Arweave学习
Arweave是主打永久存储的去中心化存储网络。但它有特色的是PermWeb层的引入,让它有可能成为未来web3世界的计算机。(它最新的AO就印证了这一点,本文还没研究AO) 本文主要来自Arweave官方文档的翻译和摘取,时间:2023.10
<!--StartFragment-->
本文主要来自Arweave官方文档的翻译和摘取,时间:2023.10
1. 概述
ARWeave主打永久存储,它包含两个核心产品:
-
ARweave,即文件永久存储服务,可以认为是存储层。
-
Permaweb,建立在ARweave存储之上的网络,可以认为这是建立在ARweave存储层之上的,对存储内容的访问和解释层。因为ARweave可以存储任意类型,所以这个访问和解释层就可以有非常多种形态,有很好的扩展性。它可以在原始的浏览器中直接访问,而无需额外开发。
比如ARweave里的是图片,用Permaweb打开就能看到图片,存的是html网页,打开就能看到网页。用Permaweb还可以创建动态网页。
Permaweb由如下内容组成:\ -
- Arweave,永久存储的去中心化数据层
- 网关:各种商业模式和激励措施支持的内容交付服务器
- GraphQL:网关公开的查询系统,可以像传统数据库,web程序一样做查询。
- SmartWeave:智能合约系统,可以有token。
\
带宽和业力(Karma)
业力就是IPFS里的libp2p的积分。节点观察自己与其他节点的数据交换,依据数据提供/下载量对其他节点打分,从而决定是否要跟其他节点共享数据。有时候节点也会随机地,不根据业力得分来传输数据,从而达到纳什均衡。
对业力的计算是由每个节点自己进行的,并没有全网共识。节点也可以选择完全不管业力。所以节点在网络传输上的自由度,自主能力是非常高的。
业力对网络稳定是非常重要的,因为乐于分享数据,能够快速回应数据请求的节点可以获得更高的排名,别的节点也更乐意与更高排名的节点分享数据,从而可以让区块数据更容易被更多节点保存,尤其是比较稀有的节点数据。这有利于永久存储文件。如果大家都持有一些区块,但不分享给其他节点,那么某些区块数据可能就随着时间流逝丢失了,这是要极力避免的。
内容审查
ARweave认为任何节点都不应该被强迫存储自己不想存储的内容,所以其架构中的所有层均可自己进行内容审查,决定自己要存储的内容。
- 矿工。矿工可以对他们存储的任意内容进行检索和计算,从而决定是否要存储它们。矿工要遵守当地法律。
- 网关。用户访问PermWeb时,一般都是通过网关进行的。与矿工类似,网关也可以选择它们检索和服务的内容。相应的,用户也可以自由选择能代表其价值观的网关。同样的应用,可能因为通过不同的网关,可能带来不同的结果。
- 在DApp层面,开发人员可以将内容过滤代码永久部署在ARweave上。在代码层面,永久进行内容过滤。
网关
用户通过网关查看ARweave上的内容,可以通过没经过特殊处理的浏览器查看。比如图片或html文件等。另外也可以托管动态app,网关通过公开的JS,GraphQL查询ARweave网络。
注意:网关的激励被排除在ARweave的协议之外,因此这允许建立各种不同的激励模式。开发者不需要为用户的访问买单,因此可以建立部署一次,永久免费,永久使用的dapp。
大部分网关都会公开GraphGL的接口,因此用户可以通过这些接口查询,检索链上event等。例如用app:blog, type:post就能检索用户发布的blog。
链扩展性
通过ANS-104,我们可以知道AR是怎么存储文件的。简单来说,把文件都保存为区块链上的交易。例如一个文件可以被拆分为多个DataItem,每个DataItem保存文件的一部分,这些DataItem可以按照规则拼接回完整的文件;每个DataItem可以被设置多个tag(k,v)等可扩展标识,设置owner等固定标识;而且可以对其签名。这让系统用统一的规则来灵活的处理文件和交易,即文件的存储,和转账等交易,都是交易,都有统一的结构。
