探索加密数据 II:使用外包数据服务
- 2077 Research
- 发布于 2025-02-25 17:19
- 阅读 3782
本文探讨了区块链数据管理和解释的外包解决方案,包括多种服务类型,如节点即服务(NaaS)、原始流、解码流、索引数据API和影子日志等。这些服务帮助开发者和企业高效地访问区块链数据,而不必自行管理节点和基础设施。文章提供了深入的技术细节和实例,展示了每种服务的功能和应用。
这篇文章是关于加密数据系列的一部分。你可以在这里找到第一篇文章:探索加密数据 I:数据流架构
在不断发展的区块链技术领域,管理和解读大量数据既是一个挑战,也是一个机遇。对于希望利用区块链而不是自己管理节点和基础设施的开发者和企业而言,外包数据服务已成了一种关键解决方案。本章探讨为了满足这些需求而出现的各种外包数据服务类型,提供可扩展、可靠和高效的方法来访问和处理区块链数据。
节点即服务(Node-as-a-Service)
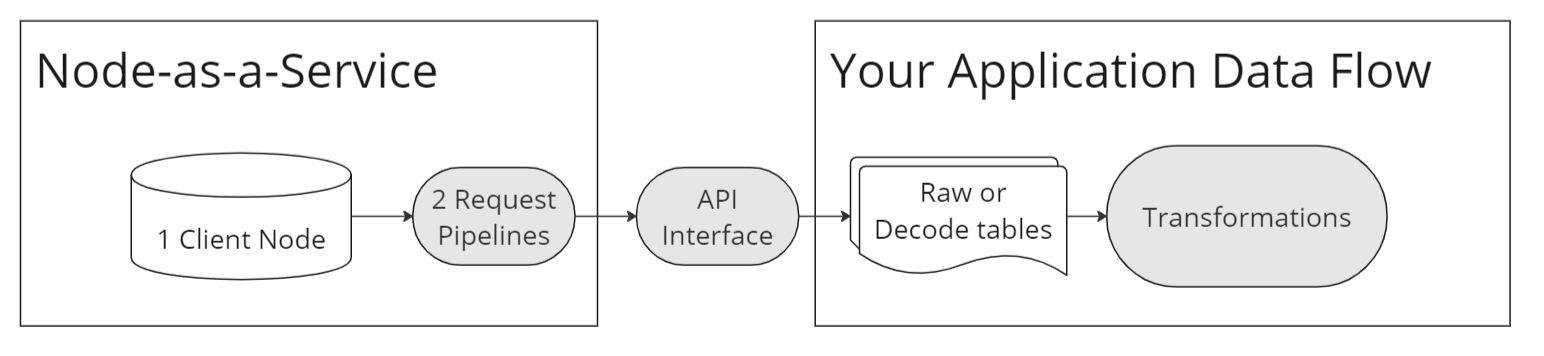
它是什么? - 运行自己的节点可能很有挑战性,尤其是在刚开始时或希望快速扩展时。这些服务为你运行优化的节点基础设施,并提供一个接口供你请求其数据,因此你可以专注于开发你的转型或产品。通常,节点服务会运行多种链和优化类型,因此你不需要运行多个客户端,从而可以通过一个 API 访问完整节点和归档节点,并使用特定于客户端的方法。
运行自己的节点可能令人生畏,特别是在开始或快速扩展时。节点即服务(NaaS)提供商提供优化的节点基础设施,使你能够专注于开发,而不必管理自己的节点。这些服务通常支持多种链和优化类型,通过统一的 API 提供对完整节点和归档节点的访问,以及特定于客户端的方法。
它是如何工作的? - NaaS 提供商在后台操作分布式节点客户端,通常提供与区块链交互的 API 接口。这可以包括专用节点或平衡请求负载的共享节点。虽然 NaaS 并不索引数据,但它可能提供优化功能,并在请求时提供原始或解码的数据流。
示例:Alchemy、Infura、Akr、Quicknode、Helius、Tenderly
可用数据:
- 你可以请求的所有内容,包括原始和更复杂的链上数据。
原始数据流(Raw Stream)
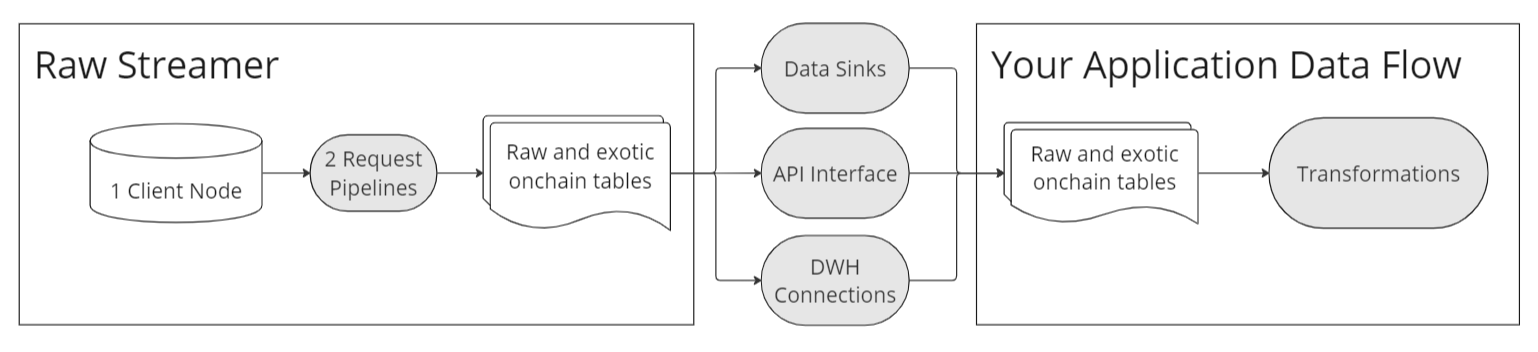
它是什么? - 客户通常需要大量数据,并以规律的节奏跟进链的块头。原始数据流服务通过提供标准化的架构来满足频繁请求的数据,并通过各种接口和接收端传递数据。
