Solana获取程序帐户
- 想样
- 发布于 2024-11-25 18:44
- 阅读 2316
一个返回程序所拥有的账户的RPC方法。目前不支持分页。请求getProgramAccounts应该包括dataSlice和/或filters参数,以提高响应时间并返回只有预期结果的内容。综述参数programId:string-要查询的程序的公钥,以base58编码的字符串形式
<!--StartFragment-->
一个返回程序所拥有的账户的RPC方法。目前不支持分页。请求getProgramAccounts应该包括dataSlice和/或filters参数,以提高响应时间并返回只有预期结果的内容。
综述
<!--EndFragment--> <!--StartFragment-->
参数
-
programId:string- 要查询的程序的公钥,以base58编码的字符串形式提供。 -
(可选)
configOrCommitment:object- 包含以下可选字段的配置参数:-
(可选)
commitment:string- [状态承诺/State commitmentopen in new window] -
(可选)
encoding:string- 账户数据的编码方式,可以是:base58,base64, 或jsonParsed. 请注意 web3js 用户应改用 [getParsedProgramAccountsopen in new window] -
(可选)
dataSlice:object- 根据以下内容限制返回的账户数据: -
offset:number- 开始返回账户数据的字节数 -
length:number- 要返回的账户数据的字节数 -
(可选)
filters:array- 使用以下过滤器对象对结果进行过滤: -
memcmp:object- 将一系列字节与账户数据匹配:offset:number- 开始比较的账户数据字节偏移量bytes:string- 要匹配的数据,以base58编码的字符串形式,限制为129个字节
-
dataSize:number- 将账户数据的长度与提供的数据大小进行比较 -
(可选)
withContext:boolean- 将结果包装在一个 [RpcResponse JSON objectopen in new window]
-
响应
默认情况下,getProgramAccounts将返回一个具有以下结构的 JSON 对象数组:
-
pubkey:string- 账户公钥,以 base58 编码的字符串形式 -
account:object- 一个包含以下子字段的 JSON 对象:lamports:number, 分配给账户的 lamports 数量owner:string, 账户所分配的程序的 base58 编码的公钥data:string|object- 与账户关联的数据,根据提供的编码参数,可以是编码的二进制数据或 JSON 格式 parameterexecutable:boolean, 指示账户是否包含着程序rentEpoch:number, 该账户下次需要支付租金的纪元(epoch)
<!--EndFragment--> <!--StartFragment-->
深入
getProgramAccounts 是一个多功能的RPC方法,用于返回由程序拥有的所有账户。我们可以利用getProgramAccounts进行许多有用的查询,例如查找:
- 特定钱包的所有代币账户
- 特定代币发行的所有代币账户(即所有[SRMopen in new window]持有人)
- 特定程序的所有自定义账户(即所有[Mangoopen in new window]用户)
