Sunnyside Devnet 更新 - 07/14
本文是Sunnyside Devnet 07/14的更新报告,主要关注在高blob吞吐量下网络带宽的基准测试。报告涵盖了blob吞吐量、网络使用情况、CPU/RAM使用情况和创世同步等多个方面的测试结果,通过限制网络带宽,分析了不同客户端在应对高负载和网络约束时的表现,并识别了影响吞吐量的瓶颈。
Sunnyside Devnet 更新 - 07/14
概览
大多数单个 CL devnet 可以达到每个区块约 72 个 blob,但在本轮中,Lighthouse & Teku 的峰值约为 60 个,Nimbus 约为 40 个。这种性能不佳可能是由于使用的验证器较少(8 个而不是 100 个)。
所有经过测试的 EL 客户端都支持 ≥72 个 blob/区块(Reth 需要手动 peer boosting 才能超过 ~40 个 blob)。
持续负载:一个 128 节点的混合 devnet 在 60 个 blob/区块的情况下稳定运行超过 48 小时。
30 Mbps 带宽上限:单个 CL devnet 实现了 ~60 个 blob/区块,而 128 节点的 devnet 实现了 ~45 个 blob。
网络使用:即使在高负载下,平均带宽仍然适中(在 60 个 blob 时 <20 Mbps),但短时突发流量(尤其是 slot 开始时的 gossip)经常达到带宽上限,成为限制因素。
EL 网络方面的发现:比较在 peering 和网络使用中观察到的行为。
资源使用:在整个测试过程中,CPU 利用率保持在较低水平,但 RAM 使用率在长时间运行中稳步攀升(与 Fusaka-Devnet-2 中已观察到的情况相同)
Genesis 同步:所有客户端对 (CL+EL) 都从 genesis 同步,除了那些使用 Geth 的客户端,它们遇到了同步错误。Geth 问题的修复正在审查中
介绍
在本轮 Sunnyside devnet 中,我们专注于高 blob 吞吐量下的网络带宽基准测试,对每个客户端使用最新的 Fusaka-Devnet-2 spec 镜像。在之前的测试中,fullnode 使用了不切实际的高验证器数量(每个节点 100 个);这次我们减少到每个 fullnode 8 个验证器,以实现更真实的设置。我们运行了一系列 devnet,涵盖了每个主要的 CL 客户端(每个客户端都与默认 EL 配对)和每个主要的 EL 客户端(与默认 CL Prysm 配对)。我们还启动了一个包含 128 个节点(4 个 CL x 4 个 EL 的组合,每个组合 8 个节点)的混合 Devnet,以观察互操作性。
我们的分析强调网络使用和带宽限制在高 blob 吞吐量下的影响,同时还监控其他数据和测试,例如 CPU/RAM 使用和 genesis 同步测试。
方法
我们总共运行了 12 个 devnet。每个 devnet 都经历了多达三个连续的测试阶段(测试 1 → 测试 2 → 测试 3),进展取决于前一阶段的成功(如果 devnet 在一个阶段失败或产生的数据不足,则会跳过后面的阶段)。
测试 1:Blob 吞吐量基准测试
我们逐渐增加每个区块的 blob 数量(每 5 分钟增加 1 个),直到 devnet 达到目标最大值(≥72 个 blob)或链失败。这可以指示每个客户端当前的最大可持续 blobs-per-block,并确定网络或客户端在什么吞吐量下会崩溃。结果指导了在后续测试中使用哪些 blob 速率(例如,我们根据每个 devnet 可以处理的速率选择 48、60、72、84 个 blobs/区块作为标准化速率)。(注意:单客户端 EL 专用 devnet 仅运行测试 1,因为它们的目的是在本轮中仅评估最大 blob;它们没有继续进行测试 2-3。)
测试 2:网络带宽基准测试
对于在测试 1 中达到至少 ~48 个 blob 的 devnet,我们进行了持续负载测试。我们将 blob 吞吐量固定为每个区块 48、60、72 和 84 个 blob(取决于 devnet 的容量),持续较长时间(≥1-2 小时)。这使我们能够测量高 blob 速率下的稳态网络带宽使用情况,并验证客户端可以持续保持这些速率。它还有助于观察在重 blob 负载下的任何长期性能问题(例如,内存泄漏)。除非测试 2 显示出异常的网络行为,否则所有 devnet 都会进入下一阶段。
测试 3:网络带宽限制
在此阶段,我们重复了 blob 吞吐量测试,但在 OS 级别限制了 fullnode 的网络带宽。我们最初使用 Linux Traffic Control (TC) 脚本应用了 30 Mbps 的上限(每个 fullnode)(有关详细信息,请参见附录 A)。仅节流 fullnode(supernode 未受限制),因为即使在负载下,也观察到 supernode 使用 <200 Mbps,并且我们假设担任该角色的真实 staaker 具有足够的带宽。如果 devnet 在 30 Mbps 的速率下仍然很容易达到最大 blob,我们会根据具体情况尝试更低的限制(例如,20 Mbps、10 Mbps)。此测试评估了带宽限制如何影响 blob 传播,并确定网络压力下的吞吐量限制。
| 测试 | 总结 |
|---|---|
| Blob 基准 | Spamoor 每 5 分钟逐渐增加 1 个 blob 的吞吐量,直到达到最大 blob 或链失败。 |