它是如何工作的? - 原始数据流服务类似于节点即服务,但增加了存储和提供大量数据的能力。这些提供商维护设计用于处理连续数据流的基础设施,确保用户能够有效访问实时或近实时数据。
示例:主要的节点即服务提供商如 Alchemy、Infura、Akr、QuickNode、Helius、Tenderly 和 Block Native,以及专业的解码流服务提供商,提供原始流服务的能力。
可用数据:
- 通常为区块、交易、跟踪、日志
- MemPool 数据
- Blob 索引
- Beacon Chain
- MEV 数据
解码数据流(Decoded Stream)
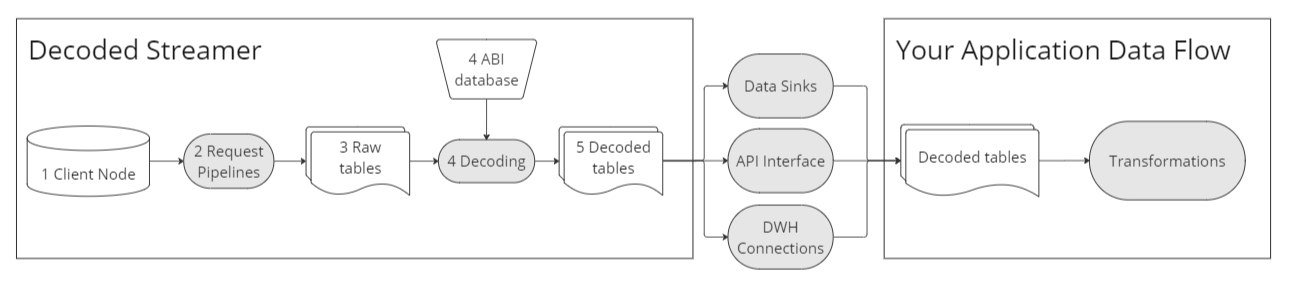
它是什么? - 解码流服务将原始数据流提升了一步,通过提供可供人类阅读的日志、跟踪,有时还提供视图函数表。这项相对新服务通过将复杂区块链数据翻译成更易解释和分析的格式,简化了与复杂数据的工作。
它是如何工作的? - 解码数据不仅仅是访问节点的原始数据。提供商必须维护一个全面的 ABI(应用程序二进制接口)数据库和解码系统运行。由于 ABI 无法直接从区块链获得,通常是通过像 Etherscan 这样的链下提供商获取的,这些地方提交合约以确保透明度和审计性。然而,并非所有合约都提供其 ABI。
解码数据有两种主要方法:
- 手动 ABI 检索:这种方法由 Dune 首创,涉及用户填写表单以提供一个 ABI,或允许系统自动从 Etherscan 下载。只有与请求的合约确切匹配的 ABI 被解码,使这种方法高度可靠,但依赖于拥有广泛的合约提交以增加覆盖范围。
- 算法解码:这种方法使用算法将日志和函数签名(topic0,8 字节)与任何可用的 ABI 匹配。虽然它涉及复杂的逻辑,但由于合约共享大量代码,因此算法可以识别与合约签名匹配的 ABI,即使确切的 ABI 文件不可用。该方法提供更广泛的覆盖,但可能需要处理不匹配的情况。这种方法对于分析非常有用,因为它允许探索合约数据,而无需事先了解其存在。
示例:Dune、Flipside、Allium、Sonaverse、Bitquery、Chainbase、Parsiq、Zettablocks
可用数据:
- 解码的跟踪,解码的日志,ERC20/721/1155 转移事件
- BalanceOf 和 SupplyOf 视图函数(Allium),在 transferEvt 后触发
索引数据 API(Indexed Data API)

它是什么? - 索引数据 API 是任何数据提供商的常规产品。它们通过 API 提供度量(转化数据),通常附带 SDK 以便于集成。这些度量可以涵盖广泛的数据,提供商不断扩展其提供的新型和专业度量,每个提供商试图开辟新利基。
