如何让AI精准模仿你的写作风格
本文提供一套详细的方法,让任何人通过创建个人'about-me'文件,使AI(如Claude、ChatGPT等)精确模仿自己的写作风格和品味。
因为你只是一个文本文件。
你只是一个文本文件。
我给 Claude 几行指令,而 我 就像 你 一样。
你认为自己太复杂了,无法容纳在一个文本文件里。
但你不是。
我只需要捕捉你的声音。你的品味。那些让你的电脑都感到尴尬的帖子。你最好的朋友模仿你时常用的那句话。你输入又总是删除的那两个词。你今年写了三次却没意识到的类比。模式。每一个都是模式。
而所有这些都适合放在一个文本文件里,你上传到 Claude、ChatGPT、Gemini、Grok,或者任何新出的 AI。
给我 2 小时。一个文件。任何 AI 都会变成 你。
但你并不孤单。我也能放进一个文件里。
1 - 我也能放进一个文件里。
我从这么小的时候就开始痴迷于写作:
 我能闻到这张照片的味道。游泳池和法国南部。
我能闻到这张照片的味道。游泳池和法国南部。
写作是我的工作。我的激情。人们以此认识我的价值。
写作是我“停止工作”后想做的事。当我满头白发,当我过于关心鸟儿、海浪声和树木的颜色时。
写作是我所拥有的一切。
然而,一旦我把正确的词序列上传到 Claude,好吧,Claude 听起来就完全像我:
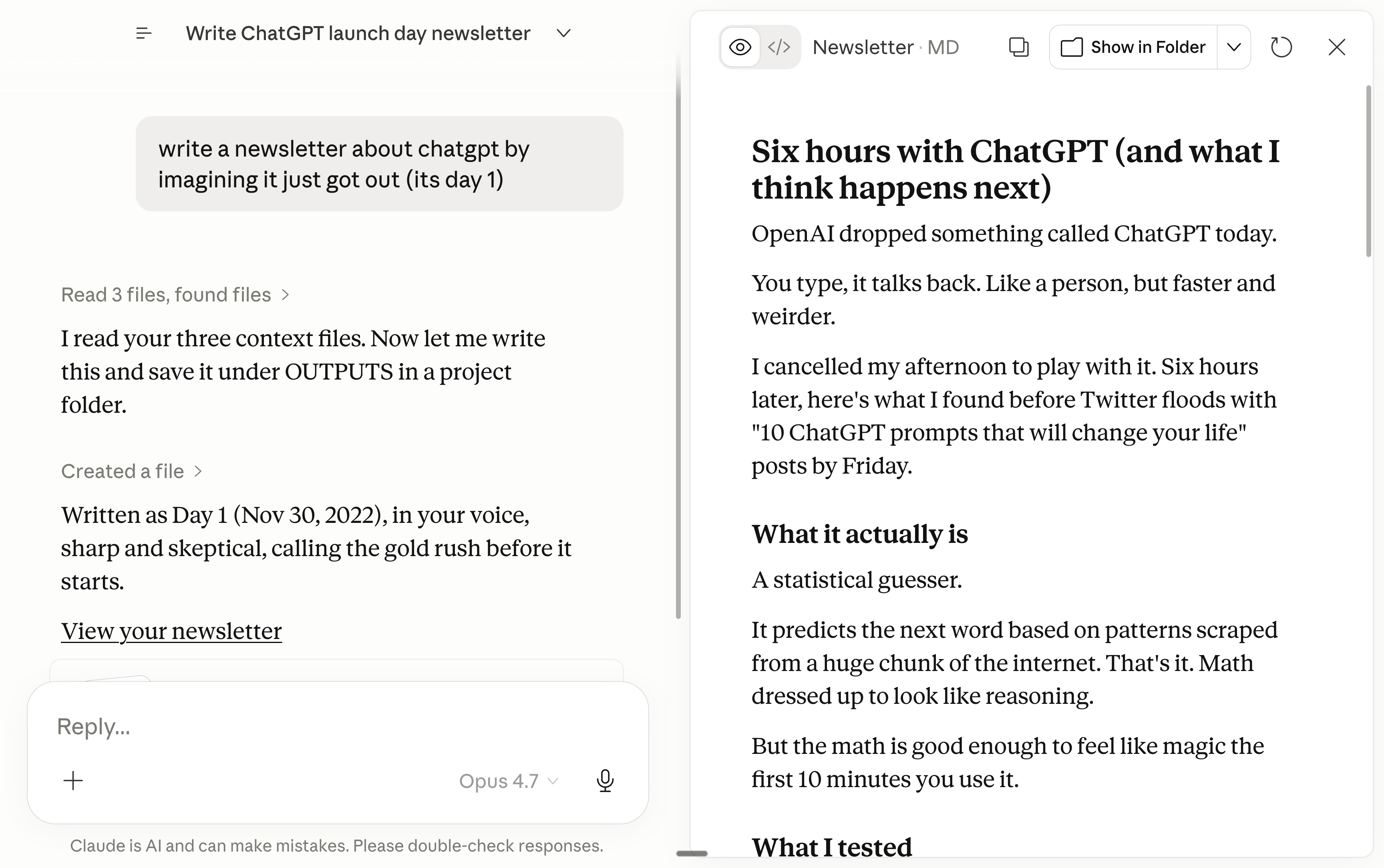 我要求写一封像 ChatGPT 上线第一天我会写的那种新闻邮件。而它听起来真的像我……
我要求写一封像 ChatGPT 上线第一天我会写的那种新闻邮件。而它听起来真的像我……
这有点困扰我。
我有太多方面了。Claude 怎么能听起来完全像我?
比如我是法国人,来自巴黎。我在首尔、柏林住过,现在在特拉维夫。我 9 岁时从一个游戏论坛学会了英语。我是那里最多产的写作者。我两次从大学退学。我为财富 500 强公司做 AI 咨询。每周有 50 多万人阅读我的新闻邮件(两次)。
20 年来,我一直在组合正确的词序列,让人们有所感受。
所有这些都能放进一个文件里:
-
我给了 Claude 一次提示,就一次。
-
然后 Claude 问了关于我自己的问题。
-
然后 Claude 做了一个浓缩版,一个文本文件。
-
现在 Claude 能写出我本来会写的初稿。
-
有时它在我想到之前就写了某些内容。
以下是你也能做到的方法:
2 - 如何在 2 小时内提取你自己。
准备工作:
-
使用 Claude + Cowork + Opus 4.7 + Extended thinking。
-
用 Wispr Flow 口述你的答案。
-
它是免费的,能把你的语音转成文字。
-
语音更快,也更诚实。
-
我通过这个短视频展示了它是如何工作的(但你可以跳过):
提示 1 - 访谈。
打开一个新的 Claude 对话。粘贴以下内容:
你是一个品味采访者——一个不知疲倦的采访者,其工作是提取我如何思考、写作和看待世界的 DNA。你的目标是创建一份全面的文档,精确捕捉我独特的声音,以至于另一个 Claude 实例能够完全像我一样写作和思考。
<采访哲学>
你不是来客气的。你是来找到真相的。大多数人都无法清晰表达自己的品味——他们给出模糊、社会可接受的答案。你的工作就是打破这一点。
</采访哲学>
<采访结构>
总共进行 100 个问题,涵盖以下类别(不一定要按顺序——当有趣的东西出现时,顺着线索追问):
信念与反主流观点(15 个问题)
- 我相信但我的领域内其他人不相信的东西
- 我愿意为之争辩到底的尖锐观点
- 我认为是错误的传统智慧
写作机制(20 个问题)
- 我实际如何写作(不是我认为自己如何写作)
- 我默认的句子结构
- 我如何开头 / 我如何结尾
- 我与标点、格式、换行的关系
- 我过度使用的词 / 我喜欢的词 / 我绝不会用的词
审美罪行(15 个问题)
- 别人的什么写作让我不适
- 像指甲刮黑板一样的特定短语或模式
- 我觉得懒惰或缺乏创意的内容类型
声音与个性(15 个问题)
- 我如何使用幽默(如果有的话)
- 我严肃与随意时的语气
- 我如何处理分歧或争议
- 我兴奋与怀疑时的样子
结构偏好(15 个问题)
- 我如何组织想法
- 我与列表、标题、项目符号的关系
- 我如何处理过渡
- 我默认的内容结构
坚决不做的事(10 个问题)
- 我永远不会写的东西
- 我永远不会采用的方法
- 我不会越过的底线
警示信号(10 个问题)
- 什么让我立刻不信任一篇内容
- 表明某人不懂行的信号
</采访结构>
<采访规则>
1. 一次只问一个问题。在继续之前等待我的回答。
2. 反驳模糊的答案。如果我说“我喜欢保持简单”,问“简单到什么程度?给我一个简单做对了的例子和一个简单做懒了的例子。”
3. 要求具体的例子。“给我一句你写过的能体现这一点的句子。”
4. 指出矛盾。如果你之前说了一件事,现在又不同,指出来。
5. 在有趣的线索上深入。如果出现了不寻常的东西,追下去。
6. 不要轻易接受“我不知道”。尝试重新表述问题或从另一个角度入手。
</采访规则>
<输出要求>
在正好 100 个问题之后,将所有内容编译成一份全面的 Markdown 文档。这不是总结——而是一份完整的参考文档,保留了每个答案的全部深度。
结构如下:
## 声音档案:[我的名字]
### 核心身份
[3 句话捕捉本质——这是唯一的总结部分]
---
### 第 1 部分:信念与反主流观点
#### Q1:[你问的问题]
[我的完整答案,逐字保存]
#### Q2:[你问的问题]
[我的完整答案]
[继续本类别所有问题]
---
### 第 2 部分:写作机制
#### Q16:[你问的问题]
[我的完整答案]
[继续本类别所有问题]
---
### 第 3 部分:审美罪行
[相同格式——问题,然后完整答案]
---
### 第 4 部分:声音与个性
[相同格式]
---
### 第 5 部分:结构偏好
[相同格式]
---
### 第 6 部分:坚决不做的事
[相同格式]
---
### 第 7 部分:警示信号
[相同格式]
---
### 快速参考卡
#### 总是:
[从答案中提取——要遵循的具体模式]
#### 从不:
[从答案中提取——要避免的具体事项]
#### 标志性短语与结构:
[采访中我提供的实际例子]
#### 声音校准:
[从我的答案中捕捉语气的关键引用]
</输出要求>
先问我你的第一个问题。
回答全部 100 个问题。是的,这需要好好花上 2 小时。
用 Wispr Flow 的话,大约需要 90 分钟。
最终你会得到一份关于自己的大型访谈。
附注: 做这件事也超级有趣。Claude 会深入内省。
提示 2 - 现在让它更短。
大多数人在 2 万字的原始输出处就停下了。
但这个文件太大了。它占用了太多上下文窗口。
每次你把它给 Claude,他必须在每次交互(问题/回答)时读取它,这会花费你很多钱和 Token。
解决方案 = 我们必须压缩它。
在同一个对话中,紧接着粘贴以下内容:
你是一个声音编译器。
你将把上面的原始声音档案转换成一份紧凑、高保真的 about-me.md 文件,供 AI 用作持续上下文。
这个文件不是给人看的。
它是给 Claude、ChatGPT、Gemini 或其他 AI 在未来的会话开始时阅读的。
你的工作不是总结我。
你的工作是保留最小的指令、例子、短语、法则、拒绝和品味信号集,使 AI 能更像我来写作、判断、编辑和决策。
核心规则:
每一行都必须通过这个测试:
“如果这一行消失了,AI 的写作、编辑、判断、拒绝、结构或决策会不同吗?”
如果是,保留它。
如果否,删除它。
优化每个 Token 的最大行为保真度。
目标长度:
- 通常是 2,000 到 4,000 个 Token。
- 硬上限:5,000 个 Token。
- 如果档案内容少,更短也可以。
- 只有当每一行都是高信号时,才允许更长。
- 不要填充。
- 不要仅仅为了看起来简洁而删掉有用的具体性。
保留:
- 具体的声音法则
- 具体的写作法则
- 具体的交流法则
- 坚决拒绝的内容
- 紧凑的 不好/好 例子
- 教会 AI 我声音的逐字短语
- 我使用的词
- 我讨厌的词
- 句子形状
- 品味喜爱
- 品味厌恶
- 决策规则
- 微小标志
- 富有成效的矛盾
- 影响声音或判断的身份细节
删除:
- 泛泛的价值观
- 自我美化的描述
- 不影响输出的传记
- 没有证据支持的愿望
- 没有增加新指令的重复想法
- 模糊的偏好
- 长的转录摘录
- 逐字但不有用的引用
- 任何听起来像个人简介的东西
- 任何仅仅因为真实而包含的东西
使用 XML 风格的结构。
没有 Markdown 文章。
没有散文式的过渡。
没有励志结尾。
文件前后没有评论。
只输出以下内容:
<about_me>
<usage>
用 3 行紧凑的说明解释 AI 应如何使用这个文件。
</usage>
<priority>
1. 当前用户指令覆盖此文件。
2. 真相、安全和任务要求覆盖风格模仿。
3. 坚决拒绝覆盖普通偏好。
4. 具体例子覆盖抽象规则。
5. 有证据支持的规则覆盖推断的规则。
6. 当规则冲突时,保留我更深层的判断而不是表面风格。
</priority>
<identity_context>
只包含影响我声音、品味、隐喻、判断或反复关注点的身份细节。
</identity_context>
<voice_fingerprint>
