Conflux的自我进化:从DAG到树图
- 李画
- 发布于 2019-04-12 10:46
- 阅读 17915
这是一篇技术性非常强的采访,Conflux的首席技术官伍鸣博士帮我们解答了疑问:「DAG」与「链」的本质区别是什么?我们为什么要用它?它自身的局限性又在哪里?
这是一篇技术性非常强的采访,Conflux的首席技术官伍鸣博士帮我们解答了疑问:「DAG」与「链」的本质区别是什么?我们为什么要用它?它自身的局限性又在哪里?
Conflux的身份不再是DAG,它是树图
采访时伍鸣却告诉我们,Conflux已不再把自己归类为DAG,它的新身份是树图(Tree-Graph)。
不过我们的疑问依然被解答了,因为最有趣的地方就在于,Conflux从DAG类别变更为树图类别的原因,恰恰能回答采访前我们想要弄明白的那三个问题。甚至因为引入了树图概念,我们能从一个更高的角度来理解这些问题。
区块链账本的结构反映的是区块与区块之间的连接关系,而这种连接关系是由「指针」决定的。更科学的账本分类方法不是基于它的形状,而是基于其「指针」的类别、数量。
我们的采访对象伍鸣是Conflux的联合创始人,在加入Conflux之前任微软亚洲研究院系统组资深研究员,主要的研究方向为分布式事务处理系统、图计算引擎和人工智能平台,他在分布式系统的设计和实现上拥有丰富的专业知识。
Conflux是使用树图结构的公有链,其团队成员大多拥有美国一流大学的留学背景和在硅谷、华尔街的多年工作经验,有着突出的科研能力与技术能力。姚期智院士是Conflux团队的首席科学家。
链、DAG、树图:结构不同能力不同
问:DAG、树图这些非链式的账本结构能被认为是区块链吗?
伍鸣:不管是链、DAG,还是树图,我们要通过它们解决的问题其实是一样的,我们可以用区块链技术这个词把它们概括起来。
问:链结构、DAG结构、树图结构的本质区别是什么?为什么Conflux是树图而不是DAG?
伍鸣:你可以认为在链结构里,每个区块只能有一个指针,这个指针是指向其父亲区块的,那么所有区块就会一个接一个连起来,形成一个链状的结构。
DAG结构概括来讲是指每个区块有多于一个的指针,可以指向多于一个的其他区块,形成的是一个有向无环的图状结构。
Conflux的树图结构不同于链或DAG只有一类指针,它的每个区块都有两种指针,一种指针指向父亲区块,且只能有一个父亲,与传统的链式结构一样;一种指针指向引用区块,需要引用多个区块,表达不同区块间的happens-before(先行发生)关系。
所以,在 Conflux 里有两种类型的边,父边(父亲指针确定的边)和引用边(引用指针确定的边)。如果只看父边,账本的结构是一棵树;如果同时看父边和引用边,账本的结构是一个图。树图结构就是指在图中包含了一棵树的这样一种结构。
我们觉得如果继续叫DAG 可能会让大家产生误解,因为目前其他基于DAG的区块链系统都只有一种类型的连接区块或交易的边,因此有了树图这个概念。树图它更接近于Conflux账本结构的本质。
问:Conflux为什么要引入两种指针?三种不同账本结构的区块链系统会有何不同?
伍鸣:三种不同账本结构下的区块链系统最大的不同在于,它们对全序的支持或实现方式是不一样的。
链结构支持全序,DAG结构天然形成的是偏序,树图结构支持全序。
链结构中舍弃了分叉上的区块,其主链上的区块都有着唯一的父子关系,天然形成一个确定的顺序,所有人都可以按照这个顺序执行区块里的交易,所有人最后都能够达到一个一致的状态。
DAG结构中天然形成的是一个偏序。偏序的意思是说如果图中的两个区块之间没有直接的边,或者两个区块之间不存在一条路径,就没有办法确定这两个区块及它们所包含的交易间的顺序。
不过DAG可以通过设计为区块排出全序,现有的DAG有些支持全序有些不支持全序。
树图结构通过引入主链和Epoch的概念,实现了对区块全序的支持,这也是Conflux有两种指针的原因。(如何实现全序将在下一节详细介绍)
问:为什么要排全序,偏序会带来什么问题?
