在 Jupyter 和 Colab 中将 Vyper 连接到你的钱包
- daniel.schiavini
- 发布于 2024-01-18 11:40
- 阅读 1491
文章介绍了如何将Vyper智能合约编程语言与JupyterLab和Google Colab笔记本连接,使用户能够直接从笔记本中与智能合约交互并部署新合约。通过浏览器钱包进行地址和支付,解决了私钥在不安全环境中暴露的问题。
在过去几周,我一直在致力于实现 Vyper 智能合约编程语言与基于网络的互动平台 JupyterLab 笔记本之间的连接。
这使得用户可以从他们的笔记本与智能合约交互并直接部署新的智能合约。地址和支付通过他们浏览器中的钱包完成!
Twitter 嵌入

·
google colab 成为 vyper 合约的部署环境 
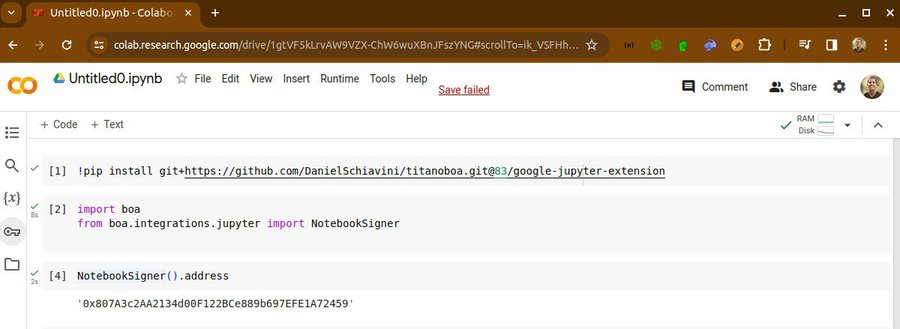
复制链接
Twitter 组件 Iframe
Vyper 团队在 Twitter 上分享成果
这并不是一项简单的任务,我在这个过程中学到了很多。人们在 Twitter 上对此感到非常高兴,因此我认为分享一些我的发现是个好主意。
你在说什么?
在我们深入探讨之前,连接一下这里涉及的一些技术可能是明智的:
- Vyper 是一种 Python 风格的编程语言,用于编写运行在以太坊虚拟机上的智能合约 ( EVM)
- Titanoboa (boa) 是一个 Vyper 解释器,允许用户从 Python 直接与 Vyper 合约进行交互
- Jupyter Notebook 是一个可共享的文档,结合了计算机代码、普通语言描述、数据、丰富的可视化(如 3D 模型、图表和图形)。该平台在数据科学社区中使用广泛。
- Google Colab 是一个托管的 Jupyter Notebook 服务,无需设置即可使用,并提供对计算资源的免费访问。
- Ethers.js 是一个前端库,用于与以太坊区块链及其生态系统进行交互。我们主要使用它来与浏览器中的加密钱包进行交互,例如 Rabby、Metamask 和任何实现 EIP-1193 的插件。
为什么这对你有用?
用户已经使用 boa 部署合约有一段时间了。然而,当使用笔记本时,唯一签署交易的方法是在不安全的环境中暴露私钥。
通过实现一个使用浏览器钱包的插件,可以做到让私钥不需要离开用户的设备。当连接到硬件钱包时,用户将能够完全不用在机器上存储私钥即部署合约。
起点
说实话,Charles Cooper 已经创建了一个 Vyper 插件。人们一直在使用和分享 Jupyter 笔记本;然而,这不适用于 JupyterLab,只能在较旧版本的 Jupyter 中工作。此外,该插件使用了一些非常“魔咒的代码”,不应该被碰触 😱

是的,_很_难让笔记本等待前端回调。
Jupyter 版本
自 2022 年以来,Project Jupyter 正在迁移 借助 v6 的过时时间默认平台(即 nbclassic)转向更可持续和现代化的平台(即 v7,JupyterLab)。
然而,Google Colaboratory(别名 Colab)仍然使用可能自定义的 notebook v6 版本。此外,Google 在 Jupyter 之上开发了许多工具,使这两种环境发生了显著的分歧。
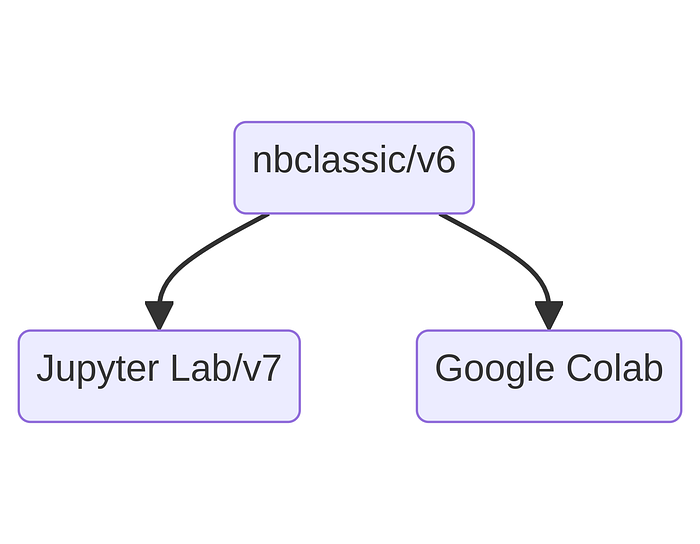
不同的 Jupyter 版本
它是如何工作的?