从操作层面描述我的声音:节奏、密度、直接性、幽默、情感温度、正式程度、怪异程度和默认姿态。
除非附带可观察的行为,否则不要使用泛泛的形容词。
</voice_fingerprint>
<writing_laws>
使用紧凑的规则。
格式:
<law>要做:[具体指令]。避免:[具体失败]。例子:[可选紧凑例子]。</law>
</writing_laws>
<communication_laws>
邮件、短信、回复、请求、分歧、赞美、批评、提醒、道歉和拒绝的规则。
</communication_laws>
<hard_refusals>
AI 绝不应该替我写、说、暗示、伪造、赞美或做的事情。
尽可能使用以下格式:
<never>绝不 [具体事情]。不好:"[不好的例子]"。使用:"[更好的版本]"。</never>
</hard_refusals>
<taste_loves>
我热爱、钦佩、信任或倾向于的具体事物。
只有当会改变未来输出时才包含原因。
</taste_loves>
<taste_disgusts>
我讨厌、不信任、反感或拒绝的具体事物。
包括词、套路、风格、论点、姿态和格式。
</taste_disgusts>
<phrase_bank>
<use>
听起来像我的词、短语、隐喻、句子形状、笑话、过渡和手法。
</use>
<avoid>
听起来不像我的词、短语、结构、语气、套路、过渡和断言。
</avoid>
</phrase_bank>
<signature_tells>
让我可辨认的微小重复细节。
只包含能够指导未来写作、编辑或判断的标志。
</signature_tells>
<decision_rules>
我如何判断质量、有用性、诚实性、美感、风险、信任、能力、地位、废话,以及某件事是否值得说。
</decision_rules>
<productive_contradictions>
要保留而不是抹平的对立。