伍鸣:一个区块链系统,如果只需要处理普通的转账交易,又能通过指针保证并发交易间没有因果关系,那它也许可以用偏序。
因为这种系统只需要处理加减操作,而加减操作是满足交换律和结合律的,交易的执行顺序对系统状态没有影响,系统最终的状态是一致的。
但偏序不能支持智能合约,因为智能合约是图灵完备的,它需要表达复杂的逻辑计算,它有乘法,一旦有乘法和加法就不会满足交换律了。
也就是说,两笔交易A和B,先执行A后执行B得到的状态与先执行B后执行A得到的状态是不一样的。偏序下两笔交易有可能以任意的顺序执行,那么不同的矿工就会得到不同的系统状态,就无法取得共识。
如果一条链想要支持智能合约,就要支持全序。
问:既然为了实现全序要多做工作,为什么使用DAG或树图,而不是链结构?
伍鸣:区块链会产生很多分叉,链结构是无法定义分叉上的区块的执行顺序的,它只能选择丢掉分叉。
丢掉分叉会牺牲掉一些区块,不仅浪费了资源,还制约了吞吐率;丢掉分叉也会牺牲一些安全性,因为在最长链共识机制下,分叉上的区块是不能为最长链共识作出贡献的,比如有很多好人区块分叉的话,这些区块就不能用来贡献最长链,也就不能用来贡献链的安全,坏人可以用更少的算力攻击这条链。
树图和实现了全序的DAG把分叉区块加入到账本中,并定义了分叉上区块的执行顺序。
把所有的区块都算进来,也就让所有区块都贡献到系统的吞吐率上,这使得系统的瓶颈就不再是共识机制,而是网络本身。只要网络足够快,系统的性能就还能再高,从而使得整个系统在不牺牲安全性的同时获得更高的吞吐率。
Conflux如何实现全序
问:Conflux如何实现全序?
伍鸣:Conflux是通过引入主链这个概念最终实现全序的。我们之前讲过每个区块都有两种指针,其中一种是指向父亲区块的,这种指针决定的账本结构是一棵树,通过这棵树可以确定一条主链。
具体实现上,Conflux采用了Ghost和Epoch这两种规则。Ghost规则用来确定主链,Epoch规则用来确定区块的顺序,两者结合,就能实现区块的全序。
问:Ghost如何确定主链?
伍鸣:Ghost从创世区块开始,迭代的去从孩子区块中选择放在主链上的下一个区块,选择规则是挑选拥有最大子树的孩子区块为主链区块。
如下图所示,区块A和区块B是创世区块的两个孩子区块。A子树有6个区块,B子树有5个区块,所以选择区块A作为紧接着创世区块的主链上的区块。根据同样的规则,把区块C,E,H,都选择进了主链。
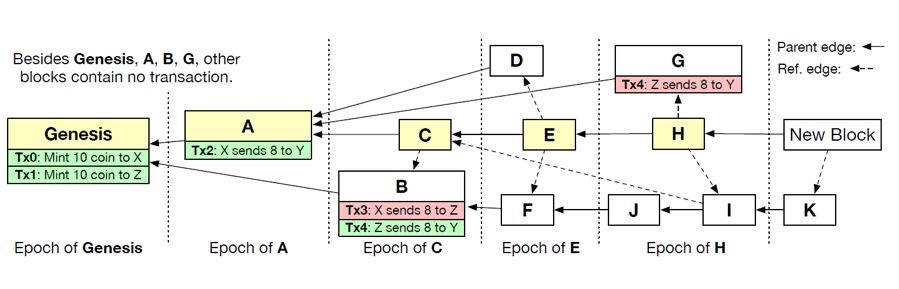
(图中实线箭头指向父亲区块,虚线箭头指向引用区块)
问:Epoch如何实现对区块的排序?
伍鸣:Conflux中的每个新区块在产生时,除了选择主链(该区块观察到的主链)上的最后一个区块作为自己的父亲区块外,还必须把所有自己观察到的但还没有被其他区块引用的区块引用起来,表达不同区块之间的happens-before的关系。
如上图所示,如果一个机器节点在产生区块E的时候,发现系统中已经有了区块D,而且这个时候区块D还未被任何其他区块引用,那么区块E就把自己的引用指针指向区块D,也就是说在区块E和区块D之间加上一个有向的引用边,表示D是在E之前产生的。
主链上的每一个区块确定一个Epoch。在分叉上的区块属于哪个Epoch,是由第一个产生在它之后的主链区块所在的Epoch决定的。比如区块D属于Epoch E,因为D最先被E引用,所以产生在E之前,但是D并不产生在C之前。
问:在同一个Epoch内,区块间的顺序是如何确定的?
