理解 Solana:指令与消息——第三部分
本文系统讲解了 Solana 交易的底层结构:instruction 由 program id、账户列表和数据组成,message 则把多个 instruction、签名者和 recent blockhash 组织成可验证的原子单位。
在此之前,我们探讨了 Solana 的并行架构和 account model——数据如何存在于链上、谁可以修改它,以及为什么 Sealevel 能够实现真正的并发。
但仅有 account 还不足以改变状态。Solana 上的每一次更新,从转移 token 到创建 PDA,都是通过由 instructions 组成的 transactions 来完成的。
在这篇文章中,我们会拆解从钱包点击到链上执行之间真正发生了什么:
1. transaction 在底层是如何构造的,
2. runtime 如何将 instructions 路由到 programs,
3. accounts 如何被锁定,以实现安全的并行执行,
4. “signing”、“message” 和 “recent blockhash” 到底是什么意思。
到最后,你将理解 Solana 如何逐步对 transactions 进行编码、验证和执行,以及如何直接从你的代码中构建、模拟并发送它们。
Instructions
Instructions 是 Solana 上的核心执行单元。你可以把每个 instruction 看作链上 program 暴露出的一个函数调用。每个 program 都定义了自己的 instruction set,也就是它能够执行的具体操作。当你与网络交互时,你不会直接调用 programs,而是把它们的一个或多个 instructions 打包进一个 transaction,签名后提交执行。
Instruction 由以下部分组成
- ProgramId
- Accounts
- Instruction specific data
ProgramId
包含该 instruction 逻辑的 program 的链上 Id(地址)。
Accounts
每个 instruction 都包含一个 AccountMeta 条目数组,这些元数据描述了它将从哪些 account 读取或向哪些 account 写入。通过显式列出这些 accounts,Solana 的 runtime 可以判断哪些 instructions 是彼此独立的,并且只要它们不修改同一个 account,就能安全地并行执行。
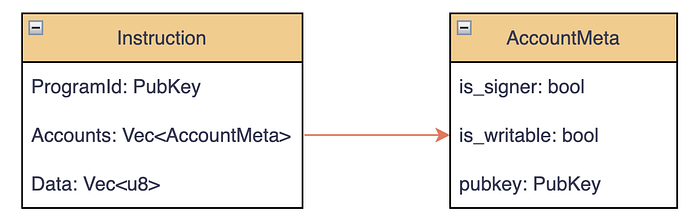
is_signer: 如果该 account 必须对 transaction 签名,则设为trueis_writable: 如果该 instruction 会修改该 account 的数据,则设为truepubkey: 该 account 的 public key 地址
Data
instruction 的 data 字段是一串字节,用于告诉 program 要执行哪个具体函数,并包含该调用所需的参数。
示例(Simple 0.01 SOL 转账)
{
"program_id": "11111111111111111111111111111111",
"accounts": [\
{\
"pubkey": "6uR7N6oDgE3vJXvM6Eh4xVHw2g7o7YhA7FJxC4pXcZtT",\
"is_signer": true,\
"is_writable": true\
},\
{\
"pubkey": "3Nq8yVbGz7KpYw9sT6rF2LmHc4Qz5XvA1uJd8BvCzRy",\
"is_signer": false,\
"is_writable": true\
}\
],
"data": [2, 0, 0, 0, 128, 150, 152, 0, 0, 0, 0, 0]
}
program_id
这是 System Program,Solana 的内置 program,用于管理原生 SOL 转账、创建 accounts 和分配 ownership。每个 validator 默认都会包含这个 program。这告诉 runtime:调用 System Program 执行它的某个函数。
accounts:
6uR7…ZtT:发送方,必须签名且可被修改(lamports 将被扣除)。
3Nq8…zRy:接收方,可写,因为 lamports 将被增加,但不需要签名。
data:
每个 data 变体都按 [variant_index:u32][variant_payload] 编码。
在我们的例子中:
pub enum SystemInstruction {
CreateAccount { ... },
Assign { ... },
Transfer { lamports: u64 },
...
}
Transfer 变体的索引是 2,其载荷是 u64(8 字节)。
[2, 0, 0, 0, 128, 150, 152, 0, 0, 0, 0, 0]
which is:
[02 00 00 00 | 80 96 98 00 00 00 00 00] // 4 + 8 = 12
[0:4) bytes\
- Type: u32
- Value: 2 —— 在这个 program source code 中,我们可以看到 Transfer 在 SystemInstruction enum 中的索引是 2
[4:12) bytes\
- Type: u64
- Value: 10000000 lamports
[2, 0, 0, 0] → discriminant = 2
[128, 150, 152, 0, 0, 0, 0, 0] → bytes to hex
[80 96 98 00 00 00 00 00] → hex representation
[0x00000000989680] → 0x00989680 = 10_000_000 lamports (0.01 SOL)
Messages
Solana 上的一个 transaction 不只是一个 instructions 列表,它还是一个由一个或多个 accounts 签名的 message。message 精确定义了 将运行什么、涉及哪些 accounts,以及 哪个 recent blockhash 将其锚定到链的当前状态。
Solana 签名的是 message,而不是逐个 instruction 单独签名。这种设计让 transactions 更紧凑且可验证:validator 只需要检查签名者是否授权了网络收到的同一份 message 字节。
一旦 signatures 被验证,runtime 就会按顺序执行这些 instructions,并以原子方式提交所有更改——要么全部成功,要么整个 transaction 回滚。
换句话说:
- The message is the canonical record of “what should happen”
- The signature just proves “who approved it”
Legacy 和 Versioned Messages
最初,所有 Solana transactions 都使用一种单一的 message 格式,现在称为 legacy message。它对简单转账和小型 program 很有效,但每个 transaction 都必须列出它将读取或写入的 所有 accounts(为了并行执行)。
由于每个 account 地址都是 32 字节,message 总大小会迅速增长,而 Solana 对包大小施加了严格上限(序列化后的 transactions 约为 ≈ 1232 bytes),以适配网络 MTU。这使得 legacy transactions 只能包含大约 35 个 accounts,这对需要同时与多个 programs 交互的复杂、可组合的 DeFi protocols 来说成了问题。
为了解决这个问题,Solana 引入了 versioned transactions,从 v0 messages 开始,同时引入了一个新的链上 program,称为 Address Lookup Table (ALT) program。
Lookup tables 允许开发者把一组 addresses 存储在链上,并在之后通过很小的 1-byte indexes 引用它们,而不是完整的 32-byte keys。这样 transaction 在执行期间就可以“查找”额外的 accounts,而不会超过大小限制。
Legacy Messages
pub struct Message {
pub header: MessageHeader,
pub account_keys: Vec<Address>,
pub recent_blockhash: Hash,
pub instructions: Vec<CompiledInstruction>,
}
pub struct MessageHeader {
pub num_required_signatures: u8,
pub num_readonly_signed_accounts: u8,
pub num_readonly_unsigned_accounts: u8,
}
// As learned previously
pub struct CompiledInstruction {
pub program_id_index: u8,
pub accounts: Vec<u8>,
pub data: Vec<u8>,
}
Note:
#[serde(with = "short_vec")]很重要,我们稍后会看到原因
它可以容纳大约 35 个 accounts(35 * 32(address size) = 1120bytes out of 1232)。我们可以看到,它包含固定的 header、accounts、blockhash 和 instructions,适用于简单或中等复杂度的 transactions。
Versioned Messages
pub enum VersionedMessage {
Legacy(LegacyMessage),
V0(v0::Message),
}
pub struct Message {
pub header: MessageHeader,
pub account_keys: Vec<Pubkey>,
pub recent_blockhash: Hash,
pub instructions: Vec<CompiledInstruction>,