| 带宽基准 | Spamoor 持续发送相同数量的 blob (48/60/72/84) 至少 1~2 小时。 |
| 带宽限制 | 与 Blob 基准相同,但 fullnode 位于带宽受限的环境下。 |
Devnet 配置 & 测试
所有 devnet 的配置都类似于 EthPandaOps 设置。我们在多个地域使用具有相同规范(8 个 vCPU,16GB RAM)的 DigitalOcean 节点。在每个 devnet 中,一半的节点是 fullnode(每个节点运行 8 个验证器),另一半是 supernode。应用了相同的 45M gas 限制。我们只是调整为具有更高的 BPO,例如 72 或 96。
CL 和 EL 客户端软件镜像在附录 C 中有详细说明。我们为每个 devnet 的指标提供 Grafana 仪表板(参见附录 B)。下表总结了运行的 devnet,包括每个 devnet 中完成的测试以及最大和目标 BPO。 表示在该 devnet 上执行了测试。所有配置都在 fusaka-devnets 中。
| 名称 | 节点 | Blob 基准 | 带宽基准 | 带Bandwidth 限制 | 最大/目标 Blobs |
|---|---|---|---|---|---|
| 混合 Devnet | 128 节点* | 72 | |||
| Grandine Devnet | 50 Grandine-Geth | 96 | |||
| Lighthouse Devnet | 50 Lighthouse-Geth | 96 | |||
| Lodestar Devnet | 50 Lodestar-Geth | 96 | |||
| Nimbus Devnet (Interop)** | 50 Nimbus-Nethermind | 128 | |||
| Nimbus Devnet | 50 Nimbus-Geth | 96 | |||
| Prysm Devnet (Geth)*** | 50 Prysm-Geth | 96 | |||
| Teku Devnet | 50 Teku-Geth | 96 | |||
| Besu Devnet**** | 50 Prysm-Besu | 96 | |||
| Erigon Devnet | 50 Prysm-Erigon | 96 | |||
| Nethermind Devnet | 50 Prysm-Nethermind | 96 | |||
| Reth Devnet | 50 Prysm-Reth | 96 |
注释:
* 混合 Devnet 由每个唯一的 CL-EL 对(Grandine、Lighthouse、Prysm、Teku x Besu、Erigon、Geth、Nethermind = 共 128 个节点)的 8 个节点组成。
** “Nimbus (Interop)” 在 Fusaka-Devent-1 spec 上使用了来自 Berlin Interop 的 Nimbus 构建版本(Nimbus 团队的特殊请求)
*** 上面的仅 Prysm Devnet 实际上是一个“仅 Geth”EL devneet,因为所有其他仅 EL devnet 都使用 Prysm 作为 CL。(我们跳过了 Prysm-Geth 的显式测试 1,因为之前的运行表明它可以轻松处理 84 个 blob。)
**** Besu devnet 运行了一个自定义 tx 池设置,以将 blob tx 最多设置为 72 个 blob
--tx-pool-max-prioritized-by-type="BLOB=72"
由于内部设置问题,我们本轮没有运行仅 NimbusEL 的 devnet;我们计划将其包含在未来的测试中。
结果 & 主要发现
1. Blob 吞吐量
1.1. 基准
CL Devnet
| Devnet | Grandine | Lighthouse | Lodestar | Nimbus | Prysm | Teku |
|---|---|---|---|---|---|---|
| Blob 吞吐量 | ≥72 | 60+ | ≥72 | 40+ | ≥72 | 60+ |
大多数 CL 客户端都实现了高 blob 吞吐量,Grandine、Lodestar 和 Prysm 达到了每个区块 84+ 个 blob。Lighthouse 和 Teku 在本次运行中达到 60 多个 blob,Nimbus 达到 40 多个 blob。与之前的 devnet 相比,这些结果对于 Lighthouse 而言明显较低(在之前的 devnet 中,Lighthouse 使用 Geth EL 维持了 24 小时每个区块 72 个 blob)。我们怀疑下降的原因是自上次运行以来的差异——可能最近的客户端更新/优化或每个节点减少的验证器数量(8 个而不是 100 个),这意味着每个节点订阅的 blob 子网(数据“列”)更少,并且可能会降低整体数据可用性。
Nimbus 在 Fusaka-Devnet-1 配置上使用其 Berlin-Interop 构建实现了约 40 个 blob/区块,但在 Fusaka-Devnet-2 配置上仅实现了约 25 多个 blob。Nimbus 可能同样受到 8 验证器设置的影响,从而降低了其有效的子网覆盖范围。我们应要求运行了额外的以 Nimbus 为中心的 devnet,并且将在 Nimbus 进行更新时继续重新进行基准测试。
EL Devnet
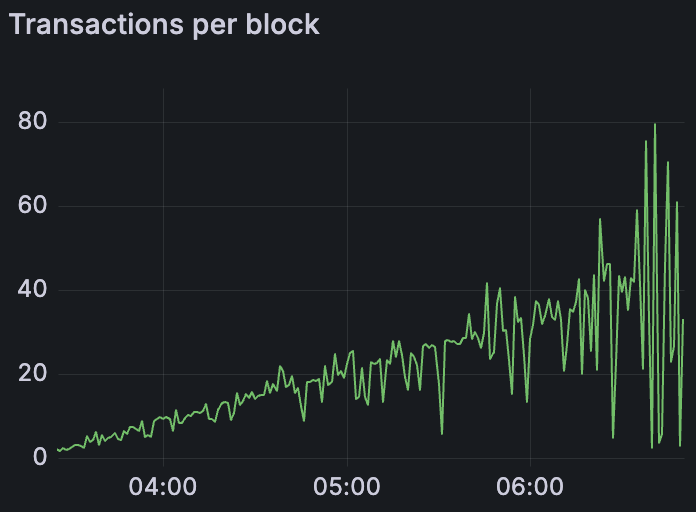
Reth Devnet blob 在 peers 较少时的吞吐量
ALT
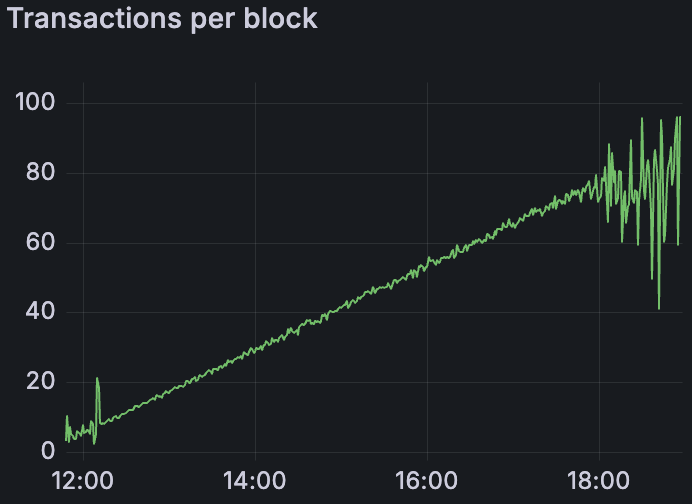
Reth Devnet blob 在手动 peering 时的吞吐量
ALT
所有 EL 客户端(与 Prysm 配对时)都能够达到每个区块 72 个或更多 blob。这是一个令人鼓舞的结果——这是我们第一次在这些 blob 容量下测试每个 EL。一个需要注意的是 Reth,由于 peer 连接性差,如果没有手动干预,它只能达到约 40 个 blob/区块。通过使用我们的 peering assit 工具 (Peeroor) 为 Reth 手动连接 peer(Discord 线程),我们使其能够达到完整的 72-blob 速率。这突出了 peer 网络在执行层上的重要性:有了足够的 peer,即使是历史上滞后的 EL 也能跟上。(上面的两张图表说明了 Reth 在手动 peering 前后的 blob 吞吐量——显示了在 peer 计数增加后,吞吐量有了显着提高)
混合 Devnet
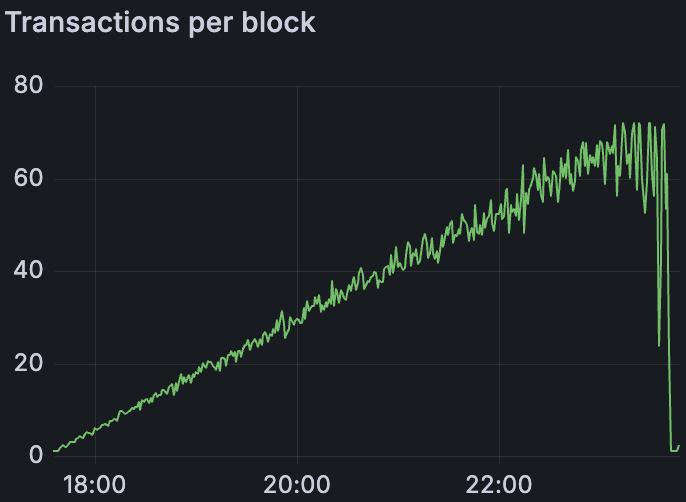
混合 Devnet blob 吞吐量
ALT
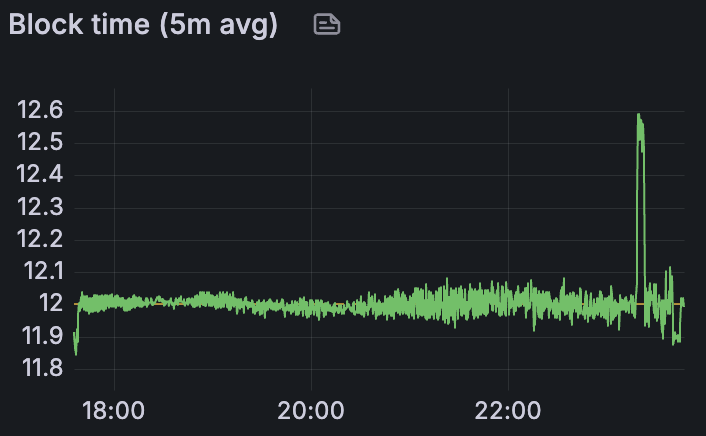
混合 Devnet 平均区块时间
ALT
混合客户端网络(具有 128 个节点,运行 4 个 CL 和 4 个 EL 的混合)最大只能达到每个区块约 60 多个 blob。这似乎受到 Lighthouse 和 Teku 节点的限制,如上所述,在此配置中它们仅执行约 60 个 blob。
1.2. 维持高 blob 计数
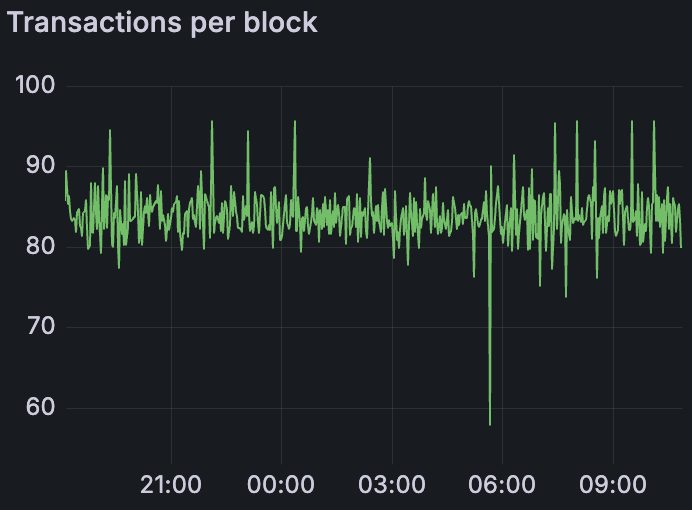
Grandine Devnet 在平均 84 个 blob/区块的情况下运行了 16 小时
ALT
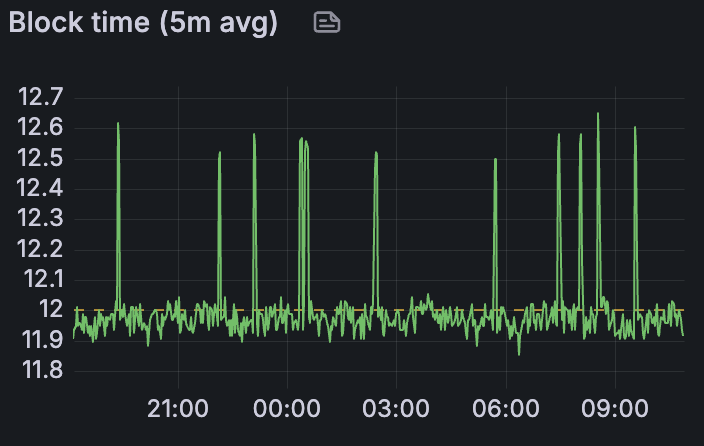
Grandine Devnet 区块时间
ALT
我们延长了几次运行,以测试持续的高 blob 吞吐量(作为测试 2:带宽基准的一部分)。过去,我们的 devnet 通常会增加 blob 计数,直到发生故障,但不会长时间保持高速率。这一次,通过保持 1-2 小时的恒定 blob 速率,我们可以观察到客户端是否能在给定的时间段内在 60 或 72 个 blob/区块的情况下保持稳定。所有 devnet 都能够在至少一两个小时内维持各自的最大 blob 速率,而没有立即出现问题。Teku Devnet 是一个例外:Teku 难以持续保持 60 个 blob/区块。在负载下运行一段时间后,出现了不稳定的迹象,因此我们没有继续运行。
值得注意的是,Grandine Devnet 在 ~84 个 blob/区块的情况下运行了超过 16 个小时(一夜之间),没有任何明显的故障或降级。这在一定程度上是偶然的(测试仍在运行),但它提供了一个有价值的数据点:至少某些客户端组合可以可靠地将 blob 吞吐量推到非常高的水平,并持续很长时间。
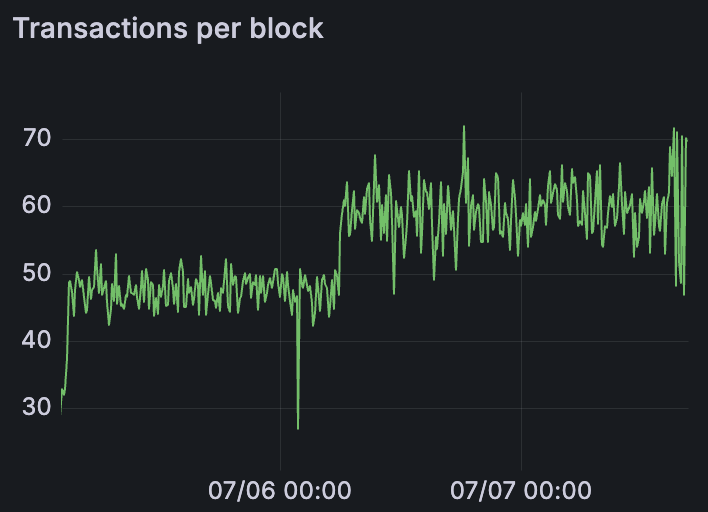
Mixed Devnet 第一次启动在前 24+ 小时发送 48 个 blob/区块,在接下来的 36+ 小时发送 60 个 blob/区块
ALT
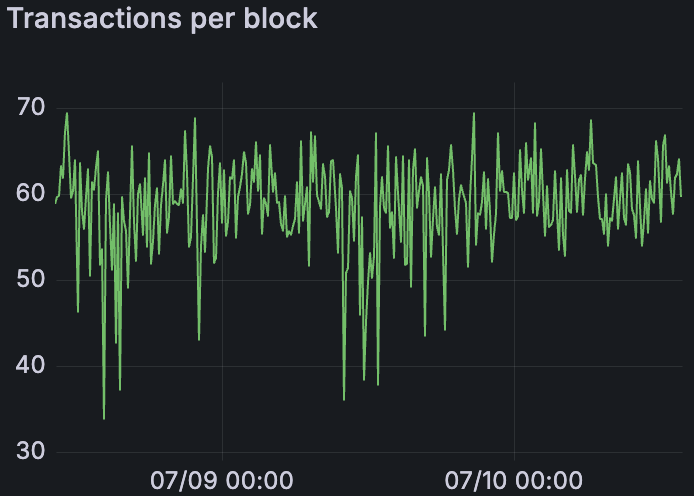
混合 Devnet 第二次启动在 48+ 小时内发送 60 个 blob/区块
ALT
根据 Lighthouse 团队的请求(Discord 线程),我们还运行了更长时间的混合 Devnet。在第一次混合 devnet 启动中,我们保持 48 个 blob/区块 24+ 小时,然后提高到 60 个 blob/区块,再运行 ~36 小时。然后,我们第二次重新启动混合 Devnet,并设法将其保持在 60 个 blob/区块的情况下运行了 ~48 小时。在此 48 小时期间,网络在 60 个 blob 吞吐量下保持稳定。我们仅在 48 小时后降低了 blob 负载,以便为下一阶段(带宽限制测试)做准备。
1.3. 在受限网络带宽下
| 带宽限制 | 单个 CL Devnet | 混合 Devnet |
|---|---|---|
| 30 Mbps | ~60 个 blob/区块 | ~45 个 blob/区块 |
| 20 Mbps | ~50 个 blob/区块(仅 LH) | |
| 10 Mbps | ~40 个 blob/区块(仅 LH) |
对于测试 3,我们将 fullnode 带宽限制为 30 Mbps。最初,我们在每个单 CL devnet 中都应用了此限制。所有 CL devnet(Lodestar 除外)都成功运行了上限,并且仍然达到了约 ~60 个 blob/区块的吞吐量。(我们在测试 3 中跳过了 Lodestar,因为 Lodestar 团队告知我们,他们的 fullnode 仍在订阅所有子网,导致异常高的使用率;在他们修复此问题之前,结果将毫无意义。)在 30 Mbps 下普遍达到了 ~60 个 blob/区块的事实表明,此速率可能接近上限下的网络绑定限制,而不是特定于客户端的限制。
然后,我们在一个 devnet(Lighthouse)上尝试了更严格的带宽限制,以查看它如何影响 blob 生产。在 20 Mbps 的情况下,Lighthouse 大约管理了 ~50 个 blob/区块,而在 10 Mbps 的情况下,它大约管理了 ~40 个 blob/区块。正如预期的那样,这种情况会缩放——较低的可用带宽会进一步限制 blob 吞吐量。我们没有在每个客户端上运行 20/10 Mbps 测试,因为我们预计在这些限制下其他客户端也会有类似的行为。
在 30 Mbps 上限下,混合 Devnet 达到了大约 ~45 个 blob/区块。这低于单客户端网络的 ~60 个,这反映出混合设置具有更高的聚合带宽需求(更多节点、不同的网络策略等)。
2. 网络使用
在看到 blob 吞吐量可能受到网络容量的限制后,我们接下来将详细检查网络带宽使用情况。我们将分析节点在各种 blob 负载下交换了多少数据(入站/出站)、导致峰值的原因以及不同组件(CL 与 EL、gossip 与其他)对使用情况的贡献程度。
2.1. 基准
2.1.1. Fullnode
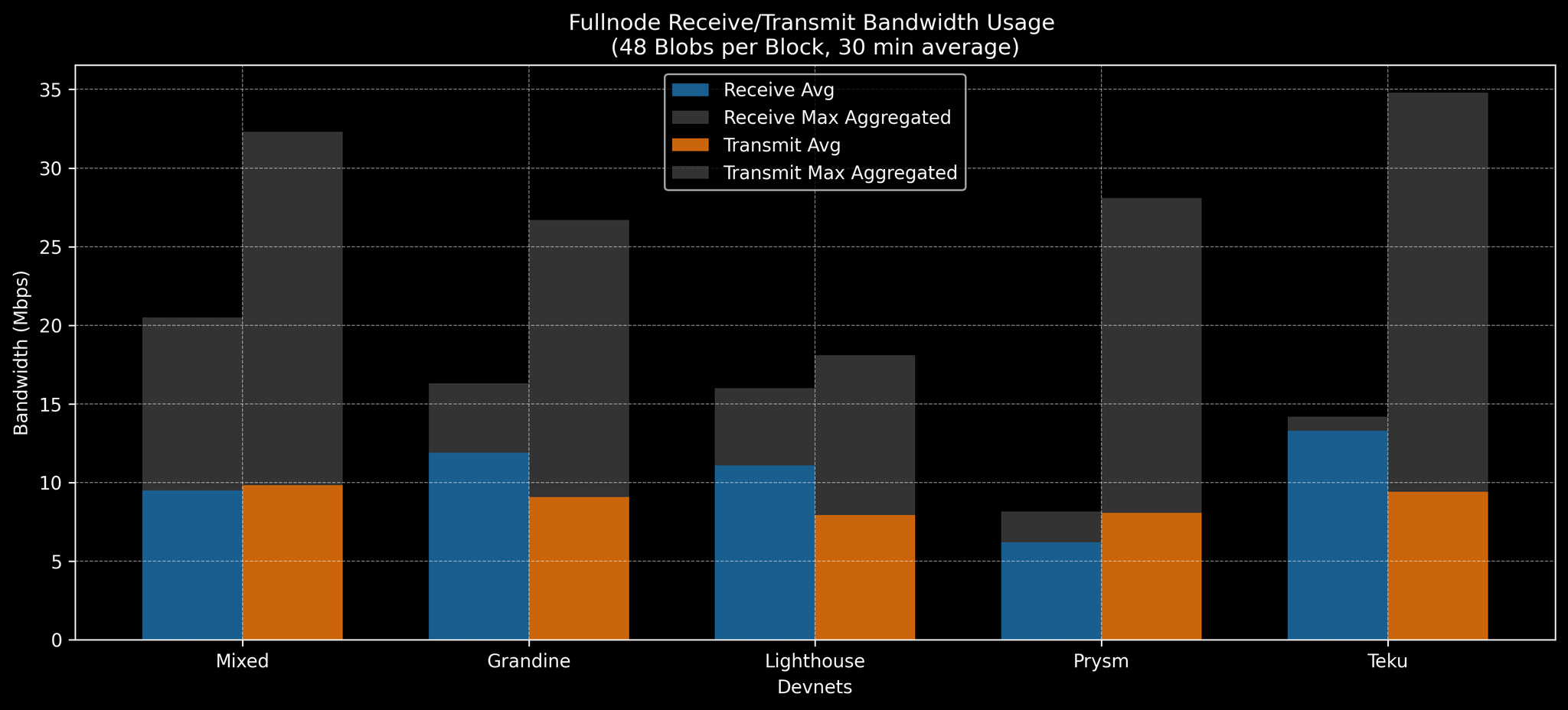
来自混合 Devnet 和单个 CL Devnet 的 48 个 blob/区块下的 Fullnode 带宽基准
ALT
每个 fullnode 有 8 个验证器,平均消耗的带宽出奇地低——在每个区块 48-60 个 blob 的情况下约为 ~10 Mbps(包括入站和出站)。我们在稳定的 1-2 小时运行中以 30 分钟的平均值收集了指标。即使在 60 个 blob/区块的情况下,每个 fullnode 的平均网络使用率也保持在 ~20 Mbps 以下。但是,在这些情况下,峰值使用率(在任何节点上聚合的最大值,仍然平均为 30 分钟的窗口)接近 ~25-30 Mbps。这些峰值表示流量突发。我们认为 30 Mbps 是测试 3 的合理带宽限制,因为它大约是 ~72 个 blob 所需平均值的 150-200%,提供了一些空间。事后看来,我们发现实际上限制上限下性能的是突发流量(而不是平均值)。此外,混合 Devnet 显示出更高的使用率:在相同的 blob 速率 (48-60) 下,混合节点正在推送 >30 Mbps 的出站流量。实际上,在 48 个 blob 的情况下,混合节点已经超过 30 Mbps,这表明在 30 Mbps 的上限下,混合 devnet 网络可能难以达到每个区块 48 个 blob。(包括更高 blob 吞吐量的完整原始数据在附录 D 中。)
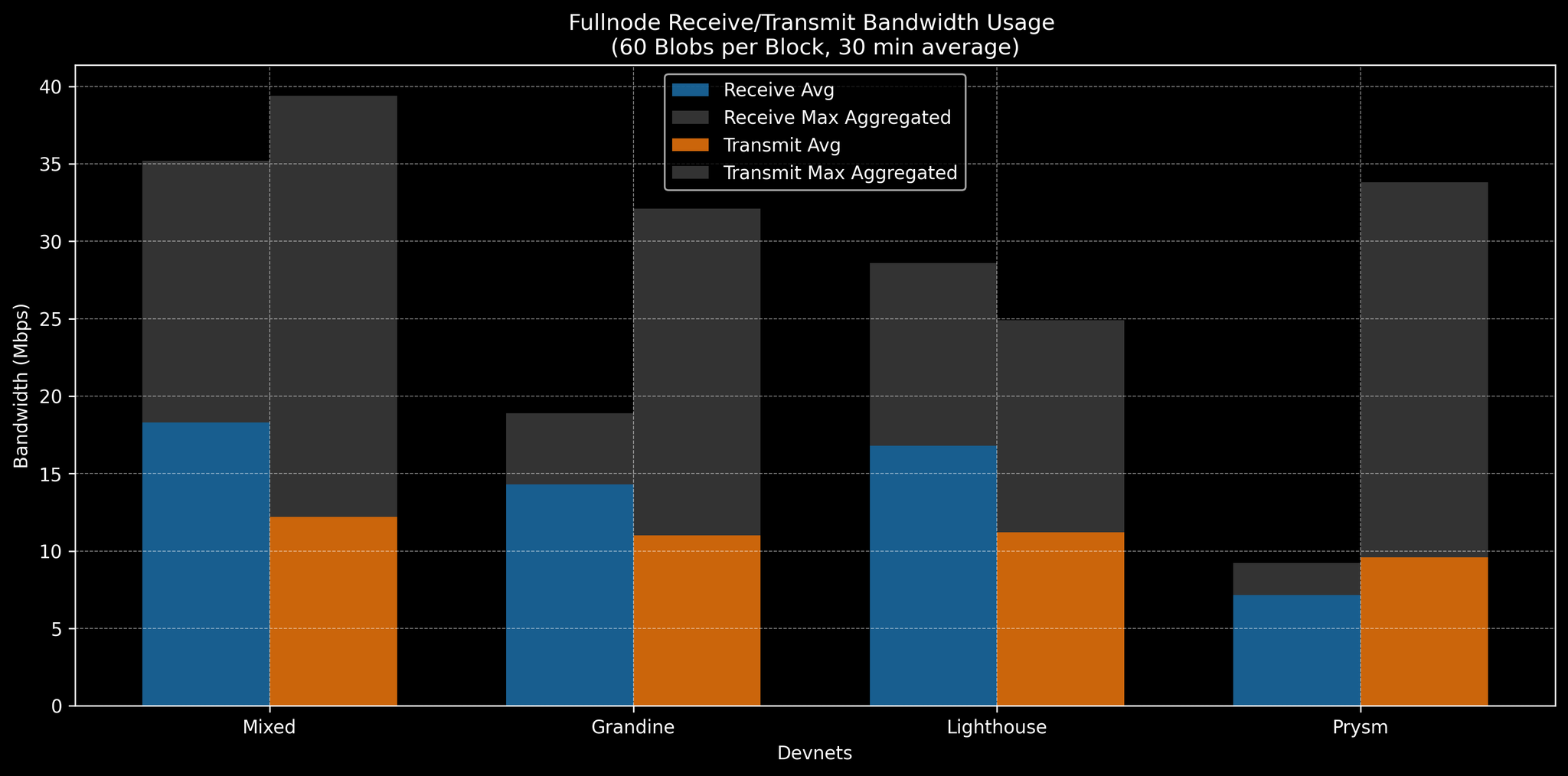
混合 Devnet 和单个 CL Devnet 的 60 个 blob/区块下的 Fullnode 带宽基准
ALT
2.1.2. Supernode
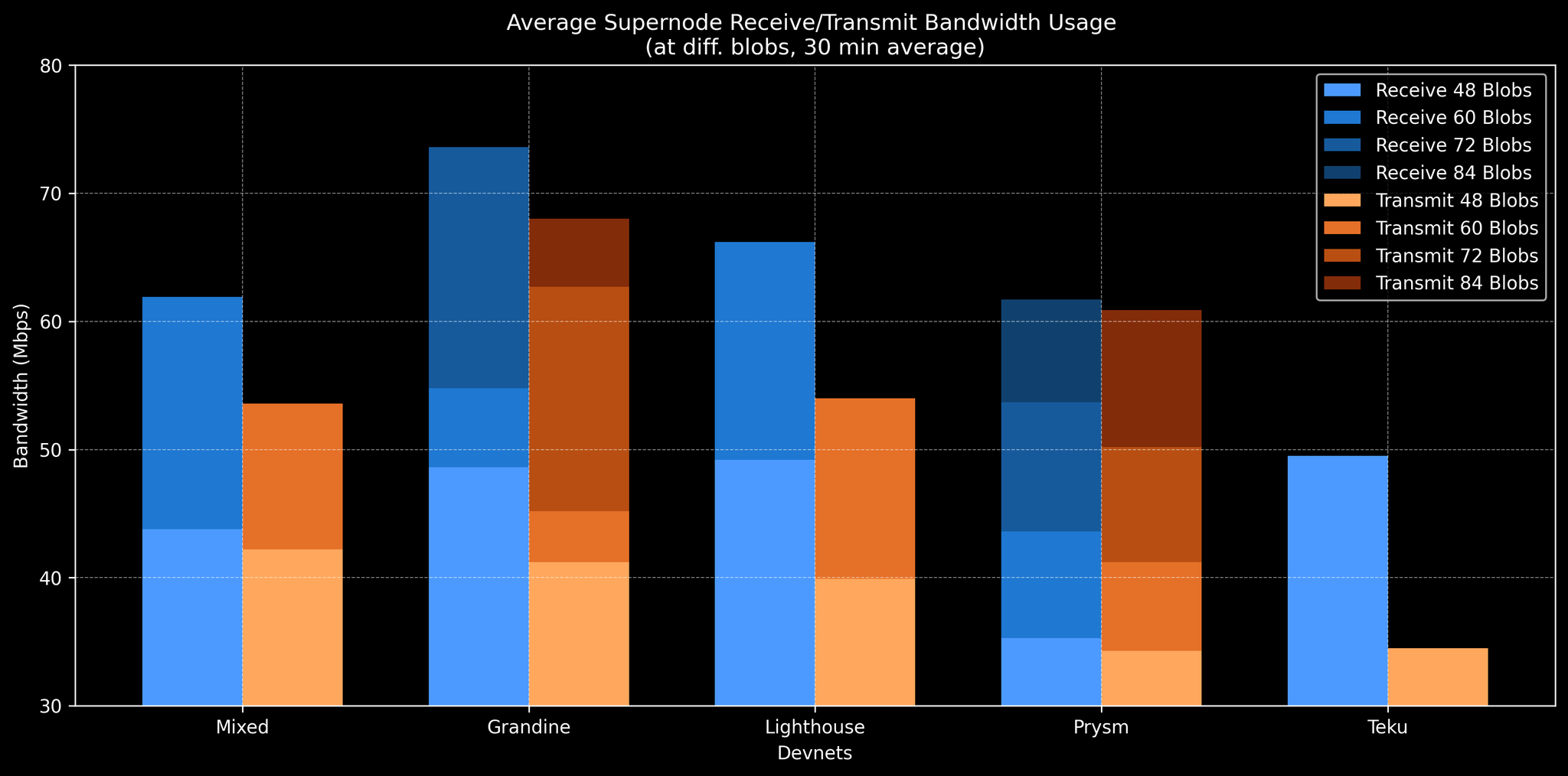
混合 Devnet 和单个 CL Devnet 中不同 blob 负载水平下的平均 supernode 带宽
ALT
毫不奇怪,Supernode 比 fullnode 使用更多的带宽。对于 supernode,使用率与 blob 计数大致线性缩放,与 fullnode 类似,但斜率更陡。在我们的测试中,supernode 的最大聚合使用率(入站或出站在峰值时)仅略高于 100 Mbps。我们假设超级节点运营商将具有非常好的互联网连接,因此 100+ Mbps 的突发应该是可以接受的。
2.2. 受突发流量限制
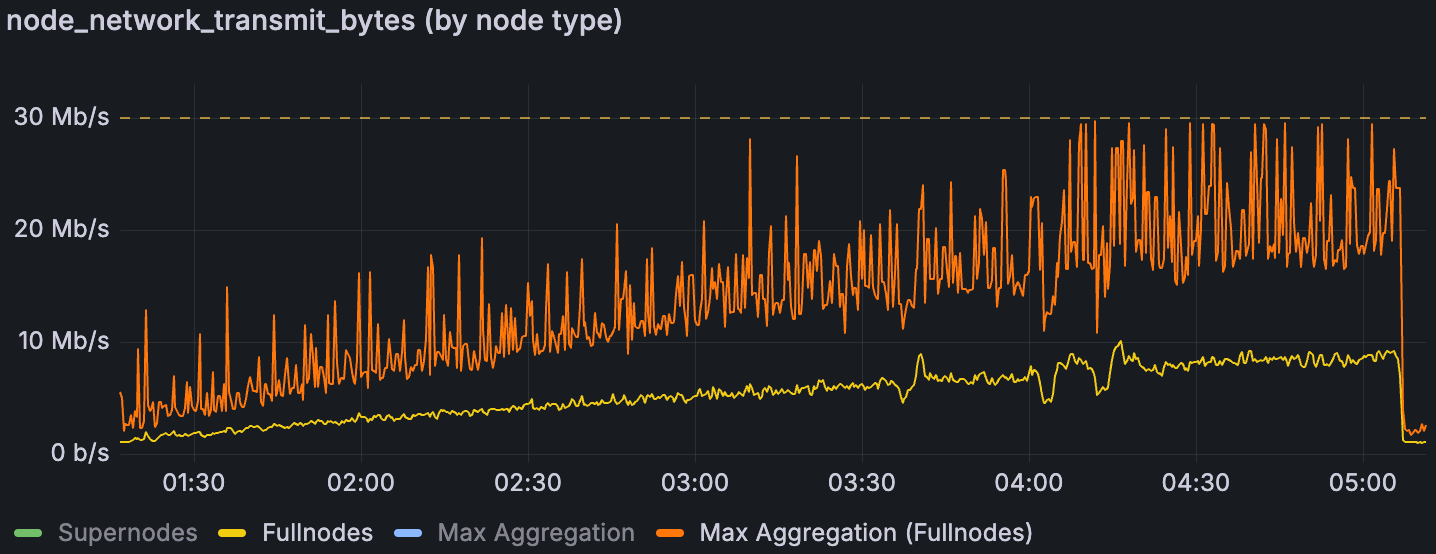
在 30 Mbps 上限测试中,我们观察到我们的流量控制脚本成功地将节点流量限制为设定的速率——在 Prometheus 数据中,入站和出站指标都保持在 ~30 Mbps 或更低。换句话说,节流按预期工作:节点没有超过施加的带宽上限。
重要的是要注意,我们的数据收集间隔(和 Prometheus 指标)会随时间平均,因此极其短的突发可能会被掩盖。例如,在每个 slot 开始时,会在几百毫秒内交换大量 gossip(blob 公告等)。这些突发可能会瞬间飙升至 30 Mbps 以上,但由于我们以较长的时间段进行采样,因此记录的值仍然可能显示在阈值以下。因此,可能存在比图表明确显示的更多的短暂突发活动。
一个关键发现是,blob 吞吐量受到这些突发时刻的限制。在测试 3 中,一旦入站和出站的峰值(突发)使用率开始频繁达到 30 Mbps,devnet 就无法进一步增加 blob 计数。即使每个节点的平均带宽使用率仍然非常低(通常 <10 Mbps),也会发生这种情况。这表明,耗尽带宽和限制系统的不是连续负载,而是峰值(gossip 泛滥等)。我们还注意到,出站与入站的突发模式不同,并且当网络受到限制与不受限制时,它们会发生变化(详见下文)。
2.2.1. 数据传输
混合 Devnet 网络在增加 blob 吞吐量时的上传(30Mbps Fullnode 带宽限制)
ALT
在带宽上限下,来自 fullnode 的出站数据平均 <10 Mbps,但查看各个节点,我们没有发现任何一个“坏角色”节点导致所有流量;相反,每个节点都会周期性地爆发。在无约束的 devnet 中,节点也会爆发,但这不成问题。在有上限的情况下,爆发行为会如何造成损害?当节点尝试发送超过 30 Mbps 的数据时,Linux HTB 整形器 会延迟或丢弃数据包。如果请求的 blob 数据块被延迟,请求的对等方可能会超时并向另一个对等方请求相同的数据,从而使流量成倍增加。我们怀疑这导致了一个反馈循环:延迟响应 -> 重复请求 -> 额外流量,这甚至可能淹没某些节点的传入带宽。因此,出站 节流 可能会因冗余数据而间接导致入站峰值。
2.2.2. 数据检索
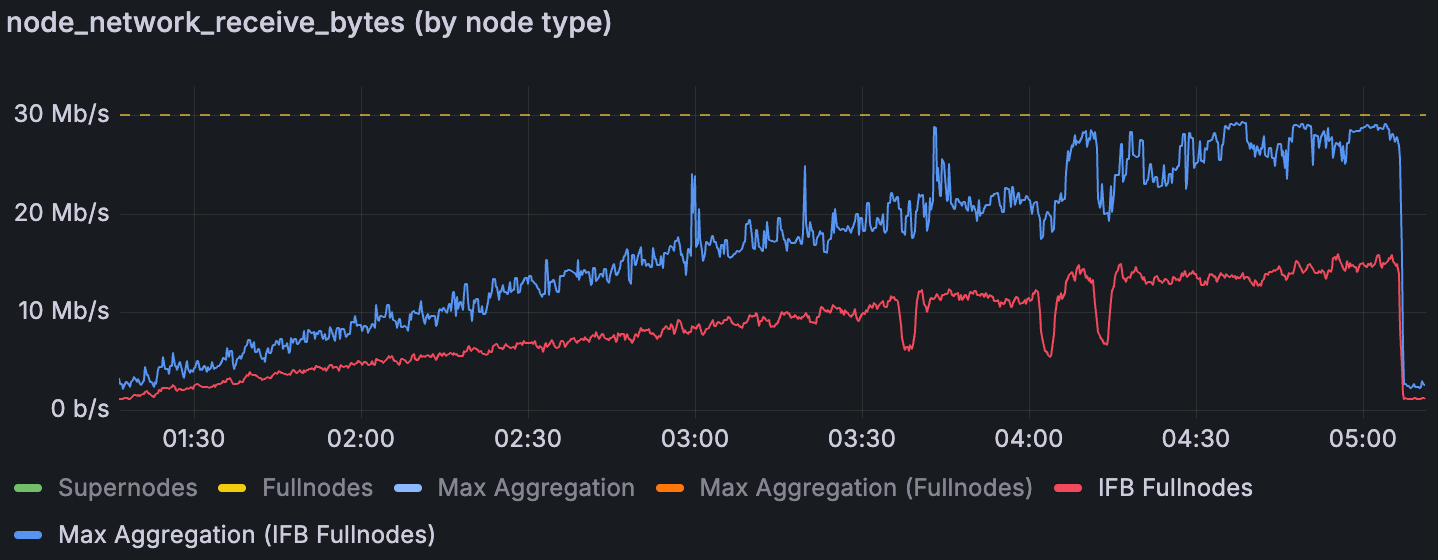
混合 Devnet 网络在增加 blob 吞吐量时的下载情况(30Mbps 全节点带宽限制)
ALT
同样,对于传入数据,在 30 Mbps 的上限下,每个节点的最大入站爆发远高于平均入站速率。(相比之下,在无上限的情况下,入站爆发并不那么明显——大多数全节点没有看到大的周期性下载峰值。)
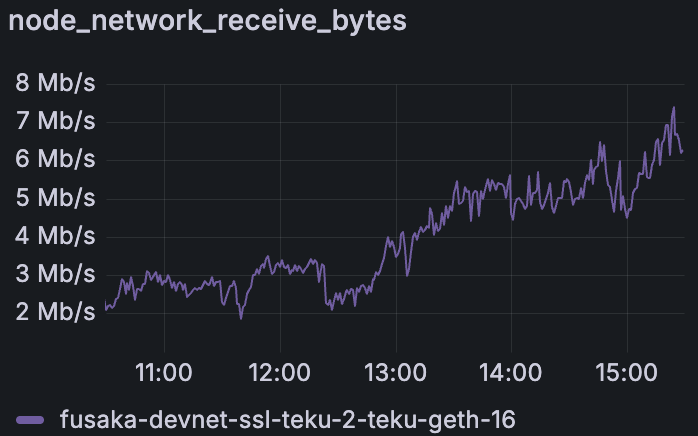
Teku Devnet 中全节点在增加 blob 吞吐量时的下载情况(无带宽限制)
ALT
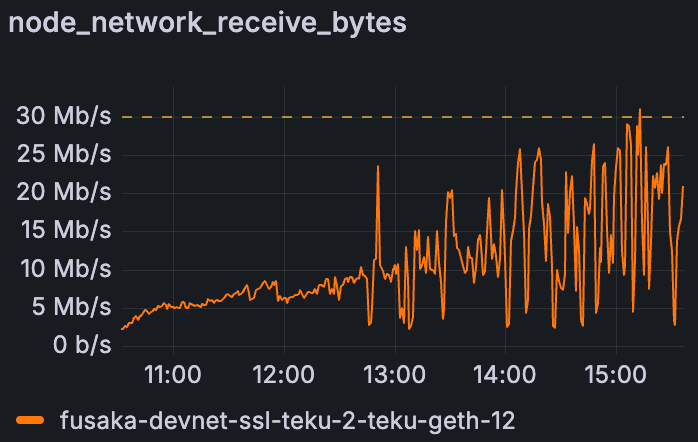
Teku Devnet 中全节点在增加 blob 吞吐量时的下载情况(30Mbps 带宽限制)
ALT
在我们查看的受限运行中,许多节点都显示出如上所述的入站爆发。本质上,当初始响应缓慢或丢失时,同一 blob 数据的多个副本会到达,从而导致请求节点上数据的突然涌入。这表明带宽限制可能会导致数据传输效率低下——这是潜在的优化点(例如,更智能的请求取消或对等方协调,以避免在低带宽设置中出现重复)。
2.3. 网络使用组成
从以上内容中,我们了解到当带宽受到限制时,爆发流量才是真正的瓶颈。现在,我们检查哪些类型的流量(gossip 消息等)负责这些爆发,无论是在正常情况还是受限情况下。
2.3.1. 数据传输
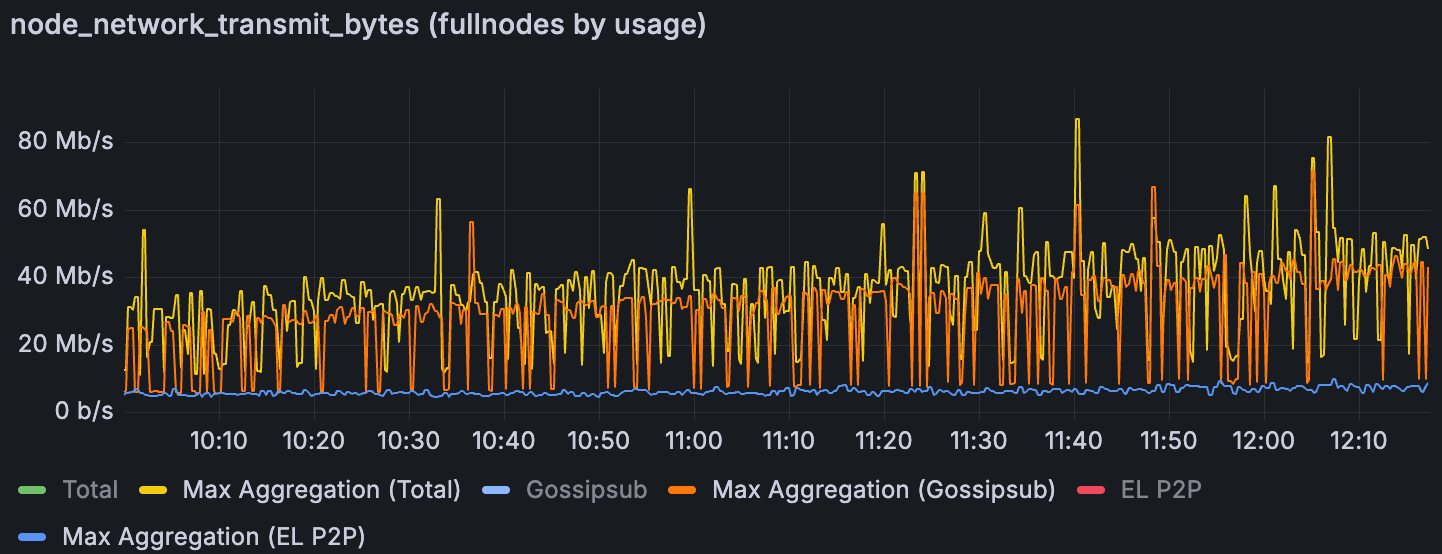
Lighthouse Devnet 中增加 blob 吞吐量时的最大聚合上传(无带宽限制)
ALT
在无约束的网络中,共识层 gossip(gossipsub)是传出数据爆发的主要驱动因素。在我们的测试中,与此相比,执行层 P2P 流量微不足道。出站流量的图表显示,gossipsub 吞吐量峰值与总出站使用量的峰值对齐。换句话说,当我们看到节点总传出带宽出现峰值时,几乎完全是由于 CL 八卦(blob 公告、证明等),而不是 EL 有效载荷。这是预期的,因为数据列传播是在 CL 级别通过 gossip 子网处理的。
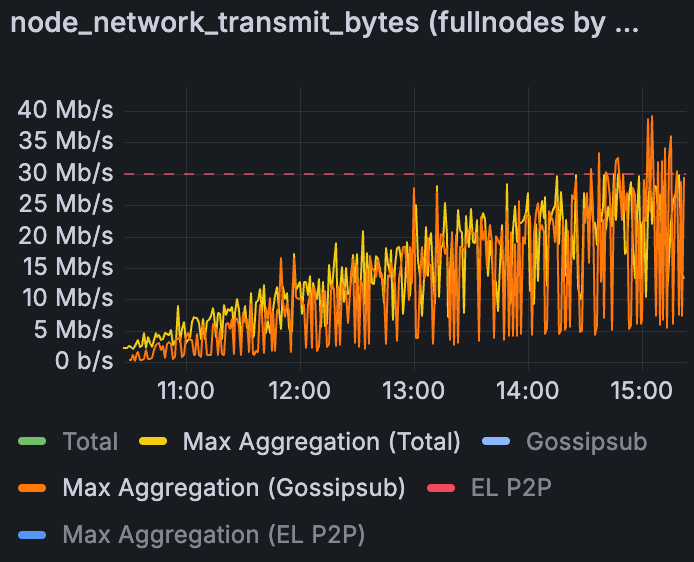
Grandine Devnet 中增加 blob 吞吐量时的最大聚合上传(30Mbps 带宽限制)
ALT
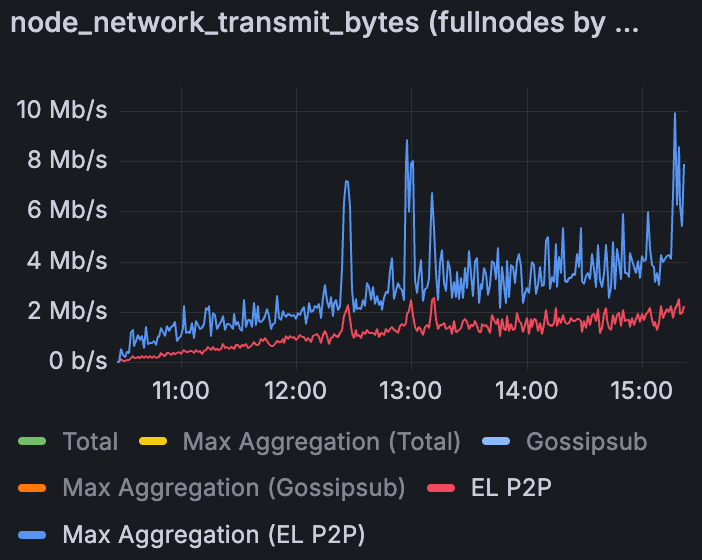
Grandine Devnet 中增加 blob 吞吐量时的 EL P2P 上传(30 Mbps 带宽限制)
ALT
在 30 Mbps 限制的情况下,一个有趣的观察是 CL 客户端的 gossipsub 内部指标显示尝试输出高于 30 Mbps。在操作系统级别测量的总出站流量保持在 30 Mbps(由 TC 限制),但是,例如,Lighthouse 节点的指标可能表明它尝试发送 40 Mbps 的 gossipsub 数据。这种差异是因为节点的网络堆栈正在推出数据,但操作系统正在排队/丢弃超过 30 Mbps 的数据包。因此,CL“认为”它发送了更多(并且确实生成了这些消息),但内核限制了实际在线传输的内容。这证实了如果允许,CL 八卦 将在 blob 爆发期间超过阈值——它们实际上是在尽最大努力并触及上限。
我们还看到 EL P2P 流量在带宽限制下开始显示爆发。在无限制测试中,EL 网络是安静的(没有爆发)。但是,在设置上限后,EL 节点(特别是 Erigon、Nethermind 等)开始更积极地爆发传输。我们没有发现单个 EL 节点负责——似乎所有 EL 实例都会有活动高峰时刻,可能是因为它们在上限的限制下难以及时获取 blob 事务或区块。这种额外的 EL 流量增加了网络的负载。随着 blob 数量的增加,CL 和 EL 之间的负载分配变得重要:如果两层同时爆发,可能会压垮低带宽连接。理想情况下,可以调整职责,使 CL 和 EL 网络不会同时达到峰值,从而帮助带宽有限的节点。这个领域可能需要进一步优化,并且在我们接近主网规模时将非常重要。
2.3.2. 数据检索
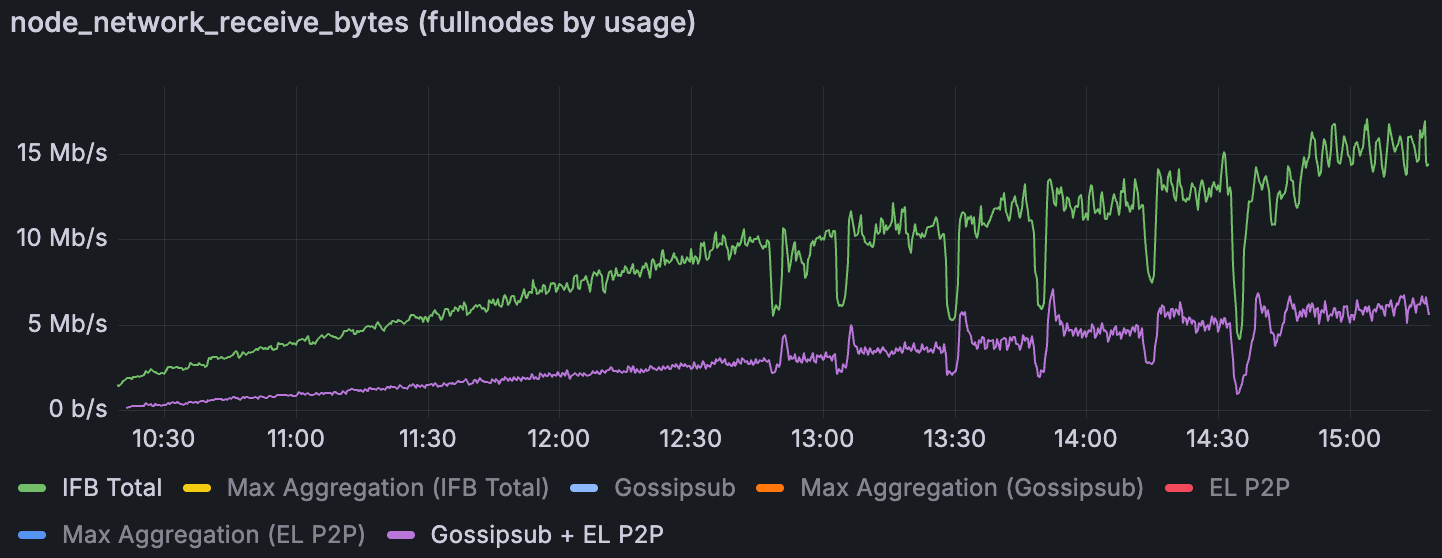
Lighthouse Devnet 中增加 blob 吞吐量时的平均下载(无带宽限制)
ALT
