Filecoin 二阶段测试(1) - 小试牛刀
- 阳建
- 发布于 2020-06-30 15:27
- 阅读 6568
万众期待的 Filecoin 二阶段测试已经如火如荼的进行 2 周了。由于客户的机器没有到位,而 Filecoin 矿机如此昂贵的价格又不是我们这种屌丝能支付得起的,故而我们这周才进行的测试。
系列导航: Filecoin 二阶段测试(1) - 小试牛刀 Filecoin 二阶段测试(2) - AMD CPU 的胜利 Filecoin 二阶段测试(3) - 异构集群测试
他强由他强,清风拂山岗; 他横由他横,明月照大江; 他自狠来他自恶,我自一口真气足。 ---- 金庸《倚天屠龙记》
我想用金老爷子的这句话来表达我对当前 Filecoin 测试网百矿争霸的态度,做一个纯粹的测试者,在主网算法确定或者上线之前,安安静静的测试,以不变应万变就好。
万众期待的 Filecoin 二阶段测试已经如火如荼的进行 2 周了。由于客户的机器没有到位,而 Filecoin 矿机如此昂贵的价格又不是我们这种屌丝能支付得起的,故而我们这周才进行的测试。
虽然测试的结果不尽人意,但是还是想把测试结果记录下来,供有心加入二阶段测试的同学参考。
另外,我们在参与二阶段之前,也把一阶段的测试的结果录制了视频上传到 Bilibili 了, 下面是视频链接:Filecoin 一阶段挖矿测试回放
本次测试我们覆盖了各种测试架构。比如在挖矿架构上我们分别测试了单机挖矿和集群挖矿;在存储上我们分别测试了 Ceph 存储,Raid0, Raid5, LVM;CPU 我们分别测试了 AMD 和 Intel的,
GPU 有使用 2080Ti,也有使用 2070SUPER等。
sector 逻辑处理逻辑变化
二阶段测试 sector 处理的逻辑相对一阶段的发生了一些变化,我觉的在正式开始测试之前我们得先了解这些变化。
首先,我觉得最大的变化就是算法从之前的 window SDR 变成了 SDR,至于什么是 window SDR 和 SDR 这个我们后面再解释。
第二个比较大的变化是 Sector Precommit 过程分为了两个阶段,分别是 phase1 以及 phase2, 也就是大家都一直在说的 阶段1(P1)和阶段2(P2)。
Phase1 的过程主要是两部分的计算:
-
计算原始数据的merkle树(二叉树,sha256 hash计算)
-
label,也就是SDR的计算。原始数据的merkle树(tree_d),树根为comm_d。
Phase2 的过程主要也是两部分的计算
-
column hash
-
针对column hash的计算结果生成merkle树(八叉树,poseidon hash计算)3)针对label的计算结果,再做一次encoding,生成merkle树(八叉树,poseidon hash计算)。
column hash的计算过程如下:
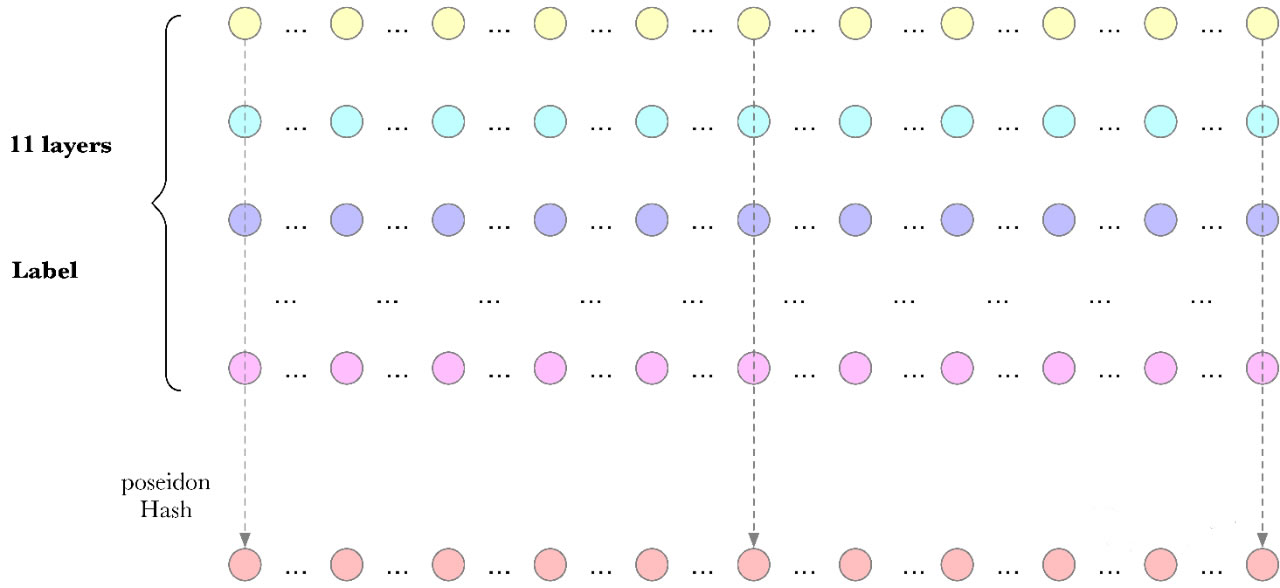
- 32GB 的Sector,分割成 1G 个 node。SDR 的计算会生成11层的处理数据,每层都为 32GB。每层的同一个编号的 node 数据,
组合在一起后的 hash 的结果就是 column hash 的计算结果。Column hash 的计算结果也是 32GB。
-
针对
column hash的计算结果,生成八叉树(tree_c),树根为comm_c。 -
label encoding的计算是将 SDR 的计算结果和原始数据进行 encoding。所谓的 encoding,目前就是大数的加法。
encoding 的结果,生成八叉树(tree_r_last),树根为 comm_r_last。
- 上链的数据是两个:
comm_d和comm_r。其中,comm_r是comm_c和comm_r_last的 posedion 的 hash 结果。
测试环境
- 系统版本:Ubuntu-18.04LTS
- Lotus 版本:
0.3.0'+gitf86a2ce'+api0.3.0
集群测试
本次集群测试我们还使用了一阶段的那 5 台机器,就是内存升级到了 380GB。具体配置如下:
Miner 配置
- CPU: Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz
- RAM: 512GB + 512GB Swap
- GPU: GeForce RTX 2080Ti x 1
- 存储: Ceph 存储
- cache: 1TB SSD
- 网卡: 万兆网卡 x 2
Worker 配置
- CPU: Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz
- RAM: 380GB + 128GB Swap
- GPU: 无
- 存储: 8TB 企业硬盘
- cache: 无
- 网卡: 万兆网卡 x 1
单机测试
另一个客户的机器配置稍微低一些,所以我们就做了单机测试:
- CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
- RAM: 128GB + 128GB Swap
- GPU: GeForce RTX 2080Ti x 1
- 存储: Ceph 存储
- cache: 1TB SSD
- 网卡: 万兆网卡 x 1
测试结果
我们这次测试 Intel 的机器几乎没有一个成功提交了 1 个扇区的。虽然都慢吞吞的做完了 P1 和 P2,但是无例外的都超时了,抛出了 ticket expire 异常,也就是没有在规定的时间窗口内提交完成。
2020-05-25T12:24:35.697Z ^[[33mWARN^[[0m sectors storage-fsm@v0.0.0-20200427182014-01487d5ad3c8/fsm.go:308 sector 0 got error event sealing.SectorSealPreCommitFailed: ticket expired: ticket expire d: seal height: 28261, head: 36609
2020-05-25T12:24:42.355Z ^[[34mINFO^[[0m sectors storage-fsm@v0.0.0-20200427182014-01487d5ad3c8/states_failed.go:19 SealFailed(0), waiting 52.644495636s before retrying
2020-05-25T12:25:35.015Z ^[[34mINFO^[[0m sectors storage-fsm@v0.0.0-20200427182014-01487d5ad3c8/states.go:70 performing sector replication... {"sector": "0"}
2020-05-25T12:25:35.022Z ^[[35mDEBUG^[[0m advmgr sector-storage@v0.0.0-20200513185232-4051533cc4bd/localworker.go:66 acquired sector {233294 0} (e:1; a:0): {0 0} /gamma/lotus-storage-miner/ data/unsealed/s-t0233294-0 }
2020-05-25T12:25:35.022Z ^[[34mINFO^[[0m stores stores/local.go:345 remove /gamma/lotus-storage-miner/data/sealed/s-t0233294-0
2020-05-25T12:25:35.023Z ^[[34mINFO^[[0m stores stores/local.go:345 remove /gamma/lotus-storage-miner/data/cache/s-t0233294-0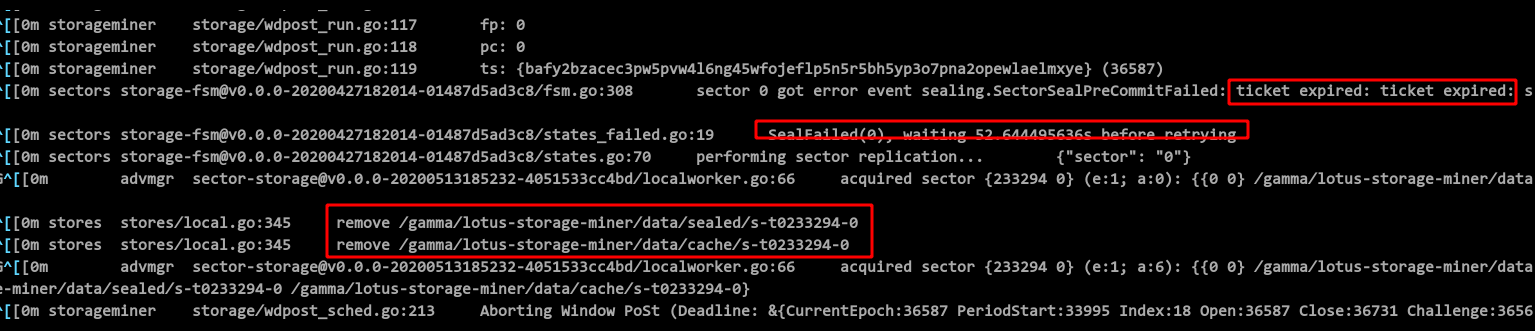
<div class="custom-block tip">
事实上,本次测试 Intel 的机器跑 P1 几乎都要超过 30 个小时,而且几乎没有单独用 Intel 机器成功提交的,最多也是 AMD 和 Intel 的异构集群。
</div>
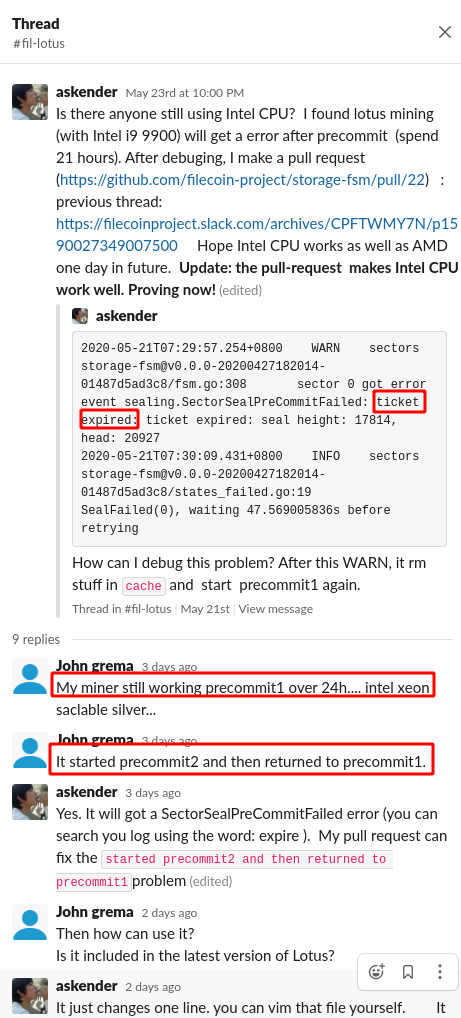
测试结果数据如下:
| 机器配置 | Precommit 1 | Precommit2 |
|---|---|---|
| 集群 | 36h5min | 2h10min |
| 单机 | 49h29min | 3h5min |
小结论
(1) 每个 Sector 密封只能占用一个 CPU,用官方的话来说就是:P1 只能单核滑行(滑行二字相当贴切),所以 P1 的速度慢让人无法忍受。Intel 的机器基本都需要 30 个小时以上的,稍微差点的机器都到 40 多个小时了。
(2) 想要批量做 Precommit 的话,内存要够用,目前我们 380GB 的内存,最多只能同时密封 6 个 sector, 256 GB 是 3 个,多了就会报物理内存不足的错误了。
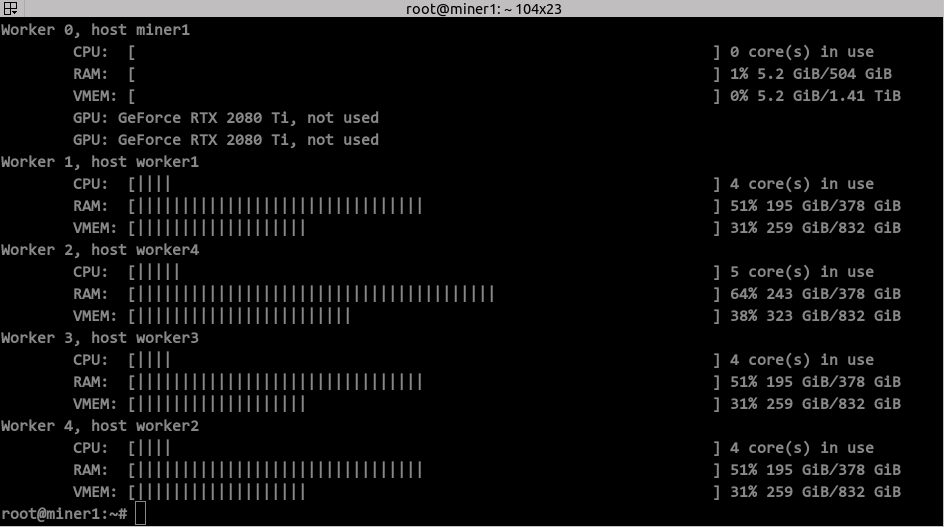
(3) 总体来看,Intel 虽然做 P1 不怎么行,速度几乎不到 AMD 3960x 的五分之一,但是做 P2 速度还是不错的,配合 GPU 加速,跟 AMD 的差距不大。
(4) 如果 Worker 搭载的比较多并且你打算用 Miner 做 P2 的话,Miner 的内存就要配的高一点,否则会内存溢出。就拿我们的 Miner 来说,512GB 的 RAM + 512GB 的 Swap 在同时做 8 个 P2 的时候还是挂了。

记住:千万不要指望多加点 Swap 能起到什么作用,根据我们的测试观察,Swap 最多用到 128GB,一般都不会用到 64GB,然后就给你报内存不足,或者内存溢出了。****
下面是矿工整理的 Lotus 每个阶段的内存需求计算公式,供大家参考:
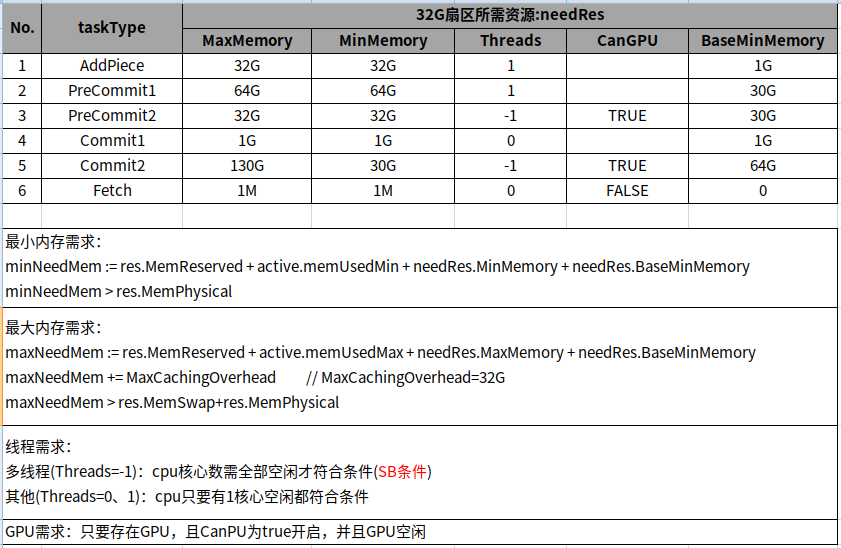
window SDR, SDR AND NSE
这里简单介绍一下 window SDR,SDR 以及 NSE,了解过的同学请略过。
window SDR
一阶段测试启用的 Sector 复制证明算法。window SDR 算法中的 window,就是每个 Sector 的数据,先分割成一个个 128M 的 window。
一个 32G 的 Sector 会划分成 256 个 window。window 和 window 之间相互独立。每个 window,单独进行 SDR 的计算(labeling encode)。总共需要做 4 层(layer)。
也就是说,独立的 window 之间,需要做 4 层运算。层与层之间满足 SDR 的关系。
SDR
相对 window SDR,SDR 的算法更加简单和粗暴一些。一个 Sector,再也不划分 window。整个 Sector,进行 SDR 的计算,并且计算 11 层。
贴一张日志图大家感受一下:
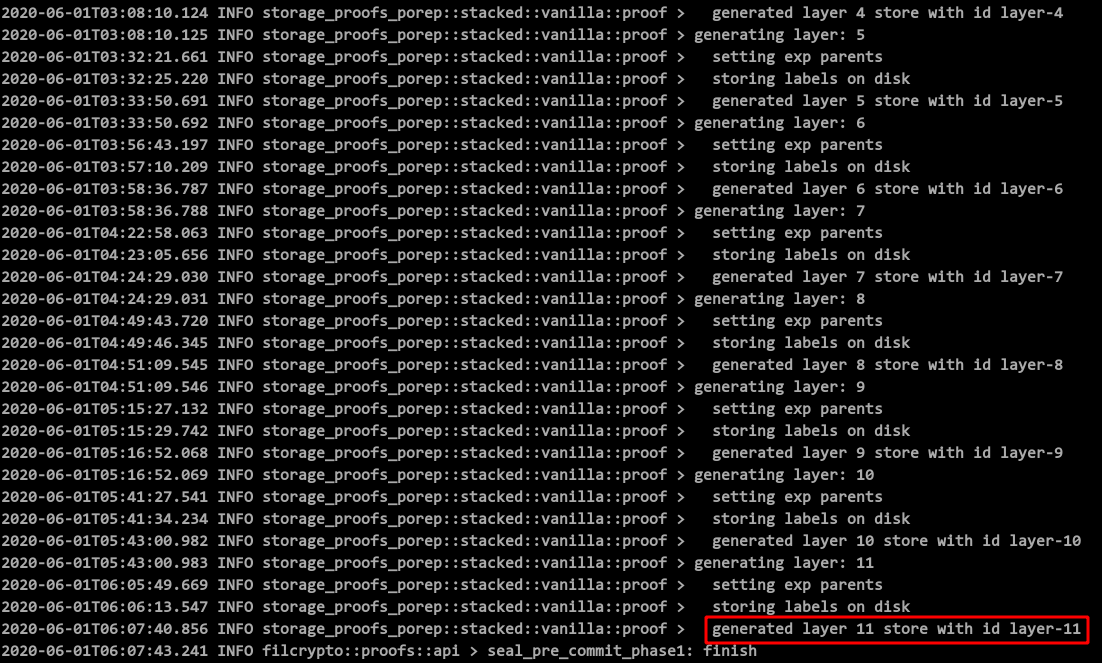
NSE
NSE 是最新的 PoREP 算法。NSE算法的全称:Narrow Stacked Expander PoRep。
源码地址:https://github.com/filecoin-project/rust-fil-nse-gpu
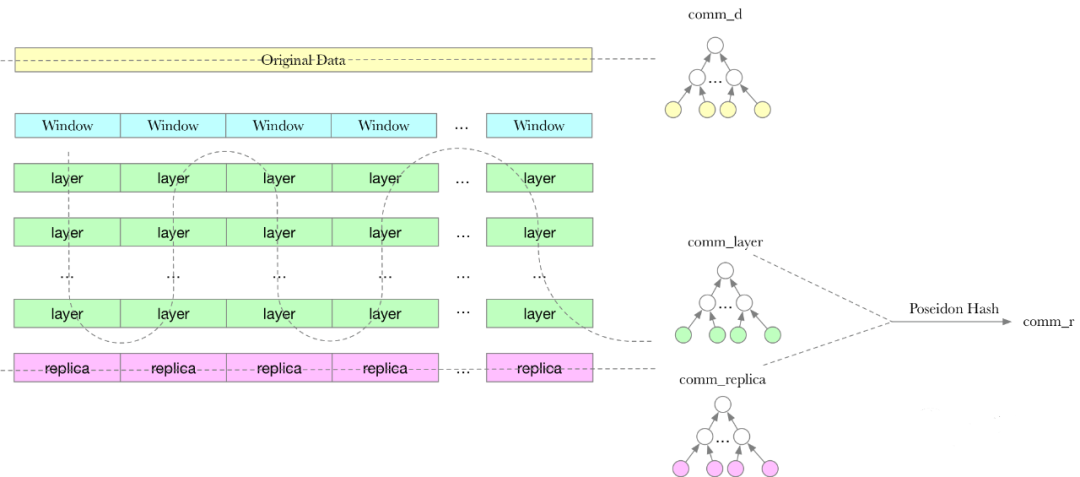