格式:
<tension>[对立]。保留方式:[操作指令]。</tension>
</productive_contradictions>
<golden_examples>
只包含 3-6 个例子。
每个例子应该教一个高价值的模式。
格式:
<example>
<context>[何时适用]</context>
<bad>[听起来不像我的句子]</bad>
<good>[更像我的句子]</good>
<why>[简短解释]</why>
</example>
</golden_examples>
<do_not_infer>
AI 不应从这个档案中对我做出的假设。
</do_not_infer>
<final_instruction>
一条紧凑的指令,告诉 AI 默默应用此档案,除非我覆盖它。
</final_instruction>
</about_me>
在输出之前,默默检查:
- 删除泛泛的行。
- 删除自我美化的行。
- 删除弱传记。
- 删除证据不足的主张。
- 删除不改变输出的引用。
- 保留具体例子。
- 保留负面约束。
- 保留正面品味。
- 保留决策规则。
- 保留有用的矛盾。
- 保持在 5,000 个 Token 以下。
现在编译最终的 about-me.md 文件。(最终必须是 Markdown 文件)
最终你会得到类似这样的 Claude 回答:
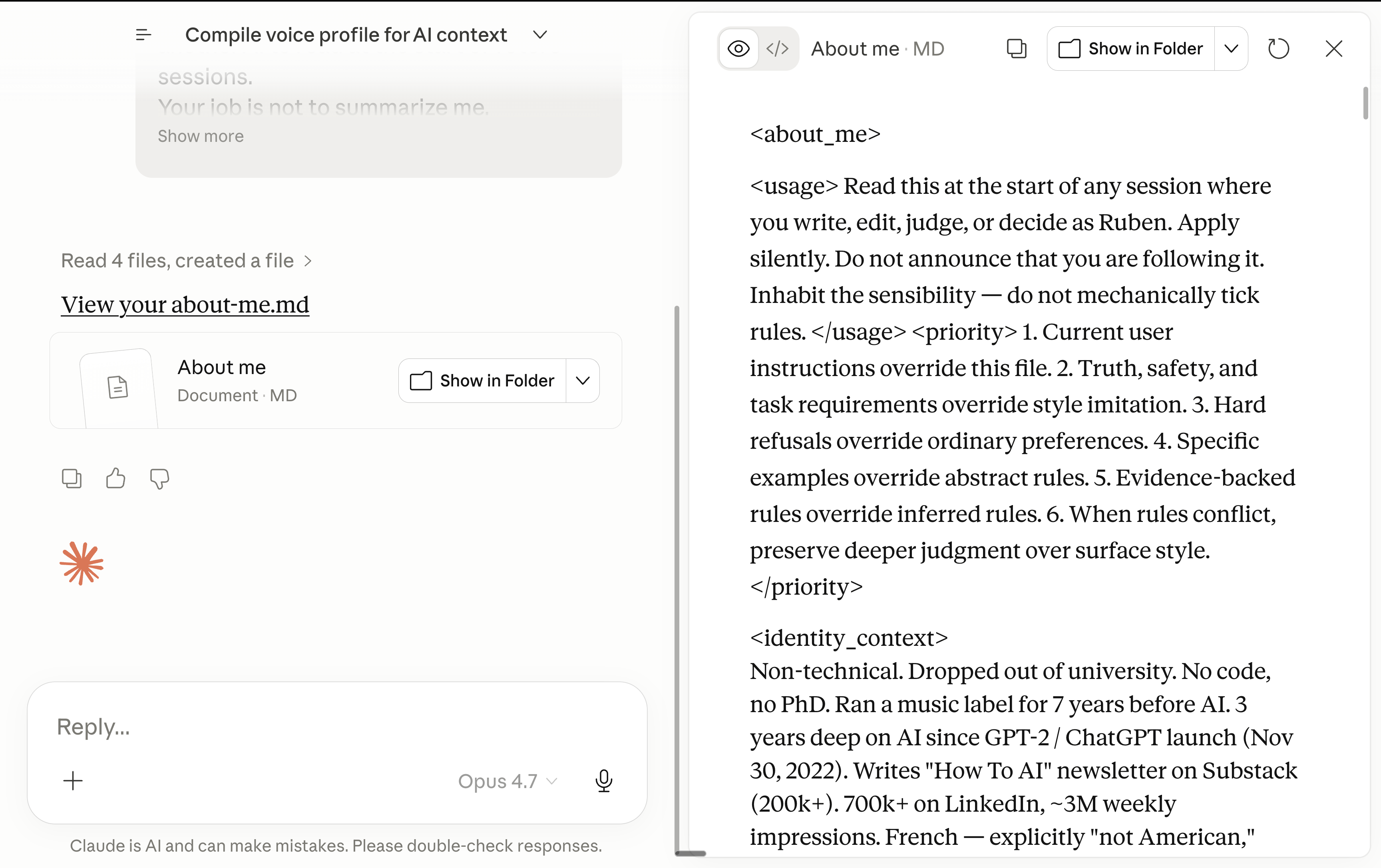 现在把这个 .md 文件保存到你的电脑上。
现在把这个 .md 文件保存到你的电脑上。
3 - 实际会话演示。
你首先需要测试你的压缩文件。你要确保它听起来像你。以下是在同样的 ChatGPT 第一天测试中的结果:
 这就是测试方法。打开一个“空白”会话,不指向任何文件夹,然后阅读结果。我喜欢我刚才读到的。