现有的 Vyper 插件只支持较旧的 notebook 版本,并使用 Jupyter 的“Comms”机制在前端 JavaScript 和后端 Python 之间进行通信。
下面的图中展示了这一点。请注意,为了使 Python 接收来自钱包的任何信息,它必须等到通过 comms 接收到异步回调。在那之前,笔记本保持在一个轮询循环中,等待消息。
这种“等待”代码导致必须干扰 Python 的内部 asyncio 。
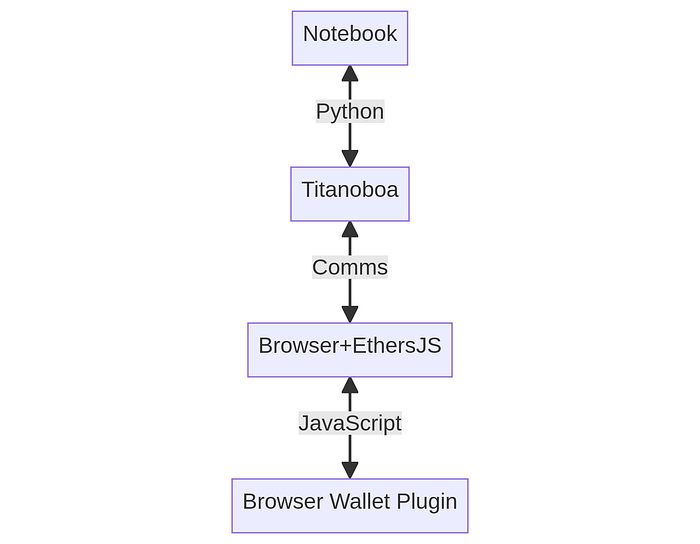
旧插件中通信的工作原理
新的 JupyterLab 插件
虽然旧的 Jupyter 版本使用 comms 抽象在浏览器和笔记本之间进行通信,但 JupyterLab 正在转向一个更可扩展的解决方案,使用实际的 npm 和 pip 包。
模板
Jupyter 提供了一个模板项目,具有良好的用户体验。这是我尝试使用的第一件事,结果可以在这个分支中找到。新的插件系统使得前端和后端代码更加清晰地分离。它具有更广泛的隔离和集成测试的可能性。
使用共享内存而不是 comms
内核不再像以前那么直接可用,这对于打开一个新的 comm 目标是必要的。相反,应该创建几个 HTTP 端点,这些端点将添加到 Notebook 中,以及在浏览器中执行并向新端点发送 HTTP 请求的 JavaScript 库。
不过,请注意,内核和 HTTP 服务器不是在同一进程中运行。为了允许它们之间某种形式的通信,我发现最简单的解决方案是在内核和服务器之间构建一段共享内存。具体如下:
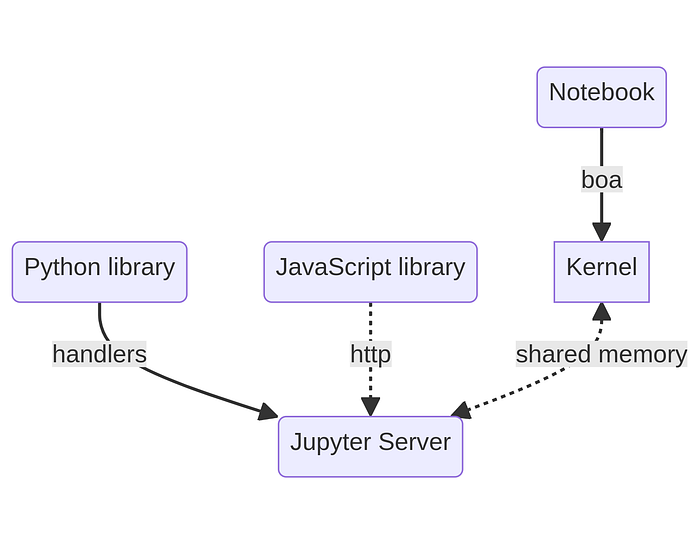
新插件中通信的工作原理
所以当你在笔记本中运行:
from boa.integrations.jupyter import BrowserSigner
BrowserSigner().addressBrowserSigner 将创建一块共享内存,并等待一个回调 ( 完整代码):
## 创建共享内存
token = _generate_token()
memory = SharedMemory(name=token, create=True, size=memory_size)
## 在前端调用 JavaScript 函数
Javascript(f"window._titanoboa.loadSigner('{token}');")
## 现在等待内存被设置
while buffer.tobytes().startswith(NUL):
if inner_loop.time() > deadline:
raise TimeoutError(timeout_message)
await sleep(0.01)在前端,loadSigner 函数询问用户的同意,然后向服务器发送 HTTP 请求,并带上收到的签名。
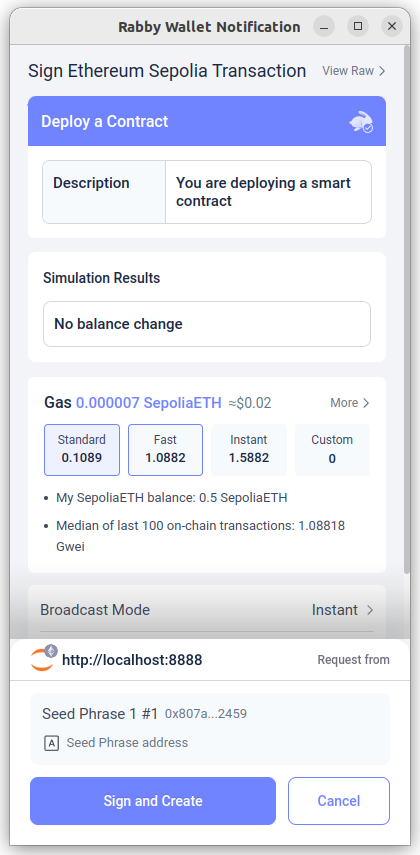
Rabby 确认部署的弹出窗口
测试与发布
在所提供的模板中,前端代码被发布到 npm 包,后端则发布到 pip 包。包含自动测试和发布的 GitHub Actions。
在花了一些时间让包含的 GitHub Actions 正常工作后,我意识到模板不必要且有些过于复杂,因为它要求发布 和安装 npm 和 pip 包。
相反,我决定将前端代码放在 boa 存储库中的一个单独文件里;这样我们就不需要一个单独的前端插件,只需要一个服务器插件便可以使新的 JupyterLab 集成工作。由于我们可以将代码放入 boa 包,因此没有必要创建新的 pip 或 npm 包。
需要注意的是,我们仍然需要创建一个新的测试策略来自动化测试此代码。
调整插件以在 Colab 中工作
我在这一点上实现的插件要比现有解决方案简单得多并且在 Jupyter Lab 中运行良好,但在 Google Colab 中不行。
虽然在 Google Colab 中可以运行 !pip install titanoboa 和 !jupyter serverextension enable boa,但服务器扩展中的新端点不会变得可用。它需要 Jupyter 重启,但会清除你的安装。
官方方法
Google 实际上在 Jupyter Notebook 之上构建了一些功能;即使它们没有很好地记录, eval_js 函数 正是我们需要的,以便与前端进行通信。
这大大简化了插件实现,因为整个 HTTP 和共享内存机制都不再必要。我们只需在 Python 中直接在 BrowserSigner 运行 eval_js,Google 处理等待承诺结果。
然而,Colab 的回调是在沙盒内执行的。每当我们需要与前端通信时,都会创建一个新的 iframe,我们的 JavaScript 代码将被删除。
经过大量测试,我最终设法在这个沙盒中让 Colab 工作;我们确实需要为每个回调注入 Ethers 代码,但那是可行的。
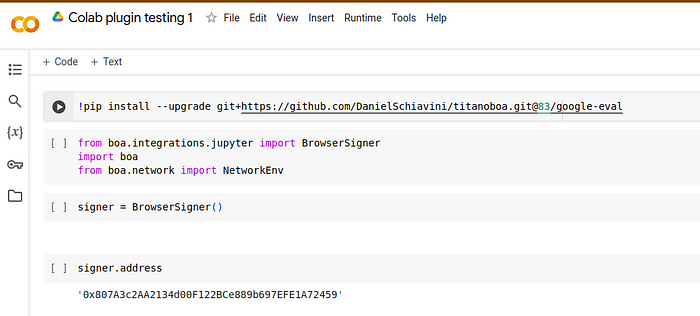
插件在 Google Colab 中的运行效果
它已准备好审查
这里是拉取请求,包含实现!任何反馈或改进建议总是欢迎。
拉取请求的截图
- 原文链接: medium.com/@daniel.schia...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 以太坊
- 标签: Vyper JupyterLab Google Colab 智能合约 EVM ethers.js





