密码学基础二 单项函数算法深入(Hash)
单向函数算法深入单向散列函数,又称单向Hash函数,就是把任意长度的输入消息串变化成固定长的输出串且由输出串难以得到输入串的一种函数。这个输出串称为该消息的散列值。MD5MD5简介是RSA数据安全公司开发的一种单向散列算法,MD5被广泛使用,可以用来把不同长度的数据块进行暗码运算成一个1
单向函数算法深入
单向散列函数,又称单向Hash函数,就是把任意长度的输入消息串变化成固定长的输出串且由输出串难以得到输入串的一种函数。这个输出串称为该消息的散列值。
MD5
MD5 简介
是RSA数据安全公司开发的一种单向散列算法,MD5 被广泛使用,可以用来把不同长度的数据块进行暗码运算成一个128 位的数值。 MD5 在一致性Hash验证,数字证书,安全访问方面具有突出的作用 但是值得注意的是,目前的MD5已被破解,不再具有安全性
MD5 算法流程
第一步 初始化4个缓冲区 第二步 计算并初始化 MD5 算法中的预定义常数数组 T,这个预定义的常数数组,主要是为了增加复杂性和混淆性。 第三步 消息填充,确保待处理的消息长度满足512位的倍数,使得其方便分块 第四步 处理消息块 1.将 512 位(64 字节)消息分成 16 个 32 位整数 2.主循环 64 次迭代,在每次迭代中,根据不同的逻辑对a,b,c,d 进行辅助处理 3. 在每一轮中,a, b, c, d 的值通过位操作(例如左循环移位 rotateLeft)来更新,这些处理使得数据变化非常复杂
b = b + Integer.rotateLeft(a + f + K[j] + X[g], s[j]);
a 是前一次计算的结果
f 是计算出的函数值
K[j] 是 MD5 的常数表中的第 j 个常数
X[g] 是消息块的第 g 个 32 位整数
第五步 更新缓冲区(将 a, b, c, d 加到 A, B, C, D 中) 第六步 输出最终的结果值
MD5 代码实现
// 测试 MD5 函数
public static void main(String[] args) {
String s = md5("hello world".getBytes());
System.out.println(s); // 测试输出
}
// 主 MD5 函数
public static String md5(byte[] message) {
// 初始化四个缓冲区
int A = 0x67452301;
int B = 0xefcdab89;
int C = 0x98badcfe;
int D = 0x10325476;
// 预定义的常数
int[] T = new int[64];
for (int i = 0; i < 64; i++) {
T[i] = (int) (4294967296L * Math.abs(Math.sin(i + 1)));
}
// 消息填充
int originalByteLen = message.length;
int originalBitLen = originalByteLen * 8;
// 添加 1 bit (0x80) 和 padding 0 bits
message = Arrays.copyOf(message, ((originalByteLen + 8) / 64 + 1) * 64);
message[originalByteLen] = (byte) 0x80;
// 添加原始长度(小端序)
ByteBuffer lengthBuffer = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN).putLong(originalBitLen);
System.arraycopy(lengthBuffer.array(), 0, message, message.length - 8, 8);
// 处理消息块
for (int i = 0; i < message.length; i += 64) {
int a = A, b = B, c = C, d = D;
int[] X = new int[16];
ByteBuffer block = ByteBuffer.wrap(message, i, 64).order(ByteOrder.LITTLE_ENDIAN);
for (int j = 0; j < 16; j++) {
X[j] = block.getInt();
}
// 主循环
for (int j = 0; j < 64; j++) {
int f, g;
if (j <= 15) {
f = F(b, c, d);
g = j;
} else if (j <= 31) {
f = G(b, c, d);
g = (5 * j + 1) % 16;
} else if (j <= 47) {
f = H(b, c, d);
g = (3 * j + 5) % 16;
} else {
f = I(b, c, d);
g = (7 * j) % 16;
}
int temp = d;
d = c;
c = b;
b = b + leftRotate(a + f + T[j] + X[g], new int[]{7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21}[j]);
a = temp;
}
// 将结果加到当前的哈希值
A = (A + a) & 0xFFFFFFFF;
