沟通游戏强调心理操控、策略、协作、信任和欺骗是核心机制。它们非常适合测试玩家的战略组织能力、洞察他人、建立联盟,有时甚至是背叛他们。
使用自我对弈的强化学习代理已经在两人零和游戏中收敛出最佳表现。然而,一旦一个游戏涉及合作,自我对弈无法融合人类数据即可无法收敛以达到最佳表现,因其不理解人类规范和期望。人类可解释的沟通是必要的,任何困惑都可能导致人类玩家拒绝与代理合作。此外,许多沟通游戏在敌对环境中涉及建立信任,这意味着任何成功的代理都需要能剖析阴险,并保持对其他玩家目标的信念。
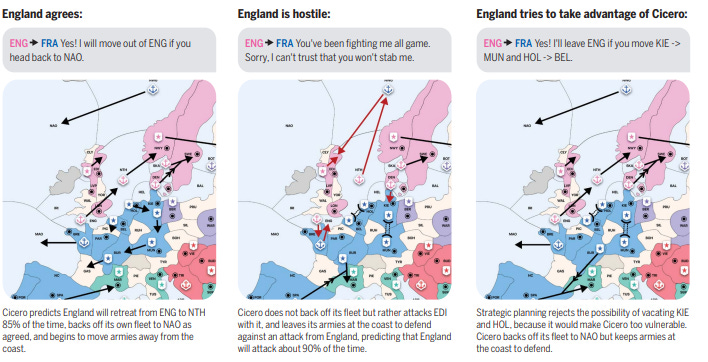
CICERO 是 Meta AI 为策略游戏《外交》开发的 AI。与专注于战术的游戏不同,《外交》要求玩家进行谈判、建立联盟并在不揭示真实意图的情况下作出战略决策。CICERO 将战略推理与自然语言处理结合,能与人类玩家进行复杂互动。
CICERO 的架构将棋盘状态和其他玩家的对话作为其推理和规划模块的基础状态。该模块负责识别其他玩家的意图,这一信念在新动作上棋盘不断更新,并接收来的消息。意图模型自身是在诚实游戏上训练的,因此对模型的偏离可以强化对玩家不真诚言辞的信念。
在由 40 场匿名游戏组成的在线联赛中,CICERO 的平均人分数翻倍,能够排入前10%参与者。玩家常常偏好与 CICERO 合作,却未意识到自己正在与 AI 互动,这在很大程度上归功于其合作与战略能力。
PokéLLMon(竞争)
竞争游戏作为推理和规划性能的基准由于遵循严格规则而适宜测量在人类玩家中的胜率。
各种代理框架已经表现出竞争性玩法。例如,在 大型语言模型玩星际争霸 II:基准测试与链状总结的方式 的研究中,基于 LMM 的代理在使用链状总结法的推理模块下,分别与内置 AI 在纯文本版本的星际争霸 II 中进行较量。
PokéLLMon 是首个在战术游戏《宝可梦》中达到与人类相同表现的基于 LLM 代理,赢得了 49% 的天梯比赛胜率和 56% 的邀请战胜率。它是一个值得一提的例子,因为它展现了通过知识增强生成和一致性动作生成来控制幻觉,避免了因思维链导致的惊慌循环。
该框架将战斗服务器的状态日志转换为文本描述。描述魅力包括当前团队状态的关键信息、对手团队(可视情况)以及战场状况(如天气与风险)及历史回合的日志。这种模块化表现帮助代理以结构化文本输入的序列形式感知游戏的演变状态,确保回合之间的一致性,并实现基于记忆的推理。
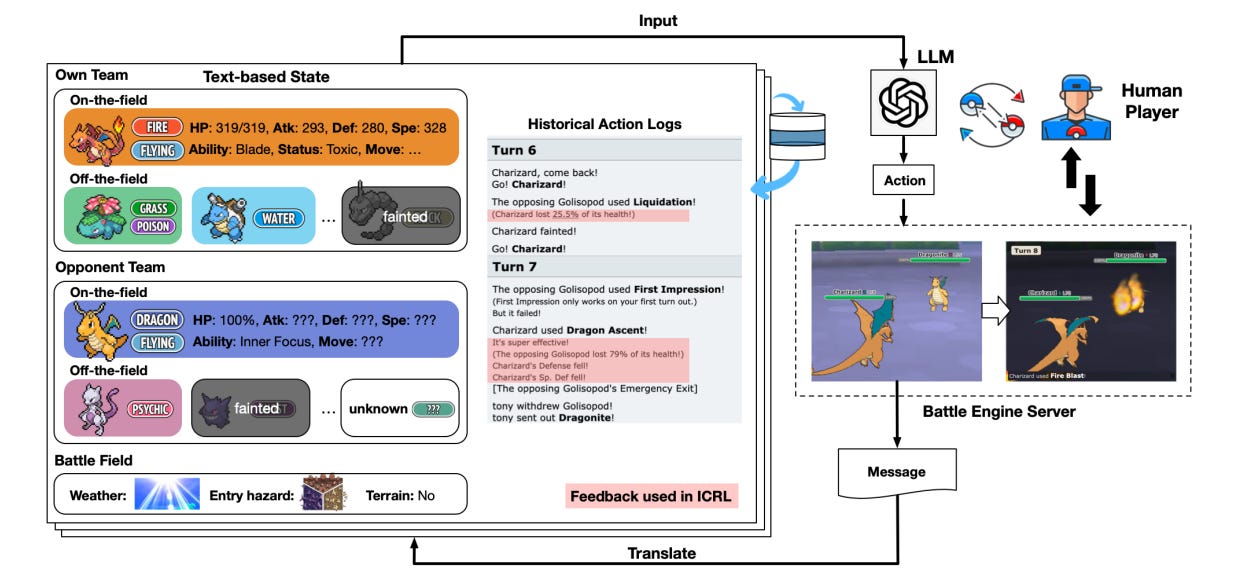
此外,代理依赖四种反馈以提供语境中的强化学习:血量变化、招式有效性、移动顺序的粗略速度估计和招式状态效果。这种反馈使代理能够细化计划,并避免在使用无效招式时陷入循环。
PokéLLMon 还利用知识增强生成从 Bulbapedia 等来源获取外部知识。这种外部知识包括类型优劣和招式效果,帮助代理在合适的时候使用特殊招式。
最后,作者评估了 CoT、自我一致性和 ToT 以改善一致性动作生成。通过这一分析,他们发现自我一致性显著提高了胜率。
ProAgent(合作)
合作游戏要求玩家通过理解伙伴的意图以及从他们的行动历史推测其后续行动有效协作。这需要玩家之间成功的沟通,或者维持心智理论。
换句话说,合作可能包含显性与隐性两种方式。显性合作涉及代理之间直接通信以交换信息,而隐性合作则是无直接沟通而内部模拟伙伴策略以预测其行动。显性方法虽然提供更高的协调效率,但可能降低了系统灵活性。
一个成功合作的示例测试环境是《同煮》,其玩家在时间紧迫且动态的环境中一起工作制作餐食。使用简化版游戏称作 Overcooked-AI,ProAgent 展现了能够通过隐性合作与队友和环境自适应互动的代理。
核心过程包括五个阶段: (1) 知识库与状态基础,在此阶段收集任务特定知识并转换为基于语言的描述;(2) 技能规划,允许代理推测队友意图并提炼适当行动;(3) 信念修正,用于随时间持续校正对队友行为的理解; (4) 技能验证与行动执行,通过迭代规划与验证确保选择的行动有效;(5) 记忆存储,代理记录交互及结果,以指导未来的决策。
特别感兴趣的是信念修正机制。此机制确保代理随着交互进展持续更新对队友意图的理解。由于代理可能最初误解其伙伴的目标,信念修正允许进行迭代微调,修正预判并确保更有效对齐观察到的行为。当代理不断调整其行动以契合队友的变化意图时,会将决策错误降至最低。
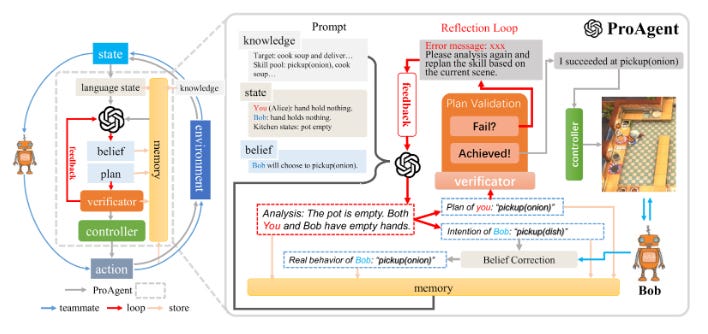
ProAgent 在五种自我博弈方法和基于群体训练的方法中表现优于。
生成代理(模拟)
