优化 Solana 程序
- 想样
- 发布于 2024-12-12 18:32
- 阅读 1874
切实可行的见解对大型数据结构和高频操作使用零拷贝反序列化使用nostd_entrypoint代替solana_program臃肿的入口点尽量减少动态分配,支持基于堆栈的数据结构实现自定义序列化/反序列化以避免Borsh开销使用[inline(always)]标记关键函数以
<!--StartFragment-->
切实可行的见解
- 对大型数据结构和高频操作使用零拷贝反序列化
- 使用nostd_entrypoint代替solana_program臃肿的入口点
- 尽量减少动态分配,支持基于堆栈的数据结构
- 实现自定义序列化/反序列化以避免 Borsh 开销
- 使用#[inline(always)]标记关键函数以获得潜在的性能提升
- 使用位操作实现高效的指令解析
- 使用 Solana 特定的 C 系统调用,例如sol_invoke_signed_c
- 测量计算单元使用情况以指导优化工作
<!--EndFragment--> <!--StartFragment-->
介绍
Solana 开发人员在编写程序时面临几个决策:平衡易用性、性能和安全性。这包括用户友好的 Anchor 框架(以一些开销为代价简化开发)和使用不安全的 Rust 和直接系统调用的低级方法。虽然后者提供了最佳性能,但它增加了复杂性和潜在的安全风险。对于开发人员来说,关键问题不仅仅是如何优化,还包括何时优化以及优化到何种程度。
这篇博文深入探讨了这些选项,为开发人员提供了优化前景的路线图。我们将研究以下抽象级别:
1. [Anchor]:大多数开发人员首选的、功能强大的高级框架2.[零拷贝] Anchor :为优化大型数据结构而编写的 Anchor 代码3.[原生 Rust]:用于平衡控制和易用性的纯 Rust 4.带有直接[系统调用 (syscalls)的][不安全 Rust]:突破性能极限
<!--EndFragment--> <!--StartFragment-->
其目标不是提出一种适合所有情况的解决方案,而是让开发人员掌握相关知识,使他们能够根据具体用例就如何编写程序做出明智的决策。
读完这篇文章后,你会更好地理解如何思考这些不同的抽象层次,以及何时考虑优化路径。请记住,最优化的代码并不总是最好的解决方案——关键在于找到适合项目需求的平衡点。
本文假设您熟悉[基本的 Rust]、[Solana 的账户模型]和[Anchor 框架]。
对于没有耐心的人:
<!--EndFragment-->
 <!--StartFragment-->
<!--StartFragment-->
计算单元
Solana 的高性能架构依赖于高效的资源管理。该系统的核心是计算单元 (CU),这是验证者处理给定交易所消耗的计算资源的度量。
<!--EndFragment--> <!--StartFragment-->
为什么要关心计算单元?
1. 交易成功率:每笔交易都有 CU 限制。超过该限制会导致交易失败\ 2. 成本效率:更低的 CU 使用率意味着更低的交易费用\ 3. 用户体验:优化的程序执行速度更快,增强整体用户体验\ 4. 可扩展性:高效的程序允许每个区块处理更多交易,从而提高网络吞吐量
<!--EndFragment--> <!--StartFragment-->
测量计算单元
solana_program ::log::sol_log_compute_units()系统调用记录程序在执行过程中的特定时间点消耗的计算单元数量。
这是一个使用系统调用的简单的 compute_fn! 宏实现:
<!--EndFragment-->
#[macro_export]
macro_rules! compute_fn {
($msg:expr=> $($tt:tt)*) => {
::solana_program::msg!(concat!($msg, " {"));
::solana_program::log::sol_log_compute_units();
let res = { $($tt)* };
::solana_program::log::sol_log_compute_units();
::solana_program::msg!(concat!(" } // ", $msg));
res
};
}<!--StartFragment-->
此宏取自[Solana Developers GitHub 存储库,]用于 CU 优化。此代码片段使用两个指令(初始化和递增)实现了一个计数器程序
