硬核对话Scroll张烨:zkEVM与Scroll及其未来
- 仙壤
- 发布于 2024-07-01 17:13
- 阅读 2455
对Scroll的联创张烨 的采访,关于 zkEVM 与 Scroll 及其未来
采访者:Nickqiao & Faust,极客Web3
受访者:YeZhang,Scroll联创
编辑:Faust & Jomosis
6月17日,极客Web3 和 BTCEden 在Scroll的DevRel——Vincent Jin的帮助下,有幸邀请到了Scroll的联创张烨,来解答关于Scroll和zkEVM的诸多问题。
期间双方不但谈到了很多技术话题,还谈到了 Scroll 的一些趣事,以及其赋能亚非拉实体经济的宏大愿景。本文是此次访谈的文字版记录,超过1万字,共包含至少15个话题:
-
ZK在传统领域的应用空间
-
zkEVM和zkVM在工程难度上的差异
-
Scroll在实现zkEVM过程中遇到的难题
-
Scroll对Zcash的halo2证明系统作出的改进
-
Scroll是怎么和以太坊PSE小组展开合作的
-
在代码审计层面Scroll如何确保自己的电路安全可靠
-
Scroll对未来的新版zkEVM及证明系统的简单规划
-
Scroll的Multi Prover设计以及其Prover生成网络(zk矿池)的搭建方式 等。
除此之外,张烨老师在最后谈到了 Scroll 将扎根在非洲、土耳其、东南亚等金融系统落后地区,打算为该地区人民创造实体经济场景以“脱虚入实”的宏大愿景 。本文可能是让更多人更好理解 Scroll 的绝佳资料之一,推荐大家仔细阅读。

ZK 在传统领域的应用空间
-
Faust:请问张烨老师对于ZK在Rollup 之外的应用怎么看?不少人习以为常地认为,ZK的主要用处在混币器、隐私转账或ZKRollup和ZK桥这些地方,但在Web3 之外,比如传统行业里对ZK的应用还是很多的。您觉得未来ZK最有可能在哪些方向上被采用?
YeZhang: 这是一个好问题,传统行业里做ZK的人,在五、六年前就在探索ZK的各种场景, 区块链中用到ZK的场景其实非常小,这也是为什么Vitalik觉得十年后,ZK的场景会和blockchain一样大。
我觉得在那些需要信任假设的场景中,ZK会有很多用武之地。 假设你现在需要处理一些繁重的计算任务,如果你在AWS上租服务器,运行自己的任务并得到结果,相当于你在自己控制的设备上做计算,然后你要支付租服务器的钱,但这笔钱往往并不便宜;
但如果我们搞计算外包的模式,很多人可以用自己闲置的设备或资源分担你的计算任务,你付出的成本可能比自己租服务器更便宜。但这里存在信任问题,你不知道别人返回给你的计算结果是否正确。现在假设说你在做一个很麻烦的计算,然后你把计算交给我来做,再给我钱。我过了半小时后随便交给你一个结果,你也没有办法相信这个结果是有效的,因为我可以随便编个结果。
但如果我能向你证明,交付的这个计算结果是对的,那你就可以放心了,并且也敢把更多计算任务外包给我来做。 ZK可以把很多不可信的数据来源变为可信的,这个功能非常强,通过ZK,你可以把不可信但很便宜的第三方计算资源更高效的运用起来。
我觉得这个场景非常有意义,可以催生类似于外包计算的商业模式。在一些学术文献里,称其为可信计算(verifiable computation),就是把一个计算变得值得信任。除此之外, ZK可以应用到数据库领域 ,假设在本地运行数据库太贵了,你决定走外包的路子,恰好一个人有富余的数据库资源,然后你把数据存储在他那边。你会担心对方更改你托管在他那的数据,或者说你一个 SQL query后得到的结果对不对?