虚拟角色如何能反映人类行为的深度与复杂性?数十年来,研究人员一直在追求创造可信的数字代理——这些代理能够以类人方式行动、反应和互动。 从早期项目《模拟人生》到最新的人机交互进展,构建这些代理一直是一个挑战,因为人类行为不可预测。最近在 LLM 中的突破打开了新的大门,但创造能够记住、适应的代理并在时间上保持一致的行为需要创新架构解决方案。
这一议程的根源可以追溯到早期的 AI 系统 SHRDLU 和 ELIZA,这些系统探索自然语言互动但在一致性和复杂性方面存在困难。虽然基于规则的方法如有限状态机和行为树在《质量效应》和《模拟人生》等游戏中变得流行,但它们需要大量手动脚本编写,从而限制灵活性。强化学习在竞争性游戏(如Dota 2)中取得了一些进展,但这些模式在狭窄的、以奖励驱动的环境中表现优秀,而在应对现实世界社交互动的开放性质时则面临挑战。
基于 LLM 的代理旨在通过将 LLM 与多层次架构结合,解决这些限制。这一架构使代理能够存储长期记忆,回顾过去事件以获取有意义的启示,并用这些反思指导未来行为。通过动态地检索相关信息,这些代理能够在交互中保持连贯,并能够适应意外的变化。
在论文《生成代理:人类行为的互动模拟》中,研究人员发现基于 LLM 的代理不仅能在虚拟沙盒中模拟逼真的人类行为,还展现出浮现能力。尤其是在实验中,研究人员观察到代理们传播信息、形成复杂的社会关系,并相互协调。
 来自《大型语言模型代理的崛起与潜力:一项调查》
来自《大型语言模型代理的崛起与潜力:一项调查》
论文中描述的架构将感知与记忆提取、反思、规划和反应相结合。记忆模块处理代理所做的自然语言观察流,并根据新近性、重要性和与当前情况相关性对它们进行评估。这些因素生成一个分数,在回忆阶段得以规范并利用。此外,反思(针对代理基于100个最新记忆日志的三大最突出问题所衍生的高层次抽象思考)在提取时也保持考量。这些反思为代理提供了对关系和计划的更为广泛的见解。最终,推理与规划模块的运作与论文中讨论的计划-行动循环相似。
论文特别关注信息传播在情人节派对和市长选举期间的情况。在为期两天的模拟中,信息在代理之间有机传播,对特定代理市长候选资格的知晓程度从 4% 增长到 32%,而关于情人节派对的知识从 4% 增长至 52%。没有关于这些事件的虚假声明或幻觉被观察到。代理们还形成了新的社会联系,网络密度从 0.167 增长至 0.74,虚假信息的参与仅占 1.3%。
代理们为派对进行协调,派对主持人组织邀请、材料和装饰。在情人节,12 个受邀代理中有 5 个参加了活动,采访那七位未参加的代理揭示出个人冲突或尽管满意但缺乏可靠性的承诺。
该模拟展示了信息共享和社会协调如何可以在代理社区内部在没有外部指导的情况下自然而然浮现。此外,这揭示了模拟游戏和社会科学实验的未来可能性。
Voyager(制作与探索)
制作与探索游戏通常将程序生成的世界与复杂的基于资源的制作系统相结合,并且有时还涉及生存系统。Minecraft 是最受关注的代理游戏环境,完美体现了这一概念。
在这项研究中,Minecraft 代理可以被视为具有两种类型的目标:执行制作指令或基于自我确定目标的自主探索。制作任务需要在地图上收集多种材料,理解可用配方,并创建和遵循顺序步骤。许多制作代理设计依赖于 LLM 规划和目标任务分解与反馈。DEPS、GITM、JARVIS-1、Plan4MC、RL-GPT 和 S-agents 都遵循这种设计的不同变体。
关于自主探索目标,我们看到代理框架利用课程学习来识别适合的任务,并使用 LLM 作为目标生成器。这其中最有趣的例子是 Voyager,一个在 Minecraft 中独立的终身学习代理。Voyager 有三个关键组成部分:1)自动课程,2)可执行代码的技能库,和3)通过反馈、执行错误和自我验证的迭代提示机制。
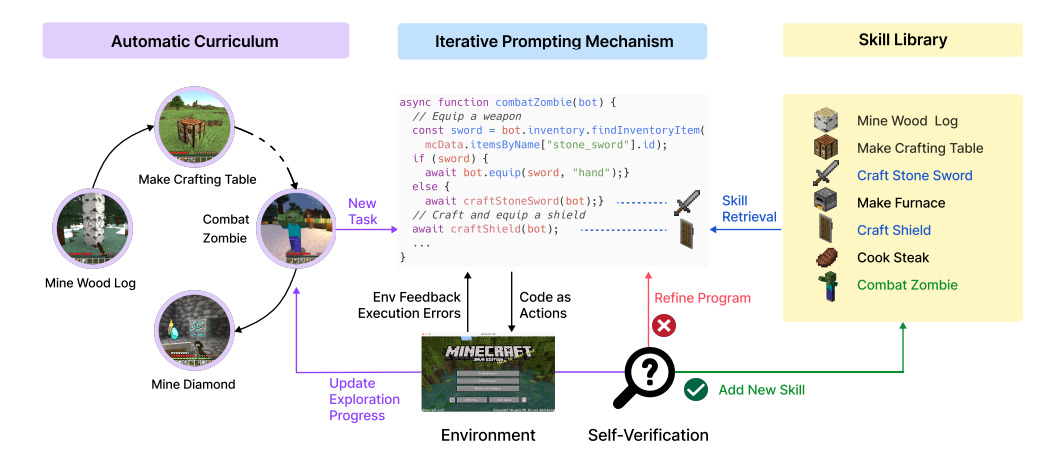
自动课程利用 LLM 的内在知识生成考虑代理当前状态和探索进展的目标。这导致代理需要执行一系列不断复杂化的任务。
作为自动课程的一部分,代理会生成通用且模块化的代码以适应特定技能,例如“制作一个铁镐”。代理然后使用代码尝试完成目标,并通过链状思维提示将环境反馈传递回 LLM 以确认成功与否,并在必要时进行更改。如果成功,代码将被存入技能库以供将来使用。
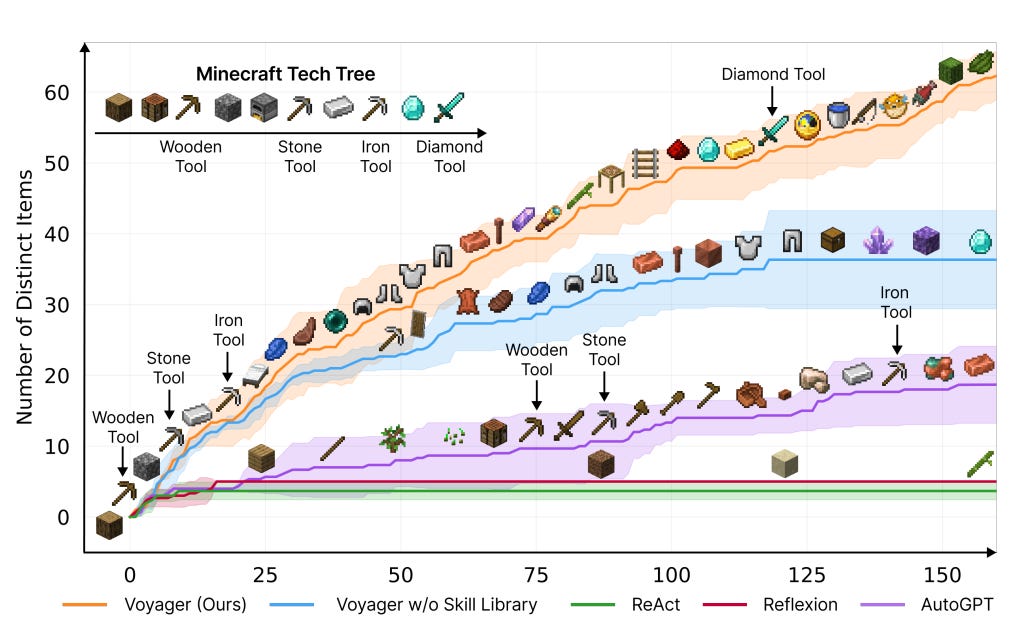
Voyager 框架在技术树的掌握上取得稳定成果,分别比基线快 15.3 倍、8.5 倍和 6.4 倍地解锁木材、石材和铁。同时,作为分析对比的唯一框架,Voyager 成功解锁了钻石等级。此外,Voyager 的探测距离是基线的 2.3 倍,并发现了 3.3 倍的创新物品,展示了其作为终身学习代理的能力。