对于进入节点的数据,我们在受限场景中注意到一些令人困惑的事情。总入站带宽随 blob 数量的增长速度远快于仅由 CL 八卦 和 EL p2p 流量组合所能解释的速度。似乎有“其他”流量在贡献。可能,来自 gossip 主题的开销(其他消息类型)或协议效率低下在带宽紧张时变得很重要。结果是,在 30 Mbps 上限下,每个节点的总下载使用量急剧上升,超过了测量的 gossip 或 EL 下载指标的增长。我们目前尚不完全了解这种额外的入站数据是什么——这将需要进一步调查。它可能包括重复的 gossip 消息、libp2p 喋喋不休 或未在主要指标下分类的其他网络开销。这是未来分析的待办事项:查明在受限条件下是什么消耗了下载带宽。
2.4. EL 中的其他发现
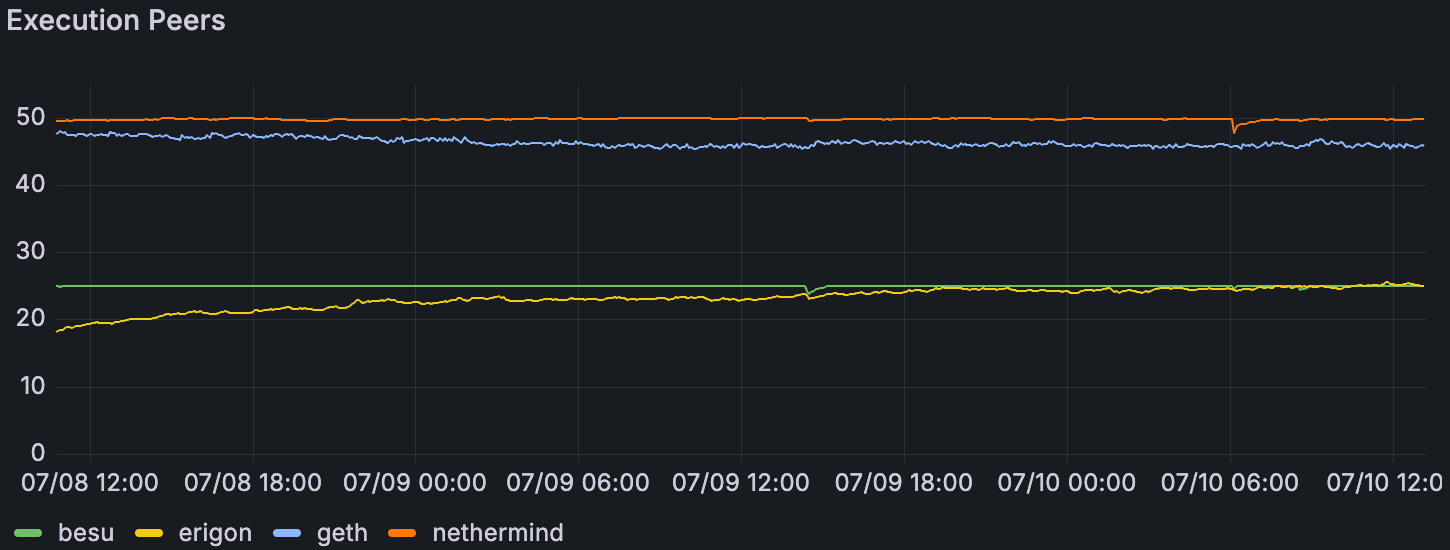
混合 Devnet 上每个 EL 的平均对等方数量,在 60 个 blob/块时
ALT
在混合 devnet 中发现了一些模式。我们可以看到不同 EL 之间的对等差异:Besu 和 Erigon 的对等方比 Geth 和 Nethermind 节点少得多。我们还看到在它们的单个 EL devnet 中完成的对等连接也较少。
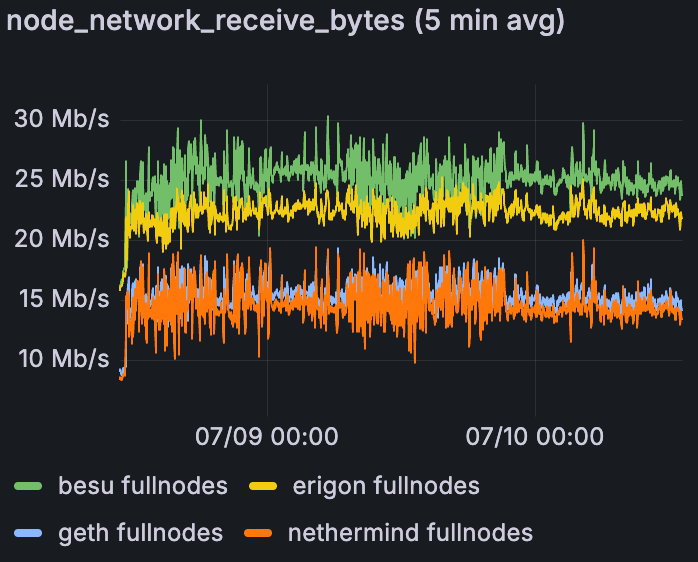
混合 Devnet 上每个 EL 的平均入站网络,在 60 个 blob/块时
ALT
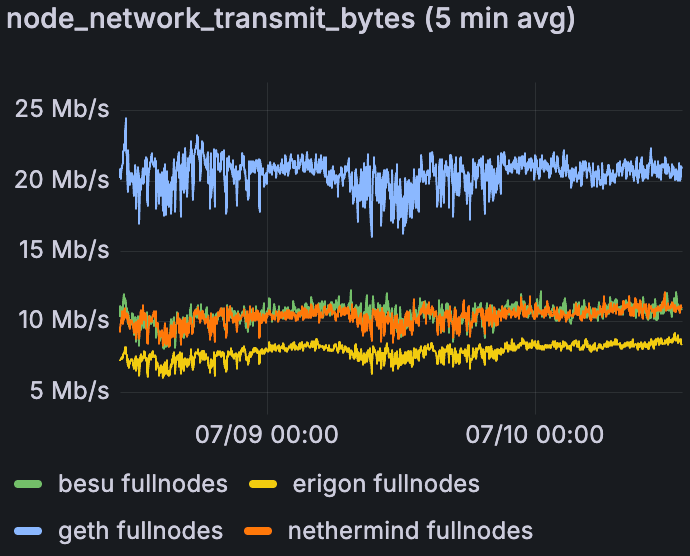
混合 Devnet 上每个 EL 的平均出站网络,在 60 个 blob/块时
ALT
Besu 和 Erigon 接收更多数据。
Geth 肯定比其他节点传输更多数据。
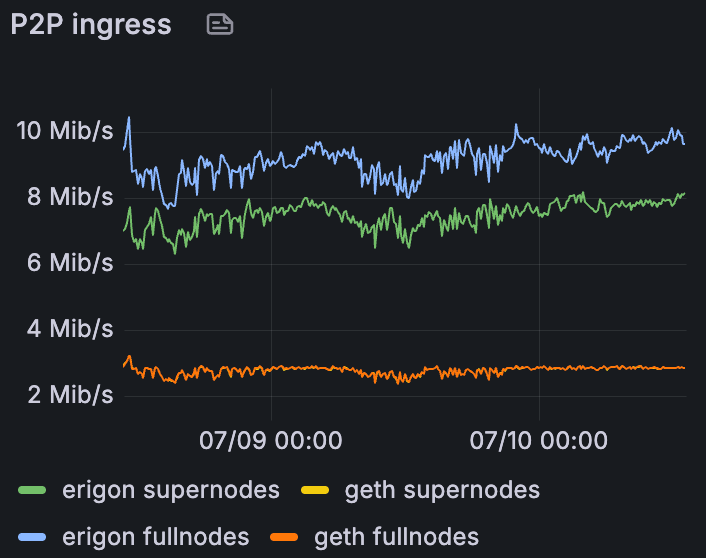
混合 Devnet 上 Erigon 和 Geth 的平均 P2P 入口,在 60 个 blob/块时
ALT
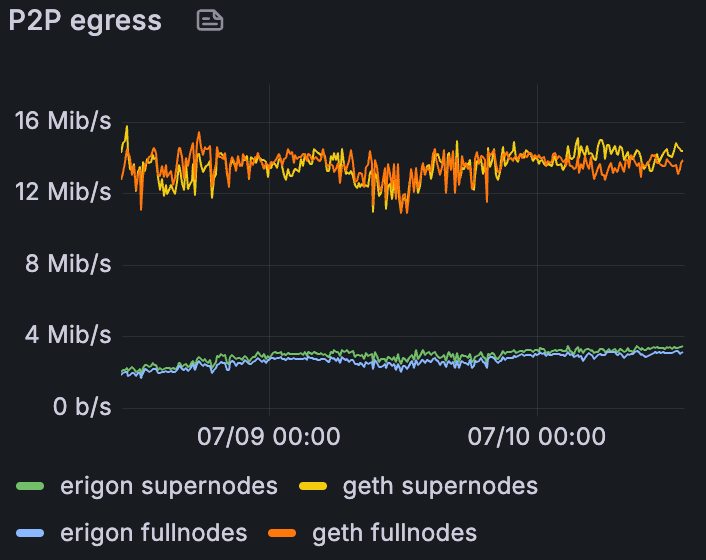
混合 Devnet 上 Erigon 和 Geth 的平均 P2P 出口,在 60 个 blob/块时
ALT
我们可以清楚地看到,Erigon 的入站远高于 Geth,而出站远低于 Geth。看起来它们的角色是相反的。
3. CPU 和 RAM 使用情况
在整个测试过程中,我们监控了节点资源使用情况。即使在高 blob 速率下,CL 和 EL 节点上的 CPU 使用率也保持在较低且稳定的水平。但是,我们确实观察到许多节点上的内存使用量(RAM)随着时间的推移而增加。在短期测试中,这并不明显,但在多小时的持续测试(测试 2)中,尤其是在多天的混合 devnet 运行中,节点内存消耗持续增长。这是在 EthPandaOps Fusaka-Devnet-2 活动期间报告的一个已知问题——本质上是客户端在处理许多 blob 事务时的内存泄漏或累积 错误。EL 团队此后实施了针对这些内存问题的修复程序。我们的第一次混合 devnet 运行可能遇到了这个限制:在高负载下运行约 36 小时后,许多节点崩溃或变得无响应,并且在检查后,我们看到它们已耗尽了可用的 RAM。
4. 创世 同步
我们对每个客户端组合执行了 创世(零状态)同步,以确保节点可以从 创世 启动并在启用 blob 的条件下赶上 头部。除了使用 Geth 作为 EL 的那些之外,所有 devnet 都从 创世 成功同步了每个 CL-EL 对。我们在 Discord 线程 上提出了这个问题,并且已经开发了一个修复程序——解决 Geth 同步 错误 的 拉取请求 目前正在审查中。一旦该修复程序合并并发布,我们将重新测试 Geth 的 创世 同步。除了 Geth 之外,没有其他客户端存在同步问题;这表明使用 blob(数据可用性采样等)进行 创世 初始化通常在客户端之间有效。
结论与讨论
在本轮 Sunnyside devnet 测试中,我们展示了重大进展,并了解了有关跨客户端的 blob 吞吐量和网络性能的宝贵经验。在共识层上,多个客户端(Grandine、Lodestar、Prysm)达到或超过了每个区块 72 个 blob 的目标,证实了可以实现高 blob 吞吐量。出现了一些差异——值得注意的是,在我们的 8 验证器配置中,Lighthouse 和 Teku 仅达到约 60 个 blob——突出表明最近的变化(或每个节点的验证器参与度降低)可能会影响 blob 传播。Nimbus 也在迎头赶上并迅速表现更好。同时,在执行层上,所有经过测试的客户端都证明有能力在正确连接时处理最大 blob 负载。Reth 需要干预才能达到该水平,这突出了强大的对等交换机制的重要性。
我们的持续负载测试证实,长时间保持高 blob 吞吐量是可行的。除了一个 Teku 运行显示在 60 个 blob 标记处存在一些不稳定性之外,每个 devnet 都在高吞吐量下运行了数小时而没有失败。一个客户端 devnet (Grandine) 令人印象深刻地在 ~84 个 blob 时运行了 16 个多小时而没有出现任何问题,并且我们的混合客户端网络在两天内保持了 60 个 blob。这些结果表明,共识和执行引擎可以处理长时间的 blob 密集型工作负载,尽管它们也揭示了一个微妙的内存泄漏问题。观察到的内存使用量增长与之前的发现(来自 EthPandaOps 测试)一致,但令人欣慰的是,客户端团队已在最近的更新中解决了这个问题。通过这些修复程序,我们预计在后续测试中会有更好的内存性能。CPU 在很大程度上不是这些试验中的一个因素,因为即使是最繁忙的节点也有充足的处理空间。