B = (B + b) & 0xFFFFFFFF;
C = (C + c) & 0xFFFFFFFF;
D = (D + d) & 0xFFFFFFFF;
}
// 输出最终哈希值
return String.format("%08x%08x%08x%08x", A, B, C, D);
}
// 左移位函数
private static int leftRotate(int x, int n) {
return (x << n) | (x >>> (32 - n));
}
// 辅助函数
private static int F(int x, int y, int z) { return (x & y) | (~x & z); }
private static int G(int x, int y, int z) { return (x & z) | (y & ~z); }
private static int H(int x, int y, int z) { return x ^ y ^ z; }
private static int I(int x, int y, int z) { return y ^ (x | ~z); }
SHA 算法
安全散列算法(英语:Secure Hash Algorithm,缩写为SHA)是一个密码散列函数家族,能计算出一个数字消息所对应到的,长度固定的字符串(又称消息摘要)的算法。 SHA 家族有SHA-0;SHA-1;SHA-224、SHA-256、SHA-384,SHA-512和SHA3。SHA-224、SHA-256、SHA-384,SHA-512 有时并称为 SHA-2 其中SHA-0 和 SHA-1可将一个最大 264 比特的消息,转换成一串 160 位的消息摘要;其设计原理相似于 MIT 教授 Ronald L. Rivest 所设计的密码学散列算法 MD4和 MD5 值得注意的是,SHA-0; SHA-1 算法已被破解,不再安全
SHA-1算法流程
第一步 初始化缓冲区 第二步 消息填充 第三步 处理消息块 1.将每个 512 位的消息块分成 16 个 32 位整数 2.扩展消息 3.初始化变量 4. 主循环80次,依次对初始化变量A,B,C,D,E 按照不同的逻辑进行处理 第四步 更新缓冲区 第五步 输出结果
从流程上来看,SHA-1 算法和MD算法的处理逻辑比较雷同
SHA-1算法具体实现
// 测试 SHA-1 函数
public static void main(String[] args) {
System.out.println(sha1("hello world"));
}
public static String sha1(String message) {
// 初始化缓冲区
int H0 = 0x67452301;
int H1 = 0xEFCDAB89;
int H2 = 0x98BADCFE;
int H3 = 0x10325476;
int H4 = 0xC3D2E1F0;
// 消息填充
byte[] messageBytes = message.getBytes(StandardCharsets.UTF_8);
int originalByteLen = messageBytes.length;
long originalBitLen = (long) originalByteLen * 8;
// 添加 0x80 的字节
messageBytes = Arrays.copyOf(messageBytes, (originalByteLen + 9 + 63) / 64 * 64);
messageBytes[originalByteLen] = (byte) 0x80;
// 添加 64 位的消息长度
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.putLong(originalBitLen);
byte[] lenBytes = buffer.array();
System.arraycopy(lenBytes, 0, messageBytes, messageBytes.length - 8, 8);
// 处理消息块
for (int i = 0; i < messageBytes.length; i += 64) {
int[] W = new int[80];
// 将每个 512 位的消息块分成 16 个 32 位整数
for (int j = 0; j < 16; j++) {
W[j] = ((messageBytes[i + j * 4] & 0xFF) << 24) |
((messageBytes[i + j * 4 + 1] & 0xFF) << 16) |
((messageBytes[i + j * 4 + 2] & 0xFF) << 8) |
(messageBytes[i + j * 4 + 3] & 0xFF);
}
// 扩展消息
for (int t = 16; t < 80; t++) {
W[t] = Integer.rotateLeft(W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16], 1);
}
// 初始化变量
int A = H0;
int B = H1;
int C = H2;
int D = H3;
int E = H4;
// 主循环