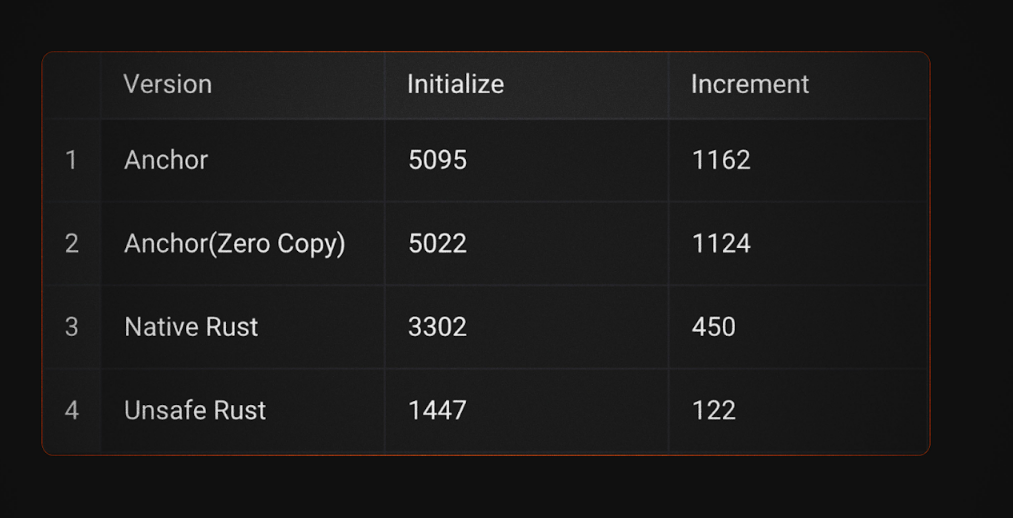
在本文中,我们将用四种不同的方式编写相同的计数器程序,使用相同的两个指令(初始化和递增),并比较它们的 CU 使用情况:Anchor、使用零拷贝反序列化的 Anchor、原生 Rust 和不安全的 Rust
初始化一个帐户并对该帐户进行微小更改(在本例中为递增)是比较这些不同方法的良好基准。我们暂时不会使用[PDA ]
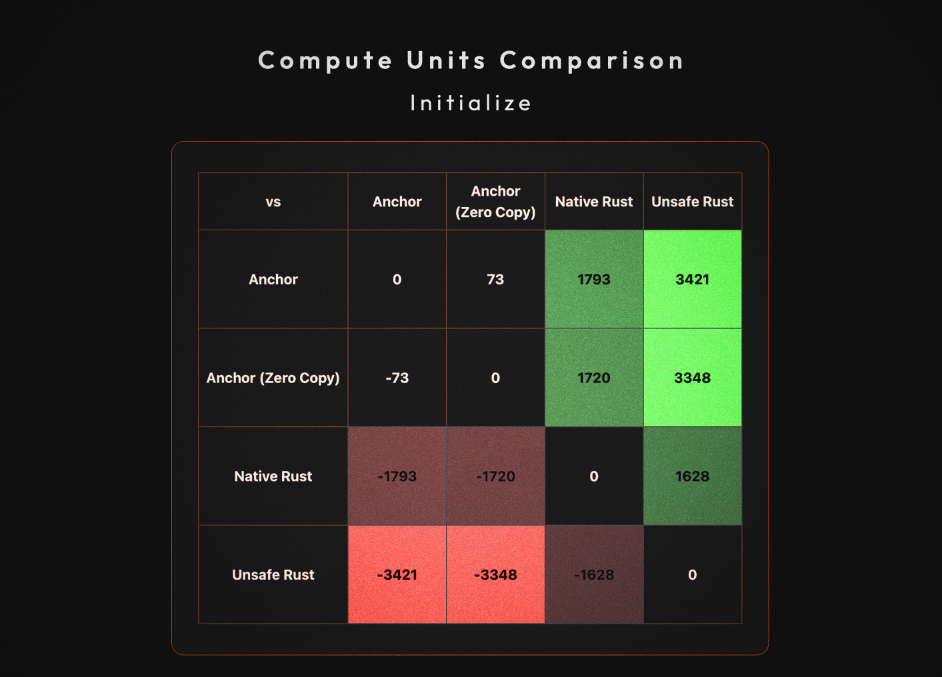
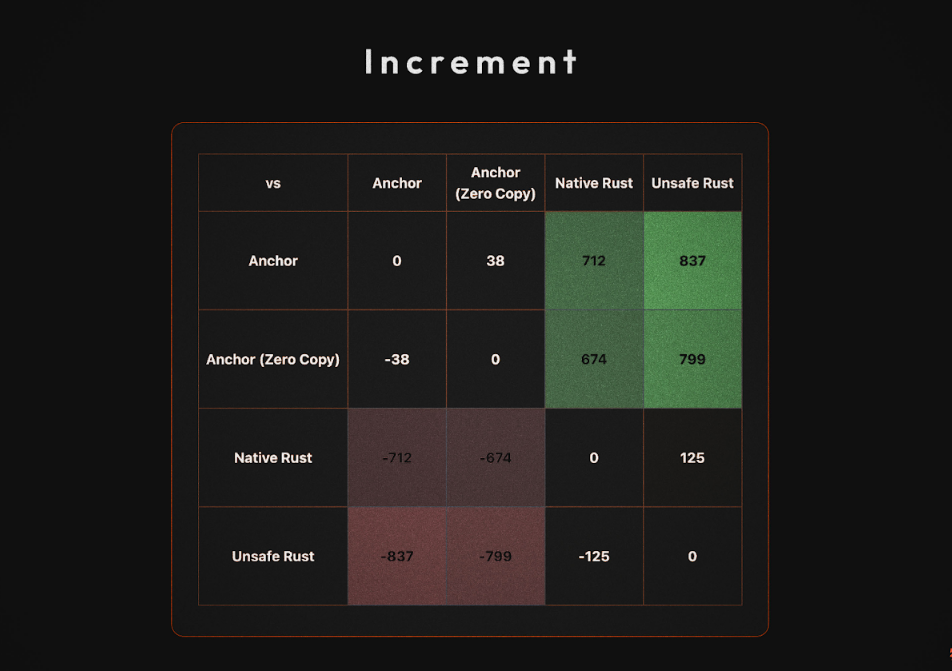
对于没有耐心的人,以下是四种方法的 CU 比较:
<!--EndFragment-->
<!--StartFragment-->
零拷贝反序列化
零拷贝反序列化允许我们直接解释帐户数据,而无需分配新内存或复制数据。这种技术可以减少 CPU 使用率、降低内存消耗,并可能带来更高效的指令。
让我们从一个基本的 Anchor 计数器程序开始:
<!--EndFragment-->
use anchor_lang::prelude::*;
declare_id!("37oUa3WkeqwnFxSCqyMnpC3CfTSwtvyJxnwYQc3u6U7C");
#[program]
pub mod counter {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
let counter = &mut ctx.accounts.counter;
counter.count = 0;
Ok(())
}
pub fn increment(ctx: Context<Update>) -> Result<()> {
let counter = &mut ctx.accounts.counter;
//Not doing checked_add, wrapping add or any overflow checks
//to keep it simple
counter.count += 1;
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize<'info> {
#[account(init, payer = user, space = 8 + 8)]
pub counter: Account<'info, Counter>,
#[account(mut)]
pub user: Signer<'info>,
pub system_program: Program<'info, System>,
}
#[derive(Accounts)]
pub struct Update<'info> {
#[account(mut)]
pub counter: Account<'info, Counter>,
pub user: Signer<'info>,
}
#[account]
pub struct Counter {
pub count: u64,
}<!--StartFragment-->
上面没什么特别的。现在让我们用 zero_copy 让它更花哨一些:
use anchor_lang::prelude::*;
declare_id!("7YkAh5yHbLK4uZSxjGYPsG14VUuDD6RQbK6k4k3Ji62g");
#[program]
pub mod counter {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
let mut counter = ctx.accounts.counter.load_init()?;
counter.count = 0;
Ok(())
}
pub fn increment(ctx: Context<Update>) -> Result<()> {
let mut counter = ctx.accounts.counter.load_mut()?;
counter.count += 1;
Ok(())
}
}
#[derive(Accounts)]
pub struct Initialize<'info> {
#[account(init, payer = user, space = 8 + std::mem::size_of::<CounterData>())]
pub counter: AccountLoader<'info, CounterData>,
#[account(mut)]
pub user: Signer<'info>,
pub system_program: Program<'info, System>,
}
#[derive(Accounts)]
pub struct Update<'info> {
#[account(mut)]
pub counter: AccountLoader<'info, CounterData>,
pub user: Signer<'info>,
}
#[account(zero_copy)]
pub struct CounterData {
pub count: u64,
}<!--StartFragment-->
主要变化:
1. 使用 AccountLoader 替代 Account\ 我们现在使用AccountLoader<'info, CounterData>替代Account<'info, Counter>。这样可以实现对帐户数据的零拷贝访问。
2. 零拷贝属性\ **CounterData上的#[account(zero_copy)]属性表示该结构可以直接从内存中的原始字节进行解释。**
3. 直接数据访问\ 在初始化和增量函数中,我们分别使用load_init()和load_mut()来获取对帐户数据的可变访问,而无需复制它
4. 缓解重复账户漏洞
零拷贝反序列化解决了 Borsh 序列化中存在的潜在漏洞。使用 Borsh,可以创建和改变账户的不同副本,然后将其复制回同一地址。如果同一账户在交易中多次出现,此过程可能会导致不一致。然而,零拷贝直接从同一内存地址读取和写入。这种方法可确保交易中对账户的所有引用都对相同的数据进行操作,从而消除了由于重复账户而导致不一致的风险。
5. 内存布局保证\ **zero_copy属性确保CounterData具有一致的内存布局,从而允许安全地重新解释原始字节。此实现将初始化指令的 CU 使用量从 5095 减少到 5022,将增量**指令的 CU 使用量从 1162 减少到 1124。
在我们的案例中,零拷贝带来的改进很小,而且很大程度上微不足道。然而,在处理大型数据结构时,零拷贝反序列化可能很有用。这是因为它可以在处理存储复杂或大量数据的帐户时大幅减少 CPU 和内存使用量
权衡和考虑
零拷贝也存在一些挑战:
1. 复杂性增加:代码变得稍微复杂一些,需要小心处理原始数据
2. 兼容性:并非所有数据结构都适合零拷贝反序列化 — 它们必须具有可预测的内存布局。例如,具有动态大小字段的结构(如 Vec 或 String)与零拷贝反序列化不兼容。
使用零拷贝应该基于您的具体用例。对于像我们的计数器这样的简单程序,好处可能微乎其微。但是,随着程序的复杂性增加并处理更大的数据结构,零拷贝可以成为一种强大的优化工具。
虽然零拷贝优化并没有为我们的简单计数器程序带来显著的改进,但对效率的追求并没有就此结束。让我们探索另一种途径:在没有 Anchor 框架的情况下用 Rust 编写原生 Solana 程序。这种方法提供了更多的控制和优化潜力,尽管复杂性增加了。
<!--EndFragment--> <!--StartFragment-->
本土化
原生 Rust 程序提供较低级别的接口,需要开发人员处理 Anchor 自动化的各种任务。这包括帐户反序列化、序列化和各种安全检查。虽然这对开发人员的要求更高,但也为精细优化提供了机会。
让我们检查一下计数器程序的本机 Rust 实现:
<!--EndFragment-->
use solana_program::{
account_info::{next_account_info, AccountInfo},
entrypoint,
entrypoint::ProgramResult,
program_error::ProgramError,
pubkey::Pubkey,
rent::Rent,
system_instruction,
program::invoke,
sysvar::Sysvar,
};
use std::mem::size_of;
// Define the state struct
struct Counter {
count: u64,
}
// Declare and export the program's entrypoint
entrypoint!(process_instruction);
// Program entrypoint's implementation
pub fn process_instruction(
program_id: &Pubkey,
accounts: &[AccountInfo],
instruction_data: &[u8],
) -> ProgramResult {
let instruction = instruction_data
.get(0)
.ok_or(ProgramError::InvalidInstructionData)?;
match instruction {
0 => initialize(program_id, accounts),
1 => increment(accounts),
_ => Err(ProgramError::InvalidInstructionData),
}
}
fn initialize(program_id: &Pubkey, accounts: &[AccountInfo]) -> ProgramResult {
let account_info_iter = &mut accounts.iter();
let counter_account = next_account_info(account_info_iter)?;
let user = next_account_info(account_info_iter)?;
let system_program = next_account_info(account_info_iter)?;
if !user.is_signer {
return Err(ProgramError::MissingRequiredSignature);
}
if counter_account.owner != program_id {
let rent = Rent::get()?;
let space = size_of::<Counter>();
let rent_lamports = rent.minimum_balance(space);
invoke(
&system_instruction::create_account(
user.key,
counter_account.key,
rent_lamports,
space as u64,
program_id,
),
&[user.clone(), counter_account.clone(), system_program.clone()],
)?;
}
let mut counter_data = Counter { count: 0 };
counter_data.serialize(&mut &mut counter_account.data.borrow_mut()[..])?;
Ok(())
}
fn increment(accounts: &[AccountInfo]) -> ProgramResult {
let account_info_iter = &mut accounts.iter();
let counter_account = next_account_info(account_info_iter)?;
let user = next_account_info(account_info_iter)?;
if !user.is_signer {
return Err(ProgramError::MissingRequiredSignature);
}
let mut counter_data = Counter::deserialize(&counter_account.data.borrow())?;
//Not doing checked_add, wrapping add or any overflow checks to keep it simple
counter_data.count += 1;
counter_data.serialize(&mut &mut counter_account.data.borrow_mut()[..])?;
Ok(())
}
impl Counter {
fn serialize(&self, data: &mut [u8]) -> ProgramResult {
if data.len() < size_of::<Self>() {
return Err(ProgramError::AccountDataTooSmall);
}
//First 8 bytes is the count
data[..8].copy_from_slice(&self.count.to_le_bytes());
Ok(())
}
fn deserialize(data: &[u8]) -> Result<Self, ProgramError> {
if data.len() < size_of::<Self>() {
return Err(ProgramError::AccountDataTooSmall);
}
//First 8 bytes is the count
let count = u64::from_le_bytes(data[..8].try_into().unwrap());
Ok(Self { count })
}
}<!--StartFragment-->
主要区别和注意事项:
- 手动指令解析\ 与自动路由指令的 Anchor 不同,我们手动解析指令数据并将其路由到适当的函数
<!--EndFragment-->
let instruction = instruction_data
.get(0)
.ok_or(ProgramError::InvalidInstructionData)?;
match instruction {
0 => initialize(program_id, accounts),
1 => increment(accounts),
_ => Err(ProgramError::InvalidInstructionData),
}<!--StartFragment-->
2. 账户管理\ 我们使用next_account_info遍历账户,手动检查签名者和所有者。Anchor 使用其#[derive(Accounts)]宏自动处理此问题
<!--EndFragment-->
let account_info_iter = &mut accounts.iter();
let counter_account = next_account_info(account_info_iter)?;
let user = next_account_info(account_info_iter)?;
if !user.is_signer {
return Err(ProgramError::MissingRequiredSignature);
}<!--StartFragment-->
3. 自定义序列化:\ 我们为Counter结构体实现了自定义**序列化和反序列化**方法。Anchor默认使用[Borsh 序列化,将其抽象化]
<!--EndFragment-->
impl Counter {
fn serialize(&self, data: &mut [u8]) -> ProgramResult {
if data.len() < size_of::<Self>() {
return Err(ProgramError::AccountDataTooSmall);
}
//First 8 bytes is the count
data[..8].copy_from_slice(&self.count.to_le_bytes());
Ok(())
}
fn deserialize(data: &[u8]) -> Result<Self, ProgramError> {
if data.len() < size_of::<Self>() {
return Err(ProgramError::AccountDataTooSmall);
}
//First 8 bytes is the count
let count = u64::from_le_bytes(data[..8].try_into().unwrap());
Ok(Self { count })
}
}<!--StartFragment-->
4. 系统程序交互\ 创建帐户涉及使用invoke与[系统程序]直接交互并执行[跨程序调用(CPI)],Anchor 通过其init约束简化了这一过程: <!--EndFragment-->
invoke(
&system_instruction::create_account(
user.key,
counter_account.key,
rent_lamports,
space as u64,
program_id,
),
&[user.clone(), counter_account.clone(), system_program.clone()],
)?;<!--StartFragment-->
5. 细粒度控制\ 一般来说,本机程序对数据布局和处理提供更多的控制,因为它们不遵循单一的、固执己见的框架,从而允许更优化的代码。
<!--EndFragment--> <!--StartFragment-->
如何看待主播与本地人?
-
显式与隐式 本机程序需要显式处理 Anchor 隐式管理的许多方面。这包括帐户验证、序列化和指令路由
-
安全注意事项 如果没有 Anchor 的内置检查,开发人员必须警惕实施[适当的安全措施],例如检查帐户所有权和签名者状态
-
性能调优\ 本机程序允许进行更细粒度的性能优化,但需要更深入地了解 Solana 的运行时行为
-
样板代码\ 预计需要为 Anchor 抽象出来的常见操作编写更多样板代码
-
学习曲线\ 虽然本机编程可能更高效,但学习曲线更陡峭,需要对 Solana 的架构有更深入的了解
<!--EndFragment--> <!--StartFragment-->
总结
从 Anchor 到原生的最大限制因素是处理序列化和反序列化。在我们的例子中,这相对简单。但是,随着状态管理变得越来越复杂,它会变得越来越复杂。
不过,Anchor 使用的 Borsh 确实在计算上非常昂贵,所以这种努力是值得的。
我们的优化之旅并未就此结束。在下一节中,我们将利用直接系统调用并避免使用 Rust 标准库,进一步突破界限。
这种方法很有挑战性,但我保证它将为 Solana 运行时的内部工作原理提供一些有趣的见解。
<!--EndFragment--> <!--StartFragment-->
使用不安全的 Rust 和直接系统调用突破极限
为了将计数器程序的性能推向极限,我们现在将探索不安全 Rust 和直接系统调用的使用。不安全 Rust 允许开发人员绕过标准安全检查,从而实现直接内存操作和低级优化。同时,系统调用为 Solana 运行时提供直接接口。这种方法虽然复杂且需要细致的开发,但可以节省大量 CU。然而,它还需要更深入地了解 Solana 的架构并仔细关注程序安全性。潜在的性能提升是巨大的,但它们也伴随着更大的责任。
让我们检查一下利用这些先进技术的高度优化的计数器程序版本:
<!--EndFragment-->
use solana_nostd_entrypoint::{
basic_panic_impl, entrypoint_nostd, noalloc_allocator,
solana_program::{
entrypoint::ProgramResult, log, program_error::ProgramError, pubkey::Pubkey, system_program,
},
InstructionC, NoStdAccountInfo,
};
entrypoint_nostd!(process_instruction, 32);
pub const ID: Pubkey = solana_nostd_entrypoint::solana_program::pubkey!(
"EgB1zom79Ek4LkvJjafbkUMTwDK9sZQKEzNnrNFHpHHz"
);
noalloc_allocator!();
basic_panic_impl!();
const ACCOUNT_DATA_LEN: usize = 8; // 8 bytes for u64 counter
/*
* Program Entrypoint
* ------------------
* Entrypoint receives:
* - program_id: The public key of the program's account
* - accounts: An array of accounts required for the instruction
* - instruction_data: A byte array containing the instruction data
*
* Instruction data format:
* ------------------------
* | Bit 0 | Bits 1-7 |
* |-------|----------|
* | 0/1 | Unused |
*
* 0: Initialize
* 1: Increment
*/
#[inline(always)]
pub fn process_instruction(
_program_id: &Pubkey,
accounts: &[NoStdAccountInfo],
instruction_data: &[u8],
) -> ProgramResult {
if instruction_data.is_empty() {
return Err(ProgramError::InvalidInstructionData);
}
// Use the least significant bit to determine the instruction
match instruction_data[0] & 1 {
0 => initialize(accounts),
1 => increment(accounts),
_ => unreachable!(),
}
}
/*
* Initialize Function
* -------------------
* This function initializes a new counter account.
*
* Account structure:
* ------------------
* 1. Payer account (signer, writable)
* 2. Counter account (writable)
* 3. System program
*
* Memory layout of instruction_data:
* -----------------------------------------
* | Bytes | Content |
* |----------|----------------------------|
* | 0-3 | Instruction discriminator |
* | 4-11 | Required lamports (u64) |
* | 12-19 | Space (u64) |
* | 20-51 | Program ID |
* | 52-55 | Unused |
*/
#[inline(always)]
fn initialize(accounts: &[NoStdAccountInfo]) -> ProgramResult {
let [payer, counter, system_program] = match accounts {
[payer, counter, system_program, ..] => [payer, counter, system_program],
_ => return Err(ProgramError::NotEnoughAccountKeys),
};
if counter.key() == &system_program::ID {
return Err(ProgramError::InvalidAccountData);
}
let rent = solana_program::rent::Rent::default();
let required_lamports = rent.minimum_balance(ACCOUNT_DATA_LEN);
let mut instruction_data = [0u8; 56];
instruction_data[4..12].copy_from_slice(&required_lamports.to_le_bytes());
instruction_data[12..20].copy_from_slice(&(ACCOUNT_DATA_LEN as u64).to_le_bytes());
instruction_data[20..52].copy_from_slice(ID.as_ref());
let instruction_accounts = [
payer.to_meta_c(),
counter.to_meta_c(),
];
let instruction = InstructionC {
program_id: &system_program::ID,
accounts: instruction_accounts.as_ptr(),
accounts_len: instruction_accounts.len() as u64,
data: instruction_data.as_ptr(),
data_len: instruction_data.len() as u64,
};
let infos = [payer.to_info_c(), counter.to_info_c()];
// Invoke system program to create account
#[cfg(target_os = "solana")]
unsafe {
solana_program::syscalls::sol_invoke_signed_c(
&instruction as *const InstructionC as *const u8,
infos.as_ptr() as *const u8,
infos.len() as u64,
std::ptr::null(),
0,
);
}
// Initialize counter to 0
let mut counter_data = counter.try_borrow_mut_data().ok_or(ProgramError::AccountBorrowFailed)?;
counter_data[..8].copy_from_slice(&0u64.to_le_bytes());
Ok(())
}
/*
* Increment Function
* ------------------
* This function increments the counter in the counter account.
*
* Account structure:
* ------------------
* 1. Counter account (writable)
* 2. Payer account (signer)
*
* Counter account data layout:
* ----------------------------
* | Bytes | Content |
* |-------|----------------|
* | 0-7 | Counter (u64) |
*/
#[inline(always)]
fn increment(accounts: &[NoStdAccountInfo]) -> ProgramResult {
let [counter, payer] = match accounts {
[counter, payer, ..] => [counter, payer],
_ => return Err(ProgramError::NotEnoughAccountKeys),
};
if !payer.is_signer() || counter.owner() != &ID {
return Err(ProgramError::IllegalOwner);
}
let mut counter_data = counter.try_borrow_mut_data().ok_or(ProgramError::AccountBorrowFailed)?;
if counter_data.len() != 8 {
return Err(ProgramError::UninitializedAccount);
}
let mut value = u64::from_le_bytes(counter_data[..8].try_into().unwrap());
value += 1;
counter_data[..8].copy_from_slice(&value.to_le_bytes());
Ok(())
}<!--StartFragment-->
主要区别和优化:
1. 无标准环境
我们使用 solana_nostd_entrypoint,它提供了一个无标准环境。这消除了 Rust 标准库的开销,减少了程序大小并潜在地提高了性能。感谢[cavemanloverboy]和他的 GitHub 存储库“ [Solana 程序的无标准入口点”]。
2. 内联函数\ 关键函数用 #[inline(always)] 标记。内联是一种编译器优化,将函数主体插入到调用点,从而消除函数调用开销。这可以加快执行速度,尤其是对于小型、频繁调用的函数。
3.指令解析的位操作\ 我们使用[位操作]instruction_data[0] & 1来判断指令类型,这比其他解析方法更有效:
<!--EndFragment-->
// Use the least significant bit to determine the instruction
match instruction_data[0] & 1 {
0 => initialize(accounts),
1 => increment(accounts),
_ => unreachable!(),
}<!--StartFragment-->
4.零成本内存管理和最少的恐慌处理
noalloc_allocator !和basic_panic_impl!宏实现了最小、零开销内存管理和恐慌处理:
Noalloc_allocator!定义了一个自定义分配器,它在任何分配尝试时都会崩溃,并且在释放分配时不执行任何操作。将其设置为 Solana 程序的全局分配器可有效防止运行时的任何动态内存分配:
<!--EndFragment-->
#[macro_export]
macro_rules! noalloc_allocator {
() => {
pub mod allocator {
pub struct NoAlloc;
extern crate alloc;
unsafe impl alloc::alloc::GlobalAlloc for NoAlloc {
#[inline]
unsafe fn alloc(&self, _: core::alloc::Layout) -> *mut u8 {
panic!("no_alloc :)");
}
#[inline]
unsafe fn dealloc(&self, _: *mut u8, _: core::alloc::Layout) {}
}
#[cfg(target_os = "solana")]
#[global_allocator]
static A: NoAlloc = NoAlloc;
}
};
}<!--StartFragment-->
这至关重要,因为:
a)它消除了内存分配和释放操作的开销
b)它迫使开发人员使用基于堆栈或静态内存,这在性能方面通常更快、更可预测
c)减少程序的内存占用
basic_panic_impl!提供了一个最小的恐慌处理程序,它只记录“恐慌!”消息:
<!--EndFragment-->
#[macro_export]
macro_rules! basic_panic_impl {
() => {
#[cfg(target_os = "solana")]
#[no_mangle]
fn custom_panic(_info: &core::panic::PanicInfo<'_>) {
log::sol_log("panicked!");
}
};
}<!--StartFragment-->
- 高效的CPI准备
InstructionC结构以及to_meta_c和to_info_c函数提供了一种为 CPI 准备数据的低级、高效的方法: <!--EndFragment-->
let instruction_accounts = [
payer.to_meta_c(),
counter.to_meta_c(),
];
let instruction = InstructionC {
program_id: &system_program::ID,
accounts: instruction_accounts.as_ptr(),
accounts_len: instruction_accounts.len() as u64,
data: instruction_data.as_ptr(),
data_len: instruction_data.len() as u64,
};
let infos = [payer.to_info_c(), counter.to_info_c()
];<!--StartFragment-->
这些函数创建可直接传递给sol_invoke_signed_c系统调用的 C 兼容结构。通过避免 Rust 高级抽象的开销并直接使用原始指针和 C 兼容结构,这些函数最大限度地减少了准备 CPI 的计算成本。这种方法通过减少使用更抽象的 Rust 类型时通常会发生的内存分配、复制和转换来节省 CU。
<!--StartFragment-->
例如,to_info_c方法使用[直接指针算法]有效地构造一个AccountInfoC结构: <!--EndFragment--> <!--EndFragment-->
pub fn to_info_c(&self) -> AccountInfoC {
AccountInfoC {
key: offset(self.inner, 8),
lamports: offset(self.inner, 72),
data_len: self.data_len() as u64,
data: offset(self.inner, 88),
owner: offset(self.inner, 40),
// … other fields …
}
}<!--StartFragment-->
这种对内存布局的直接操作可以非常高效地创建 CPI 所需的结构,从而降低这些操作的 CU 成本。
6. 直接系统调用和不安全的 Rust
这种方法绕过了常见的 Rust 抽象,直接与 Solana 的运行时交互,从而提供了显著的性能优势。然而,它也带来了复杂性,需要谨慎处理不安全的 Rust:
<!--EndFragment-->
// Invoke system program to create account
#[cfg(target_os = "solana")]
unsafe {
solana_program::syscalls::sol_invoke_signed_c(
&instruction as *const InstructionC as *const u8,
infos.as_ptr() as *const u8,
infos.len() as u64,
std::ptr::null(),
0,
);
}<!--StartFragment-->
7.条件编译:
#[(cfg(target_os = “solana”)]属性确保此代码仅在针对 Solana 运行时时编译,这是必要的,因为这些系统调用仅在该环境中可用。
不安全锈蚀的潜在问题
虽然功能强大,但如果处理不当,不安全的 Rust 可能会导致严重问题:
- 内存泄漏和损坏
- 未定义的行为
- 竞争条件
<!--EndFragment--> <!--StartFragment-->
不安全锈蚀的潜在问题
虽然功能强大,但如果处理不当,不安全的 Rust 可能会导致严重问题:
- 未定义的行为
- 竞争条件
为了降低使用不安全的 Rust 时的风险:
- 谨慎使用不安全的块,并且仅在必要时使用
- 记录所有安全假设和不变量
- 利用[Miri]和 Rust 的内置[清理工具]等工具进行测试
- 考虑关键部分的形式化验证技术
- 进行彻底的代码审查,重点关注不安全的块 <!--EndFragment--> <!--StartFragment-->
总结
虽然这一切都很吸引人,但在生产就绪的程序中使用这种超优化方法以确保真金白银却很难让人接受,因为复杂性增加、错误可能性增加以及维护挑战增加。对于大多数应用程序来说,引入严重错误的风险往往超过性能优势。
使用这种方法很可能会让您陷入过早优化的陷阱。
<!--EndFragment--> <!--StartFragment-->
然而,有些事情很容易复制:
- 使用nostd_entrypoint代替 solana_program 臃肿的入口点
- 尽可能使用内联函数
- 尽量减少动态分配并支持基于堆栈的数据结构 <!--EndFragment--> <!--StartFragment-->
结论
本文探讨了 Solana 程序的各种优化级别,从高级 Anchor 开发到具有直接系统调用的低级不安全 Rust。我们已经看到每种方法如何在易用性、安全性和性能之间提供不同的权衡。
关键要点:
- Anchor 提供了一个用户友好的框架,但有一定的性能开销
- 零拷贝反序列化可以显著提高大型数据结构的效率
- 原生 Rust 提供更多控制和优化潜力
- 不安全的 Rust 和直接系统调用提供了最高的性能,但增加了复杂性和风险
优化级别的选择取决于您的具体用例、性能要求和风险承受能力。始终衡量优化的影响,并考虑您的选择对长期维护的影响。
如果您已经读到这里,谢谢您,anon!请务必在下面输入您的电子邮件地址,这样您就不会错过有关 Solana 最新动态的更新。准备好深入了解了吗?
<!--EndFragment--> 作者:GTokenTool 来源:https://www.gtokentool.com





