矿工实用:Arweave 矿机数据监测的三个工具
- PermaDAO
- 发布于 2024-06-11 14:56
- 阅读 1656
作为官方,更倾向于给到一个指导概览,与案例推荐,至于如何能够获得高性价比,又兼具兼容性的配置,还需要矿工朋友们,甚至是有意向的矿机厂商们来努力达成。

作者: ArweaveOasis
原文首发于:@ArweaveOasis 推特
此前,我在《想攒一台 Arweave 矿机需要哪些配置?》一文中列举过 Arweave 矿机需要的配置信息,得到了广大矿工朋友的关注。但反馈仍然是「并不清晰」,「没有更加明细的配置清单与攒机教程」。在这里,我想表达的是对于矿机的配置,硬件与硬件之间会有兼容性问题,此外还有性价比的考量,对于挖矿来说,成本永远是极其重要的考量点之一。而这些都需要经过大量实际测试,才能更加明确,这对于资源有限的官方来说无疑是比较重的工作。所以作为官方,更倾向于给到一个指导概览,与案例推荐,至于如何能够获得高性价比,又兼具兼容性的配置,还需要矿工朋友们,甚至是有意向的矿机厂商们来努力达成。
不过不得不说,近期官方共识工程师不仅在版本迭代上,还是在文档更新上都更加频繁。这些基础设施与信息的不断完善,让整个底层变得更加稳定。
今天就为大家更新一下在矿机硬件指引内容中新增的内容 —— Arweave 矿机基准测试。
在 Arweave 节点中,附带了三个工具,可以用来做矿机性能的基准测试与数据监控。
- 打包(Packing): ./bin/benchmark-packing
- Hashing: ./bin/benchmark-hash (目前在 master 中,将会在 v2.7.4 发布)
- VDF: ./bin/benchmark-vdf
打包 Packing
benchmark-packing 工具将会报告矿机的所有核心每秒预期的打包数据块的数量。
这里我做一下补充说明:打包数据块是矿工进行挖矿之前必须要做的事情。矿工获取到 Arweave 网络中的原始数据之后是没有办法直接进行挖矿的,需要将自己的挖矿地址与数据一起 Packing 一遍,将数据做成一份独立的副本,所有数据也以统一的格式转换成为以 256 KiB 为单位的一个个小数据块(我们称其为 Chunk)之后,才可进行挖矿。在矿圈,这又被称为 P 盘。这个过程会相对比较缓慢,其速度与 CPU 运算速度相关。这个 benchmark-packing 工具就是用于了解该机器 P 盘的速度的。
实践中,机器除了 P 盘外,还需要运行其他相关进程,这会占用一部分计算资源,所以观察到的值会略少于 benchmark-packing 值。但这仍然是一个具有高度参考性的度量标准。
更多关于信息可以参阅 《同步和打包指南》。此外,你还需要记住的:
- 在同步时,你应该预期每写入一个块,就会有一到两次打包操作。
- 每个数据块大小是 256 KiB。
例如,如果benchmark-packing工具报告你的 CPU 每秒打包 100 个块,那么你可以预期你的节点的上限速度为 12.5 到 25 MiB / s进行同步。
Hashing
benchmark-hash 工具将报告计算 H0 哈希以及 H1 或 H2 哈希的速度,单位为毫秒。这些指标主要用于挖矿时使用。
报告的时间是单线程(即单核)执行的时间。系统每秒计算的 H0 或 H1/H2 哈希的数量可以根据你的 CPU 核心数量进行扩展。我们尚未对超线程/SMT 的影响提供指导,因此目前最好只计算 CPU 上的物理核心数量,而不是虚拟核心。
请记住以下几点。对于每个 VDF step,你的矿机将计算:
- 每个分区 1 个 H0 Hash
- 每个分区 400 个 H1 Hash