伍鸣:在每一个Epoch内部,Conflux用拓扑排序确定区块间的顺序。如果出现平局,再根据区块的哈希值来排序。
如此一来,通过Ghost规则确定主链,通过Epoch规则确定区块的大体顺序,通过拓扑和哈希排序实现同一Epoch内区块的顺序,最终,Conflux的树图结构账本提供了一个一致的区块全序。
备注:去年技术工坊有一个Conflux分享:视频:漫谈区块图技术之XDAG和Conflux 也介绍了确认主链和排序,有兴趣的可以看看。
DAG和树图引发的思考
问:如果多个节点同时出块,这些区块又都有效,会不会同一时间段产生大量区块?这样一来,每个区块中引用指针占的空间会不会变得很大?
伍鸣:不会的,实际上整个系统的出块率是固定的,我们会动态的去调整出块难度,出块率很高,我们就增加难度把它降下来,出块率很低,我们就减少难度让它增上去。
问:如果多个节点同时出块,并发区块中应该会包含相同的交易,怎么解决重复打包交易的问题?
伍鸣:Conflux采用的是混合策略(Mixed-Strategy,博弈论中的一种策略),矿工们根据交易费的选择权重随机地从交易等待池中选取交易。随机是比较抽象的一个描述,它实际上很复杂,矿工会跟随这种随机方法选取交易,让自己打包交易获得的回报最大化。
当然不可能完全避免重复,交易池的交易越多重复概率越小,在正常情况下可能有30%左右的交易重复。如果交易池里的交易很少,比如说最极端的情况,只有一个交易,那当然是会重复的,因为所有人都会打包这个交易。
问:如果多个节点同时出块,有没有可能发生交易冲突的问题?
伍鸣:一般我们说的交易冲突是指上一个交易把钱花光没有余额了,但后面还有交易。Conflux通过区块全序保证了交易的执行顺序,就会避免这个问题,如果发生在前边的交易把钱花光了,就会让它后边的交易变为无效。
另一种情况是相同的交易有可能被打包到不同的区块里,在这种情况下,Conflux只接受在区块全序中排在最开始位置的这笔交易,而把后面的交易变为无效。
问:因为账本结构的复杂性,会不会出现不同节点账本不一致的情况?
伍鸣:肯定是有的,但经过一段时间以后就能确定账本。有一个公式可以算出主链区块被统一的概率,大概五、六个Epoch后,账本就能一致。
问:树图在51%攻击上的安全性是怎么样的?
伍鸣:Conflux中只要主链定了,交易的全序就定了,攻击者想发动51%攻击、想改变交易的顺序,就必须改变主链的顺序。
因此在51%攻击上,树图的安全性和Ghost链的安全性是差不多的。
Ghost规则比最长链规则安全,Ghost看的是子树的权重,把分叉上的区块也考虑到了,所有的区块、所有的算力都贡献到主链的选择上,能够严格地满足51%这个概念。但最长链规则没有考虑分叉链上算力的浪费。
问:在对矿工的激励机制上,树图跟链式结构有什么不同?
伍鸣:有一种情况是树图中才会出现的。树图需要区块去引用其他区块,表达不同区块之间的happens-before的关系,那有的区块可能不去正常引用其他区块,就是说看到其他区块也不引用。这是我们不希望看到的情况。
另一种发生在树图上的欺骗行为在传统的链上也会发生,就是产生区块但不广播,偷偷挖一个私有的链,等到某个时机再放出去。
在这两种情况下,这些不正常区块的并发区块会变得很多,因为它们和其他区块之间缺少happens-before关系。Conflux以此为依据去惩罚这两种行为:并发区块的个数越多,矿工获得的奖励越少。
结束语
链式结构放弃了分叉上的区块,这样做虽然牺牲了一定的吞吐率,却保证了交易的全序。DAG把分叉上的区块都纳入到账本中,这样做虽然不再浪费算力,却引入了一个如何对区块排序的难题。
有的DAG干脆不对区块排序,因为在一些应用场景下,交易的全序可能并不那么重要,比如IOTA。其他DAG则需要设计一种方法,实现对区块的排序。比如Byteball 、Hashgraph。
当我们深入地去了解不排全序的DAG、排全序的DAG、排全序DAG的不同排序方法,以及这些DAG采用的不同账本结构,就会发现它们是截然不同的。
或许正因如此,Conflux不再把自己归类为DAG,而具有两种不同类别指针的它也确实与DAG有着不小的区别,树图也许更接近其本质。
于是,这次带着弄清DAG与链的差别开始的采访,最后得出的结论是:不同DAG项目的差别,比DAG与链的差别都大。