因为ARweave上的存储都是永久存储,因此不需要像其他区块链一样,处理存储期限,谁存储等问题,因此它的处理很容易:支付一次,永久存储。因此增加新的文件存储不需要增加计算量等,唯一增加的就是存储空间。
ARweave拥有巨大的存储池,里面都是一个个数据切片,每个数据切片都256kb。有一个merkle树组织这些分片。这种统一的存储模式允许ARweave可以管理矿工们为存储生成的Proof of Storage(PoS)。
AR的出块时间是2分钟,每个块最多容纳1000笔交易。因此TPS很低。但是交易可以被捆绑,非常多交易可以被捆绑为一笔交易,另外捆绑是可以递归的,因此可以认为AR有无限的交易容纳能力。几千笔交易就可以处理百万条数据。因此AR可以在如此低的TPS下,不存在交易市场(也就是不用竞争gas,就能入块,但是要接受捆绑交易商的服务,如Bundlr Network和EverVision HQ)
不过需要注意,转账交易是不能捆绑的,只有存储文件的交易可以捆绑。因为捆绑后会由根来支付存储费用。
2. 经济学设计
2.1 存储成本和挖矿奖励
https://arwiki.arweave.dev/#/en/storage-endowment
\

\
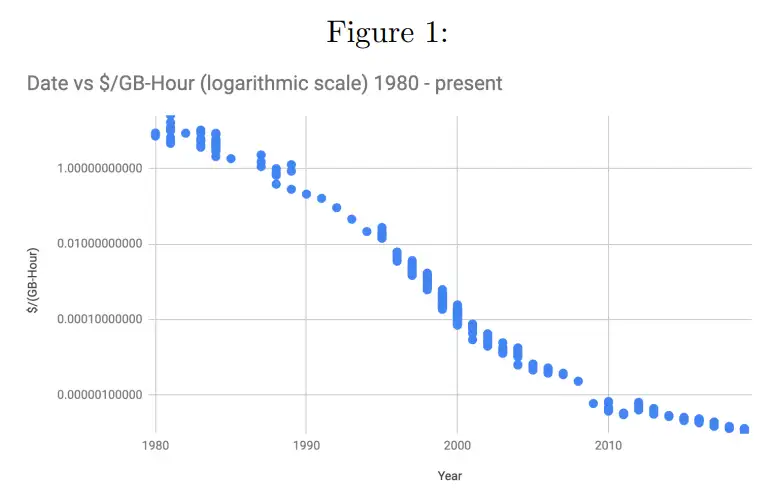
商用存储GBh成本一直在下降
\
\
因此永久存储的成本可以认为是随时间推移而下降的存储成本之和。
\

\
交易定价如下,由两部分组成,对永久存储的估价(把文件存储200年的费用),和一个预定的比例。
\

\
存储禀赋(Storage Endowment)
为了网络可持续发展,在每个区块,都必须维持奖励大于存储支出。
\
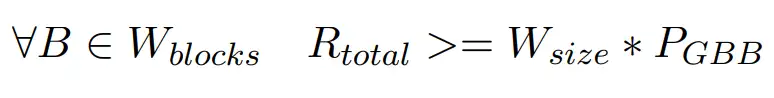
\
但也不能太多,需要在代币价格和存储成本之间寻求一种稳定。所以挖矿奖励由3部分组成:
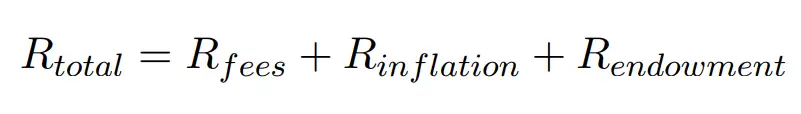
\
Rfees是区块中交易费之和,即存储这些文件缴纳的费用。但请注意,用户支付的是永久存储费用,这是比较高的费用,这些费用中只有14%会立刻被矿工收取作为手续费;剩下的86%会进入endowment pool,当未来手续费和区块膨胀费用不够覆盖矿工成本时,endowment pool中的代币会被分发出来,可以看下面Rendowment部分。
通货膨胀奖励是随着区块高度增加而逐渐减少的(逐块减少),如下:
\

\
如上所述,只有在交易费和通货膨胀无法覆盖矿工们的存储成本的情况下,捐赠(Endowment)部分才不为零。因为存储很便宜,所以很大的可能,很长时间内,都不会有捐赠币。
\
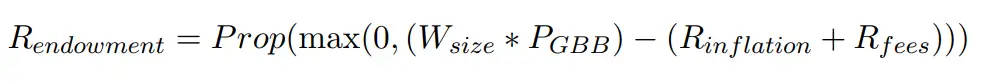
\
Prop函数会取出之前区块的捐赠水平,让下个新块的卷则与之前的捐赠平均数成比例,这样可以避免链上出现特大块或特小块。
\

\
最终,下一个块的捐赠计算方法如下:
\

\
如上存储成本分析,以及经济学设计中,存储成本持续下降是重要的前提。这可以通过一系列数据以及技术分析可以得知,这在很长一段时间内都将会是正确的。存储成本的下降比率称为Kryder Rate。
在AR中,使用Kryder + 模型,它考虑了一些其他因素:多副本成本,电力,及运营成本。这些成本与存储成本类似,也会是按比例下降的,只不过参数有些不同。AR通过向用户收取 200 年存储成本来达到永久存储,因为那之后的存储成本,预估可以接近0.
2.2 存储价格的稳定
用户以AR支付存储费用,但AR的价格是浮动的,因此AR采取一种措施,让存储价格能稳定在法币上。
三个因素影响存储成本:
- 正在存储的数据大小
- 目前永久存储 1 GB 数据的法定成本
- AR(Arweave 的原生代币)的法定价格
\

\
为了确定 AR 的法定价值,Arweave 使用代理措施,而不是依赖外部预言机 - 它根据以下因素估计代币的价值:
- 基线:AR在历史特定时刻的参考价格。
- 变化:AR 奖励相对于基线的相对变化。
AR 奖励的变化本身取决于两件事:
- 网络难度(直接关系):难度增加意味着更多矿工有动力参与生态系统——这是AR价格上涨的信号。
- 通货膨胀奖励(反比关系):随着通货膨胀奖励减少,AR 的价格应该上涨,以跟上采矿成本。
一堆代码和计算后...
\
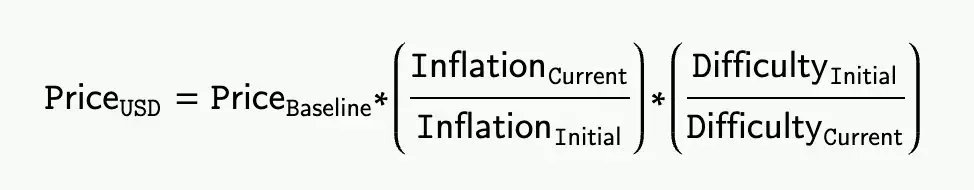
\
注意上面的Priceusd是美元的价格,也就是AR价格的倒数。例子:
- 网络难度:如果网络难度增加 2 倍,上面计算的值会减少一半,AR 的估计值会增加一倍(因为越来越多的矿工发现网络挖矿利润丰厚)
- 通货膨胀奖励:如果通货膨胀奖励减少到初始奖励的1/4,则上面的计算值按比例减少(4x),AR的预估价格翻倍
反之亦然。
请注意,存储成本不取决于AR的价格,而是取决于随着时间的推移矿工支付的实际价值!这意味着,如果出于某种原因,美元购买力增加,分配给矿工的 AR 数量将超过必要的数量,导致更多矿工涌入系统,并随后调整该机制对 AR 代币价格的估计。
上述价格稳定机制依赖于几个假设:
- Arweave 挖矿的市场是高效的。这意味着 AR 价格的所有变化都会很快被矿工利用。这个假设可能过于理想化,因为它没有考虑 AR 挖矿的复杂性、时间滞后和进入壁垒。
- 通货膨胀奖励是挖矿奖励的当前主要部分,因此通货膨胀奖励与 AR 价格之间是互惠的关系。实际上,虽然通货膨胀奖励目前占矿工总奖励的很大一部分,但由于通货膨胀时间表,它们将逐渐形成较小的部分。考虑到这一点,在未来的更新中,协议将根据分配给矿工的全部奖励(而不仅仅是通货膨胀部分)来稳定价格。
2.3 挖矿
AR挖矿的目标是尽可能增加对数据的复制副本。在挖矿过程中,会产生大量简洁随机存取证明Succinct Proofs of Random Access (SPoRAs)。具体参考https://github.com/ArweaveTeam/arweave-standards/blob/ans-103/ans/ANS-103.md
前提:
- 机制的核心是要连续读取历史数据块,每个数据块都有个offset,所有的数据都能够通过offset被索引到。
- 共识机制需要一种确定性但不可预测的方式来选择候选块作为挑战。选择候选块不能太容易,太容易的话,矿工就会只存那些会被选中的块。这里使用RandomX算法。
算法:
每个块都唯一地定义一个搜索空间 [0, weave size at a certain block (Search Space Upper Bound)],目前默认搜索空间是所有数据的10%。
- 生成随机数nonce,使用RandomX,计算出Merkle tree的hash的hash(Hash 0),这个merkle tree包括当前状态,待选区块,nonce。
- 通过H0,上一个块的hash(PrevH),和搜索空间边界,计算出唯一的recall byte。
- 搜索本地的区块,寻找包含这个recall byte的数据chunk,找不到就从a重新开始。
- 计算H0和包含recall byte的数据的块的快速hash
- 检查这个快速hash是否比当前的链的难度值大,如果没有,就从a重新开始;如果有,就打包并发布区块。(包含Nonce和chunk)
这个chunk和包含它的块的merkle证明,被称为Succinct Proof of Random Access (or SPoRA) 。这种算法会让矿工在CPU和存储之间进行权衡,矿工存储的数据副本越多,越可能走到h。
对网络搜索空间的限制(a步骤)可以激励矿工存取那些比较冷的数据。
\
搜索空间(Search Space Upper Bound)的选择:
搜索空间需要足够大有两个原因:
- 使得按需下载整个搜索空间的成本过高。
- 使得通过散列来弥补数据缺失的成本过高。
另一方面,搜索空间需要足够小,以激励矿工复制较稀有的数据,这将使他们比在相应区块上复制较少相应区域的矿工更有优势。
当前搜索空间大小为数据的 10%。在这种情况下,10% 的矿工在网络中存储独特的 10% 的数据,而每个人都存储 90% 的数据,其效率大约是其他矿工的 1.2 倍。它适用于计算 RandomX 哈希所需的时间与查找块所需的时间的各种比率。
3. PermWeb
3.1 网关
网关解析AR上存储的数据,并将其作为一个接口提供给用户使用。
网关能力
网关必须实现一个http接口,它能够响应路径/_arweave_gateway_capabilities上的GET,其内容应该表示当前网关的能力。返回值例如:
{
"capabilities": [
{ "name": "arql", "version": "1.0.0" },
{ "name": "graphql", "version": "1.0.0" },
{ "name": "arweave-id-lookup", "verson": "1.0.0" },
{ "name": "post-bundled-tx-json", "version": "1.0.0" },
{ "name": "post-delegated-tx", "version": "1.0.0", "maxFee": "0.00125" },
{ "name": "push-on-event-api", "version": "1.0.0", "platforms": ["push-android", "push-ios", "web-push-firefox", "webhook" ] }
]
}
3.2 Bundle
https://github.com/joshbenaron/arweave-standards/blob/ans104/ans/ANS-102.md
Bundle类似IPFS里的DAG,把文件分片组织起来。不过在AR里,每个文件片都有些属性。
Bundle可以把多个逻辑数据交易(logical data transaction,称为DataItem)打包成一笔交易,是存储文件必不可少的工具。
DataItem与普通的数据交易(DataTransaction)有很多一样的属性,如owner, data, tags, target, signature, and id. 区别是它不能转账token,没有reward。由打包完的根交易支付reward。
Bundle有很多好处:
- 允许支付代理(如DataItem的owner不需要拥有AR币,由打包者帮忙支付)的同时,保存了owner的签名;
- 允许多个DataItem被打包成group
