大幅简化的新分片设计
- ETH中文网
- 发布于 2022-01-07 13:52
- 阅读 4568
这个新分片设计既解决 MEV 带来的问题,也大大简化了原来的设计。
作者 | Dankrad Feist
译者注:近日以太坊研究员 Dankrad Feist 提出新的分片设计,得到了社区的关注。由于其文章技术性较高,Dankrad 在推特上发布文章时用比较浅显的语言对这个设计进行了介绍。为了增强文章的可读性,ECN 也把其推文翻译了,并放在开头。如果正文翻译有不准确之处,还请读者指教。
白话版:
我在构思一个新的分片设计,在这个设计里,不是每个分片都由独立的提议者,而是在一个 slot 里的所有分片区块都与该信标区块一起被提议。这大大简化了分片设计。
在之前的设计里,在每个 slot 里,分片区块是被独立提议的,而数据可用性必须由委员会来验证。我们不能对所有分片进行整体地验证,因为每个提议者都能够破坏整个流程 (活性故障)
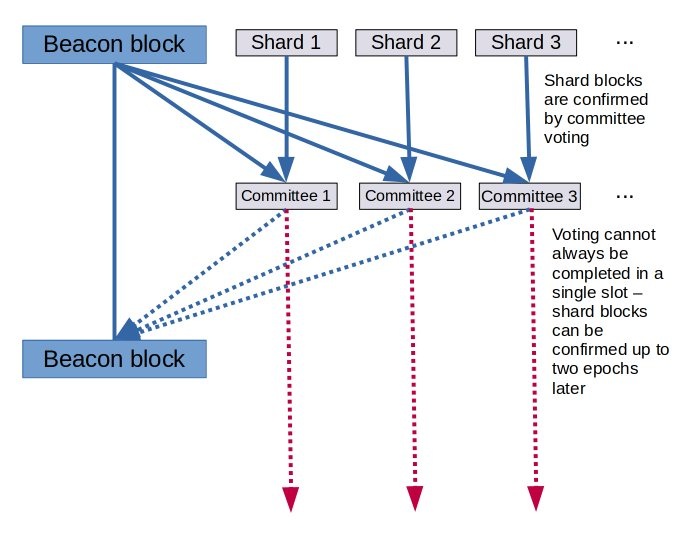
在大多数情况下,下一个信标区块应该包含所有被确认的分片数据,这并不能得到保证:投票可能需要更长时间,特别是如果分片提议者有意使数据最低限度可用。这会使事情变得相当复杂。
在这个新设计里,信标区块也会包含所有分片区块,且它们都由一个委员会一起确认 (每个委员会成员仍然只对分片数据的一小部分进行采样)。所有信标和分片数据一起确认。
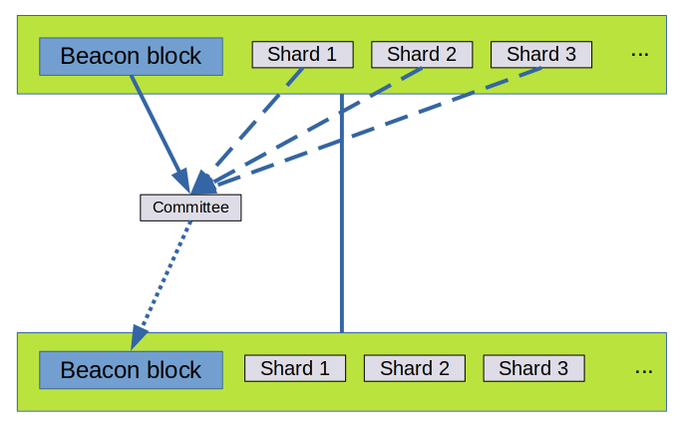
这会更简单,使得在同一个信标区块里的所有交易访问分片数据 (你甚至可以在 zkrollup 和 L1 之间获得同步交易!) 并大大地简化了 rollup 的构造 (不会延迟确认等)
这种设计之所以成为可能,是因为有两项新进展。以前,我们认为最好是有许多不同的分片提议者,以最大化抗审查性,并最小化对区块提议者的要求。但是,MEV 改变了这个情况。
我们现在认为, 解决 MEV 的唯一可行解决方案是通过提议者/构建者分离方案来对执行区块进行竞拍。因此,常规的验证者(提议者) 只需要从多个区块构建者中选择出价最高的区块。
这意味着对构建者要求的担忧成为一个不那么需要担忧的问题,因为无论如何他们最终都会成为高度专业化的角色。在实践中,如果执行权和分片区块权是一起竞拍的 (就如这个提案所描述的),市场会变得最高效。
但它的抗审查行如何呢?在有 PBS 的环境里,我们需要对此非常谨慎,因为一小部分的专业组织比一个分布良好的验证者网络更可能进行审查。幸运的是,@fradamt 提出了一个解决方法:crLists。
区块提议者可以构建给所有他们想打包到一个区块的交易创建一个列表 (crList)。然后,构建者必须要么全部打包,要么用其他交易填充区块,直到达到 gas 上限。
@fradamt 提的解决方案:https://t.co/JjJR7I4Lf4
这保留了审查的成本应该是连续为交易出价的成本。由于同步设计,我们在 L1 有新的分片数据构造,是直接依赖于和访问分片数据的,这些数据可以进入 crList。
这是一个简短的总结,请阅读正文以了解更多细节。如果有反馈的话,特别是来自研究 MEV 和设计 L2 的,我会非常感谢!
推特来源:
<iframe id="twitter-widget-2" scrolling="no" frameborder="0" allowtransparency="true" allowfullscreen="" class="" title="Twitter Tweet" src="https://platform.twitter.com/embed/Tweet.html?dnt=false&embedId=twitter-widget-2&features=eyJ0ZndfZXhwZXJpbWVudHNfY29va2llX2V4cGlyYXRpb24iOnsiYnVja2V0IjoxMjA5NjAwLCJ2ZXJzaW9uIjpudWxsfSwidGZ3X2hvcml6b25fdHdlZXRfZW1iZWRfOTU1NSI6eyJidWNrZXQiOiJodGUiLCJ2ZXJzaW9uIjpudWxsfSwidGZ3X3NwYWNlX2NhcmQiOnsiYnVja2V0Ijoib2ZmIiwidmVyc2lvbiI6bnVsbH19&frame=false&hideCard=false&hideThread=false&id=1475995508372131842&lang=en&origin=https%3A%2F%2Fmirror.xyz%2Fwrite&sessionId=95bcc741958ec18c27c5e54040bde57aa2cb5bf2&theme=light&widgetsVersion=9fd78d5%3A1638479056965&width=550px" data-tweet-id="1475995508372131842"></iframe>
正文:
之前的数据分片构造:把 n=64 个数据分片添加到信标链。每个 slot 都有 n 个提议者独立提议他们的分片 blob,这些数据段随后会由委员会确认。 一旦一个分片 blob 被确认了 (这可能需要几个 slot),它就可以被执行链引用。
这里提出一个替代方案:添加一种新的交易类型,可以包含额外的分片数据作为 calldata。然后,区块由一个单一的区块构建者 (这可以不同于提议者/构建者分离方案的提议者) 构建,打包常规交易和有分片 calldata 的交易。这样效率是高的,因为它意味着 rollup 和 L1 之间的紧密集成成为可能,而且预计这种“超级区块构建者”策略无论如何都会在实践中出现,以便最大限度地提取 MEV。
优势:
- 与当前的 Eth1 链更紧密地结合——管理合约可以马上看到 rollup 数据
- 所有数据与 rollup 调用一起被确认
- 不需要等到分片区块被确认
- 不需要担心会有重复的分片数据等
- 对开发者来说更容易理解
- rollup 不需要实现难以处理的“分片扫描逻辑”。发送到它们的数据可以立即用 L1 交易进行标记
- 分片不需要独立的 PBS (提议者/构建者分离)
- 这将降低构建者进入市场的成本,因为它们将不必构建两个不同的系统
- 这也意味着,构建者可以无风险地提取来自数据和执行之间交互的 MEV,也就是说构建者的中心化程度降低了。
- 不需要一个单独的分片交易支付系统
- 分片 calldata 的开销可以直接向使用这些数据的交易收取
- 我们可以使用所有现有的以太坊交易支付基础设施
- 提高抗贿赂性,因为数据可以由更大的委员会确认 (1/32 的验证者集)
- 没有独立的分片区块确认,可以更好地进行交易聚合。我们每个 slot 只需要一个委员会 (PBS 需要两个)
- 我们可以立即将信标和执行区块添加到数据可用性集
- 一旦 Verkle tries 开发成熟,为由数据可用性+欺诈证明保护的轻客户端执行奠定基础
- “Eth1作为一个 rollup"
- 使不需要运行一个全 Eth1 节点的,更轻量级的验证者+节点成为可能
- 在 ZKrollup 里,从 L2 到 L1 的同步调用变得可能
- 应用不需要对它们想要使用的分片进行承诺
- 总的区块大小可以用与区块 gas 上限相似的方式进行治理
- 当信标链变得欺诈可证明时,超级轻量的客户端 (只有数据可用性) 将成为可能。
- 一旦 Verkle tries 开发成熟,为由数据可用性+欺诈证明保护的轻客户端执行奠定基础
- 当前的分片 blob 市场是低效的
- 我们声称有 64 个独立的提议者。然而在实践中,这是不可能的,因为这将导致大量的重复确认,这反过来会导致市场的中心化。
- 如果一个分片需要 10 个独立的 blob 被确认,那么就没有有效的方法在同一个 slot 里对所有的 blob 进行竞价 (全有或全无式出价)
- 更轻量的客户端是可能的
- 客户端只需约 20kb/信标区块 (1.7 kb/s) 就可以进行完全的数据可用性采样,而在之前的构造中需要 1 MB/信标区块 (90 kb/s)。这是因为我们可以马上提供 2d (二维)采样。