/// 用于加载该 transaction 额外 accounts 的 address table lookups 列表。
#[serde(with = "short_vec")]
pub address_table_lookups: Vec<MessageAddressTableLookup>,
}
pub struct MessageAddressTableLookup {
pub account_key: Pubkey,
#[serde(with = "short_vec")]
pub writable_indexes: Vec<u8>,
#[serde(with = "short_vec")]
pub readonly_indexes: Vec<u8>,
}
Transactions 必须适配约 1232 bytes 的 packet payload。将每个 account 都内联列出(每个 32 bytes)会把 legacy messages 的上限限制在大约 35 个 accounts,还要扣除 signatures 和其他开销。V0 引入了 Address Lookup Tables (ALTs),因此一个 message 可以通过 1-byte indexes 引用更多 accounts,而不是内联 32-byte pubkeys。
Address lookup 如何工作
在 runtime 中,validator 会构造一个统一的 resolved account list,instructions 会对其进行索引:
resolved_keys =
[ message.account_keys
, looked_up_writable_keys (from all ALTs, in order)
, looked_up_readonly_keys (from all ALTs, in order)
]
每个 MessageAddressTableLookup 都指向一个特定的链上 ALT(account_key)。
writable_indexes 和 readonly_indexes 是该 ALT 中存储地址的 u8 indexes。
runtime 会获取这些 pubkeys,并将它们按两组 追加 到 resolved_keys 中:
- 所有 writable lookups(保持跨 tables 的顺序)
- 所有 readonly lookups(保持跨 tables 的顺序)。
program_id 和 accounts 仍然像 legacy messages 一样,精确指向这个 combined list。
如何识别 v0
Versioned transactions 使用 message 编码中的 leading version bit:
- 如果第一个字节的最高位被 置位,其余位编码一个 version number(v0 = 0)。
- 如果未置位,则视为 legacy message。
你通常不会直接处理这个,SDKs 会负责,但这也是 v0 和 legacy 能够共存的原因。
大小影响
v0 会增加少量开销,但在需要很多 accounts 时会大幅减少内联 key 字节数。
每笔 transaction 增加的开销(约)至少包括:
- +1 byte:version tag
- +1 byte:address_table_lookups length
- +34 bytes per lookup table(32 bytes 用于 table pubkey + 1 + 1 用于 writable/readonly index arrays 的长度)
- +1 byte per looked-up index(ALT 中的每个 index)
节省的空间: 每个 looked-up address 用 message 中一个 1-byte index 替代一个 32-byte 的 inline pubkey。
当你要引用几十到几百个 accounts 时,这个权衡非常划算。
需要记住的限制和规则
- 每个 ALT 最多 256 项。 Indexes 是 u8。
- 最多可整体加载 256 个 unique accounts(因为 compiled instruction 的 account indexes 也是 u8)。
- Signers 不能来自 ALTs。 所有 signer keys 必须出现在 account_keys 中,以便高效验证它们的 signatures。
- 不能有重复项。 同一个 account 不能在 account_keys 和 ALT lookups 中被加载超过一次。
- ALT 可用性: 新追加的 ALT 条目会在 一个 slot 之后 才可用(warm-up)。
- ALT 生命周期: Tables 必须满足 rent-exempt,采用 append-only,可以被 deactivate,并且只能在 cooldown 之后关闭,以避免 censorship/race 问题
让我们理解这些数字以及为什么是这些限制
让我们看看前面那些令人困惑的说法。
每个 ALT 最多 256 项。Indexes 是 u8: 每个 Address Lookup Table (ALT) 最多可以存储 256 个 addresses,因为用于引用它们的 indexes 是 u8(1 byte)。
pub writable_indexes: Vec<u8>,
pub readonly_indexes: Vec<u8>,
这些 vectors 中的每个元素都是单个字节,范围是 0–255。
所以当我们说:
writable_indexes = [0, 2, 4, 6]
runtime 会从该 table 的链上存储中加载第 0、2、4、6 个 addresses。因此 最多 256 是因为 u8 可以编码 0–255 个可能值,这意味着 每个 lookup table 最多 256 个 unique entries