- 提高网络吞吐量。
数据格式
交易Tag
Bundle里必须有两个tag:
- Bundle-Format,可以是json或binary,代表了不同的打包格式
- Bundle-Version,对json,是1.0.0, 对binary,是2.0.0
下面为了方便,用json做例子,binary的内容差不多,格式不一样。
交易体内容:
{
items: [
{ DataItem },
{ DataItem }
]
}
DataItem的格式:
其中Empty String表示这是可选的
\
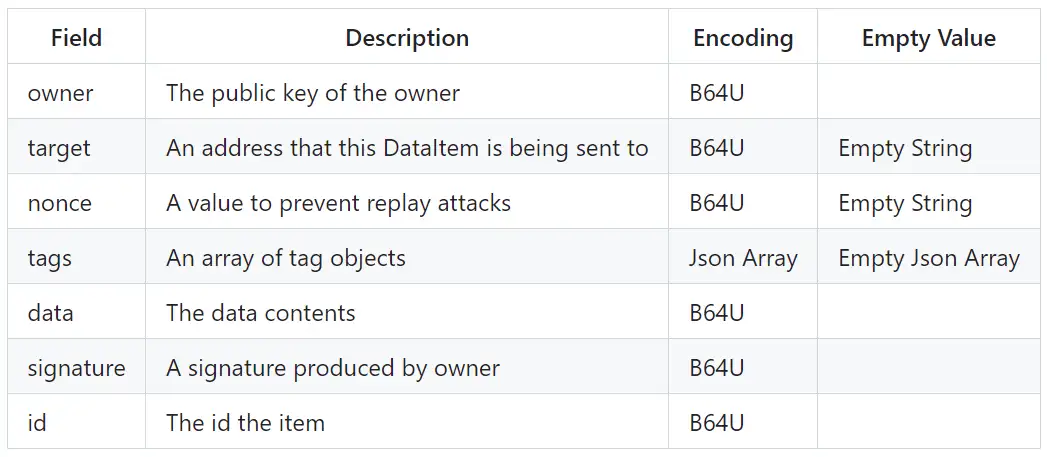
\
其中tags是以“name","value"命名的key,value对。
DataItem的签名
签名内容是递归定义的,用Arweave 2.0深度hash算法,
owner对内容签名,id是签名的sha256
获取签名的内容如下:
[
utf8Encoded("dataitem"),
utf8Encoded("1"),
owner,
target,
nonce,
[
... [ tag.name, tag.value ],
... [ tag.name, tag.value ],
...
],
data
]
3.3 SmartWeave
SmartWeave是AR上的智能合约。它和其他链的合约有很大差别,因为它只对交易有共识,对状态没有共识,实际的合约执行是在客户端本地的,这意味着:
- 合约可以用任意语言编写,如JS
- 合约的执行不受时间限制
- 合约的安全需要信任,即只有信任合约的用户,才会执行合约。
运作原理:
- 开发人员发布合约时,合约源码和初始参数会被提交到AR上保存。
- 有用户希望与合约交互时,他的交易需要提交到链上,达到共识。
- 用户需要执行合约时,需要调用GraphGL,查询获得合约的源码,初始参数,所有历史交易
- 客户端本地执行所有交易,直到获得最新的状态。这个执行过程也可以委托给代理,但是这得信任代理。
标准的SmartWeave客户端调用本地JS引擎来执行交易。因此JS已经称为AR上的通用合约语言。
3.4 GraphQL
GraphQL是在AR上查询transaction/block metadata的最佳工具。服务入口:https://arweave.net/graphql
GraphQL是在AR上构建permWeb,或者构建网关的工具,就像web3j之于以太坊开发。
例如我们想构建一个名字叫PublicSquare的DApp,我们可以使用交易里的tag。这样后续我们就可以检索出所有tag里包含这个名字的交易。
query {
transactions(tags: [{
name: "App-Name",
values: ["PublicSquare"]
}])
{
edges {
node {
id
tags {
name
value
}
}
}
}
}
前半段定义了怎么搜索,后半段定义了怎么返回数据。GraphQL可以查询非常多种类型的数据,具体还得看文档。https://gql-guide.vercel.app/
3.5 ARDrive
一个可以永久存储的DApp
3.6 例子
https://arwiki.arweave.dev/#/en/creating-a-dapp
用AR构建了一个类似twitter的DApp。
<!--EndFragment-->
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