对此,你可以让对方生成一个proof,如果这件事能做到, 你可以把数据存储也外包出去,并得到一个trustworthy的结果。 这和前面的可信计算彼此都是一大类应用场景。
此外还有很多应用实例,我记得 有篇论文讲了 Verifiable ASIC, 在生产芯片的时候,可以把ZK算法写到你的芯片上,当你用芯片运行程序的时候,产生的结果默认会带一个Proof。这样一来我觉得很多东西都能代理给任何一台设备,生成可信的结果。
还有一个有点扯的东西,叫PhotoProof 照片证明。 比如说很多图片,你不知道是不是P过的,但我们可以通过ZK去证明相片没有被篡改过,比如可以在相机软件中加一些设置,自动生成一些数字签名,你拍完照片后,这个签名相当于给照片盖了章。如果有人把你拍的照片拿去PS,搞“二次创作”,我们验证下签名就能识别出图片是被改动过的。
这里面我们可以引入ZK,当你对原图进行了些许改动后,你可以用ZK Proof向别人证明自己只是对照片做了旋转、平移等简单操作,并没有篡改照片的原始内容,证明自己微调后的图片和原版图片基本一样,也就是证明自己没有篡改图片的核心内容搞“二次创作”。
这个场景 还可以拓展到视频音频上,通过ZK,你不必告诉对方自己对原版视频做了哪些改动,但可以证明自己没有篡改原版的核心内容 ,证明自己只做了一些无伤大雅的调整。此外还有很多有意思的应用,都是ZK能插一脚的。
目前,我觉得 ZK的应用场景还没有被广泛接纳的原因,在于其成本太高,现有的ZK证明生成方案,还不能做到对任意计算都实时生成证明, 因为ZK的开销一般是原始计算的100倍到1000倍,当然我说的数字已经是压的比较低的了。
所以你想象一下,一个计算任务本来要算1小时,你现在给它生成个ZK Proof,Overhead可能是100倍,也就是要花100个小时来生成证明,虽然你可以用GPU或ASIC把这个耗时给缩短,但还是要付出巨大的计算开销,如果你要求我算一个很麻烦的东西,还要求我为此生成ZK Proof,我可以拒绝这么做,因为这要额外耗费100倍的计算资源,最后落实到经济账上就很不划算。所以 对于一对一的场景来说,生成一次性的ZK证明很昂贵。
不过,这也是为什么 对于Blockchain来说,非常适合用ZK,原因是区块链做的是冗余计算,有很多1对多的场景。 区块链网络中不同节点做的是相同的计算任务,如果有1万个节点,那么相同的任务要被执行1万次。但如果你在链下完成任务,生成ZK证明,1万个节点只验证ZK证明而不重跑任务,就不必再把原始计算重放1万遍了,相当于你用自己1个人的计算成本,和1万台节点搞冗余计算的成本做了置换,从整体的角度看,可以让更多人节约资源。
所以,其实链越去中心化越适合搭配ZK,因为 任何人都能近乎零成本的验证ZKP,我们只要在初始生成证明的时候付出一定成本,就可以换来对大多数人的解放,这就是为什么区块链的公开可验证性非常适合ZK,因为区块链里有很多1对多的场景。
还有一个上面没提到的点。现在区块链领域用到的Overhead比较大的这种ZK证明,都是非交互式的,就是你给我一个东西,我给你证明,然后就结束,因为在区块链中,你不可能反复的去跟链上交互。但有一种更高效、开销更低的证明生成方式,也就是交互式证明。比如说,你给我发一个Challenge,我给你发一个东西,你再给我发一个东西,我再给你发一个,通过这种双方多次交互的方式,有可能把ZK的计算量级再降低下来。如果这种方式可以,就有可能解决大的ZK应用场景的证明生成问题。
如何看待 zkML
Nickqiao:如何看待zkML,也就是ZK和机器学习相结合的发展前景?
YeZhang: zkML也是一个很有趣的方向,能把Machine Learning给ZK化,但 我觉得这方面还是缺乏杀手级的应用场景。 大家普遍认为随着ZK系统的性能提升,未来能够支持ML这个级别的应用,目前zkML的效率能够支持gpt2这种级别的应用,在技术上能做到,但只能做ML中的推理。归根结底,我觉得大家还是在摸索这块的应用场景,也就是 到底什么样的东西才需要你证明其推理过程是对的 ,这个事情是挺刁钻的。
zkEVM和zkVM 工程实现差异
-
Nickqiao:想请教下张烨老师,zkEVM和zkVM在工程实现难度上的差异具体有多大?
YeZhang:首先,无论是zkEVM还是zkVM,本质都是为某个虚拟机的操作码/指令集生成定制的ZK电路, 而zkEVM的工程落地难度取决于你实现它的方式,在我们刚启动项目时,因为ZK的效率还没那么高, 通过为EVM的每个操作码都写一个对应的电路,然后把电路组合起来,定制一个zkEVM是最高效的方式。
但这种方案的工程实现难度肯定很大,比zkVM大很多, 毕竟EVM的指令集有超过100个操作码,每个操作码都要定制一套东西,然后组合起来, 一旦有EIP为EVM增添新的操作码,比如EIP-4844,zkEVM都要相应的加新东西。 最后你要写很长的电路并进行漫长的审计工作,所以开发难度和工作量要比zkVM大很多很多。
反之, zkVM是自己定义了一套指令集/操作码,它自定义的指令集可以做的很简单, 可以很ZK friendly,你做出来一套zkVM后,不必频繁的更改底层代码,就能支持各种升级和预编译。所以 zkVM的主要工作量和后续升级维护的难度,就放在了编译器也就是把智能合约转化为zkVM操作码的那一步,这和zkEVM有很大不同。
所以,从工程难度来看,我觉得zkVM要比定制化的zkEVM更容易实现, 但是如果要在zkVM上跑EVM的话,总体性能比定制化的zkEVM低很多,因为后者是专门定制的。 但目前,Prover生成证明的效率在过去两年间有了至少3~5倍甚至5~10倍的飞跃,zkVM的效率在随之提升,现在用zkVM去跑EVM,整体效率已经慢慢提上来了,未来zkVM在性能上的劣势可能被它易于开发维护的优势给掩盖住。 毕竟对于zkVM和zkEVM而言,除去性能外的最大瓶颈就在开发难度上,必须要有一个非常强大的工程团队,才能维护好这样一套复杂的系统。
Scroll遇到的技术难题
-
Nickqiao: 能否讲一下Scroll在zkEVM落地的过程中,是否遇到一些技术难题,又是怎么解决的?
YeZhang: 一路走来的话,最大的挑战还是在于,最初启动项目时的不确定性太大。 我们刚启动项目时,基本没有其他人做zkEVM,我们是最早探索zkEVM从不可能变成可能的一个团队。 在理论层面,项目刚开始的6个月就基本确定了一套可行的框架,而 在后续实现的过程中,zkEVM的工程量非常大,还有一些非常技术性的挑战, 比如说你怎么动态的支持不同的Pre-Compile(预编译),怎么去更高效地聚合操作码(opcode),这涉及到很多工程上的难题。
而且我们是唯一一个,也是最早支持EC Pairing椭圆曲线配对这个Pre-Compile的,像Pairing这种电路实现起来难度非常大,涉及到很多数学等错综复杂的难题,对写电路的人的密码学/数学功底,以及工程能力要求都很高。
然后在后期发展上,还要考虑技术栈的长期可维护性,以及要在什么样的时间节点,升级到下一代的zkEVM 2.0。 我们有一个专门的研究团队,一直在研究此类方案,比如通过zkVM的方式来支持EVM, 我们也有相关的论文去做这方面的一些讨论。
总结下来,我觉得之前的难点在于把zkEVM从不可能变为可能,面临的难题主要在工程落地和优化上。而 下一阶段,更大的难点是在什么时候、通过什么样的具体方式,切换到一个更高效的ZK证明系统,以及我们怎么把目前的这套代码库过渡到下一代zkEVM身上,以及下一代的zkEVM能给我们提供什么样的新Feature, 这里面有大的探索空间。
未来Scroll打算换用什么证明系统
-
Nickqiao:听起来是Scroll已经考虑切换到别的ZK证明系统上了。据我了解,目前Scroll用的是基于PLONK+Lookup的一套算法,那么这套算法在目前是否是最适合实现zkEVM的,以及未来Scroll打算换用什么证明系统?
YeZhang:首先我来简单回答下关于PLONK和Lookup的问题,目前这一套还是最适合实现zkEVM或者zkVM的系统,大部分的实现跟具体的PLONK和Lookup是绑定的。一般提到PLONK时,其实更多是用PLONK的arithmetization,也就是电路的算术化表达方式去写zkVM的电路。
Lookup是写电路时用到的一种方式,一种约束类型 。所以当我们提到PLONK + Lookup,指的是在写zkEVM或zkVM电路时,使用PLONK的约束格式,这种方式目前是最常见的。
而在后端方面,PLONK和STARK的界限已经变得模糊,它们只是用了不同的多项式承诺方式,但其实很类似。即使采用STARK + Lookup的组合,跟PLONK + Lookup也是类似的,大家看的只是算法,两者的差别主要体现在Prover的效率、证明大小等方面。当然,就前端而言,Plonk + Lookup来实现zkEVM还是最适合的。
关于第二个问题,就是Scroll未来打算切换到什么证明系统。 因为Scroll的目的是永远让自己的技术和链的框架保持在zk领域里最顶尖的位置,所以我们肯定会用最新的一些技术。我们一直以安全性、稳定性作为最优先的目标,所以 不会过于激进地切换自己的ZK证明系统,可能先通过一些MultiProver做过渡,一步一步的摸索递进,来完成下一版的升级迭代。 Anyway,要保证说这是一个平稳的过渡流程。
但就现在来说,切换到新的证明系统还很早,这其实是下一阶段比如未来6个月到1年的发展方向。
Scroll 的创新
-
Nickqiao: Scroll在当前基于PLONK和Lookup的证明系统上,有没有一些独特的创新?
YeZhang:目前在Scroll主网上运行的是halo2, halo2最早源于Zcash这个项目团队,他们最早做了一个能支持 Lookup,支持灵活地写电路格式的一套后端系统。 然后,我们和以太坊的PSE小组一起改造了halo2,把它采用的多项式承诺方案从IPA换到了KZG,把Proof Size变小了,从而能在以太坊上更高效的验证ZK Proof。
然后我们在GPU硬件加速上做了很多工作,跟用CPU生成ZKP来对比的话,能让ZKP生成速度快5~10倍。总体来说, 我们把原版halo2的多项式承诺方案替换成了更易于被验证的版本,并做了很多关于Prover的优化,在工程化落地上下了不少功夫。
Scroll 与PSE团队的合作
-
Nickqiao:所以Scroll现在是和以太坊PSE团队共同维护KZG版本的halo2。您能否给我们讲一下,你们是怎样和PSE团队合作的?
YeZhang: Scroll在启动项目前,我们本来就认识一些PSE团队的工程师,我们就有和他们聊,说自己想做zkEVM,我们估计了一下这个效率是ok的。刚好在同一个时间节点,他们也想做同样的事,然后大家一拍即合。
所以, 我们是从以太坊社区,从Ethereum Research那边认识了一起想做zkEVM的人,大家都想把zkEVM产品化落地,都有为以太坊服务的想法,所以很自然地开始了开源合作的模式。 这种合作方式更像开源社区,而不是商业化的公司,比如我们每周都会通一次电话,同步一下进度,讨论遇到了哪些问题。
我们以这种方式去开源地维护了这套代码,从改进halo2到实现zkEVM,这中间有很多探索的过程,我们相互会帮忙Review代码。你 从Github的代码贡献量能看出来,PSE他们写了一半,Scroll这边写了一半, 后续我们完成了代码的审计,并实现了一版真正产品化落地并在主网上运行着的代码。 总结下来,我们和以太坊PSE的合作模式,更像是一个开源社区的路径,是自发的形式。
如何保证安全
-
Nickqiao:您刚才提到,要编写zkEVM的电路,对数学和密码学的要求非常高,既然如此,能摸清楚zkEVM的人估计很少。那么Scroll怎么保证电路编写的正确性以及少出bug?
YeZhang: 因为我们是开源的代码,基本上每一个PR都会有我们的人和以太坊的一些人,以及一些社区成员去Review,有比较严格的审计过程。同时 我们在电路审计方面也花了很多钱,超过100万美元,找了这个行业里最专业的密码学和电路审计机构,比如Trail of Bits,Zellic等。我们链上智能合约的部分也找了openzepplin来审计,基本上所有和安全相关的东西都动用了最高档的审计资源。 我们内部还有专门的安全团队去做测试,持续提升Scroll的安全性。
Nickqiao: 除了这种审计方式,有没有形式化验证等在数学上比较严谨的方式?
YeZhang: 我们其实很早就看过就Formal Verification(形式化验证)这个方向,包括以太坊最近也在思考,怎么给zkEVM做形式化验证,这其实是一个很好的方向。但 就目前来说,要给zkEVM做完整的形式化验证还比较早,只能从一些小的模块开始摸索, 因为Formal Verification运行是有成本的,比如你要给一套代码去运行Formal Verification,你要给它先写一个spec,但写spec并不容易,这套东西要完善需要很长时间。
所以我觉得目前还没有到给zkEVM做完整的形式化验证的阶段,但我们会持续的跟以太坊在内的外部合作者去积极探索怎么做zkEVM的形式化证明。
目前来说,最好的方式其实还是人工审计, 因为你就算有了spec,有了Formal Verification,如果spec写错了,那你还是会出问题。所以我觉得,目前最好还是先通过人工审计,然后通过开源和漏洞悬赏的方式,确保目前Scroll代码的稳定性。
但是, 在下一代zkEVM中,关于怎么去做形式化验证,怎么去设计一个更好的zkEVM进而更容易的写出来spec,通过形式化验证的方式去证明它的安全性,是以太坊的终极目标。 就是说,当一个zkEVM被形式化验证以后,他们就可以彻底放心地将其实施到以太坊主网上。

Scroll 未来证明系统的选择
-
Nickqiao:关于Scroll采用的halo2,如果要支持STARK等新的证明系统,开发成本会不会很大。能否实现一种插件化的体系,同时支持多个证明系统?
YeZhang: halo2是一个非常模块化的ZK证明系统,你可以替换它的域、多项式承诺等,只要把它用的多项式承诺从KZG换成FRI,基本就可以实现一个halo2版本的STARK,这个事也确实有人做了,所以 halo2要支持STARK,这种兼容是完全ok的。
然后在实际落地中会发现,如果你要追求极致效率的话,越模块化的框架越可能导致一些效率问题,因为你为了模块化牺牲了定制化的程度,会有付出一些代价。 我们在持续关注一个问题,就是未来的发展方向该是模块化的框架,还是非常定制化的框架, 尤其像我们有足够强的ZK开发团队,可以维护一个独立的证明体系,然后让zkEVM 变得更高效。当然上述问题需要做出一些权衡,但就halo2而言,它可以支持FRI。
-
Nickqiao: 目前Scroll在ZK方面主要的迭代方向是什么?是优化目前的算法、增加一些新的feature之类的?
YeZhang:我们的工程团队核心在做的事情,还是要把目前的Prover性能再提升一倍,然后EVM兼容性也要做到最好。 在下一版升级中,我们会继续保持自己在ZK Rollup里最EVM兼容的这样一个位置, 现在其他所有的zkEVM应该都没有我们的兼容性好。
所以这是Scroll工程团队一方面在做的,就是继续优化Prover和Compatibility,并且要降低费用。 我们现在已经投入了很多人力,去研究下一代zkEVM,大概投入了一半的工程力量, 以实现分钟级甚至秒级的ZK证明生成,让Prover的效率变得高起来。
同时,我们在探索新的zkEVM执行层, 我们的节点之前用的是go-ethereum,但现在有性能更好的Rust版本以太坊客户端Reth。所以我们在研究,怎么把下一代zkEVM跟Reth客户端更好地结合,把整个链的性能给提升上来。我们会考察zkEVM如果围绕着新的执行层,该用什么样的实现方式和过渡形式最好。
-
Nickqiao: 那么像Scroll在考虑支持的多样化证明系统,有没有必要在链上实现多个Verifier合约呢?比如做交叉验证
YeZhang: 我觉得这是两个问题, 首先就是说,有没有必要去做模块化的证明系统和多样化的Prover, 我觉得这么做是有意义的,因为我们从始至终,就是开源项目。你把开源出去的这套框架做的越通用化,会吸引来越多人帮你造轮子,你的社区也会因此壮大,后面在项目开发或者工具使用上,可以自然而然的引用外部力量。所以我觉得, 如果能做一个不光给Scroll自己使用,还能给其他人用的ZK证明框架很有意义。
然后第二个事情,就是在主网上做交叉验证这个事,这其实和证明系统本身是否是多样化的,是否支持STARK或PLONK是正交的话题。一般很少有项目把同样的zkEVM用PLONK验证一遍,再用STARK验证一遍,这是很少的,因为这么做对安全性的提升不大,反而会让Prover付出更高成本,所以一般不会出现这种交叉验证的情况。
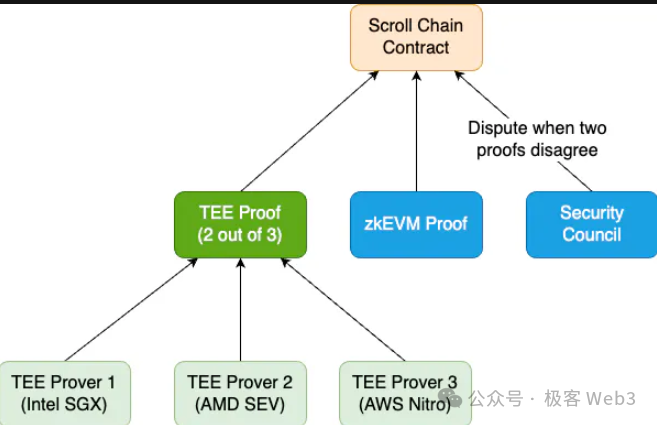
我们其实在做一个东西叫MultiProver,可以有两套Prover一起证明相同的一个Block,但是会在链下把两个Proof聚合到一起再放到链上去验证。 所以,并不会在链上做STARK和SNARK之间的交叉验证。我们的多Prover方案,是为了保证在其中一套Prover的代码出问题时,另一套代码可以兜底,一套系统出了bug另一套能照常运行,所以这和交叉验证是另一个话题。
-
Nickqiao:Scroll的Multi Prover,每个Prover运行的证明程序会有什么不同?
