FirstBatch 去中心化 AI 系列研报解读1一《数据采集:质量、版权与所有权》
- PermaDAO
- 发布于 2024-02-19 13:09
- 阅读 1910
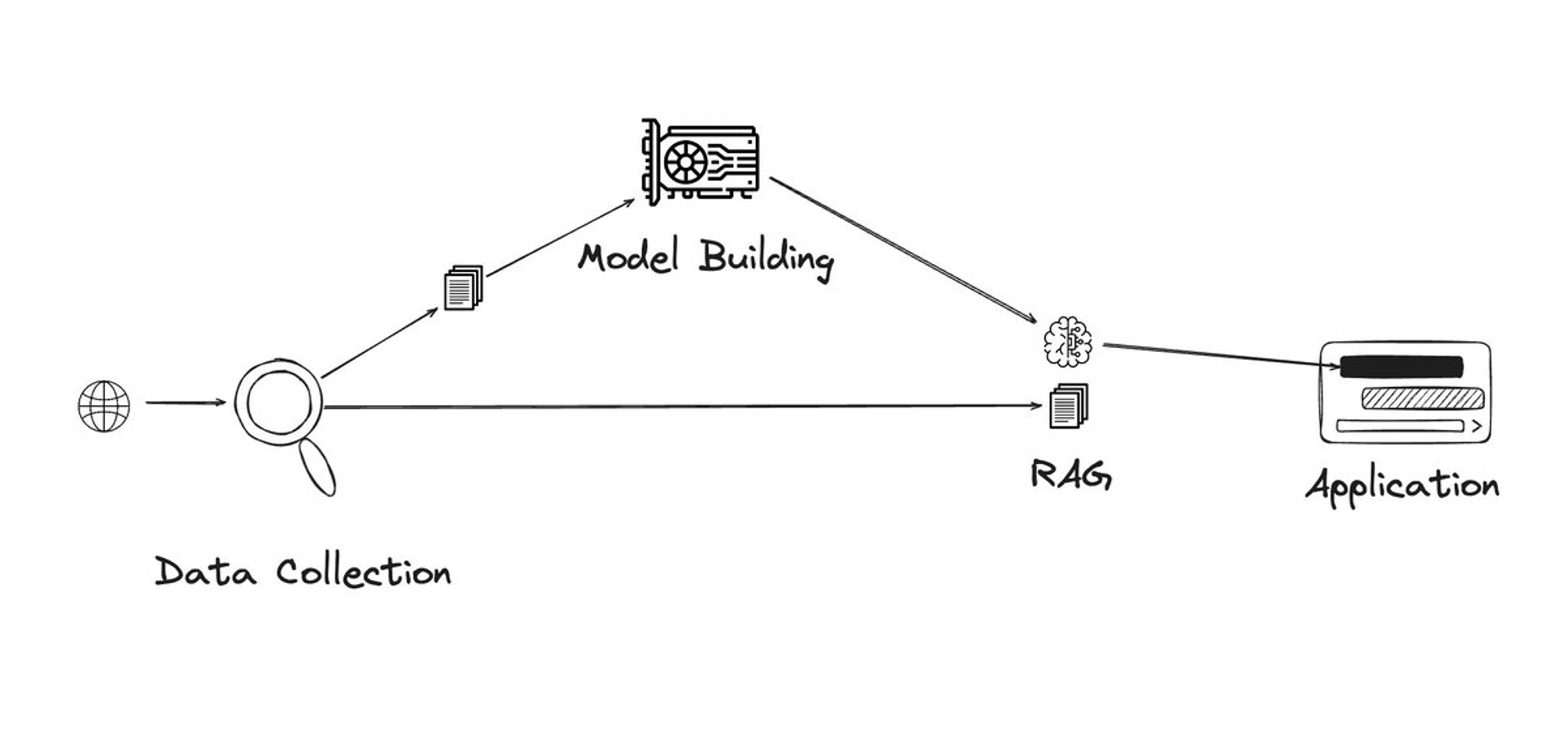
目前的 AI 团队和开发者在数据采集中会遇到的问题:1)无法收集足量的数据 2)无法收集到优质的数据 3)存储问题 4)隐私控制 5)版权问题。我们将逐一来看去中心化是如何为这些问题提供解决方案的。
 作者: Jomosis @ Contributor of PermaDAO
作者: Jomosis @ Contributor of PermaDAO
审阅:Lemon @ Contributor of PermaDAO
FirstBatch 去中心化 AI 系列研报解读一《数据采集:质量、版权与所有权》
FirstBatch 是 Dria 的母公司。Dria 是一个存储在 Arweave 上的开源知识聚合平台,旨在建立人类与机器之间的知识交流,被 FirstBatch 称为 “AI 版的维基百科”。最近 FirstBatch 开启了一个研究去中心化 AI 的研报系列,聚焦数据聚合问题与去中心化的结合点。这篇报道中我们将导读第一篇研报《数据采集:质量、版权与所有权》的内容,我们会关注去中心化是如何为数据采集问题提供解决方案的,以及去中心化方案存在的风险和挑战。
去中心化如何解决数据采集中遇到的问题
目前的 AI 团队和开发者在数据采集中会遇到的问题:1)无法收集足量的数据 2)无法收集到优质的数据 3)存储问题 4)隐私控制 5)版权问题。我们将逐一来看去中心化是如何为这些问题提供解决方案的。
在收集数据量方面,Meta 的首席 AI 科学家指出,尽管现在 LLM 有非常大的进展,用于训练 AI 模型的数据仍然比不上一个 4 岁小孩获取到的信息量。目前,数据的类型和来源局限于文字和某些垂直领域。FirstBatch 畅想的是可以通过社交或者经济激励来鼓励团队或者个人来做数据的审编和筛选的工作,这样可以将大大提高引入新的数据种类的速度,也可以增加多种数据源。
现在,AI 开发者们面临的挑战是无法收集到优质数据以及很难检测收集到的数据的质量,因为数据源中有很多重复和过时的数据,并且当下自动检测的方式降低了数据的准确性和质量。FirstBatch 从开放数据平台如 Hugging Face、Kaggle 和维基百科提高数据质量的经验中得到灵感,FirstBatch 提出了可以建立去中心化开放数据中心,让所有的人都可以参与数据的筛选、审核和评价过程。这样做既可以减轻专门保证数据集质量的小团队的处理压力,也可以防止数据被单一组织操纵或干预。如果实行合适的激励机制,这些去中心化的数据开放中心和社区化数据审核流程可以在高速和大量数据流入时,确保数据的质量。目前 FirstBatch 旗下的产品 Dria 正在构建这样的去中心化全球知识中心。**
存储上 AI 项目遇到的问题是成本和维护问题。面临不断增长的数据量,和随之而来的订阅费用的上涨,这些使用者也想过提前购买更大的空间来获取折扣,但这样在经济和技术角度上同样是种浪费。FirstBatch 选择将数据存储在可以永久存储数据的 Arweave 上,这样可以免受数据丢失的风险。不仅如此,还可以在上面创建共享数据池来让大家存储不同的数据,这样不同的数据就可以存储在同一个地方,解决了在不同的地方存储相同数据,造成空间浪费和存储费用浪费的问题。
数据中会存在一些识别个人身份的数据,这些数据具有隐私性,将这些数据的筛查公开给协作平台让成千上万人审查会违背一些隐私条例。FirstBatch 提出可以在这些隐私数据进入公开的数据筛选平台之前,利用零知识证明或者 DID 的技术,让未来的线上活动数据都可以在隐私保护的模式下进行。
许多在线平台和媒体机构对 AI 公司使用受版权保护的材料提出质疑,称 AI 模型的训练和使用对原始内容造成侵权。NFT 由于链上行为的透明性和不可更改性,使创意/知识产权材料的所有权非常清晰和透明。这些代币可以用于验证和识别哪些材料受到何种类型的程序的约束,从而使数据清理过程和应对诉讼更加容易。
去中心化方案的风险和挑战
去中心化方案虽好,但仍然存在的问题是用户的匿名性带来的风险。例如,当涉及到版权或有害内容的相关法规问题时,匿名的违法行为可能会引发更大的问题,将平台置于风险之中。将数据永久存储在去中心化网络上的情况下,上传的数据中可能依旧包含有害内容,即使有大众的数据审查,仍然避免不了漏网之鱼。
目前存在的一大挑战是如何分配数据量和质量激励的权重。因为无论平台如何架构,总会有人上传更多质量较低的数据或质量较高但数量较少的数据。
总结
随着去中心化 AI 数据采集平台的进一步发展,将会有更多机会促进更好的协调范式,以实现更顺畅的数据收集流程。我们也期待 FirstBatch 的 Dria 能带来更多有关于提高数据的数量和质量方面的好消息。
关于 PermaDAO:Website | Twitter | Telegram | Discord| Medium | Youtube

- 原创
- 学分: 0
- 标签:





