99%容错共识指南
- Vitalik Buterin
- 发布于 2018-08-09 16:19
- 阅读 1681
这篇文章详细介绍了一种能够实现99%容错共识的算法,探讨了在不同假设下共识算法的容错能力如何随着参与者和观察者的配合而增强。文章从基本概念出发,逐步深入展示了具体算法的步骤,包括如何通过签名的使用实现信息传播的时效性,以及如何与现有的共识算法相结合以提高稳定性和容错性。
99% 故障容忍共识指南
感谢 Emin Gun Sirer 的审阅
我们早已听说,在同步网络中,如果任何诚实节点广播的消息能够在一些已知时间段内被所有其他诚实节点接收到,便可以实现 50% 的故障容忍(如果攻击者拥有 超过 50% 的节点,他们可以执行“51% 攻击”,这种类型的算法也有类似的情况)。我们也早就听闻,如果想要放宽同步假设,并让算法在非同步环境下“安全”,那么最大可达的故障容忍度将降至 33% (PBFT、Casper FFG 等算法均属于此类别)。但是你知道吗,如果添加更多假设(具体来说,你要求观察者,即那些并不积极参与共识但关心其输出的用户,也要在整个共识过程中积极观察,而不仅仅是在事后下载其输出来),就可以将故障容忍度提升到 99%?
事实上,这一事实早已为人所知;莱斯利·兰波特(Leslie Lamport)在 1982 年的著名论文《拜占庭将军问题》(链接这里)中描述了该算法。以下是我对该算法进行描述和改写的尝试,尽量简化。
假设有 N 个参与共识的节点,所有人事先达成一致这些节点是谁(根据情况,这些节点可以通过一个信任方选择,或者如果需要更强的去中心化,可以通过某种工作证明或股权证明方案选择)。我们将这些节点标记为 0 至 N-1。此外,假设网络延迟加上时钟差存在一个已知的界限 D(例如,D = 8 秒)。每个节点可以在时间 T 发布一个值(恶意节点当然可以在早于或晚于 T 的时刻提出值)。所有节点等待 (N−1)⋅D 秒,运行以下过程。定义 x:i 为“节点 i 签名的值 x”,x:i:j 为“节点 i 签名的值 x,以及节点 j 对该值和签名的共同签名”,依此类推。在第一阶段发布的提案形式为 v:i,其中包含提案节点的签名。
如果验证者 i 收到某个消息 v:i[1]:...:i[k],其中 i[1]...i[k] 是已(按顺序)对该消息签名的索引列表(只有 v 本身属于 k=0,而 v:i 则属于 k=1),那么验证者检查 (i) 时间是否小于 T+k⋅D,(ii) 他们尚未看到包含 v 的有效消息;如果两个检查都通过,他们便发布 v:i[1]:...:i[k]:i。
在时间 T+(N−1)⋅D 处,节点停止监听。在这一时刻,保证所有诚实节点都“有效地看到了”同一组值。
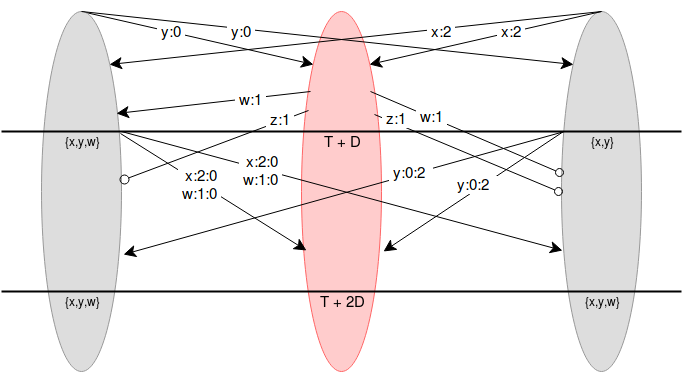
如果问题需要选择一个值,他们可以使用某种“选择”函数从他们所见值中选出一个单一的值(例如,他们可以选择哈希值最低的那个)。节点随后可以就此值达成一致。
现在,让我们探讨为何这能奏效。我们需要证明的是,如果一个诚实节点看到了一个特定的值(有效地),那么每个其他诚实节点也都看到了这个值(如果我们能证明这一点,那么我们就知道所有诚实节点看到了同一组值,因此如果所有诚实节点运行相同的选择函数,他们将选择相同的值)。假设任意一个诚实节点收到了他们认为有效的消息 v:i[1]:...:i[k](即它在时间 T+k⋅D 之前到达)。假设 x 是另一个诚实节点的索引。要么 x 属于 i[1]...i[k],要么不属于。
- 在第一种情况下(假设 x=i[j]),我们知道诚实节点 x 已经广播了该消息,他们是在接收到带有 j−1 个签名的消息并在时间 T+(j−1)⋅D 之前做出响应后广播该消息的,因此他们在那个时间广播了他们的消息,所以该消息必须在 T+j⋅D 之前被所有诚实节点接收到。
- 在第二种情况下,由于诚实节点在 T+k⋅D 之前看到该消息,那么他们将会用自己的签名广播该消息,并保证包括 x 在内的每个人都将在 T+(k+1)⋅D 之前看到它。
请注意,算法通过添加自己的签名作为对消息超时的一种“提升”,并且这种能力保证了如果一个诚实节点及时看到一个消息,他们能够确保所有其他人也能及时看到该消息,因为“及时”的定义随着每个添加的签名的增加而以超过网络延迟的速度递增。
在一个节点是诚实的情况下,我们能否保证被动观察者(即关心了解结果但未参与共识的节点)可以看到结果,即使我们要求他们全程观察这个过程?按照上述方案,有一个问题。假设一个指挥官和一些 k 个(恶意的)验证者产生了一条消息 v:i[1]:....:i[k],并在时间 T+k⋅D 之前将其直接广播到一些“受害者”。受害者将看到该消息是“及时”的,但当他们重新广播它时,仅在 T+k⋅D 之后才到达所有诚实的共识参与节点,因此所有诚实的共识参与节点会拒绝该消息。

但是我们可以填补这个漏洞。我们要求 D 是 两倍 的网络延迟加上时钟差的界限。接着,我们给观察者设定一个不同的超时:观察者在时间 T+(k−0.5)⋅D 之前接受 v:i[1]:....:i[k]。现在,假设观察者接受到一个消息。作为观察者,他们将能够在时间 T+k⋅D 之前将其广播给一个诚实节点,而诚实节点将签名该消息,这会在时间 T+(k+0.5)⋅D 之前到达所有其他观察者,即具有 k+1 个签名的消息的超时。

适配到其他共识算法
上述算法理论上可作为独立的共识算法使用,甚至可以用来运行一种股权证明区块链。第 N+1 轮共识的验证者集合可以在第 N 轮共识时决定(例如,每轮共识也可以接受“存款”和“提取”交易,如果这些交易被接受并且签名正确,则会在下一轮中添加或删除验证者)。需要增加的主要成分是决定谁可以提出区块的机制(例如,每轮可以有一个指定的提议者)。它还可以被修改为可用于工作证明区块链,通过允许参与共识的节点通过在其公钥上实时发布一个工作证明解决方案的同时对消息进行签名来“申报”自己。
然而,同步假设非常强,所以我们希望在不需要超过 33% 或 50% 故障容忍的情况下能够不依赖于它。可以通过以下方式来实现此目标。假设我们有某种其他共识算法(例如 PBFT、Casper FFG、基于链的 PoS),其输出 能够 被偶尔在线的观察者看到(我们将这一算法称为阈值相关共识算法,而将上述算法称为延迟相关共识算法)。假设阈值相关共识算法以持续的模式运行,以始终将新块“最终确定”到链上(即每个最终值指向一些先前的最终值作为“父节点”;如果存在一系列指针 A→...→B,则我们称 A 为 B 的后代)。
我们可以将延迟相关算法适配到这个结构上,让始终在线的观察者访问一种关于检查点“强最终性”的方式,其故障容忍度约为 95%(通过增加更多的验证者并要求过程耗时更长,可以将其推至接近 100%)。
每当时间达到某个 4096 秒的倍数时,我们运行延迟相关算法,选择 512 个随机节点参与该算法。有效的提案是由阈值相关算法最终确定的任何有效值链。如果某个节点在时间 T+k⋅D(D = 8 秒)之前看到了带有 k 个签名的某个最终值,它会将该链纳入其已知链集,并加上自己的签名重新广播;观察者使用 T+(k−0.5)⋅D 作为阈值。
最后使用的“选择”函数非常简单:
- 忽略不属于先前轮中已被认为是最终值的后代的最终值
- 忽略无效的最终值
- 在两个有效的最终值之间选择哈希值较低的那个
如果 5% 的验证者是诚实的,所有 512 个随机选择的节点中没有一个节点是诚实的概率大约为 1/1 万亿,因此只要网络延迟加上时钟差小于 D2,上述算法可以工作,正确协调节点达成某个单一的最终值,即使同时提出多个冲突的最终值,因为阈值相关算法的故障容忍度被打破。
如果阈值相关共识算法的故障容忍度得以满足(通常为 50% 或 67% 诚实),则阈值相关共识算法要么不会最终确定任何新的检查点,要么就最终确定互相兼容的新检查点(例如一系列检查点,每个检查点都指向前一个作为父节点),因此即便网络延迟超过 D2(甚至 D),并且作为结果参与延迟相关算法的节点对他们接受的值存在不同意见,所接受的值仍然保证是同一链的一部分,因此不存在真正的分歧。一旦延迟恢复正常,在未来的轮次中,延迟相关共识将重新“同步”。
如果同时打破了阈值相关和延迟相关共识算法的假设(或者在连续的轮次中),那么该算法可能会崩溃。例如,假设在某一轮中,阈值相关共识最终确定 Z→Y→X,而延迟相关共识在 Y 和 X 之间有分歧,而在下一轮中,阈值相关共识最终确定 W 作为 X 的后代,而 W 并不是 Y 的后代;在延迟相关共识中,达成一致的 Y 的节点将不会接受 W,而达成一致的 X 的节点将会接受。但是,这是不可避免的;关于在超过 13% 的故障容忍度的情况下实现安全的非同步共识是不可能的这一结果是众所周知的,即便是允许同步假设但假设离线观察者的情况下,超过 12% 的故障容忍度也是不可能的。
- 原文链接: vitalik.eth.limo/general...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