YeZhang: 首先,假设我有一个正常的、用halo2写的一套zkEVM,有一个正常的Prover生成ZKP再去链上做验证,但这里有个问题, zkEVM很复杂,有可能出现bug。 如果出现bug,比如被黑客或者项目方拿去利用这个bug生成一个Proof,最后能把大家的钱提走,这肯定是不好的。
MultiProver的核心思想,其实是Vitalik最初在Bogota活动上第一次提出的。意思是说,如果一个zkEVM可能出现bug,那你可以同时跑不同种类的Prover ,比如说可以用TEE的基于SGX的Prover(Scroll目前用了这套),或是基于OP,或用zkVM运行EVM的方式去跑一个Prover。Anyway,这些Prover要同时去证明一个L2 Block的有效性。
假设有3个不同类型的Prover,当且仅当它们生成的3个不同Proof都通过验证,或者说3个Proof中至少2个通过验证时,你才能在以太坊链上敲定Layer2的最终状态。Multi Prover可以保证在一个Prover出问题时,其他两个Prover 能够顶替,最后整个Prover系统的稳定性会很好,使ZK Rollup的安全性得到提升。当然这也会引入其他缺点,比如Prover的整体运行成本会提高,我们有一篇专门的Blog介绍了这些概念。
-
Nickqiao: 那现在关于Scroll的ZK证明生成这块,其证明生成网络(ZK矿池)是怎么建设的,是自建的,还是会把一些计算外包给如Cysic的第三方?
YeZhang: 就我们目前来说,整个设计其实很容易,我们想让更多的GPU持有者或者矿工参与进我们的这个证明网络(ZK矿池)里, 但目前来说,Scroll的Prover Market还是我们自己运营的,我们会和第三方的一些有GPU集群的人合作,他们去运行Prover,但这是为了主网的稳定性,因为你的Prover一旦去中心化后,会有很多问题。
比如说,你的激励机制设计不好的话,如果没有人给你产生Proof,网络会在性能上受到影响。前期我们选择了相对中心化的方式,但是整个接口和框架的设计,非常容易切换到去中心化的模式。人们完全可以用我们的技术框架做一个去中心化的Prover网络,再加一些激励就行了。
但目前来说,为了Scroll的稳定性,我们的Prover生成网络还是中心化的, 未来我们会更大范围的把Prover网络给去中心化,每个人都可以去运行自己的Prover节点,包括我们也在跟诸如Cysic,Snarkify network等等第三方平台合作, 看一下如果有人想通过我们的技术栈去启动自己的Layer2,可以去接到第三方的Prover Market里去直接调用对方的Prover服务。
-
Nickqiao: Scroll在ZK硬件加速方面有没有什么投入或者产出成果?
YeZhang:这其实就是我之前提到的,Scroll最初做的两大方向,第一个就是把zkEVM从不可能变成可能,第二个就是我们为什么能把它从不可能变成可能,是因为ZK硬件加速的效率提升了。
我其实在做Scroll 之前的3年,就开始做ZK硬件加速方面的工作,我们也有关于ASIC或是GPU硬件加速的论文。我们对zk硬件这块非常了解,无论从芯片还是从GPU,无论是从学术还是从实践上,都有非常强的Credibility。
但是 Scroll自己会专注于GPU方面的硬件加速, 因为我们没有专门做FPGA或是做硬件的资源,也没有流片的专门经验。所以 我们会选择跟Cysic这类硬件公司合作,他们去专门做硬件这块,我们就关注GPU加速这样一个偏软件的领域。 我们自己的团队会GPU硬件加速做优化,然后将成果开源,外部的合作伙伴可以去做专门的如ASIC等芯片,我们也会经常的讨论交流一下彼此遇到的问题。
-
Nickqiao: 您刚才提到,Scroll未来会切换到其他的证明系统。那像一些新的证明系统,比如说Nova或其他的一些算法,您能不能给我们科普一下?他们有什么优点?
YeZhang: 对。我们目前正在内部探索的一种方向,是使用更小的域,能跟我们目前的这些证明系统结合,比如说像PLONKy3这样的一些库,它可以很快的实现小域上的一些运算。这是一个Option,怎么能从我们原来的大域切换到小域,这是一种。
我们内部也在看一些方向,比如一个叫GKR的证明系统,它生成证明的耗时是线性级别的, 在复杂度上面比其他的 Prover要低很多,但目前没有特别成熟的工程落地方式。这块要做的话,要投入更多的人力物力。
但GKR的好处是,在处理重复计算时效率很高,比如说一个签名计算了1000 次,GKR可以很高效的给这样的东西生成证明。 ZK桥Polyhedra就是用GKR去证明签名的,效率很高。 然后,EVM有很多重复的计算步骤,可以通过GKR更好的把生成ZK证明的成本降低下来。
然后还有一些好处,就是说 GKR这套证明系统,它需要的计算量确实要比其他系统小很多 。比如说,你通过像 PLONK或STARK这样的方式,去证明一个keccak哈希函数的计算流程,你需要把中间所有的变量、keccak整个计算过程中产生的所有东西,全部Commit一遍、全部算一遍。
但是GKR的话,你只需要Commit它很短的输入那一层,它可以把中间的这些参数全部通过传递关系给表示出来,不需要你去Commit中间的这些变量,会让计算成本降低很多。GKR背后的这个sum check协议,也被Jolt或者Lookup argument或比较火的一些新框架所采用,所以这个方向是比较有潜力的,我们也在认真研究这个方向。
最后就是你提到的Nova。 感觉Nova在几个月前大火了一阵,因为Nova也比较适合处理这种重复计算 ,比如你本来要证明100个任务,对此的overhead是100。但Nova的做法是,我可以把这100待证明的任务一个叠一个,一个叠一个,每两个随机进行线性组合,最后组合出来一个最终要证明的东西,然后只要证明最终这个任务,就可以证明前面那100个任务都有效,这样的话可以把原本为100的证明overhead大幅压缩。
然后,后续的一些Hyper Nova之类的工作,可以把Nova扩展到除了R1CS以外的一些证明系统,一些其他的写电路的格式,可以支持lookup或是别的东西,这样才能让一个VM更好的被Nova这类ZK证明系统给证明。 但目前来说,Nova和GKR的产品化完善程度不够,目前市面上没有很好的关于Nova的高效的库。
并且因为Nova是这种折叠的方式,它的设计思路和其他的证明系统不太一样。我觉得它还很不成熟,只是一个比较有潜力的备选方案。但目前来看,从Production Ready的角度来说,还是最常见的那几套ZK证明系统更早被投入市场,但长期来看说不好说哪个最好。

YeZhang 对未来的看法
-
Faust:最后想聊一下价值观的问题。记得您去年说去了一趟非洲后,觉得区块链最有可能在非洲这种经济落后的地方被大规模采用,可以谈谈这方面的想法么?
YeZhang:我其实一直有一个非常强的信念,就是区块链在经济落后的国家真的有应用空间。 其实你现在看到,区块链这个行业里各种Scam比较多,让很多人对行业的信心都动摇了,就是为什么要在一个没有实际价值的行业里工作,区块链这个东西到底有没有用。 除了炒币或者说赌博行为外,有没有一些更实际的应用场景?