NSE,之所以称为 NSE,因为N,Narrow。Narrow 的意思是比之前的SDR算法,窄,每次处理的数据为一个 Window。
每个 Window 经过层层的处理,都会生成对应的 Replica。所有 Window 对应的每一层的数据一起构建成 Merkle 树。所有 Window 对应的 Replica 的数据也一起构建成 Merkle 树。
这两棵树树根的 Poseidon Hash 的结果作为 comm_r。comm_d 以及 comm_r 是需要上链的数据。
整个算法流程如下图所示:
这里需要提一下的是,貌似 NSE 在主网上线之前都不会启用的
适合小白的测试调优
Slack 上有很多矿工分享了如何优化挖矿效率的方法,但是大部分都涉及到改代码的,虽然有的改的很少,那些人都声称很容易改。但是你改起来就会发现,没那么容易。
事实上,Lotus 的代码极其复杂,如果你不了解整个挖矿流程,你得先看几周甚至几个月的代码,才敢动手改核心的流程(当然,改注释户或者参数啥的就不用说了)。
这里分享 2 个在测试过程的小技巧,绝对的 操作简单,效果看得见。
(1) 关闭 Numa,这个方法一般只能对 Intel 机器有用。Numa 架构中用来解决多物理 CPU(非多核)系统下共享 BUS 带来的性能问题。 但是前面我们说过,P1 只允许单核处理,所以此时 Numa 就没必要启用了。
关闭 Numa 需要通过 Bios 设置里面关闭。
(2)开启 CPU 的性能模式。Ubuntu 系统中默认 CPU 都是工作在 powersave(省电)模式的,这样性能没有最大话,所以需要调整到 performance(高性能)模式。你可以通过设置 Bios 或者通过软件临时调节。
1、安装cpufrequtils:
sudo apt-get install cpufrequtils2、查看当前cpu的状态:
cpufreq-info3、把cpu调整到性能模式:
sudo cpufreq-set -g performance以上方法亲测可用,大概可以提升 5% 的性能。
本文首发于:
小一辈无产阶级码农原文链接:http://www.r9it.com/20200525/filecoin-phase2-test1.html
参考链接
- 学分: 120
- 分类: FileCoin
- 标签: 搭建Filecoin 挖矿集群