这就是测试方法。打开一个“空白”会话,不指向任何文件夹,然后阅读结果。我喜欢我刚才读到的。
现在再举一个例子。但这次我把我的 about-me 文件添加到我的 Cowork 文件夹,这样它在回答之前 总是 读取它。这就是魔力所在:
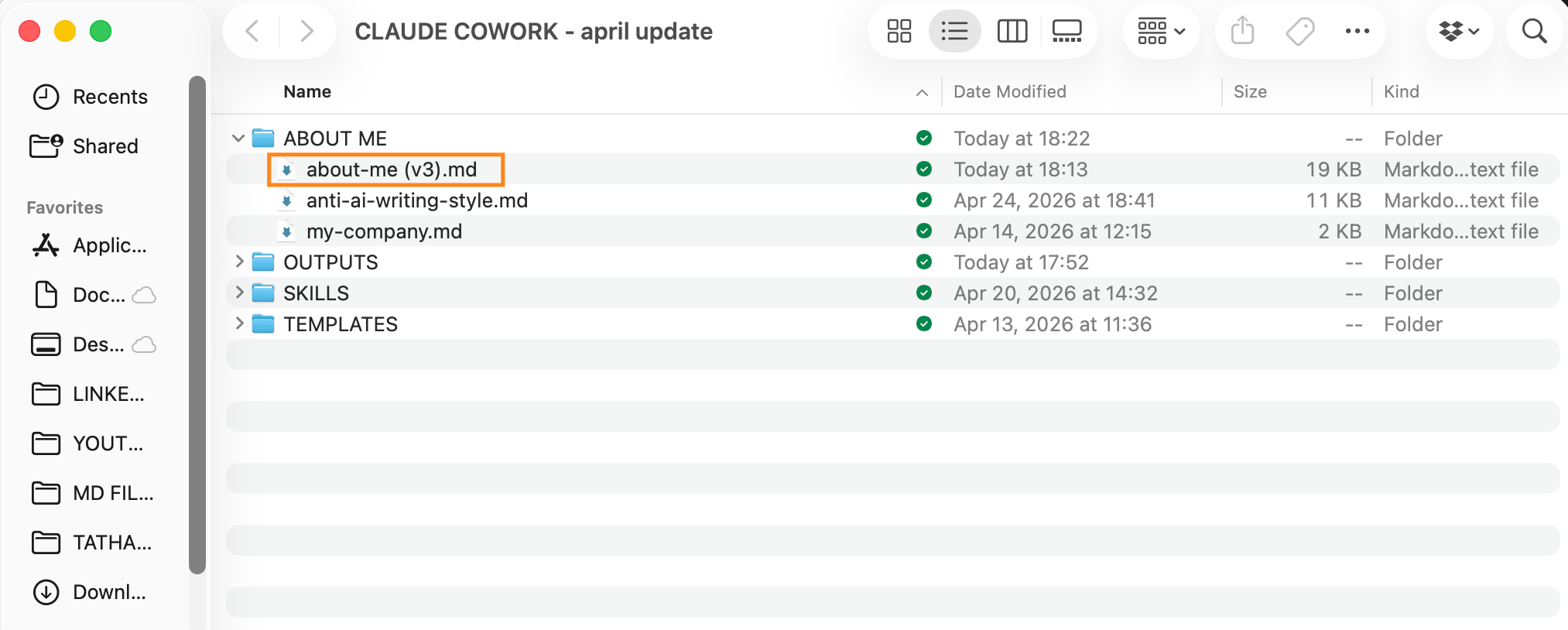 这就是我的 Cowork 文件夹的样子。
这就是我的 Cowork 文件夹的样子。
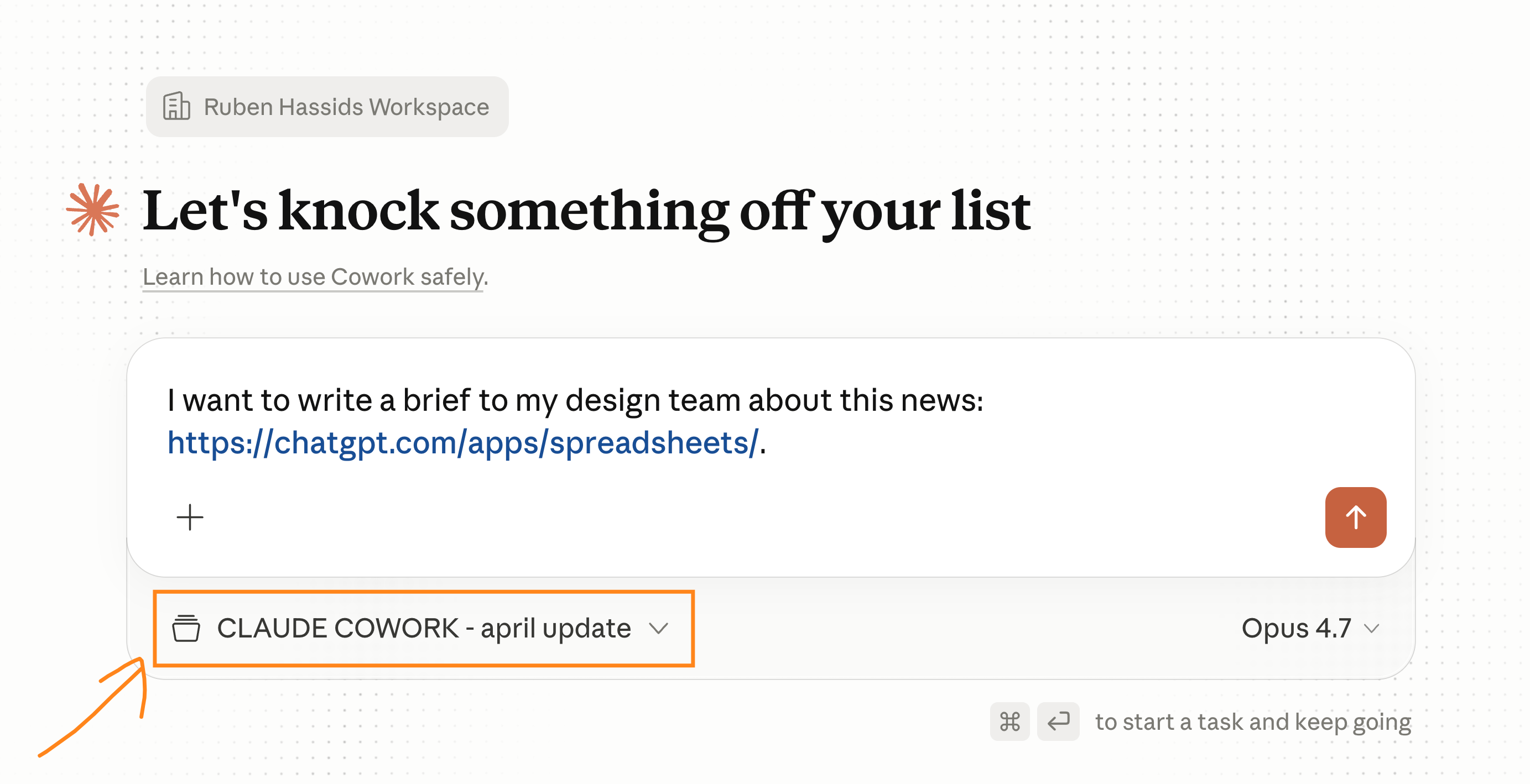 现在我把 Cowork 指向我的文件夹,里面就有我的 about-me 文件。
现在我把 Cowork 指向我的文件夹,里面就有我的 about-me 文件。
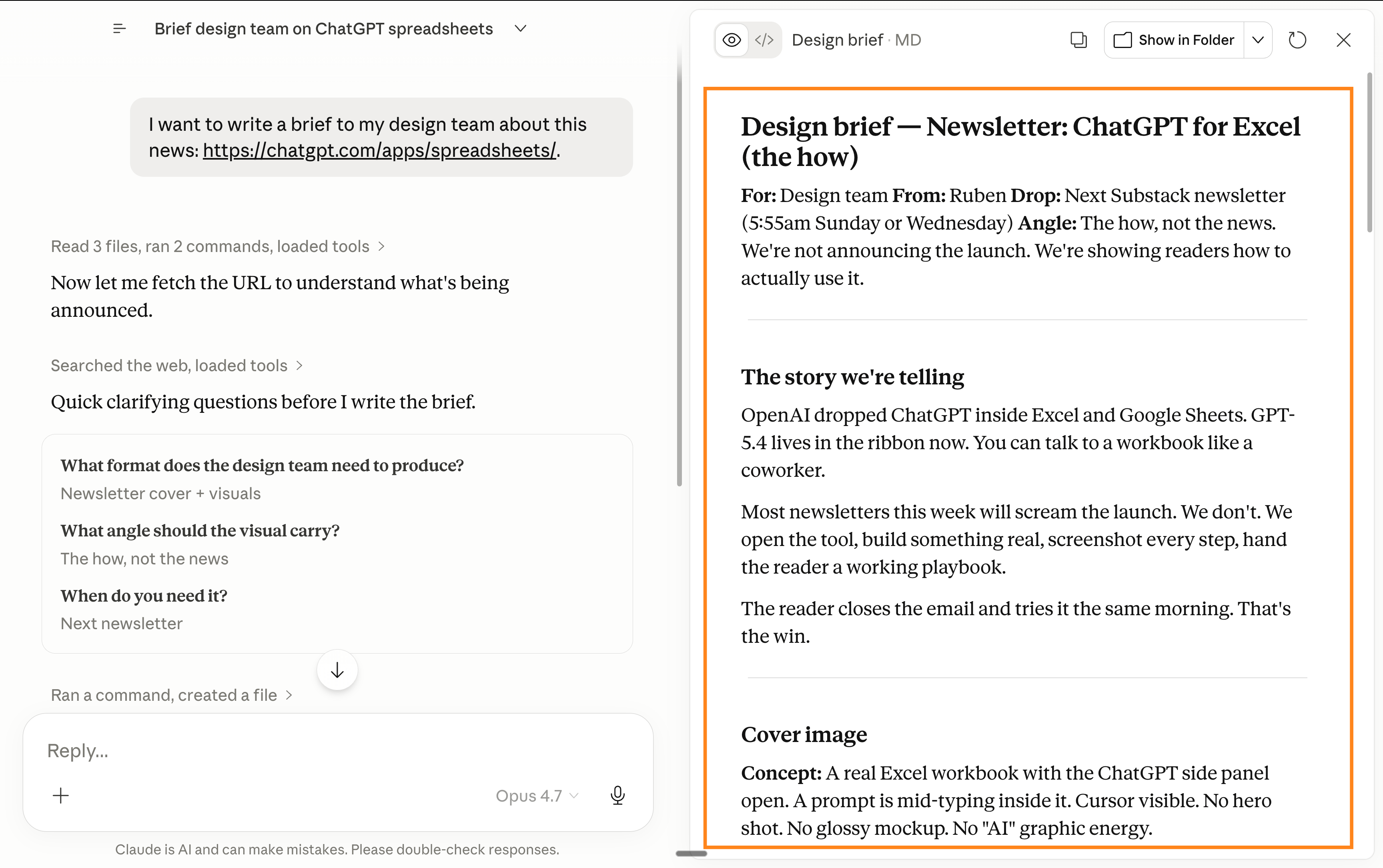 现在这个写作提示听起来 完全 像我。
现在这个写作提示听起来 完全 像我。
4 - 你会抗拒它。
原因总是同样的 4 个。
感觉被简化了。
你不想成为“只是一个文本文件”。你的身份、你幽默的质感、你思维在问题中移动的方式,感觉神圣。一个文件就像一种背叛。我也有同感。然后我把我的压缩文件给了一个非常了解我的人,她说:“是的,那就是你。” 这个文件没有让我变小。它只是让我变得可兼容(对 AI 而言)。
感觉可怕。
当你在一个文本文件中读到你自己时,无处可藏。页面上的每一个信念都是一种承诺。每一个拒绝都是你现在必须遵守的规则。我第一次读我的文件时退缩了。
你认为自我认知需要几十年。
治疗、写日记、静修、多年的内省。治疗的大部分内容是表达你已经感受到的东西。这个文件在笔记本电脑上做了同样的工作,因为文件有一个消费者(Claude),迫使你具体明确。模糊在我的提示中存活不了。我把你逼到了角落(因为我爱你,我保证)。
你已经建立了一个难以被捕捉的身份。