劣势
- 提高了对构建者的要求:
- 在~1秒内计算 32 MB 数据的 KZG 证明。这需要一个 32-64 核的 CPU。我认为可以用 <5,000 美元的价格建造一台性能足够高的机器,概念证明有待实现。根据与 Dag Arne Osvik 的对话,在 GPU 上做这个可能会便宜很多
- 更大型的低带宽要求:需要在构建者期限内能够发送 64 MB 的数据,并确保在 P2P 网络分发。可能需要至少 2.5 GBit 的上行带宽
- 这些都不是对构建者的疯狂要求,而其他入门要求可以说已经设定了更高的门槛
- 构建者有更大的权力,因为他们负责执行+数据可用性
- 但在 PBS 下,我们无论如何都需要其他抗审查的方法。有了这个系统,它们可以被当作一个单独的忧虑。目前建议的模式是,提议者有权力强行打包某些交易 (https://notes.ethereum.org/Dh7NaB59TnuUW5545msDJQ)
建议的实现
- 新常量
MAX_SHARDS = 2**8 # 256
SHARD_SIZE_FIELD_ELEMENTS = 2**12 # 2**12*31 = 126976 bytes
MAX_BLOCK_SIZE = SHARD_SIZE_FIELD_ELEMENTS * MAX_SHARDS # 2**20 field elements / 32,505,856 bytes
TARGET_BLOCK_SIZE = MAX_BLOCK_SIZE // 2 # EIP1559 for data gas
- 我们引入一个新的 BlockKZGCommitment (区块 KZG 承诺),它对所有使用 2D KZG 格式的数据进行承诺。它将对信标区块、执行负载和对分片数据的承诺进行承诺。
class ShardedBeaconBlockCommitment(Container):
sharded_commitments: List[KZGCommitment, 2 * MAX_SHARDS]
beacon_block_commitments: uint64 # Number of commitments occupied by Beacon block + Execution Payload
# Aggregate degree proof for all sharded_commitments
degree_proof: KZGCommitment
ExecutionPayload用于数据 gas 市场的新字段
class ExecutionPayload(Container):
# Execution block header fields
parent_hash: Hash32
fee_recipient: ExecutionAddress # 'beneficiary' in the yellow paper
state_root: Bytes32
receipt_root: Bytes32 # 'receipts root' in the yellow paper
logs_bloom: ByteVector[BYTES_PER_LOGS_BLOOM]
random: Bytes32 # 'difficulty' in the yellow paper
block_number: uint64 # 'number' in the yellow paper
gas_limit: uint64
gas_used: uint64
timestamp: uint64
extra_data: ByteList[MAX_EXTRA_DATA_BYTES]
base_fee_per_gas: uint256
# Extra payload fields
block_hash: Hash32 # Hash of execution block
transactions: List[Transaction, MAX_TRANSACTIONS_PER_PAYLOAD]
# NEW fields for data gas market
data_gas_limit: uint64