尽管getProgramAccounts非常有用,但由于目前的限制,它经常被误解。许多由getProgramAccounts支持的查询需要RPC节点扫描大量数据。这些扫描需要大量的内存和资源。因此,调用过于频繁或范围过大可能导致连接超时。此外,在撰写本文时,getProgramAccounts端点不支持分页。如果查询结果太大,响应将被截断。
为了解决当前的限制,getProgramAccounts提供了一些有用的参数,包括dataSlice和filters选项的memcmp和dataSize。通过提供这些参数的组合,我们可以将查询范围缩小到可管理和可预测的大小。
getProgramAccounts的一个常见示例涉及与[SPL-Token Programopen in new window]程序交互。仅使用基本调用请求由Token程序拥有的所有账户将涉及大量的数据。然而,通过提供参数,我们可以高效地请求我们要使用的数据。
filters
与getProgramAccounts一起使用的最常见参数是filters数组。该数组接受两种类型的过滤器,即dataSize和memcmp。在使用这些过滤器之前,我们应该熟悉我们请求的数据的布局和序列化方式。
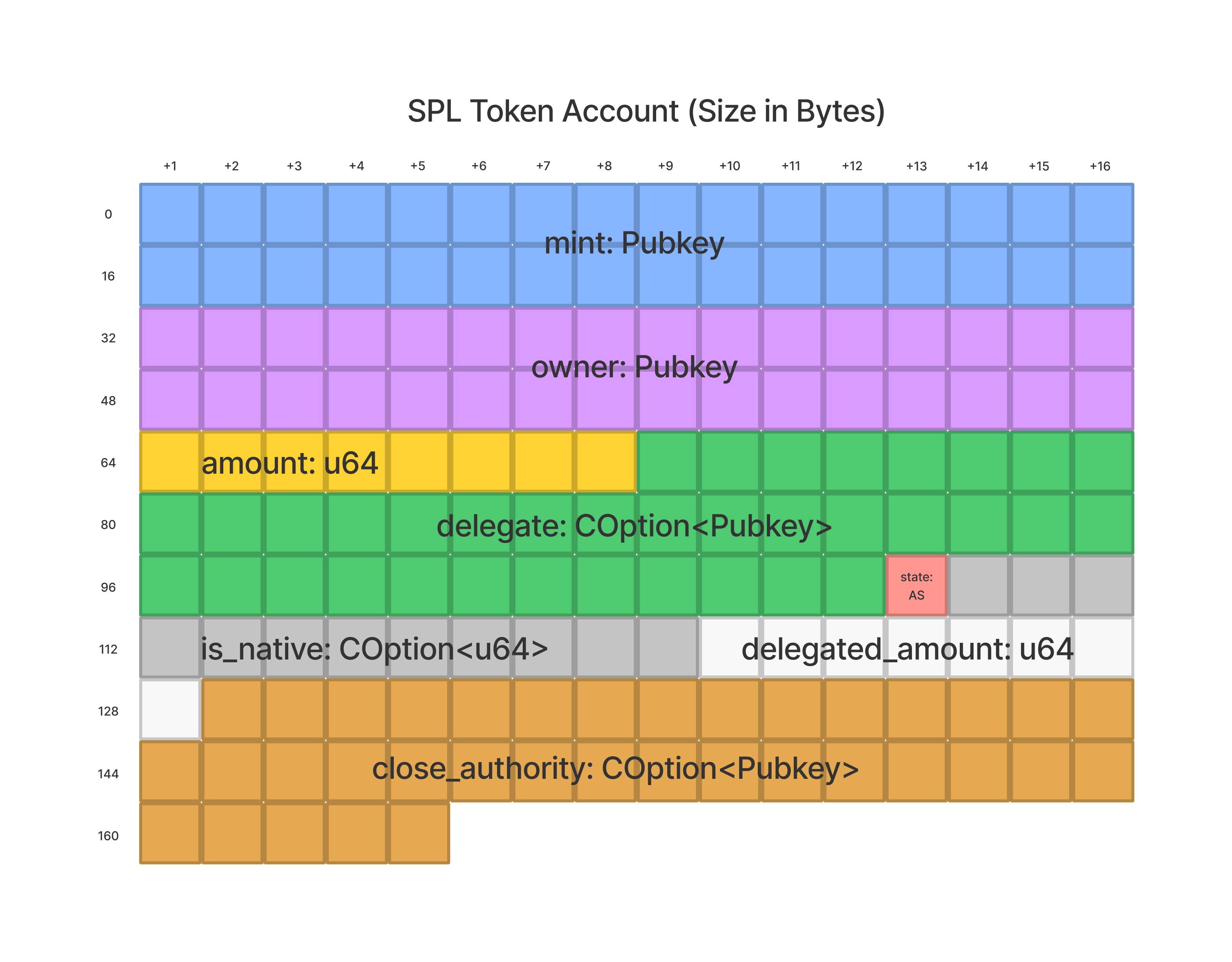
dataSize
在Token程序的情况下,我们可以看到[代币账户的长度为165个字节open in new window]。 具体而言,一个代币账户有八个不同的字段,每个字段需要一定数量的字节。我们可以使用下面的示例图来可视化这些数据的布局。
<!--EndFragment-->
 <!--StartFragment-->
<!--StartFragment-->
如果我们想找到由我们的钱包地址拥有的所有代币账户,我们可以在filters数组中添加{ dataSize: 165 }来将查询范围缩小为仅限长度为165个字节的账户。然而,仅此还不够。我们还需要添加一个过滤器来查找由我们的地址拥有的账户。我们可以使用memcmp过滤器实现这一点。
memcmp
<!--EndFragment--> <!--StartFragment-->
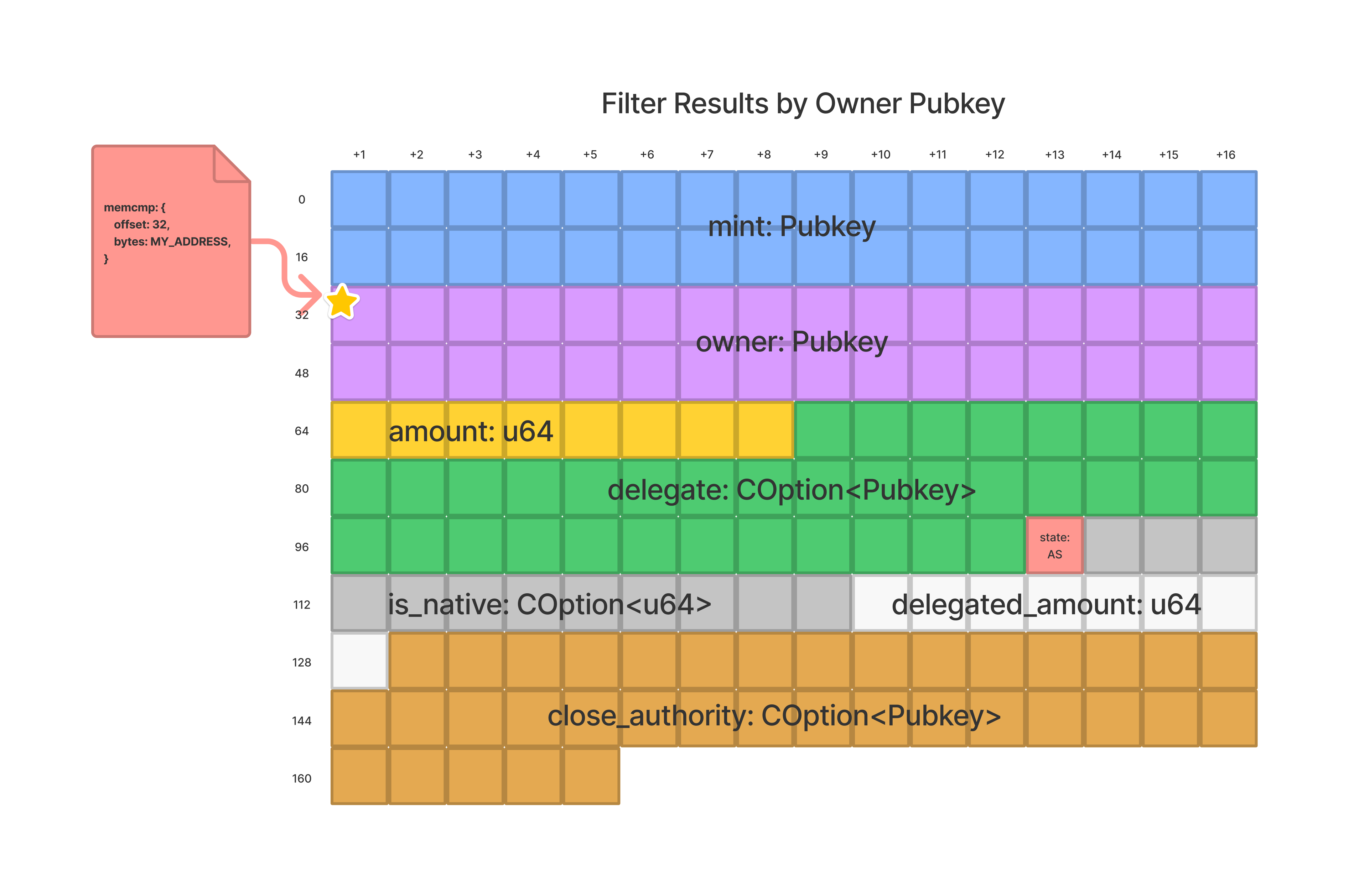
memcmp过滤器,也叫"内存比较"过滤器,允许我们比较存储在账户上的任何字段的数据。具体而言,我们可以查询仅与特定位置上的特定一组字节匹配的账户。memcmp需要两个参数:
offset: 开始比较数据的位置。这个位置以字节为单位,表示为一个整数。bytes: 数据应该与账户的数据匹配。这表示为一个base58编码的字符串,应该限制在129个字节以下。
需要注意的是,memcmp只会返回与提供的bytes完全匹配的结果。目前,它不支持与提供的bytes相比小于或大于的比较。
继续使用我们的Token程序示例,我们可以修改查询,只返回由我们的钱包地址拥有的代币账户。观察代币账户时,我们可以看到存储在代币账户上的前两个字段都是公钥,而且每个公钥的长度为32个字节。鉴于owner是第二个字段,我们应该从offset为32字节的位置开始进行memcmp。从这里开始,我们将寻找owner字段与我们的钱包地址匹配的账户。
<!--EndFragment-->
 <!--StartFragment-->
<!--StartFragment-->
我们可以通过以下实例来调用此查询:
<!--EndFragment-->
<!--StartFragment-->
import { TOKEN_PROGRAM_ID } from "@solana/spl-token";
import { clusterApiUrl, Connection } from "@solana/web3.js";
(async () => {
const MY_WALLET_ADDRESS = "FriELggez2Dy3phZeHHAdpcoEXkKQVkv6tx3zDtCVP8T";
const connection = new Connection(clusterApiUrl("devnet"), "confirmed");
const accounts = await connection.getParsedProgramAccounts(
TOKEN_PROGRAM_ID, // new PublicKey("TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA")
{
filters: [
{
dataSize: 165, // number of bytes
},
{
memcmp: {
offset: 32, // number of bytes
bytes: MY_WALLET_ADDRESS, // base58 encoded string
},
},
],
}
);
console.log(
`Found ${accounts.length} token account(s) for wallet ${MY_WALLET_ADDRESS}: `
);
accounts.forEach((account, i) => {
console.log(
`-- Token Account Address ${i + 1}: ${account.pubkey.toString()} --`
);
console.log(`Mint: ${account.account.data["parsed"]["info"]["mint"]}`);
console.log(
`Amount: ${account.account.data["parsed"]["info"]["tokenAmount"]["uiAmount"]}`
);
});
/*
// Output
Found 2 token account(s) for wallet FriELggez2Dy3phZeHHAdpcoEXkKQVkv6tx3zDtCVP8T:
-- Token Account Address 0: H12yCcKLHFJFfohkeKiN8v3zgaLnUMwRcnJTyB4igAsy --
Mint: CKKDsBT6KiT4GDKs3e39Ue9tDkhuGUKM3cC2a7pmV9YK
Amount: 1
-- Token Account Address 1: Et3bNDxe2wP1yE5ao6mMvUByQUHg8nZTndpJNvfKLdCb --
Mint: BUGuuhPsHpk8YZrL2GctsCtXGneL1gmT5zYb7eMHZDWf
Amount: 3
*/
})();<!--EndFragment-->
<!--StartFragment-->
dataSlice
除了上面提到的两个过滤器参数以外,getProgramAccounts的第三个最常见参数是dataSlice。与filters参数不同,dataSlice不会减少查询返回的账户数量。dataSlice将限制的是每个账户的数据量。
与memcmp类似,dataSlice接受两个参数:
offset: 开始返回账户数据的位置(以字节为单位)length: 应该返回的字节数
在处理大型数据集但实际上不关心账户数据本身时,dataSlice特别有用。例如,如果我们想找到特定代币发行的代币账户数量(即代币持有者数量),就可以使用dataSlice。
<!--EndFragment--> <!--StartFragment-->
import { TOKEN_PROGRAM_ID } from "@solana/spl-token";
import { clusterApiUrl, Connection } from "@solana/web3.js";
(async () => {
const MY_TOKEN_MINT_ADDRESS = "BUGuuhPsHpk8YZrL2GctsCtXGneL1gmT5zYb7eMHZDWf";
const connection = new Connection(clusterApiUrl("devnet"), "confirmed");
const accounts = await connection.getProgramAccounts(
TOKEN_PROGRAM_ID, // new PublicKey("TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA")
{
dataSlice: {
offset: 0, // number of bytes
length: 0, // number of bytes
},
filters: [
{
dataSize: 165, // number of bytes
},
{
memcmp: {
offset: 0, // number of bytes
bytes: MY_TOKEN_MINT_ADDRESS, // base58 encoded string
},
},
],
}
);
console.log(
`Found ${accounts.length} token account(s) for mint ${MY_TOKEN_MINT_ADDRESS}`
);
console.log(accounts);
/*
// Output (notice the empty <Buffer > at acccount.data)
Found 3 token account(s) for mint BUGuuhPsHpk8YZrL2GctsCtXGneL1gmT5zYb7eMHZDWf
[
{
account: {
data: <Buffer >,
executable: false,
lamports: 2039280,
owner: [PublicKey],
rentEpoch: 228
},
pubkey: PublicKey {
_bn: <BN: a8aca7a3132e74db2ca37bfcd66f4450f4631a5464b62fffbd83c48ef814d8d7>
}
},
{
account: {
data: <Buffer >,
executable: false,
lamports: 2039280,
owner: [PublicKey],
rentEpoch: 228
},
pubkey: PublicKey {
_bn: <BN: ce3b7b906c2ff6c6b62dc4798136ec017611078443918b2fad1cadff3c2e0448>
}
},
{
account: {
data: <Buffer >,
executable: false,
lamports: 2039280,
owner: [PublicKey],
rentEpoch: 228
},
pubkey: PublicKey {
_bn: <BN: d4560e42cb24472b0e1203ff4b0079d6452b19367b701643fa4ac33e0501cb1>
}
}
]
*/
})();<!--EndFragment--> <!--StartFragment-->
通过组合这三个参数(dataSlice、dataSize和memcmp),我们可以限制查询的范围,并高效地返回我们想要的数据。
<!--EndFragment-->