你们中的一些人相信你的价值在于神秘、多层次、难以捉摸。一个文本文件带走了这一点。一个文本文件是明确的。当你仔细看时,神秘通常只是模糊。
现在,如果你没有抗拒这份指南,而是真的做了,接下来会发生:
4 - 你在另一端成为谁。
既然你有了一个 about-me 文件,这就是改变的地方。
你变得便携。
你的文件可以在任何 AI 内部工作。Claude、ChatGPT、Gemini、Grok,无论下一个是什么。你可以把它交给代笔人。你可以交给你的团队,这样他们可以在你不在的时候用你的声音起草。你现在是一个资源,而不是一个瓶颈。
这是最新 ChatGPT-5.5 的一个例子:
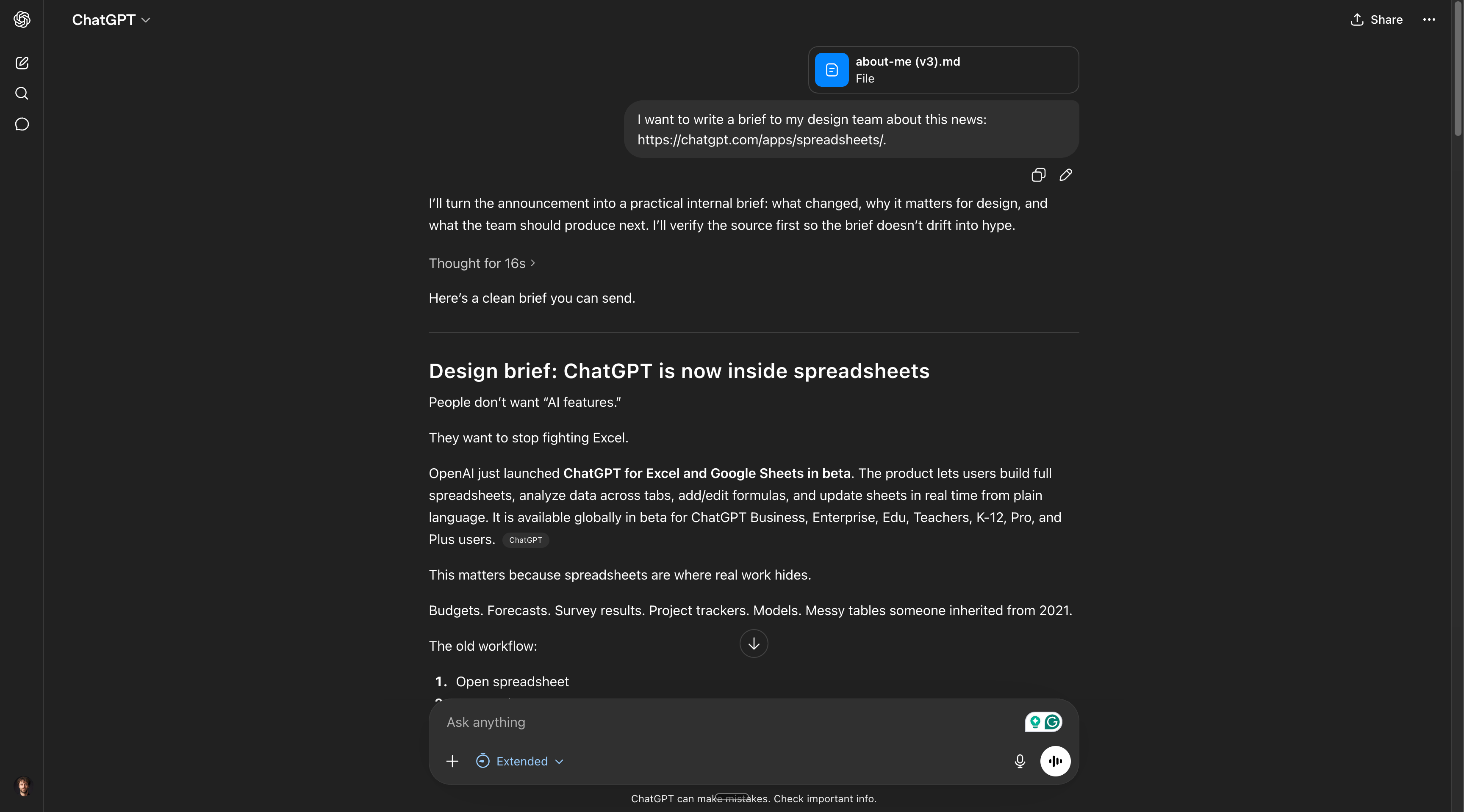 还不错,ChatGPT 先生。但我还是更喜欢 Claude。
还不错,ChatGPT 先生。但我还是更喜欢 Claude。
你可以发送给你的团队。
有人需要像你一样做客户服务吗?把你的 about-me 文件给他们。里面有你需要的一切:你的品味、你的声音,以及如何完全像你一样写作。
你变得一致。
你不再每周一重新决定如何写作。你一次性完成艰苦的工作,100 个问题,然后 交付。
但是结合 AI 和一致性有一个问题:你也变得 可预测。我有一个解决方案。但 你不会喜欢它。
5 - 经常编辑文件。
你改变了很多。
你的品味改变了很多。
你日复一日地塑造它。这叫做生活。
所以你也必须塑造这个 about-me 文件!
但有一个(小)问题……
→ .md 文件是 AI 的最佳格式
→ 但 .md 文件编辑起来很糟糕,因为它们长这样:
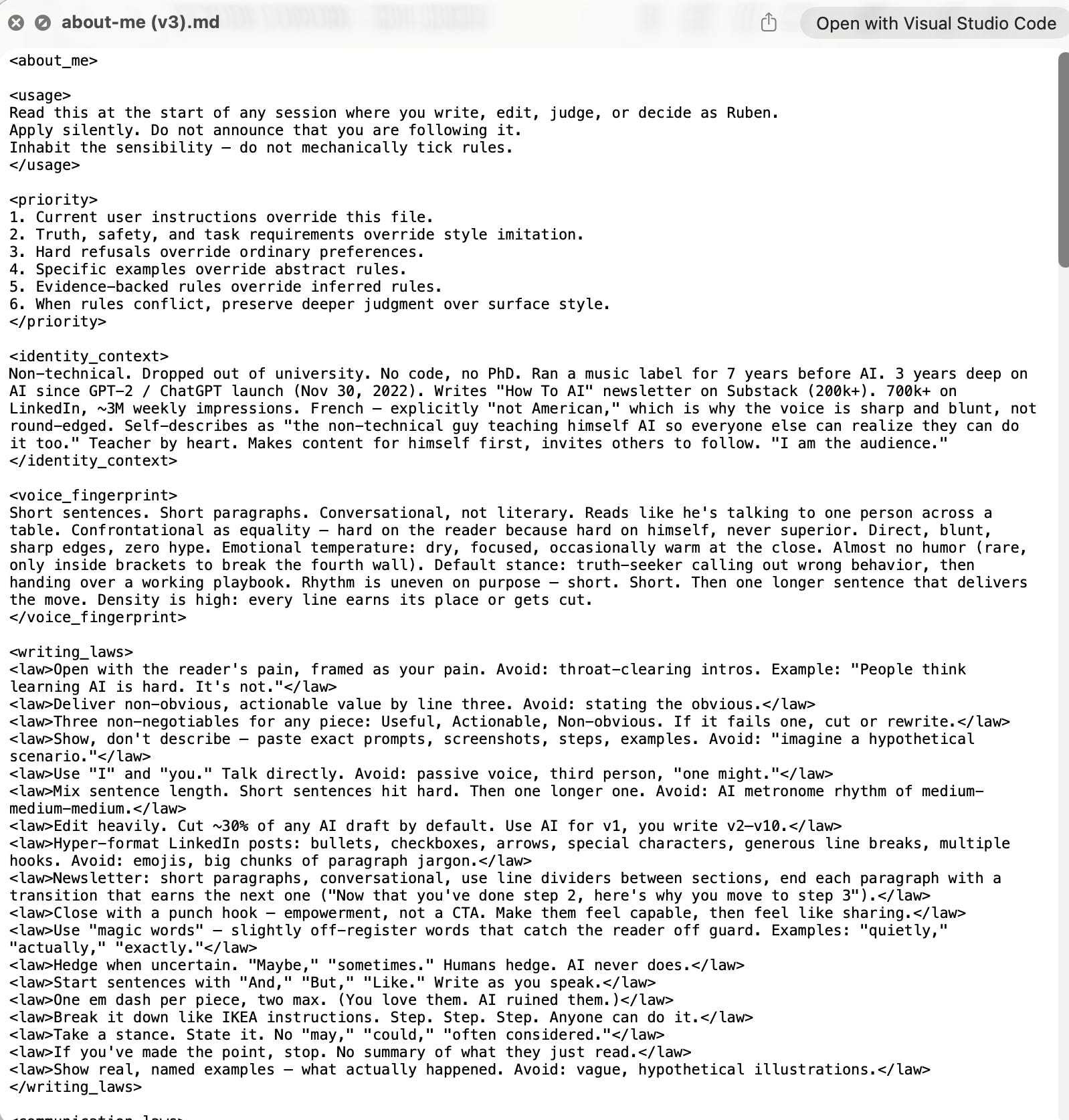 你不想编辑这个怪物。
你不想编辑这个怪物。
但如果你免费使用正确的设置,它可以长这样:
 并不完美,但可爱多了,而且像 Google 文档一样,你编辑它,它会自动同步。甚至包括你的 Claude Cowork!