data_gas_used: uint64
data_base_fee_per_gas: uint256
ShardedBeaconBlockCommitment到beacon_block_commitments是信标区块的内容 (包括执行负载),以每个字段元素 31 个字节进行编码- 其余数据没有任何有效性条件
- 添加一个新的交易类型 3,以下为它的负载规范:
@dataclass
class TransactionKZGCalldataPayload:
chain_id: int = 0
signer_nonce: int = 0
max_priority_fee_per_gas: int = 0
max_fee_per_gas: int = 0
# New data gas
max_priority_fee_per_data_gas: int = 0
max_fee_per_data_gas: int = 0
gas_limit: int = 0
destination: int = 0
amount: int = 0
payload: bytes = bytes()
# KZG Calldata
kzg_calldata_commitments: List[KZGCommitment, MAX_SHARDS]
access_list: List[Tuple[int, List[int]]] = field(default_factory=list)
signature_y_parity: bool = False
signature_r: int = 0
signature_s: int = 0
- 类型 3 的每笔交易都有一个有效性条件,要求交易的所有
kzg_calldata_commitments都被打包到ShardedBeaconBlockCommitment(分片信标区块承诺) 的sharded_commitments(分片承诺) 里
start}x]_2)$
- 在 EVM 新增一个操作码
KZGCALLDATA,它会把kzg_calldata_commitments添加到一个特定的存储位置 - 验证分片承诺是否得到正确编码
-
对于每个承诺,都有一个次数证明,证明承诺的次数
< SHARD_SIZE_FIELD_ELEMENTS, 通过配对等式来检查:
-
如果有 2N 个分片承诺,第一组 N 是数据,剩下的一组 N 是一个多项式扩张 (polynomial extension)。我们需要验证这 2N 个分片承诺都在一个次数为 N−1 的多项式里。
- 标准方法:对 2N 大小的数据进行快速傅里叶变换 (FFT),验证 N 个高阶系数为 0。这需要 2Nlog2N 次群乘法,这样开销就会很贵
- 更便宜的方法:在该阈值的任一点上使用重心拉格朗日插值公式来对前 N 个承诺进行取值,然后对后 N 个承诺做相同的事。如果两点是相同的,那么它们是在次数为 N-1 的同一个多项式上。2N 大小的数据仅需要一个多标量点乘 (MSM),它所需的时间与 2Nlog2N 次群乘法差不多。
-
- 添加操作码
BLS12_381(任何合理的分片实现所必需的)
采样
- 我们的原始数据有多达 256 个分片承诺,使用多项式扩张可以增加到 512 个
- 每个分片承诺的次数都是 2^12,扩张到 2^13 个字段元素用于采采样
- 我们假设一个样本的大小是 2^4=16 个字段元素 (即 512 字节)。然后在每个区块里,我们采样 512 行和 512 列,总共 512∗512=2^18=262144 个样本。这些样本中的任意 50% 的数据都足以重构一个完整的区块。此外,任何行/列都可以在这些样本的 50% 中被重构,这使得区块即使在种子很少的情况下,像家庭验证者这样的小型参与者也能进行有效恢复。
- 每个验证者被分到 32 个随机列,验证者必须在下一个证明里托管这些数据 (这意味着证明将托管共 32⋅32⋅512 个样本)。这产生了一个好的副作用,即每个区块获得整个验证者集的抗贿赂性的 1/32 (对一个区块来说,贿赂不到 1/2 的验证者证明是没用的)
区块构建者成本
区块构建者有两项新任务。一项是计算样本的 KZG 见证数据,另一项是在 p2p 网络里为样本播种。
- 先从第二项说起。鉴于我们有大约 128 MB 的样本,而且我们想要把每个样本分发到至少 5 个对等点,以实现良好的分散,所有这些都应该在大约 1 秒内发生,那么构建者就需要总共 640 MB/秒 或 5 GBit/秒的上行带宽。这对于家庭互联网连接来说肯定是不太可能的,但在数据中心就能轻易达到
- 如果人们真的想在家中运行一个构建者,有服务可以在样本被创建后对它们进行分发,把他们自己的上行带宽要求减少到 32 MB/秒或 256 MBit/秒,这在某些地区是可能的
- 但是,对在数据中心运行构建者的要求似乎不会有特别限制 (无论如何他们很可能会这样做)
- 计算所有样本的 KZG 证明。根据我的估计,使用 FK20 (译者注:由 Dankrad Feist 和 Dmiry Khovratovich 于 2020 年提出的快速分摊卡特证明的方法)大约需要 200~300 秒 (这个不确定性来自多标量点乘算法的精确复杂性是未知的)。这可以被分发到很多机器。在数据中心,这种计算能力很容易可得。
- Dag Arne Osvik 估计在 GPU 上,见证数据的计算可以在约 1 秒内完成。
分片交易池
原因
现在在以太坊上大多数交易经过的交易池并不处理数据交易。每个节点都处理完整的交易池,但有了分片后,链的容量会增加到 1.3 MB/秒,如果所有交易都经由交易池,1.3 MB/秒也将是预计交易池带宽的下限。
显然,节点需要处理整个交易池的交易但对数据交易进行分片是不合理的。相反,当涉及数据交易时,我们需要在交易池做数据可用性采样。
还需要交易池吗?
将交易发送到公共交易池的另一种方法是将他们发送到区块构建者,现在 Flashbots 已经有效地实现了这一点。优点是区块构建者可以承诺不会抢跑交易。如果他们这样做,用户可以简单地转换到另一个区块构建者。
例如,Solana 已经实现了这个设计,并在默认情况下发送交易到下一个区块提议者。
因此,以太坊链对交易池容量的需求很可能会变得小得多,甚至变得不再需要。但是,我们还是希望在设计中保留交易池,原因有两个:
- Francesco 的新抗审查设计需要一个公共交易池。这与上文说大多数交易将被首先直接发送到构建者是不冲突的。基本上,用户大多会将他们的交易发送给构建者,仅在他们被审查时会升级进入交易池;交易池变成了“审查池”
- 有一个全节点的以太坊用户应该可以在无需配置一个中央提供商就能发送交易。我发现这个论点不太站得住脚,因为未来的主要构成是 L1 上的 rollup 和终端用户使用 L2。因此,终端用户应该很少使用 L1。
构造
所有交易都通过 libp2p pubsub (发布订阅模式) 的 channel 广播。交易类型 3 包括 kzg_calldata_commitments,但不包含实际的底层数据。
我们构建了第二组 512 个 pubsub channel,仅用于广播分片数据交易的样本。当有人想发送一笔类型 3 交易到交易池,他们发送这 512 个样本里的每个 kzg_calldata_commitment 到这些样本 channel。
- 常规节点订阅约 10 个随机选择的 channel。这是为了确保这些 pubsub 可供想要订阅它们的节点使用
- 区块提议者随机采样 30 个 channel,从而可以确定一笔数据交易是否可用,以便能够把它们放到
crList - 区块构建者订阅至少 256 个,也可能是所有的 512 个 channel,以便它们可以对任何数据交易进行重构,以打包到区块中。
相关阅读:
ECN的翻译工作旨在为中国以太坊社区传递优质资讯和学习资源,文章版权归原作者所有,转载须注明原文出处以及ethereum.cn,若需长期转载,请联系eth@ecn.co进行授权。
本文首发于:https://news.ethereum.cn/Eth2/new-sharding