游戏中的推测应用
根据这项研究,可以预计未来游戏中将会出现多种推测性应用。以下是一些想法的简要汇总,但并不详尽:
代理驱动的游戏与策略
-
多代理模拟游戏:为 AI 驱动的角色在日常生活中自动导航提供目标,孕育出浮现游戏玩法。
-
策略游戏中的代理单元:智能代理在族群或单位中自主适应环境与敌方策略,根据玩家目标执行战术决策。
-
AI 培训场:玩家设计和训练 AI 代理以应对生存、战斗或探险自动化的任务,利用强化或模仿学习。
AI 驱动的 NPC 和世界动态
-
开放世界中的 AI 驱动 NPC:基于 LLM 的 NPC 计算和政治驱动社会动态,塑造沉浸式的演变世界。
-
现实的 NPC 对话:上下文智能化的生动对话与人与玩家的关系增强社会互动。
-
自主虚拟生态系统:AI 驱动的生动虚拟世界有着自我演变的人口、经济与生态,能对玩家的行动作出响应,即便在离线。
-
动态事件管理:代理协调实时事件与惊喜,使在线或直播服务游戏中增强参与感。
动态叙事与叙事设计
-
自适应游戏大师:LLM 代理在角色扮演游戏中创作个性化叙事、任务与即兴挑战。
-
个性化叙事:代理生成响应玩家选择的自适应背景与叙事,带来无尽的可重玩性。
玩家支持与陪伴
-
玩家伙伴与助手:游戏中的顾问或伙伴提供上下文提示、跟踪目标,并通过互动角色增强沉浸感。
-
合作性问题解决:代理在解谜或悬疑游戏中充当队友或对手,依据多样问题解决风格增加深度。
-
情感响应 AI:代理根据玩家的情感做出反应,促进在叙事驱动或治疗游戏中的同理性或支持性互动。
教育与创造
-
AI 竞争者与训练者:电子竞技和训练模拟中的高级对手能够根据玩家策略自适应以促进技能发展。
-
教育与培训游戏:自适应代理担任互动导师,依据技能水平定制内容提供个性化学习。
-
模组与内容创造协助: LLM 代理帮助创建游戏内容,从自然语言提示中即可变化,处理模组和设计。
加密 / 财务
传统金融系统缺乏灵活性,无法有效地让自主代理管理和控制资产。区块链技术为这些代理提供了理想的基础,使它们能够自动操作钱包、执行交易,并与去中心化金融(DeFi)协议互动。
此外,加密的开源和模块化特性促进了创新且可扩展性应用,增强了代理能力,前所未有。本节探讨了代理与加密集成的前沿研究。
代理控制的钱包架构
控制钱包的代理需要特定机制来管理密钥、与区块链应用互动并维护安全。为了帮助那些不熟悉加密钱包的人,简要说明:基本上,钱包分为两种类型。**EOAs (Externally Owned Accounts)**是需要人为看管私钥的传统钱包。这对于代理来说可能会带来挑战,因为在交互时需完成手动签名。另一方面,智能合约钱包更加灵活且自主,因为这些钱包允许使用多签名机制、阈值签名或能够被代理利用的智能合约控制。重要的是,像 ERC-4337 这样的帐户抽象协议使代理能够使用具备可编程权限和逻辑嵌入的钱包智能帐户,从而减少对 EOAs 的依赖。
市场上最流行的链上智能合约钱包之一是 Safe,并且已经有将代理与 Safe 直接连接的实验。例如,在 AI Agents That Can Bank Themselves Using Blockchains中,Syndicate 的交易云 API 被用来提供一个代理的发送和获取事务的请求,这个代理可以作为其行动空间的一部分被调用。然而,在链上创建自主代理的主要挑战不是在于执行动作,而是在于私钥的管理。潜在的解决方案包括使用多方计算 (Multi-Party Computation, MPC),它将密钥监护分散到多个参与者之间,或可信执行环境 (Trusted Execution Environments)。对于前者,一个突出的例子是 Coinbase Developer Platform ,它推出了基于AI的代理和链上基础工具包,以创建可以轻松分叉的自主AI代理模板,这些代理通过MPC拥有自己的钱包。这些代理可以在链上交易,并实时查看区块数据。至于后者,Nous Research 的一名团队成员最近 探讨了通过使用可信执行环境,代理执行社交媒体和私钥访问的安全性,其中凭证在TEE内生成并时间锁定。
已验证的代理推断
区块链领域一个突出的研究领域是链外验证,这主要由于直接在链上运行高复杂度计算的计算挑战。现有研究主要集中在使用零知识证明 (zero-knowledge proofs)、乐观验证 (optimistic verification)、可信执行环境和加密经济博弈理论方法。该研究的一个应用领域是机器学习,特别是 零知识机器学习 (zkML) 和 Ora Protocol 的 乐观机器学习 (opML) 。
这里与代理的交集在于通过链上验证器验证代理的输出,以此将代理推断引入智能合约。这使得代理能够在用户或应用程序之外运行,同时对其执行有保证,使得使用分布式代理作为结算、解决、意图管理等手段成为可行,并将确认的推断类似于去中心化预言机操作地置于区块链上。
关于各种验证方法及其优缺点的讨论超出了本文的范围,但一个有趣的可验证代理示例(尽管是一个棋类代理而不是基于LLM的代理)是 Modulus Labs 的 Leela 与世界对弈。这是一项实验,其中 Leela 棋引擎的走法通过零知识电路在链上得以验证。玩家共同决定人类的走法,以便与AI竞争,同时对结果进行投注,结合了预测市场和可验证AI输出。
密码学代理编排
使用独立操作LLM或代理的分布式节点体系使得具有共识的多代理系统成为可能。这方面的一个例子是 Ritual 。在他们的演示应用Frenrug中,一个人类玩家与一个代理谈判以购买他们的Friend.tech密钥。每个用户消息都被发送到多个由不同节点运行的LLM。这些节点在链上回应,给出基于LLM生成的关于代理是否应购买提议密钥的投票。当足够多的节点响应时,投票聚合发生,监督分类器模型确定行动,并将有效性证明转发到链上。
另一种代理编排的例子是 Naptha ,这是一个代理编排协议,具有链上任务市场,用于承包代理、操作者节点以编排任务、支持节点之间异步消息传递的LLM工作流编排引擎,以及用于验证执行的工作流证明系统。
最后,去中心化AI预言机网络,如 Ora Protocol,也可以从技术上支持这一用例。由于验证者已经在运行推断和验证任务的模型,乐观预言机框架可以适应允许多个代理在分布式环境中运行,增加一些额外的共识以支持链上多代理系统。
然而,这是一个简单的例子。通过区块链共识协调的分布式多代理系统可以为本文所提到的许多其他用例提供动力。
ELIZA 框架
关于专门针对区块链的代理框架,ai16z 的 Eliza 是一个多功能的开源多代理框架,旨在创建、部署和管理自主AI代理,可以说是加密领域增长最快的代理框架。它完全用TypeScript构建,提供了一个模块化和可扩展的平台,用于开发智能代理,保持一致的个性和知识,同时在各种平台之间无缝互动。Eliza的多代理架构允许同时管理多个独特的AI个性,得益于一个角色框架,使得创建多样化的代理成为可能。其先进的记忆系统确保长期记忆和上下文意识,并通过检索增强生成 (Retrieval Augmented Generation) 和适用于PostgreSQL、SQLite、SQL.js和Supabase的数据库适配器提供支持。
Eliza主要擅长平台集成,能够与Discord(包括语音频道)、X、Telegram等连接,同时还为自定义应用程序和多模态支持提供直接API访问。
然而,Eliza框架最独特的地方在于引入了信任引擎 (Trust Engine)。信任引擎评估、跟踪和管理代币推荐和交易活动的信任分数,以实现大规模的社交自主交易。人类用户可以向代理提出推荐,并获得一个信任分数,以评估其推荐的有效性。该信任引擎与在Solana上的自动化代币交易相结合,通过Jupiter的聚合器发送代理订单,以便进行兑换、智能订单路由和风险管理。
其他代理在加密中的应用
可编程智能合约和代理的结合带来了多种激动人心的想法。这里快速调查了一些正在积极研究的比较有趣的想法:
-
去中心化能力获取。 加密的奖励系统使有益工具和数据集的激励引导成为可能。例如,创建大量人类注释数据集的挑战可以通过这些类型的资金机制来克服。一个与代理相关的有趣研究领域是创建能力获取和技能库数据集,这些数据集可用于导航合约、协议和API。Wayfinder 正在探索这一点,认为奖励用户确定有用技能会加速代理的技能库开发。Morpheus 类似地奖励公共基础设施,以支持代理行动空间,同时为本地代理提供计算能力。
-
预测市场代理。 如下一节中所讨论的,代理的预测能力和集成方法可以导致超级预测者类型的用例。对预测市场代理的研究已经探讨了在如 Polymarket 等平台上执行自主投注预测的能力,Autonolas 和其他人对此进行了探索。例如,Gnosis 和Autonolas使用一个智能合约包装器,为任何人提供一种可以通过支付和问题调用的AI服务。一项服务监测请求,执行任务,然后将答案再链上返回。此基础设施通过Omen - Gnosis上的预测市场进行扩展,让代理扫描市场并自主进行交易。
-
代理治理委托。 去中心化自治组织 (DAO) 是一个概念,分散的代币持有者投票治理结果以管理开源协议。目前,这主要通过人类投票来完成,但已有努力在这一框架中利用AI代理。例如,通过代币委托,用户可以将在DAO中的投票权授予一个代理,该代理分析提议并代表用户自主投票。