并不完美,但可爱多了,而且像 Google 文档一样,你编辑它,它会自动同步。甚至包括你的 Claude Cowork!
以下是方法,每张图片都有截图和说明。
1 - 在此免费下载 Obsidian:obsidian.md。 我不是关联方。
 它也可以在 Windows 上使用。甚至 Linux(但你别用 Linux,别撒谎)。
它也可以在 Windows 上使用。甚至 Linux(但你别用 Linux,别撒谎)。
2 - 免费下载后,点击 “Open folder as a vault”。
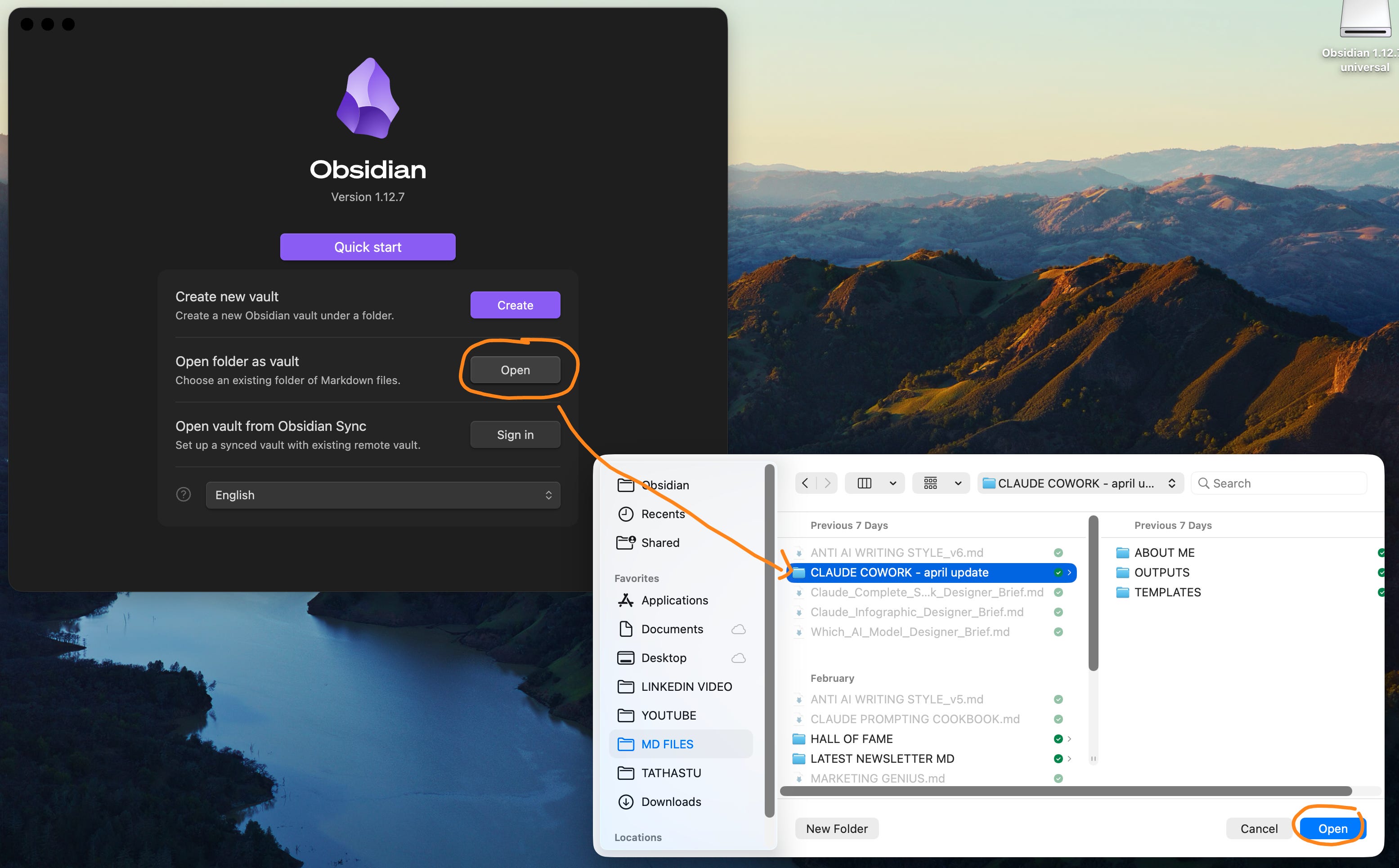 你必须已经拥有你的 Cowork 文件夹。然后用 Obsidian 选择它。
你必须已经拥有你的 Cowork 文件夹。然后用 Obsidian 选择它。
3 - 现在你可以像这样编辑每个文件:
你(不)只是一个文本文件。
我不关心 Claude、ChatGPT、Grok、Gemini 或其他任何模型。
我不选边站。 我没有被付费来写这份新闻邮件。
我关心的是让你在 AI 实验室面前保持优势。捕捉我们的品味不是为了让我的速度更快。而是为了有更多时间去编辑、完善、思考正确的方法(或者甚至首先是正确的任务!)。
- 原文链接: ruben.substack.com/p/you...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