for (int t = 0; t < 80; t++) {
int K, f;
if (t <= 19) {
K = 0x5A827999;
f = (B & C) | ((~B) & D);
} else if (t <= 39) {
K = 0x6ED9EBA1;
f = B ^ C ^ D;
} else if (t <= 59) {
K = 0x8F1BBCDC;
f = (B & C) | (B & D) | (C & D);
} else {
K = 0xCA62C1D6;
f = B ^ C ^ D;
}
int temp = Integer.rotateLeft(A, 5) + f + E + K + W[t];
E = D;
D = C;
C = Integer.rotateLeft(B, 30);
B = A;
A = temp;
}
// 更新缓冲区
H0 = (H0 + A) & 0xFFFFFFFF;
H1 = (H1 + B) & 0xFFFFFFFF;
H2 = (H2 + C) & 0xFFFFFFFF;
H3 = (H3 + D) & 0xFFFFFFFF;
H4 = (H4 + E) & 0xFFFFFFFF;
}
// 输出最终哈希值
return String.format("%08x%08x%08x%08x%08x", H0, H1, H2, H3, H4);
}
SHA-2 算法
SHA-256和SHA-512是很新的杂凑函数,前者以定义一个word为32位元,后者则定义一个word为64位元。它们分别使用了不同的偏移量,或用不同的常数,然而,实际上二者结构是相同的,只在循环执行的次数上有所差异。SHA-224以及SHA-384则是前述二种杂凑函数的截短版,利用不同的初始值做计算。这些新的杂凑函数并没有接受像SHA-1一样的公众密码社群做详细的检验,所以它们的密码安全性还不被大家广泛的信任。 SHA-256 和 SHA-224: 其中SHA-224是SHA-256 的截短版,运算的数据都是32位(4字节),核心循环次数为64次。 SHA-512 和 SHA-384:其中SHA-384是SHA-512 的截短版,运算的数据都是64位(8字节),核心循环次数为80次。
SHA-2 算法的核心流程
第一步 初始化常量:SHA-256 使用的初始哈希值和常数 K。 第二步 消息填充:填充原始消息,使其长度是 512 位(64 字节)的倍数。添加 0x80,后面跟着 0,最后添加 64 位的原始消息长度。 第三步 消息块处理:每个消息块处理成 16 个 32 位整数,然后扩展成 64 个 32 位整数。 第四步 主循环:执行 64 轮压缩函数,每轮更新工作变量。 第五步 最终哈希值输出:将每个工作变量合并成一个 256 位(8 x 32 位)的输出哈希值。
SHA-2 算法具体实现(SHA-256)
// 测试函数
public static void main(String[] args) {
String message = "hello world";
System.out.println(sha256(message)); // 输出 SHA-256 哈希值
}
// 初始化哈希值,SHA-256 的初始常数
private static final int[] H = {
0x6a09e667, 0xbb67ae85, 0x3c6ef372, 0xa54ff53a,
0x510e527f, 0x9b05688c, 0x1f83d9ab, 0x5be0cd19
};
// SHA-256 的常量 K
private static final int[] K = {
0x428a2f98, 0x71374491, 0xb5c0fbcf, 0xe9b5dba5, 0x3956c25b, 0x59f111f1, 0x923f82a4, 0xab1c5ed5,
0xd807aa98, 0x12835b01, 0x243185be, 0x550c7dc3, 0x72be5d74, 0x80deb1fe, 0x9bdc06a7, 0xc19bf174,
0xe49b69c1, 0xefbe4786, 0x0fc19dc6, 0x240ca1cc, 0x2de92c6f, 0x4a7484aa, 0x5cb0a9dc, 0x76f988da,
0x983e5152, 0xa831c66d, 0xb00327c8, 0xbf597fc7, 0xc6e00bf3, 0xd5a79147, 0x06ca6351, 0x14292967,
0x27b70a85, 0x2e1b2138, 0x4d2c6dfc, 0x53380d13, 0x650a7354, 0x766a0abb, 0x81c2c92e, 0x92722c85,
0xa2bfe8a1, 0xa81a664b, 0xc24b8b70, 0xc76c51a3, 0xd192e819, 0xd6990624, 0xf40e3585, 0x106aa070,
0x19a4c116, 0x1e376c08, 0x2748774c, 0x34b0bcb5, 0x391c0cb3, 0x4ed8aa4a, 0x5b9cca4f, 0x682e6ff3,
0x748f82ee, 0x78a5636f, 0x84c87814, 0x8cc70208, 0x90befffa, 0xa4506ceb, 0xbef9a3f7, 0xc67178f2
};
public static String sha256(String message) {
byte[] messageBytes = message.getBytes();
int originalByteLen = messageBytes.length;
long originalBitLen = (long) originalByteLen * 8;
// 消息填充
messageBytes = Arrays.copyOf(messageBytes, ((originalByteLen + 9 + 63) / 64) * 64);
messageBytes[originalByteLen] = (byte) 0x80;
// 添加 64 位消息长度
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.putLong(originalBitLen);
byte[] lenBytes = buffer.array();
System.arraycopy(lenBytes, 0, messageBytes, messageBytes.length - 8, 8);
// 初始化工作变量
int[] H = Arrays.copyOf(SHA256.H, SHA256.H.length);
// 处理消息块
for (int i = 0; i < messageBytes.length; i += 64) {
int[] W = new int[64];
// 将每个 512 位的消息块分成 16 个 32 位整数
for (int j = 0; j < 16; j++) {
W[j] = ((messageBytes[i + j * 4] & 0xFF) << 24) |
((messageBytes[i + j * 4 + 1] & 0xFF) << 16) |
((messageBytes[i + j * 4 + 2] & 0xFF) << 8) |
(messageBytes[i + j * 4 + 3] & 0xFF);
}
// 扩展消息
for (int t = 16; t < 64; t++) {
W[t] = sigma1(W[t - 2]) + W[t - 7] + sigma0(W[t - 15]) + W[t - 16];
}
// 初始化工作变量
int a = H[0];
int b = H[1];
int c = H[2];
int d = H[3];
int e = H[4];
int f = H[5];
int g = H[6];
int h = H[7];
// 主循环
for (int t = 0; t < 64; t++) {
int temp1 = h + Sigma1(e) + Ch(e, f, g) + K[t] + W[t];
int temp2 = Sigma0(a) + Maj(a, b, c);
h = g;
g = f;
f = e;
e = d + temp1;
d = c;
c = b;
b = a;
a = temp1 + temp2;
}
// 更新哈希值
H[0] = (H[0] + a);
H[1] = (H[1] + b);
H[2] = (H[2] + c);
H[3] = (H[3] + d);
H[4] = (H[4] + e);
H[5] = (H[5] + f);
H[6] = (H[6] + g);
H[7] = (H[7] + h);
}
// 输出最终哈希值
StringBuilder hash = new StringBuilder();
for (int h : H) {
hash.append(String.format("%08x", h));
}
return hash.toString();
}
// 辅助函数
private static int rotateRight(int x, int n) {
return (x >>> n) | (x << (32 - n));
}
private static int sigma0(int x) {
return rotateRight(x, 7) ^ rotateRight(x, 18) ^ (x >>> 3);
}
private static int sigma1(int x) {
return rotateRight(x, 17) ^ rotateRight(x, 19) ^ (x >>> 10);
}
private static int Sigma0(int x) {
return rotateRight(x, 2) ^ rotateRight(x, 13) ^ rotateRight(x, 22);
}
private static int Sigma1(int x) {
return rotateRight(x, 6) ^ rotateRight(x, 11) ^ rotateRight(x, 25);
}
private static int Ch(int x, int y, int z) {
return (x & y) ^ (~x & z);
}
private static int Maj(int x, int y, int z) {
return (x & y) ^ (x & z) ^ (y & z);
}
SHA3 算法
SHA-3基于Keccak算法,而Keccak又使用了一种海绵结构的算法 海绵结构:海绵结构能够进行数据转换,将任意长的输入转换成任意长的输出。
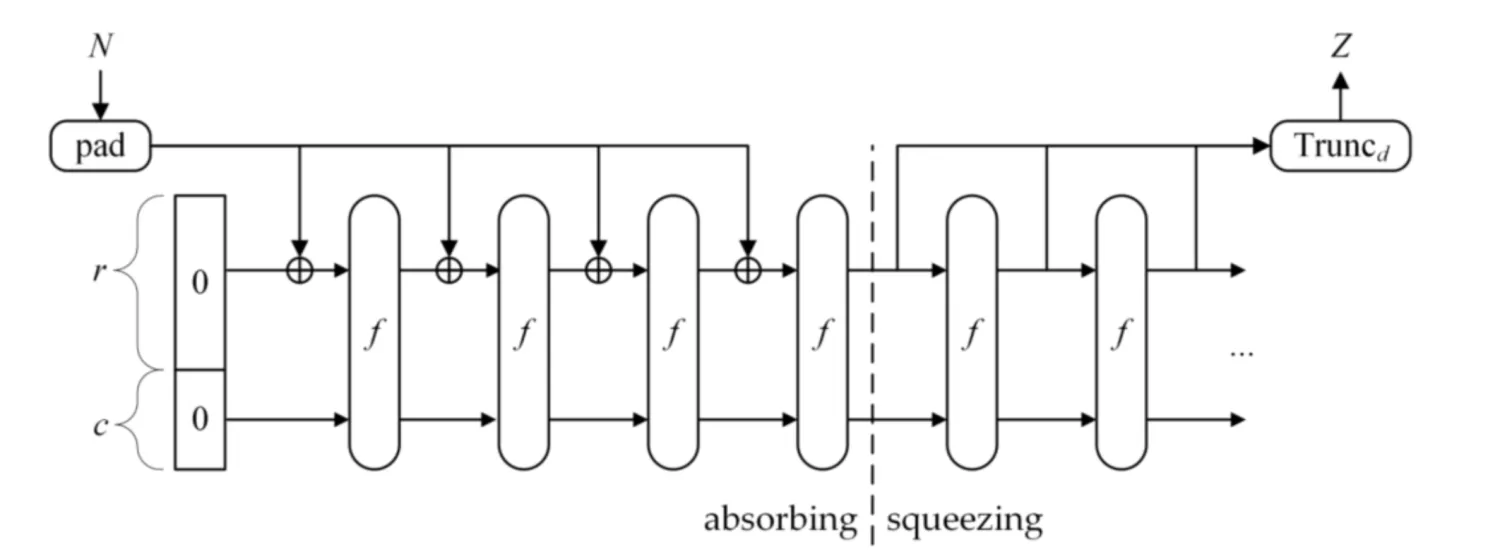 一个对数据进行等长映射的函数 f,即输出串长度与输入串长度相同,记为 b。
一个参数称为比率 ( rate ),记作 r,是指每轮要吸收的 长度为 b 的串中数据的长度,剩余部分称为容量,记为 c,因此,有 b = r + c。
一个填充 ( padding ) 函数,记作 pad(x, m),返回将长度为 m 的串填充为 x 的整数倍长度的串
一个对数据进行等长映射的函数 f,即输出串长度与输入串长度相同,记为 b。
一个参数称为比率 ( rate ),记作 r,是指每轮要吸收的 长度为 b 的串中数据的长度,剩余部分称为容量,记为 c,因此,有 b = r + c。
一个填充 ( padding ) 函数,记作 pad(x, m),返回将长度为 m 的串填充为 x 的整数倍长度的串
SHA3 的特点
安全性:SHA-3提供与SHA-2类似的安全级别,但由于其不同的结构,提供了一种额外的安全性保障。
可变输出长度:SHA-3允许生成可变长度的哈希值,虽然常见的长度是224, 256, 384和512位。
抗攻击性:基于海绵结构,SHA-3具有很高的抗预映射攻击(preimage attack)、第二预映射攻击(second preimage attack)和碰撞攻击(collision attack)能力。
灵活性:SHA-3不仅可以用作哈希函数,还可以应用于消息认证码(MAC)、伪随机数生成器(PRNG)等领域。
Keccak 的基本流程
第一步 Keccak 变量定义: BIT_RATE: Keccak-256 的位率。 CAPACITY: Keccak-256 的容量。 STATE_SIZE: 整个状态的大小是 1600 位。 第二步 Keccak 算法的内部状态被初始化为 25 个 64 位长整型值。 第三步 消息被填充,并且分块处理。每次处理 1088 位的数据,直到消息被完全吸收。 第四步 调用Keccak函数,进行 24 轮的压缩函数,包含theta(),rho(),pi(),chi(),iota() 第五步 在吸收消息后,调用 squeeze 提取输出,生成最终的哈希值。
Keccak 算法轻量实现
private static final int BIT_RATE = 1088; // Keccak-256 位率
private static final int CAPACITY = 512; // Keccak-256 容量
private static final int OUTPUT_LENGTH = 256; // 输出长度
private static final int STATE_SIZE = 1600; // Keccak 状态大小
private static final int WORD_SIZE = 64; // 字大小
private static long[] state = new long[25]; // Keccak 状态
public static void main(String[] args) {
byte[] message = "hello world".getBytes();
byte[] hash = hash(message);
// 输出哈希值
StringBuilder sb = new StringBuilder();
for (byte b : hash) {
sb.append(String.format("%02x", b));
}
System.out.println("Keccak-256 Hash: " + sb.toString());
}
private static void absorb(byte[] message) {
int rateInBytes = BIT_RATE / 8;
int blockSize = 0;
int inputOffset = 0;
while (inputOffset < message.length) {
blockSize = Math.min(rateInBytes, message.length - inputOffset);
// XOR 输入到状态
for (int i = 0; i < blockSize; i++) {
int byteIndex = i % 8;
state[i / 8] ^= ((long) message[inputOffset + i] & 0xFFL) << (byteIndex * 8);
}
inputOffset += blockSize;
// 当数据填充满 block 时,进行压缩
if (blockSize == rateInBytes) {
keccakF();
blockSize = 0;
}
}
// 在最后附加定界符
state[blockSize / 8] ^= (1L << (blockSize % 8 * 8));
state[(rateInBytes - 1) / 8] ^= 0x8000000000000000L; // 设置最后一位为1
keccakF();
}
private static void keccakF() {
// Keccak-F 压缩函数核心
for (int round = 0; round < 24; round++) {
theta();
rho();
pi();
chi();
iota(round);
}
}
private static void theta() {
long[] C = new long[5];
long[] D = new long[5];
for (int i = 0; i < 5; i++) {
C[i] = state[i] ^ state[i + 5] ^ state[i + 10] ^ state[i + 15] ^ state[i + 20];
}
for (int i = 0; i < 5; i++) {
D[i] = C[(i + 4) % 5] ^ Long.rotateLeft(C[(i + 1) % 5], 1);
}
for (int i = 0; i < 25; i += 5) {
for (int j = 0; j < 5; j++) {
state[i + j] ^= D[j];
}
}
}
private static void rho() {
int[] R = {
0, 36, 3, 41, 18,
1, 44, 10, 45, 2,
62, 6, 43, 15, 61,
28, 55, 25, 21, 56,
27, 20, 39, 8, 14
};
for (int i = 0; i < 25; i++) {
state[i] = Long.rotateLeft(state[i], R[i]);
}
}
private static void pi() {
long[] temp = new long[25];
System.arraycopy(state, 0, temp, 0, state.length);
int[] P = {
0, 6, 12, 18, 24,
3, 9, 10, 16, 22,
1, 7, 13, 19, 20,
4, 5, 11, 17, 23,
2, 8, 14, 15, 21
};
for (int i = 0; i < 25; i++) {
state[i] = temp[P[i]];
}
}
private static void chi() {
long[] temp = new long[25];
System.arraycopy(state, 0, temp, 0, state.length);
for (int i = 0; i < 25; i += 5) {
for (int j = 0; j < 5; j++) {
state[i + j] = temp[i + j] ^ (~temp[i + (j + 1) % 5] & temp[i + (j + 2) % 5]);
}
}
}
private static void iota(int round) {
long[] RC = {
0x0000000000000001L, 0x0000000000008082L, 0x800000000000808AL, 0x8000000080008000L,
0x000000000000808BL, 0x0000000080000001L, 0x8000000080008081L, 0x8000000000008009L,
0x000000000000008AL, 0x0000000000000088L, 0x0000000080008009L, 0x000000008000000AL,
0x000000008000808BL, 0x800000000000008BL, 0x8000000000008089L, 0x8000000000008003L,
0x8000000000008002L, 0x8000000000000080L, 0x000000000000800AL, 0x800000008000000AL,
0x8000000080008081L, 0x8000000000008080L, 0x0000000080000001L, 0x8000000080008008L
};
state[0] ^= RC[round];
}
private static byte[] squeeze(int outputLength) {
int rateInBytes = BIT_RATE / 8;
byte[] hash = new byte[outputLength / 8];
int hashOffset = 0;
while (hashOffset < hash.length) {
int blockSize = Math.min(rateInBytes, hash.length - hashOffset);
for (int i = 0; i < blockSize; i++) {
hash[hashOffset + i] = (byte) ((state[i / 8] >> (i % 8 * 8)) & 0xFF);
}
hashOffset += blockSize;
if (hashOffset < hash.length) {
keccakF();
}
}
return hash;
}
public static byte[] hash(byte[] message) {
absorb(message);
return squeeze(OUTPUT_LENGTH);
}
Blake 和 Blake2 算法
BLAKE(及其后续版本 BLAKE2)是一种快速且安全的哈希算法,参与了SHA-3竞赛并成为了SHA-3的五个决赛选手之一 BLAKE2 是一种快速、安全的哈希函数,是对 BLAKE 算法的改进。BLAKE2 于 2012 年发布,其设计目标是提供比 MD5、SHA-1 和 SHA-2 更高的安全性和更快的速度,同时保持高度的灵活性和简便性 Blake2 算法有两个主要版本 BLAKE2b(BLAKE2)和 BLAKE2s
Blake2 算法的特点
高效率:比 SHA-2(如 SHA-256 和 SHA-512)更快,同时在现代 CPU 上的性能通常优于 MD5 和 SHA-1 高安全性:比肩SHA-3的安全性 可变长度输出:哈希值从 1 比特到 512 比特自定 简单易用:BLAKE2 的设计和实现都相对简单 BLAKE2 包含多种额外功能:盐值,个性化,秘钥哈希
Blake2 的大致方法
第一 构造器 初始化哈希状态。 第二 核心混合函数(G函数),对消息块和状态进行操作。 第三 compress函数 对消息块进行压缩,更新哈希状态 第四 update函数 处理输入数据并调用 compress 压缩每个消息块 第五 digest函数 最终的哈希计算,处理任何剩余的数据并返回哈希值
Blake2 源码轻量实现
private static final int OUTLEN = 64; // 输出哈希的字节长度 (256 位)
private static final long[] IV = { // BLAKE2b 初始向量
0x6A09E667F3BCC908L, 0xBB67AE8584CAA73BL, 0x3C6EF372FE94F82BL, 0xA54FF53A5F1D36F1L,
0x510E527FADE682D1L, 0x9B05688C2B3E6C1FL, 0x1F83D9ABFB41BD6BL, 0x5BE0CD19137E2179L
};
private static final byte[] SIGMA = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
14, 10, 4, 8, 9, 15, 13, 6, 1, 12, 0, 2, 11, 7, 5, 3,
11, 8, 12, 0, 5, 2, 15, 13, 10, 14, 3, 6, 7, 1, 9, 4,
7, 9, 3, 1, 13, 12, 11, 14, 2, 6, 5, 10, 4, 0, 15, 8,
9, 0, 5, 7, 2, 4, 10, 15, 14, 1, 11, 12, 6, 8, 3, 13,
2, 12, 6, 10, 0, 11, 8, 3, 4, 13, 7, 5, 15, 14, 1, 9,
12, 5, 1, 15, 14, 13, 4, 10, 0, 7, 6, 3, 9, 2, 8, 11,
13, 11, 7, 14, 12, 1, 3, 9, 5, 0, 15, 4, 8, 6, 2, 10,
6, 15, 14, 9, 11, 3, 0, 8, 12, 2, 13, 7, 1, 4, 10, 5,
10, 2, 8, 4, 7, 6, 1, 5, 15, 11, 9, 14, 3, 12, 13, 0,
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,
14, 10, 4, 8, 9, 15, 13, 6, 1, 12, 0, 2, 11, 7, 5, 3
};
private long[] h = new long[8]; // 哈希状态
private long[] m = new long[16]; // 消息块
private long t0, t1; // 计数器
private boolean finished = false;
public Blake2b() {
// 初始化状态 h with IV 和参数
System.arraycopy(IV, 0, h, 0, IV.length);
h[0] ^= 0x01010000 | OUTLEN;
}
// 作用:BLAKE2b 的核心混合函数,用来操作和混合状态数组 v
private void G(int a, int b, int c, int d, int x, int y, long[] v) {
v[a] = v[a] + v[b] + m[x];
v[d] = Long.rotateRight(v[d] ^ v[a], 32);
v[c] = v[c] + v[d];
v[b] = Long.rotateRight(v[b] ^ v[c], 24);
v[a] = v[a] + v[b] + m[y];
v[d] = Long.rotateRight(v[d] ^ v[a], 16);
v[c] = v[c] + v[d];
v[b] = Long.rotateRight(v[b] ^ v[c], 63);
}
// 压缩函数,处理一个消息块。
private void compress(byte[] block) {
ByteBuffer buffer = ByteBuffer.wrap(block).order(ByteOrder.LITTLE_ENDIAN);
//首先,将输入的消息块转化为 16 个 64 位的 long 值,并存储在数组 m 中。
for (int i = 0; i < 16; i++) {
m[i] = buffer.getLong();
}
long[] v = Arrays.copyOf(h, 16);
//创建一个 v 数组(长度为 16),它由当前的哈希状态 h 和初始向量 IV 组成
System.arraycopy(IV, 0, v, 8, IV.length);
// 根据计数器 t0 和 t1,对数组 v 进行异或操作
v[12] ^= t0;
v[13] ^= t1;
// 12 轮 G 函数混合
for (int i = 0; i < 12; i++) {
G(0, 4, 8, 12, SIGMA[16 * i + 0], SIGMA[16 * i + 1], v);
G(1, 5, 9, 13, SIGMA[16 * i + 2], SIGMA[16 * i + 3], v);
G(2, 6, 10, 14, SIGMA[16 * i + 4], SIGMA[16 * i + 5], v);
G(3, 7, 11, 15, SIGMA[16 * i + 6], SIGMA[16 * i + 7], v);
G(0, 5, 10, 15, SIGMA[16 * i + 8], SIGMA[16 * i + 9], v);
G(1, 6, 11, 12, SIGMA[16 * i + 10], SIGMA[16 * i + 11], v);
G(2, 7, 8, 13, SIGMA[16 * i + 12], SIGMA[16 * i + 13], v);
G(3, 4, 9, 14, SIGMA[16 * i + 14], SIGMA[16 * i + 15], v);
}
// 更新哈希状态 h
for (int i = 0; i < 8; i++) {
h[i] ^= v[i] ^ v[i + 8];
}
}
// 处理输入数据并调用 compress 进行数据块压缩
private void update(byte[] input) {
if (finished) {
throw new IllegalStateException("BLAKE2b instance is already finished.");
}
int blockSize = 128;
int fullBlocks = input.length / blockSize;
for (int i = 0; i < fullBlocks; i++) {
byte[] block = Arrays.copyOfRange(input, i * blockSize, (i + 1) * blockSize);
t0 += blockSize;
if (t0 == 0) {
t1++;
}
compress(block);
}
}
// 最终的哈希计算,处理任何剩余的数据并返回哈希值。
public byte[] digest() {
if (!finished) {
finished = true;
byte[] block = new byte[128];
t0 += block.length;
if (t0 == 0) {
t1++;
}
compress(block);
}
ByteBuffer buffer = ByteBuffer.allocate(OUTLEN).order(ByteOrder.LITTLE_ENDIAN);
for (long hPart : h) {
buffer.putLong(hPart);
}
return Arrays.copyOfRange(buffer.array(), 0, OUTLEN);
}
public static void main(String[] args) {
Blake2b blake2b = new Blake2b();
blake2b.update("The quick brown fox jumps over the lazy dog".getBytes());
byte[] hash = blake2b.digest();
for (byte b : hash) {
System.out.printf("%02x", b);
}
}
总结
从源码角度来看,SHA-0 和 SHA-1 的消息调度方式比较简单。它们只将消息分块后的前 16 个 32 位字扩展为 80 个 32 位字。这种扩展方式导致了安全性的不足。
SHA-256 使用了更复杂的消息调度算法。它不仅扩展消息为 64 个 32 位字,而且还引入了新的位旋转和移位操作。特别是使用了 sigma0 和 sigma1 两个函数进行消息扩展,极大提高了扩展消息的随机性和混淆性,从而增强了抗碰撞能力。并且256引入了额外的逻辑函数,如 Sigma0 和 Sigma1,这些函数通过旋转和移位操作增强了混淆的效果。这些操作更复杂,使得算法更难被逆向推导,从而提高了抗碰撞攻击的能力。
SHA-0 和 SHA-1 的输出是 160 位的哈希值,而 SHA-256 输出的是 256 位的哈希值。这一改进使得 SHA-256 能够提供更强的抗碰撞性和抗攻击性,特别是在现代计算能力迅速提升的背景下。
BLAKE2 的设计目标之一是比 SHA-2 更快的计算速度,特别是在 软件实现 上。它被认为是现今最快的加密哈希函数之一,特别是在处理大块数据和多核系统上。
SHA-3 的海绵结构使得它的性能在某些平台上(尤其是硬件中)与 SHA-2 相当,甚至更快。但在软件实现中,SHA-3 的速度通常比 BLAKE2 和 SHA-2 慢。
SHA-3 的设计更多注重于安全性和对抗潜在的未来攻击,而非极端的速度优化
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