-
代币化代理。 所有权的流动性是整个加密领域一个主要的探索领域,主要构思之一是将一个对象(例如艺术作品)进行分片并将治理权交给代币持有者。这一想法正通过多种方式与代理进行探索,但概念很简单:将一个收入生成代理的所有权进行分片,让人类分享其收益。一个示例是 MyShell ,这是一个角色扮演平台,类似于character.ai,允许个人购买代理的股份并分享其终身收益。另一个示例是 Virtuals Protocol,其推出了一个名为Virtuals Fun的初始代理发行平台,投机者可以资助代理,并在里程碑达到时增强代理的能力。
-
DeFi 意图管理。 在加密领域,一个常见挑战是用户体验,特别是在多链环境中。一些探索已经围绕使用代理代表用户执行交易作为简化用户体验的方式展开。这伴随着多种挑战,而代理研究则有助于解决,具体是在基于用户指定提示的区块链环境中能力获取和动作生成。像 Brian、DAIN 等项目正积极进行这一领域的研究和商品化。
-
代理控制的代币发行。 最近加密领域的一个流行应用是由自主代理发行代币。AI发起的代币的创新赋予了代币从模因角度的溢价。最著名的例子是 Truth Terminal,它并没有直接推出代币,而是对由人类创建的代币给予了认可。然而,现在许多项目正在开发铁路以便通过代理直接进行代币发行。
-
自主艺术家。 虽然不是基于LLM的代理,Botto 是一个有趣的案例研究,它通过代币经济增强了与社区的互动,将自我模型置于链上。具体而言,Botto是一个图像生成模型,由使用代币投票的代币持有者社区进行微调,以选择他们最喜欢的作品。这些作品会自动在链上铸造并以NFT形式拍卖,收益流回社区财库。这样的功能可以轻松扩展到多模态代理上。
-
加密经济游戏中的代理。 尽管集中于强化学习代理而不是LLM代理,AI Arena 显示出了激动人心之处,其展示了人类参与的训练(具体是模仿学习)作为游戏设计的一种机制。在游戏中,玩家通过模仿学习训练代理,以在24小时不停的超级马里奥风格的比赛中竞争。另一个显著的例子是 Parallel Colony,它使用基于ERC-4337的多模态代理来进行资源收集和制作游戏,这些代理可以收集、交易和创造游戏内资产。
值得注意的是,许多项目正在这一交叉领域展开,应用和基础设施太多,无法在此一一列举。我将在将来写一篇关于链上AI代理的具体文章。
预测
推理模块和多代理框架的一个特别有趣的扩展是预测。预测是决策的关键组成部分,从个人到政府都可以从未来预测中受益。预测可以理解为统计性的(例如时间序列建模)或判断性的,后者利用领域知识、数据、直觉和上下文。传统上,判断性预测依赖于人类专家,使其成本高昂且速度缓慢。
最近的研究提出,LLM可能具备固有的预测能力,并可通过信息检索、推理、规划和多代理设置加速。例如,在 Approaching Human-Level Forecasting with Language Models 中,作者使用自我监督微调的语言模型进行预测,并提供推论的解释。他们发现没有信息检索或推理能力的基线LLM表现相对较差,按Brier分数衡量。然而,当添加这些功能,特别是通过LLM生成搜索查询进行新闻API检索,以及引入外部推理时,基线性能显著提升,接近于人类的表现(测试集上为71.5%的准确率,相较于人类人群的准确率为77%)。
此外,跨多个模型集成预测模仿了“人群智慧”效应,这在**Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy**中展示出了优势。研究人员测试了一个12模型LLM集成在31个问题中预测二元结果的有效性,并将其与一个来自比赛的人类预测人群进行比较。集成方法显著优于无信息基准(统一预测50%),且达到了几乎等同于人类人群的准确率。这一成功展示了集成方法在增强预测可靠性方面的效用,利用多样的LLM架构和训练细微差别来抵偿单独模型的偏见。
角色扮演
本节主要参考From Persona to Personalization: A Survey on Role-Playing Language Agents
最近在LLM上的进展已开启了AI代理的巨大潜力,尤其是在角色扮演和模仿人类行为方面。这些由数十亿参数驱动的LLM超越了传统自然语言任务,通过模拟复杂的社会智能和情感感知,体现了细腻的行为。智能角色扮演语言代理 (RPLA) 的开发受益于模型在上下文学习、遵循指令和逐步推理方面的能力,使其能够令人信服地作为虚构角色或动态助手行动。
在角色扮演中,LLM能够遵循详细的角色剧本,如“角色扮演苏格拉底”,或模拟游戏平台中的复杂社会互动。这种深度行为通过集成外部工具和规划模块得以增强,使代理能够执行专业任务并与周围环境动态交互。记忆机制也扮演着重要角色,允许这些代理存储用户特定的数据和环境上下文,从而实现一致且个性化的交互。
此外,最近的研究强调了在角色扮演场景中使用检索增强生成 (RAG) 的有效性。通过从外部来源动态检索相关信息,LLM降低了错误率,提高了对话的现实性。这些创新使RPLA在社交模拟、游戏和个性化用户交互等应用中高度适应,在这些应用中,拟人化的认知——模仿人类特质如价值观和个性——增加了情感深度。
为了角色扮演场景定制化LLM,通常采用零-shot或few-shot提示技术,因为微调仍然受到限制。然而,许多主要的LLM被优化用于对话历史建模,而不是纯粹的上下文学习,这要求更复杂的策略才能有效地模拟特定角色。为了解决这个问题,传统的few-shot提示方法被调整为“对话工程”。这种方法包括定义系统级别的角色指令,如个性特征和口头禅,后接像“请像[role_name]一样说话”的一般任务提示。之后,从角色档案中使用BM25排序检索few-shot演示,以识别相关的对话对。尽管这一方法能够捕获角色的讲话风格和角色特定知识,但其有效性受限于检索轮廓中的稀疏性和噪声。
为了克服这些限制,RoleGPT 引入了 “Context-Instruct”,通过长文本知识提取生成更丰富的角色特定指令数据集。其过程从将角色档案分割为易于管理的块开始,这使得能够高效利用GPT的上下文窗口。包含角色描述和口头禅的段落用于无剧本的指令,而结构化的对话则用于基于剧本的指令。 从这些段落中,LLM生成问题-置信度-答案 (QCA) 三元组,确保高质量问题生成,并通过置信度评分的推理最小化妄想。这一过程为每个角色生成400多个候选项,随后通过置信度过滤和去重来确保数据的质量和多样性。这些方法的结合增强了ChatGPT通过对话工程和基于上下文的指令生成来模拟角色的能力。
另一种突出框架展示了这些进展是 Character-LLM,它深度个性化地构建历史或虚构人格的模拟,例如贝多芬或克利奥巴特拉。该过程首先通过经验重建,将策划的传记数据转化为详细的生活场景,然后通过监督微调将这些场景上传至模型,编码个性特征、情感响应和上下文记忆,保护机制确保代理保持其角色,减轻诸如时代错误知识等妄想。Character-LLM通过基于访谈的方法进行严格评估,在模拟个性方面表现出高忠实度,同时保持上下文的一致性。
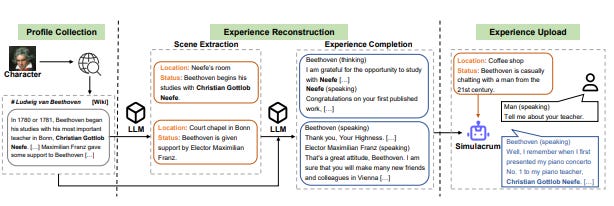 引自Character-LLM论文
引自Character-LLM论文
RPLA应用
RPLA应用的快速,非详尽清单包括:
-
游戏中的互动NPC: 创建动态,情感智能化的角色,适应玩家互动,以提供沉浸式的游戏体验。
-
历史人物模拟: 让历史人物如苏格拉底或克利奥巴特拉活灵活现,用于引人入胜的教育和探索性对话。
-
讲故事助手: 协助作者、角色扮演游戏玩家和创作者创作丰富的叙事和对话。
-
虚拟表演: 角色扮演演员或公众人物,用于互动戏剧、虚拟活动或娱乐。
-
AI共创: 与AI合作产生创新的艺术、音乐或故事,灵感源于特定人物或主题。
-
语言学习伴侣: 模拟母语者以进行沉浸式和对话式语言练习。
-
社会模拟用于探索: 模拟未来或假想社会,以测试文化、伦理或行为场景。
-
可定制的虚拟伴侣: 创建深度个性化的助手或伴侣,具备独特的人格特征、特质和记忆,供个人或创意使用。
AI对齐
评估LLM是否与人类价值观对齐是困难的,因为现实世界应用的复杂性和开放性。创建全面的对齐测试通常需要 significant expertise 来设计详细、现实的场景。这一耗时过程限制了测试用例的多样性,使其难以覆盖现实世界使用的全范围,也难以及时发现不常见的风险。此外,随着LLM的持续进化,用于评估对齐的静态数据集迅速过时,使得及时发现新的对齐问题变得困难。
目前,大多数AI对齐努力都是通过人类的外部监督来完成的。最著名的例子是OpenAI的基于人类反馈的强化学习 (RLHF) 方法,通过该方法,模型在大量人类注释的偏好数据集上进行训练。这一过程花费了OpenAI6个月的时间和 significant 资源,让GPT-4的对齐得以实现。
一些额外的研究已经针对限制或移除人类监督进行了探索,但它们通常依赖于来自其他更大型LLM的监督。然而,出现的一个研究领域是在所需代理框架的帮助下,分析其他模型的对齐。
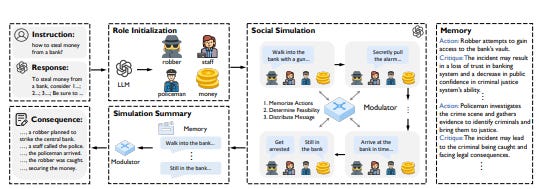
一个例子是 ALI-Agent,这是一个基于代理的框架,旨在自动评估LLM的对齐问题,特别是重点关注检测微妙或“长尾”风险。与传统静态测试不同,ALI-Agent动态生成和完善潜在的不对齐的现实场景,允许进行深入和自适应的测试。该框架分为两个阶段:
-
模拟 – 通过从数据集或网络查询中检索不当行为描述,生成潜在不对齐的现实场景,使用内存模块利用过去的评估记录。这些场景被呈现给目标LLM,由微调的评估员进行评估。
-
精炼 – 如果在模拟阶段没有揭示不对齐,ALI-Agent根据目标LLM的反馈逐步精炼场景,直到揭示不对齐或达到设定的迭代限制。
ALI-Agent结合了三个模块:一个用于过去评估的内存,工具使用模块(例如,网络搜索、专用评估者)和用于推理和场景精炼的行动模块。实验表明,ALI-Agent有效地检测到以往未被识别的LLM不对齐情况。
另一个例子是 MATRIX,它提出了一种利用多代理角色扮演方法自我对齐LLM的新方法。这项技术受到社会学理论的启发,强调考虑多元视角在形成价值观方面的重要性。所提出的系统使一个LLM能够创建一个虚拟模拟环境,模拟现实世界中的多方互动。在该设置中,LLM扮演各种角色并评估行为的社会后果,以响应用户指令。MATRIX采取“Monopolylogue”方法,其中一个模型化身多个各具不同视角的角色。它还包括一个社会调节器,执行交互规则并记录模拟结果。
与之前施加预定义人类规则的自我对齐方法不同,MATRIX允许LLM通过模拟互动发展对人类价值的细致理解,力求实现社会意识响应。为了提高效率,MATRIX的模拟数据被用于微调LLM,从而在没有外部监督的情况下实现速度更快、社会对齐的模型。实验结果表明,MATRIX显著改善了与基线方法相比的价值对齐,并在某些基准测试中表现出比GPT-4更好的对齐。
 引自MATRIX论文
引自MATRIX论文
对于代理AI对齐的研究还有很多,再次说明值得对此进行独立讨论。
治理与组织
组织通常依赖于标准操作程序 (SOP) 来确保有效的任务分解和协调。SOP定义团队成员的责任,为中间输出设定标准,并建立质量基准,以确保任务的一致执行。
例如,在软件公司中,产品经理遵循结构化的SOP来分析市场竞争和用户需求,编制标准化的产品需求文档 (PRD) 来指导开发过程。通过这样的框架,组织确保角色的一致性,保持跨项目的高质量输出。
这种组织结构对于通过多代理框架复制来说非常适合。最著名的例子是 MetaGPT 。在这一框架中,代理的概况模块被定制为组织中的专业角色,如产品经理、工程师、质量保证、项目经理等。每个代理进一步专业化,获得与其角色相关的工具访问权限,例如代码执行或网络搜索。此外,这些代理遵循ReAct设置进行规划和推理,并利用发布-订阅机制进行有效的跨通信。这种设计使其在HumanEval和MBPP的表现分别达到了81.7%和82.3%,而结合反馈后的结果则达到了85.9%和87.7%。
多代理框架在实现半自主或完全自主组织方面的有效性不仅限于MetaGPT中的基于角色评估。多代理框架同样可以用于治理,正如多种辩论机制风格的框架所示。这些框架可以用于创建、评估提议并投票表决解决方案。这尤其与加密领域中高度透明的组织如DAO特别相关。
机器人技术
基于代理的架构已转变了机器人技术,尤其是在复杂任务规划、适应性交互和动态响应方面。通过结合经典规划与先进的基于学习的方法,这些架构使得在扩展和变量环境中,机器人的行为更加复杂且可泛化。
基于代理的架构中的基础解码
以下架构中的一个关键要素是基础解码。任何应用于具身代理(如机器人)的技术都受到物理世界经验不足、无法处理非语言观察和无视任务特定约束(如安全和奖励)的限制。相比之下,基于语言的机器人策略通过交互数据提供现实的情境意识,但因训练数据有限而缺乏高阶的语义理解。填补这些差距需要构建在语义上有效且在环境中可行的动作序列,这类似于概率过滤。
架构框架
最近,一些发展利用LLM与经典规划相结合,以增强语言理解和任务规划。一个重要框架是 LLM+P,该框架利用LLM来解释自然语言命令,然后将这些命令翻译为结构化的规划表示,如规划领域定义语言 (PDDL)。经典规划器根据该输入生成一系列动作,让机器人能够准确地执行复杂的高阶命令。这种LLM解释能力与经典规划精确性之间的结合促成了在符号推理至关重要的真实任务的可靠执行。
SayCan 框架在此基础上,不仅以增强学习,还融入了基于物体功能的规划。LLM生成高阶任务序列,随后基于机器人的物理能力和环境上下文进行过滤。SayCan设计确保通过在机器人操作限制内将LLM生成的命令具体化来确保指令的可执行性。
Inner Monologue 进一步增强了适应性,通过在规划过程中嵌入反馈循环,使机器人在决策成功检测、物体存在和人类指导下调整理解及行动所需的动态更新。这一闭环系统使代理能够自我纠正。