我觉得去一些经济落后的地方,尤其像非洲,你更能感受到区块链的潜力。 因为在中国或西方国家生活的人,其货币体系、金融体系非常健全,比如中国人民用微信和支付宝就很开心,人民币也相对稳定,你没有必要通过区块链的方式去做支付。
但在像非洲这样的地方,他们是真的对区块链和链上稳定币有需求,因为他们的货币通胀真的非常严重,举个例子, 某些非洲国家的通胀率每半年就能达到20%, 这样的话每次你隔半年买菜,价格就要提升20%,如果是一年就可能提升更多。这样的话它们的货币是一直在严重贬值的,资产也在贬值,所以很多人都希望拿美元拿稳定币或是拿其他发达国家的稳定的货币。
但 非洲人很难去申请发达国家的银行账户,稳定币对于他们来说是一种刚需, 就哪怕没有区块链,他们也想拿着美元这类东西。显然,对于非洲人来说,持有美元最好的方式就是拿稳定币,他们每次一发工资,就可以去币安把这个钱赶紧换成USDT、USDC,需要用钱的时候再把它取出来,这样的话会导致他们有对区块链的真实需求和实际应用。
其实你去了非洲后,会明显感到像币安很早就在非洲布局了,做的非常的扎实,在那里 很多非洲人真的对稳定币有依赖,就是大家宁可信任交易所,都不一定信任自己本国的货币体系, 因为很多非洲人在本地可能都申请不了贷款。假设你要借100块钱,银行会开出各种手续和条件,最后你可能搞不到贷款,但在交易所或者其他的一些链上平台,对此要灵活的多,所以我觉得在非洲,人们对区块链有更多更实际的应用和需求。
当然,我说的这些大多数人并不太了解,因为大多数用Twitter的人不关心这个,或者也不会在Twitter上看得到这些。像非洲这样比较落后的地区有很多,包括在币安的用户量比较多的一些国家,如土耳其、一些东南亚国家、阿根廷,你会发现这些地区的人用交易所的次数非常多。所以我觉得,在这些地方,币安的案例已经证明了人们对区块链有非常强的需求。
所以 我觉得这些地区的市场和社区是真的很有必要去做的, 包括我们也有专门在土耳其的团队,我们在土耳其有一个非常大的社区,然后我们要去慢慢的在前面提到的非洲、东南亚、阿根廷等国家去过渡。而且我觉得,在所有的 Layer2里面,Scroll最有可能成功的在上述国家扎根,因为 我们的团队文化就相当多元, 虽然三个创始人是华人,但我们整个team大概包含至少二三十个国家的人,虽然我们总共也就七八十人,每个地区基本上都有至少两三个人,所以整体文化很多元。相比之下,你可以想到的其他Layer2,基本都是西方人为主,像OP、Base和Arbitrum就是完全西方化的。
综上, 我们希望能在非洲这种经济落后、对区块链有实际刚需的地方,给这些地方的人做一套真的有实际应用场景的基础设施,有点像“农村包围城市”的感觉,去慢慢地把Mass Adoption给做起来。 所以我觉得,我在非洲之行中的感触还是很深的,但目前来说,Scroll对于一些人而言使用成本还是有些贵,所以我还是挺希望能进一步地把成本降低,比如说十倍或者更多,然后通过一些其他的方式,把用户带到区块链里来。
其实还有一个前面没提到的、可能有些不恰当的例子,就是波场Tron。大家对它可能有一些不好的印象,但确实很多经济落后的国家的人都在用它,因为HTX之前的交易所策略和很多其他的营销策略,慢慢的让波场真的有自己的网络效应。我觉得, 如果以太坊生态里面能有一条链,能把这些用户带到以太坊生态里, 就是一个非常大的成就,而且也是在给这个行业做一些非常正面的事情, 我觉得这是很有意义的。
现在很多以太坊二层在卷TVL数据,卷来卷去,你是6亿美金,我们可能7亿美金,它是10亿美金,但我觉得相比于这些东西,更震撼的消息是,泰达突然说我在这个二层或者哪条链上又增发了10亿枚USDT,或者说发行了多少多少钱的稳定币。 一条链如果自然增长到了这样一个程度,不需要通过空投预期来捕获用户需求,那个时候才算是比较成功的状态,至少是我比较满意的一个状态, 就是能让用户的真实需求大到一定程度,使得越来越多的人真的在日常使用你这条链。
最后我其实想插个题外话, 接下来Scroll生态会有很多活动,希望大家多关注一下我们的后续进展, 多参与一下我们的defi生态。