也许最具洞察力的发现来自网络带宽研究。通过限制带宽,我们发现,正是短暂的爆发流量——特别是在 blob 被 八卦 时段开始时——对吞吐量施加了真正的限制,而不是稳态带宽消耗。即使节点在 60 个 blob 时平均仅为 ~10-20 Mbps,~30 Mbps 的峰值也足以在设置上限时限制系统。这解释了为什么 ~60 个 blob 是 30 Mbps 上限下的平台期。这也表明仅为平均带宽配置是不够的;我们需要考虑爆发容量或找到平滑这些爆发的方法。流量组成的分析证实,gossipsub (CL 层) 是这些爆发的主要来源,并且它揭示了在压力下,EL 层也会贡献意想不到的爆发。
总之,这些 devnet 实验提供了一个暗示,说明我们离 blob 吞吐量目标有多近,以及大规模的网络约束是什么样的。所有主要客户端在理想条件下都能达到高 blob 计数的能力对于 Fusaka 来说是令人鼓舞的。但是,对带宽的敏感性和爆发驱动限制的普遍存在意味着我们可能需要进一步优化实施。即使对于带宽适中的 质押者,也必须确保数据可用性传播保持强大。我们将继续与客户端团队合作处理这些发现。发现的每个问题都是在主网之前加强系统的机会。
后续步骤
我们正在与 EthPandaOps 和其他团队讨论下一组测试。各种互操作性和压力测试场景都在讨论中。我们计划在 Discord 上进一步沟通,并在 Fusaka-Devnet-2 结束前发布另一份报告。
附录
附录 A. 网络带宽限制脚本
对于出站流量,使用具有 1Mbps 爆发的 HTB 来优雅地限制给定的
带宽
Mbps。
对于入站流量,创建一个名为
ifb0
的虚拟网络接口,使用 IFB,
eth0
将其流量重定向到该接口。然后使用与使用 HTB 限制出站流量相同的方法限制 ifb0 的出站流量,以模拟下载速度限制。这是因为 TC 实际上不支持除了丢弃数据包之外的这种优雅的带宽限制。
当应用此脚本时,测量
ifb0
而不是
eth0
对于入站流量,对于带宽受限的节点是正确的。
# Outbound limit (egress)
tc qdisc add dev eth0 root handle 1: htb default 1
tc class add dev eth0 parent 1: classid 1:1 htb rate {{ bandwidth }}mbit burst 1mbit
# Inbound limit (ingress)
modprobe ifb
iplinkadd ifb0 type ifb
iplinkset ifb0 up
tc qdisc add dev eth0 handle ffff: ingress
tc filter add dev eth0 parent ffff: protocol all u32 match u32 00 action mirred egress redirect dev ifb0
tc qdisc add dev ifb0 root handle 1: htb default 1
tc class add dev ifb0 parent 1: classid 1:1 htb rate {{ bandwidth }}mbit burst 1mbit
附录 B. Grafana 仪表板
对于团队,请索取凭据以访问 仪表板
| Devnet | Blob 基准测试 | 带宽基准测试 | 带宽限制 |
|---|---|---|---|
| 混合 Devnet | 增加 Blob | 48 个 Blob (24 小时) 60 个 Blob (36 小时) 60 个 Blob (48 小时) | 30 Mbps |
| Grandine Devnet | 增加 Blob | 48 个 Blob 60 个 Blob 72 个 Blob 84 个 Blob | 30 Mbps |
| Lighthouse Devnet | 增加 Blob | 48 个 Blob 60 个 Blob | 30 Mbps 20 Mbps 10 Mbps |
| Lodestar Devnet | 增加 Blob | 48 个 Blob 60 个 Blob 72 个 Blob 84 个 Blob | |
| Nimbus Devnet (Interop) | 增加 Blob | ||
| Nimbus Devnet | 增加 Blob 1 增加 Blob 2 | ||
| Prysm Devnet | 48 个 Blob 60 个 Blob 72 个 Blob 84 个 Blob | 30 Mbps | |
| Teku Devnet | 增加 Blob | 48 个 Blob | 30 Mbps |
| Besu Devnet | 增加 Blob | ||
| Erigon Devnet | 增加 Blob | ||
| Nethermind Devnet | Blob 吞吐量 | ||
| Reth Devnet | 增加 Blob 增加 Blob(带 Peeroor) |
附录 C. 客户端镜像
| Devnet | 镜像 |
|---|---|
| 混合 Devnet | 下方的 CL & EL devnet-2 镜像 |
| Grandine Devnet | CL: grandine:fusaka-devnet-2-55923b9<br>EL: geth:fusaka-devnet-2-df12e79 |