(这是不可能的:writable_indexes = [0, 2, 310] )。
1 byte: address_table_lookups length 首先可能会想到的问题是,为什么长度只有 1 byte,明明它是一个理论上可以无限增长的 vector。关键在于:
#[serde(with = "short_vec")] 这意味着 这个 Solana 序列化结构中的 Vec<…> 使用的是 short_vec 格式。
这就是 Bincode(通过 short_vec module)高效序列化变长数组的方式:\ [length (1-9 bytes)][elements...]\ 对于小 vectors(length < 128),长度可以放进单个 byte 中。如果你有 3 个 lookup tables,这个 length byte 实际上会是 0x03。
这意味着在序列化它们的内容之前,会先额外增加 一个 byte 来表示附加了多少个 lookup tables。
每个 lookup table 34 bytes(32 + 1 + 1) 这与上一条相同,看一下:
pub struct MessageAddressTableLookup {
pub account_key: Pubkey,
#[serde(with = "short_vec")]
pub writable_indexes: Vec<u8>,
#[serde(with = "short_vec")]
pub readonly_indexes: Vec<u8>,
}
使用 #[serde(with = "short_vec")] 序列化,意味着每个 MessageAddressTableLookup 至少需要 34 bytes,再加上每个 entry 的 N-bytes。
MessageHeader
header 告诉 runtime 有多少个 accounts 必须签名,以及哪些 accounts 是 read-only。
它是 runtime 用来理解如何解释 account_keys 切片的前导信息。
num_required_signatures (u8)
account_keys 中最前面的多少个必须提供 signatures。
- 如果这是 1,那么 account_keys 中第一个 key 就是 signer。
- 如果这是 2,那么前两个 keys 就是 signers,依此类推。
这些 signatures 来自 transaction 的 signature array。每个 signer 都必须与其在 account_keys 中的位置相匹配。
num_readonly_signed_accounts (u8)
在 signer accounts 中(即 前 num_required_signatures 个),有多少个是 read-only。它们可以被 读取,但 program 不能修改 它们的 account data 或 lamports。这可以防止在 signer accounts 不需要可写时被意外或恶意修改。
示例:
- 用户使用他们的钱包签署 transaction(signer),
- 但该 wallet account 从未被写入,因此它应保持为 read-only。
num_readonly_unsigned_accounts (u8)
在 non-signers 中(其余 accounts),有多少个是 read-only。
这为什么重要:
某些 accounts 会作为 read-only 被传给 program,例如 system program、token program、metadata program。将它们标记为 read-only 可以提升安全性和性能。
recent_blockhash
这个字段用于防止 replay attacks,并设置一个 liveness requirement。
Solana 不使用 nonces。
相反,每个 transaction 都必须包含一个来自最近约 150 个 blocks(≈ 2 分钟)的 recent blockhash。
为什么需要它
Anti-replay 如果有人复制了你已签名的 transaction 并试图再次提交,它会被拒绝,因为 blockhash 已经过期。
Transaction expiration Solana 要求 transactions 必须是“fresh”。
如果 blockhash 太旧,validator 不会接受这笔 transaction。
Fork commitment Validators 认为基于 recent blockhash 构建的 transactions 属于当前 fork,从而减少歧义。
Summary
你现在应该已经理解了 Solana 如何构造每个 transaction 背后的逻辑。一个 instruction 定义要运行什么——program、accounts 和 data;而一个 message 则把这些 instructions 打包成一个可签名、可验证的原子单元。Legacy messages 适用于大多数场景,但 v0 messages 通过 Address Lookup Tables 扩展了这种格式,使得可以通过紧凑的 1-byte indexes 引用更多 accounts。
简而言之,你现在已经知道 Solana 是如何对 transaction 中发生的事情进行编码的。
- 原文链接: medium.com/@andrey_obruc...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