- 每个分区 0-400 个 H2 Hash。具体的 H2 Hash 数量由你用于挖矿的 weave 数据量来决定。
这里我做一下补充说明:Hash 数量与速度是直接关系到矿工挖矿效率的重要指标。可以这样理解,hash 数量越多,出块几率越大,而 hash 数量是受到矿工存储数据分区的多少来决定的。其中 H0 是挖矿哈希,只有获得 H0 才能够有 H1 与 H2。H1、H2 是回溯范围的 hash 数量,每个回溯范围是 100 MiB 大小,在这个范围中就有 400 个 256 KiB 数据块用于 Hash。所以每个 VDF step 就像是限时的计数始终,在每个计数中,每个分区都会获得一个 H0,从而获得每分区 400 个 H1 哈希,与 0-400 个 H2 哈希。
对于以下示例,请记住,所有基准测试中的这些计算都是一个参考。在实际操作中,你的哈希速度会受到许多基准测试未捕捉到的因素的影响(例如,与其他运行进程的争用、超线程/SMT 的影响等)。另外,矿工也需要根据这些数据来预估需要多少 CPU 容量来进行计算,以便发挥矿机的最大效能。
示例 1
- 全网分区数量是 50 个;
- 矿工拥有所有 50 个分区的数据,并通过它们进行挖矿;
- 在每个 VDF step 需要计算的 Hash 数:
- 50 个 H0 Hash
- 20,000 个 H1 Hash (50 400) - 20,000 个 H2 Hash (50 400)
- benchmark-hash 报告
- H0: 1.5 ms - H1/H2: 0.2 ms
- 每个 VDF step 你会需要 8,075 ms 的计算时间 (40,000 0.2 + 50 1.5)。
- 这意味着你会需要超过 8 个核心的 CPU 来挖掘 1 秒的 VDF。
示例 2
- 全网分区数量是 50 个;
- 矿工只拥有 20 个分区的数据量,并通过它们进行挖矿;
- 在每个 VDF step 需要计算的 Hash 数:
- 20 个 H0 Hash
- 8,000 个 H1 Hash (20 400) - 3,200 个 H2 Hash (20 (20/50) 400)*
- benchmark-hash 报告
- H0: 1 ms - H1/H2: 0.1 ms
- 每个 VDF step 你会需要 1,140 ms 的计算时间 (11,200 0.1 + 20 1)。
- 这意味着你会需要超过 1 个核心的 CPU 来挖掘 1 秒的 VDF。
VDF 速度
benchmark-vdf 工具将会报告计算 VDF 所需的秒数。
注意:基准测试工具假设 VDF 难度固定为 600,000。Arweave 网络的 VDF 难度每天更新,以网络平均 VDF 速度为 1 秒为目标。
截至 2024 年 5 月 6 日,区块高度 1,419,127,Arweave 网络 VDF 难度为 685,016。随着 VDF 难度的提高,VDF 时间增加(变慢),随着 VDF 难度的降低,VDF 时间减少(变快)。
所以今天如果 benchmark-vdf 工具报告你的 CPU 的 VDF 为 1 秒,你可以预期一旦连接到网络,将达到 1.14 秒。(685,016 / 600,000) * 1秒 = 1.14 秒。
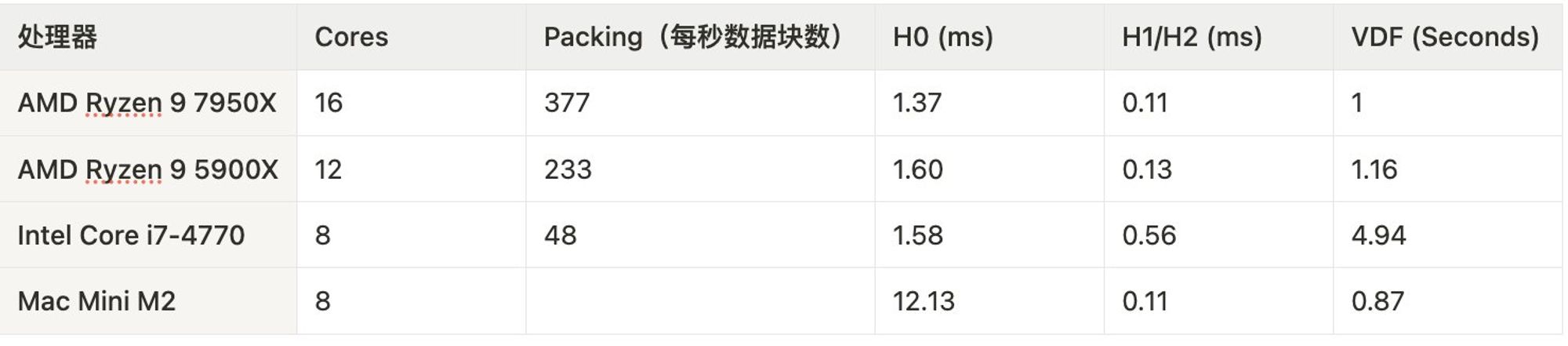
一些参考样本数据
这些数据是来自 2024 年 5 月 6 日,由于样本量较小,所以也许会有不准确。
关于 PermaDAO:Website | Twitter | Telegram | Discord| Medium | Youtube

- 原创
- 学分: 0
- 标签:





