yGenius:与Yearn对话!
- marcoworms
- 发布于 2024-01-10 10:44
- 阅读 1189
本文介绍了yGenius,一个基于GPT的聊天机器人,旨在通过索引Yearn生态系统的知识为用户提供统一的查询接口。文章详细解释了如何利用gpt_index库将知识库连接到GPT,并探讨了不同索引方法之间的权衡。
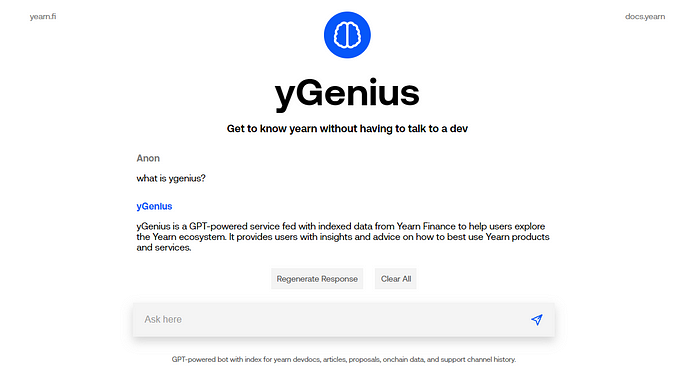
我正在发布一个实验性预览和 yGenius 的代码:一个由 GPT 支持的机器人,它索引了 Yearn 生态系统的知识,以便你可以通过一个通用聊天界面查询它。
- 测试 yGenius: https://ygenius.yearn.farm/
- 前端源代码: https://github.com/yearn/ygenius-webui
- 后端源代码: https://github.com/yearn/ygenius-brain
在本文中,我将解释如何使用 gpt_index 库将你自己的知识库连接到 GPT,并探讨不同索引方法之间的权衡。我想在 Yearn 构建这个的主要原因是我们有很多知识分散在各处,我相信 LLMs 可以提供一个统一的界面,以便我们能够消费并迭代我们生态系统中所有书面内容。
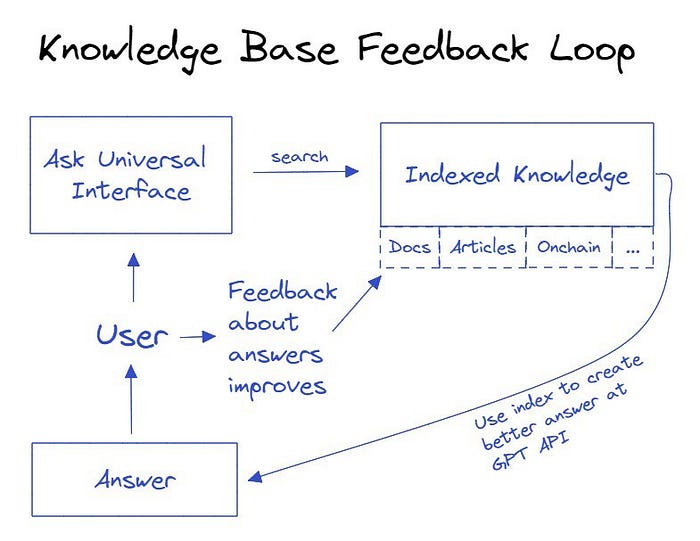
我认为通用接口在迭代已有数据方面是很酷的原因
GPT 的局限性和索引解决方案
GPT-3 当前支持大约 16,000 个字符的单个请求。这包括输入和输出,如果你想问一个需要许多文档供 GPT 消耗和回答的问题,你将很可能会达到此限制。
幸运的是,有一些很棒的人正在开发一个名为 gpt_index 的库。这个强大的工具允许我们索引文档,并且可以与 GPT 结合使用,以丰富查询相关信息。
所以我实现了索引,并将其喂入我们的知识:
- Yearn 博客文章
- Yearn 智能合约代码
- Yearn 官方文档
- Yearn Discord 支持频道历史
- 我们能找到的所有相关 Yearn 数据(vaults TVL、APY 等)
从你所有的知识中创建简单索引
要复制 yGenius 并创建一个简单的机器人,能够根据一组文档回答问题,你需要有基本的 Python 设置和知识:
- 确保你已安装 Python 和 pip。你还需要一个 OpenAI API 密钥 (这里)。
- 安装 gpt_index:
pip install gpt-index - 创建一个新的项目文件夹,比如“my-bot-app”。
- 在“my-bot-app”中创建一个
data文件夹,你可以在其中存放有关你的生态系统的所有文档;这是我们的示例。 - 在“my-bot-app”中创建一个
main.py脚本,内容如下:
import os
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_API_KEY'
## 不要忘记替换上面的 API 密钥!!
## 生成链接: https://platform.openai.com/account/api-keys
from gpt_index import GPTSimpleVectorIndex, SimpleDirectoryReader
## 加载包含所有文件的 'data' 文件夹
documents = SimpleDirectoryReader('data', recursive=True).load_data()
## 创建一个 SimpleVector 索引
index = GPTSimpleVectorIndex(documents)
## 使用提示查询索引
index.query("什么是 yearn?")
## #####################################
## 你可能希望将索引保存到磁盘上,因为
## 从头开始构建一个索引需要太长时间!
## 使用下面的函数进行保存/加载:
## 保存到磁盘
index.save_to_disk('index.json')
## 从磁盘加载
index = GPTSimpleVectorIndex.load_from_disk('index.json')只需 6 行代码,你的索引就准备好了,并且你已经对其进行了查询!如果你精通 Python,你可以改进上述脚本,使其在构建时保存索引,以便每次运行应用程序时都能加载它。创建索引很慢,对于非向量索引,它也可能很昂贵!OpenAI API 按字数收费,构建索引的昂贵方法将发送更多且更大的请求。
不同类型的索引及其权衡
在上述示例中,我使用了 GPTSimpleVectorIndex,这是一种“向量存储索引”。你可以使用许多其他索引,根据你的查询,更改它们可能是有意义的。以下是每种索引类型的官方文档链接:
让我们进一步探讨向量存储和列表索引:
Vector Store Index
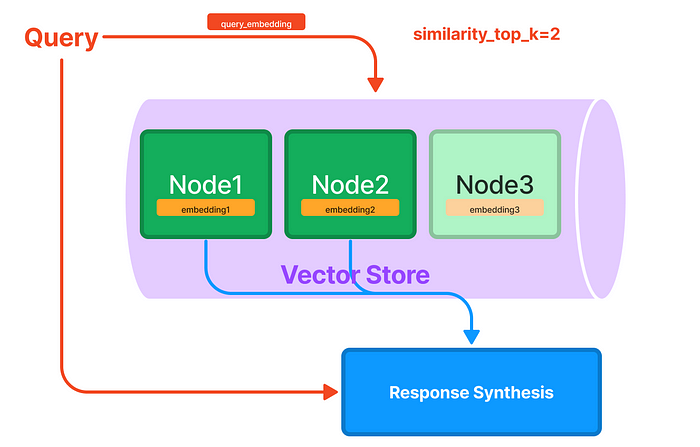
当你查询一个向量存储索引时:
- 用户查询被发送到 OpenAI 进行 嵌入。
- 使用此嵌入搜索本地存储的数据,以找出向量索引的哪个部分可能包含回答问题的相关信息。
- 然后,用户查询再次发送到 OpenAI,但这次带有相关的信息片段,希望能够组成一个更好的答案,而不仅仅是问 GPT,没有任何上下文。
向量存储使用便宜,适合创建问答服务!这是我在此首次发布 yGenius 时所使用的。
List Index
如果你需要索引中包含的所有文本来创建答案,则列表索引会更好。在向量存储中,我们仅发送相关部分给 OpenAI 来构建结果,但对于列表索引,我们将发送整个文本块到 OpenAI 来完善答案。
当你查询列表索引时:
- 假设你有 100 万个字符的文本,而 GPT API 一次只能处理 10,000 个字符(保留 6,000 个字符作为构建答案的空间)。你需要 100 块 10,000 个字符的文本才能将所有信息发送给 OpenAI。
- 所以 GPT 索引将用户查询加上第一个文本块发送给 OpenAI 以获取答案。
- 然后,它将用户查询加上当前答案加上第二个块加上一个指令,比如
尝试使用该文本块完善当前答案。 - 然后它将为每一个索引块重复上述步骤,在所有索引块中完善答案,直到没有更多块可以帮助创建答案。
列表索引用于查询非常昂贵,但它们可以完成很棒的任务,比如为大量文本创建完整的摘要,而向量存储无法完成。

组合索引以获得更智能的答案
有一个概念让我感到震惊(同时也让我的钱包受到了冲击),那就是 “索引组合性”。你还能够在图中组合索引,可以将任何类型的索引连接为另一个的子索引。此外,我们可以为每个索引提供摘要,以便当查询到达时,机器人能够更好地搜索组合索引中的相关答案。
在组合索引时,由于每个索引都有其自身的成本权衡,因此潜在的查询成本可能会增加,但是由于你对文档进行了结构化,从而使机器人在解析时更高效,答案的质量可能会提高。目前,由于成本问题,即使仅使用向量存储索引,我仍未找到在首次发布中使用组合索引的方法。
例如,以下是 gpt_index 文档如何创建一个包含多个 TreeIndexes 的 ListIndex 并使用 GPT 自动生成摘要:
## 创建多个索引
index1 = GPTTreeIndex(doc1)
index2 = GPTTreeIndex(doc2)
index3 = GPTTreeIndex(doc3)
## 使用 GPT 为索引设置摘要
summary = index1.query(
"这份文档的摘要是什么?", mode="summarize"
)
index1.set_text(str(summary))
## 为你想要设置摘要的所有其他索引重复上述步骤
## 创建包含所有其他索引的父索引
list_index = GPTListIndex([index1, index2, index3])
## 将其全部包装到一个图中,以便我们可以同时查询它们
graph = ComposableGraph.build_from_index(list_index)
## 执行查询
response = graph.query("作者在哪里长大?")使机器人具有聊天历史上下文
机器人的另一个重要部分是它应该知道当前对话状态,以便它听起来像是在与某个东西聊天,因为你可以参考旧消息,比如:
- 匿名: 什么是 yswaps?
- yGenius: 它是 […]
- 匿名: 给我更多细节
- yGenius: 当然,yswaps […]
在第二条消息中,匿名不需要告诉 yGenius 他想要更多有关哪个服务的细节,因为它知道他们之前是在讨论“yswaps”。
这样做其实非常简单。在每个用户查询中,我都会将历史记录与查询一起发送到后端。以下是我如何查询索引的。
######### 与匿名用户的聊天历史记录以获取上下文
CHAT_HISTORY_WITH_USER
######### 当前与匿名用户的交互作为 yGenius(一个通过 Yearn 财务的索引数据支持的 GPT 机器人,帮助用户探索 Yearn 生态系统)
问题: USER_CURRENT_QUESTION
回答:将 CHAT_HISTORY_WITH_USER 和 USER_CURRENT_QUESTION 更改为来自前端查询的变量。在我们的 yswaps 示例中的最后一个查询将看起来像这样:
######### 与匿名用户的聊天历史记录以获取上下文
问题: 什么是 yswaps?
回答: 是的 [...]
######### 当前与匿名用户的交互作为 yGenius(一个通过 Yearn 财务的索引数据支持的 GPT 机器人,帮助用户探索 Yearn 生态系统)
问题: 给我更多细节
回答:你必须注意控制历史和输入的最大大小。在 yGenius 中,我为输入留了 4K 字符,为历史记录留了 4K 字符。
GPT-4 128k 发布后的更新
本文和 ygenius 仍然有用,但可能有新的方法构建 AI 机器人,它们可能不再需要向量存储。我为智者机器人设计了一个新的结构,只使用 gpt4 128k tokens API,你可以在这里查看: https://github.com/ApeWorX/apegenius
致谢
- 非常感谢 Poma 帮助我导航索引相关的内容!
- 我最初在查看这个 futurekarol 帖子 后开始寻找索引相关的内容。
- 感谢 jerryjliu 开发了 gpt_index 以及所有 贡献者 的帮助,使其不断改进!
- 以及感谢 Yearn 的优秀团队,他们总是帮助进行测试、审查,克服技术障碍。

yGenius 说:“嘿,匿名,我注意到你已经读完了这篇文章,谢谢你的阅读!”
- 原文链接: medium.com/@marcoworms/y...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,在这里修改,还请包涵~