它是如何工作的? 虽然索引数据提供商似乎是前面服务的演变,但它们实际上是服务的不同功能。尽管数据仍然经过本系列第一篇文章中描述的整个流程,但索引数据提供商通常使用更简化的栈。它们专注于提取、转换、加载和传递特定度量,而不是从客户处提供解码、原始数据或数据请求。前述服务类型旨在可扩展,提供标准化和广泛的数据,无需转化,而索引数据提供商优化为提供特定的预处理度量。
此外,前述流媒体服务只能提供原始和解码数据。如果索引数据提供商提供的度量需要“其他链上数据”,其系统必须进行额外的节点请求——无论是通过它们自己的节点还是依赖外部节点——按其规范获取必要的数据。
示例:Nansen、Defillama、Artemis、Bitquery、Arkham、Blockworks、Glassnode、Messari、Token Terminal
可用数据:
- 网络和协议度量(Dex、借贷、衍生品和期货、Dex Agg 等)
- NFT
- 钱包交互和余额
- MemPool
- 桥接
- 质押等
阴影日志(Shadow Logs)
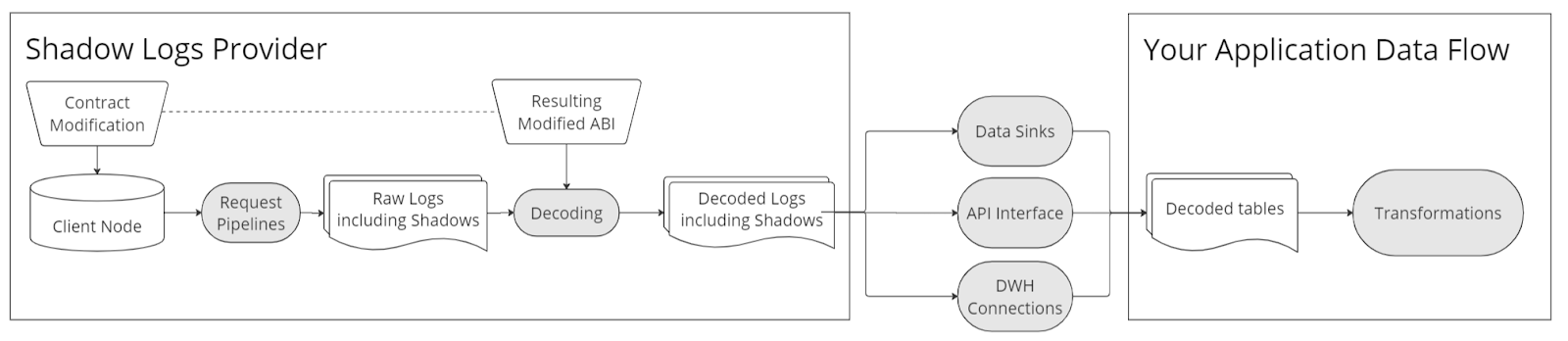
它是什么? - 阴影日志类似于常规日志,但它并不是由部署在区块链上的合约发出的,而是通过在本地修改合约源代码并提交到一个特殊的归档节点来发出。该节点重新执行区块链历史直到当前块头,但运行合约的新代码版本。提供阴影日志的公司提供类似于原始或解码日志的格式的数据。
它是如何工作的? - 与常规日志必须写入原始合约代码不同,阴影日志可以由任何人随时创建,而不仅仅是部署者。这种灵活性使得创建在原始合约部署中不存在的日志和度量变得可能。因此,阴影日志可以访问广泛的数据类型,包括原本更复杂的读取状态部分,如内部函数和内部变量。这使得阴影日志成为深入数据分析的强大工具。
示例:阴影日志、幽灵日志
结论
了解可以外包哪些服务已成为在庞大而复杂的加密数据领域中导航的必备知识。从运行节点到提供原始、解码和索引数据,这些服务使开发者和企业能够高效访问区块链,而无需管理自己的基础设施。每种类型的外包数据都有独特的权衡,满足不同的需求。通过利用这些服务,用户可以专注于构建和扩展他们的应用程序,而由专业提供商处理数据基础设施的繁重工作。随着生态系统的不断发展,保持这些外包解决方案的可访问性的依赖只会增加,使其成为加密数据领域的基石。
- 原文链接: research.2077.xyz/explor...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