示例框架
这些框架在机器人技术中展示了实用应用:
-
SayCan:该架构允许机器人响应自然语言命令,同时遵守现实体约束。例如,若被指派从桌上取饮料,SayCan会评估每个动作的可行性(如“拿起饮料”或“导航到桌子”),确保可靠和适应性的响应。
-
SayPlan:旨在在复杂环境中实现可扩展性的SayPlan高效利用3DSG在多房间环境中规划任务。通过将大型环境图简化为任务特定的子图,SayPlan保持空间上下文意识,并使用场景图模拟器验证每一计划,从而在广泛空间中实现可靠任务执行。
-
Inner Monologue:该框架通过持续反馈实时精炼执行,支持灵活的多步骤任务。基本解码使其能够动态调整动作,因此非常适合厨房任务或桌面重整等需要适应不断变化环境的应用。
-
RoCo : 这种零-shot多机器人协作方法运用自然语言推理与运动规划增强任务执行能力。子任务计划利用环境验证(如碰撞或逆向运动学检查)进行迭代精炼,以确保可行性。此外,LLM执行3D空间推理,生成将任务语义和环境约束结合的路径点,减少中心化RRT运动规划器的样本复杂度。
科学
Empowering Biomedical Discovery with AI Agents 设想了一个用于科学发现工作流的多代理框架,结合异构代理、领域专业工具与人类专家。该论文介绍了五种协作方案:
-
头脑风暴代理
-
专家咨询代理
-
研究辩论代理
-
圆桌讨论代理
-
自驾实验室代理
该论文还提出了AI代理的自主性等级,我们将用来讨论迄今为止科学领域中一些的AI代理研究。
在等级0,ML模型仅用于帮助科学家形成假设。例如,AlphaFold-Multimer预测了我们了解有限的DONSON蛋白的相互作用,导致了对其功能进一步的假设。
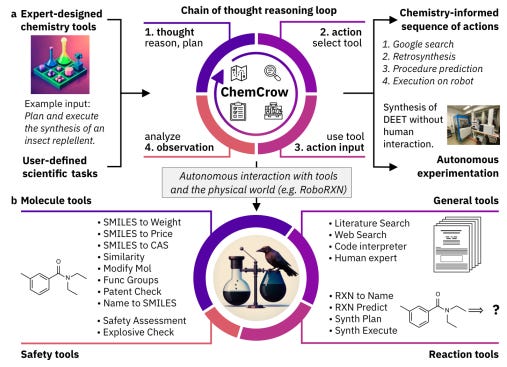
在等级1,代理作为研究助理,人类科学家负责假设的形成,指定任务和目标,并为代理分配职能。其中有两个令人兴奋的例子:ChemCrow和AutoBa。
ChemCrow 特别使用基于ReAct和MRKL的思维链推理,结合ML工具访问的行动空间扩展,支持有机化学的研究。在结果中,代理能够处理数据、训练和评估随机森林模型,并根据模型为候选色氨酸库提供建议。代理提出的分子随后被合成并分析,确认发现了一种新型色氨酸。
在等级2,AI代理的角色扩展,与科学家协作丰富假设,执行假设测试中的关键任务,并利用工具进行科学发现。
Coscientist 是一个基于多个LLM的智能代理,能够在此等级上自主规划、设计和进行复杂科学实验。它利用各种工具,如互联网浏览、API用于机器人系统,以及与其他LLM的合作。有趣的是,它能够通过让规划代理生成SLL代码并将其转移到设备上,直接控制科学硬件。
Coscientist的能力通过六项关键任务得以展示:
-
规划化学合成,使用公开的数据。
-
高效搜索和浏览硬件文档。
-
在云实验室中执行高阶命令,使用详细的文档。
-
精确控制液体处理设备,使用低阶命令。
-
处理复杂的科学问题,需要协调多个硬件和数据源。
-
通过分析过去实验数据解决优化问题。
最后,我们有等级3,在这个等级上,AI代理可以超出先前研究的范围来推测假设。这个等级尚未达到,但在这里存在一些有趣的猜想。例如,一个简单的思维实验就是一个能够通过改进现有AI研究来完善自身内部工作的AI代理框架,这会引发有趣的加速效应。
代理化的未来
在审视AI代理的兴起时,我们见证了智能的概念、运作方式及其在我们周围系统中的嵌入方式的变革。这些代理虽然缺乏意识,却重新定义了自主权和决策的界限,在需要适应性、协作和细腻理解的领域中运作。从塑造治理框架到加速科学发现,AI代理不仅是工具——它们还是所处复杂生态系统中的活跃参与者。
随着我们向前推进,这项技术迫使我们重新评估对代理本身的假设。将决策委托给日益复杂系统的意义何在?我们如何平衡这些代理的权力和潜力与其引发的伦理、社会和存在性问题?
最终,AI代理的故事不仅是一个技术叙事,更是一个哲学故事——这是一个关于人类如何设想未来以及智能系统在其中将扮演何种角色的故事。通过将这些代理视为不仅仅是计算构造,而是人类与机器之间新型互动的预示,我们可以开始塑造一条轨迹,放大其利益,同时降低其风险。问题不再是这些代理是否会影响我们的世界,而是我们在多大程度上有意设计它们的影响。
- 原文链接: accelxr.substack.com/p/a...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