| Lighthouse Devnet | CL: lighthouse:fusaka-devnet-2-af8f25e<br>EL: geth:fusaka-devnet-2-df12e79 |
| Lodestar Devnet | CL: lodestar:fusaka-devnet-2-7ced4f6<br>EL: geth:fusaka-devnet-2-df12e79 |
| Nimbus Devnet (Interop) | CL: nimbus-eth-2:berlinterop-devnet-2-35f1182<br>EL: nethermind:fusaka-70a2c12 |
| Nimbus Devnet | CL: nimbus-eth-2:fusaka-devnet-2-738e228<br>EL: geth:fusaka-devnet-2-df12e79 |
| Prysm Devnet | CL: prysm-beacon-chain:fusaka-devnet-2-41eaa96<br>EL: fusaka-devnet-2-df12e79 |
| Teku Devnet | CL: fusaka-devnet-2-1628c34<br>EL: fusaka-devnet-2-df12e79 |
| Besu Devnet | CL: prysm-beacon-chain:fusaka-devnet-2-41eaa96<br>EL: besu:fusaka-devnet-2-63ef633 |
| Erigon Devnet | CL: prysm-beacon-chain:fusaka-devnet-2-41eaa96<br>EL: erigon:fusaka-devnet-2-277d70e |
| Nethermind Devnet | CL: prysm-beacon-chain:fusaka-devnet-2-41eaa96<br>EL: nethermind:fusaka-devnet-2-b05b241 |
| Reth Devnet | CL: prysm-beacon-chain:fusaka-devnet-2-41eaa96<br>EL: reth:fusaka-devnet-2-7bdcf88 |
附录 D. 每个 Devnet 的接收/传输基准原始数据
数据顺序如下:fullnode 平均值 / fullnode 最大聚合值 / supernode 平均值 / supernode 最大聚合值。
单位为 Mbps,3.s.f.
接收数据
| Devnet | 48 个 Blob | 60 个 Blob | 72 个 Blob | 84 个 Blob |
|---|---|---|---|---|
| 混合 | 9.49/20.5/43.8/72.5 | 18.3/35.2/61.9/97.2 | ||
| Grandine | 11.9/16.3/48.6/70.9 | 14.3/18.9/54.8/76.3 | 17.3/22.3/73.6/100 | 10.7/15.5/70.8/102 |
| Lighthouse | 11.1/16.0/49.2/65.0 | 16.8/28.6/66.2/88.9 | ||
| Lodestar | 41.6/60.3/32.0/47.7 | 51.0/72.7/38.2/72.8 | 59.2/82.1/45.1/82.1 | 67.0/92.9/52.1/93.3 |
| Prysm | 6.21/8.16/35.3/52.5 | 7.15/9.22/43.6/68.0 | 8.10/10.5/53.7/79.1 | 9.05/11.8/61.7/90.5 |
| Teku | 13.3/14.2/49.5/69.9 |
传输数据
| Devnet | 48 个 Blob | 60 个 Blob | 72 个 Blob | 84 个 Blob |
|---|---|---|---|---|
| 混合 | 9.82/32.3/42.2/83.2 | 12.2/39.4/53.6/103 | ||
| Grandine | 9.08/26.7/41.2/63.5 | 11.0/32.1/45.2/67.4 | 13.4/40.3/62.7/89.2 | 15.7/42.9/68.0/101 |
| Lighthouse | 7.92/18.1/39.9/55.2 | 11.2/24.9/54.0/74.0 | ||
| Lodestar | 24.3/49.1/34.5/66.6 | 27.3/58.1/43.2/81.3 | 29.8/68.8/51.7/98.1 | 31.5/79.6/60.9/116 |
| Prysm | 8.07/28.1/34.3/53.3 | 9.58/33.8/41.2/67.7 | 11.4/39.0/50.2/81.9 | 12.9/47.5/57.8/91.9 |
| Teku | 9,41/34.8/34.5/68.3 |

Jae Hee Lee
7 月 14 日
Reth 团队从 ACDT 确认,这个问题现在已修复
- 原文链接: testinprod.notion.site/2...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
