Uniswap V3 的刻度(Tick) - 深入了解集中流动性
- mixbytes
- 发布于 2025-02-25 13:36
- 阅读 3832
本文深入探讨了Uniswap V3中集中流动性概念的技术设计,阐明了如何通过数学模型简化复杂算法的实现,从而降低交易和流动性供应的燃气费用。文章涵盖了Uniswap V3的核心原理、实现细节,以及流动性提供的机制,强调了该设计中的优化思路和技巧,为开发者和审计人员提供了有价值的见解。
作者:Sergey Boogerwooger, MixBytes 的安全研究员

简介
现代 DeFi 协议中有多种使用集中流动性理念的方案。Uniswap V3 提出了这一概念的实现,许多人日常使用此协议。然而,在智能合约中实现集中流动性是一个棘手的过程,需要在数学概念和高度优化的智能合约代码之间建立巧妙的连接。
你不能仅仅阅读 Uniswap V3 的白皮书就轻松了解它为何如此设计。同样,当查看 Uniswap V3 的 Solidity 代码时,你也无法完全理解为何使用这样的设计。因此,我们需要弥合这两部分信息之间的差距,以提供对集中流动性概念及其复杂性的全面理解。也许这些理念中的一些会在你的代码中找到用武之地,或帮助审计利用集中流动性的协议。
主要理念
我们假设读者对 Uniswap V2 AMM 概念和 Uniswap V2 池中恒定乘积的工作原理是熟悉的。你可能知道 Uniswap V2 池面临的如资本效率低、滑点和无常损失等问题。一个好的例子是稳定币之间的兑换,其中即使在大量兑换时,价格也不应发生显著变化,或者在流动性池中的流动性较小且兑换会导致显著的价格变化和无常损失的情况下。
因此,Uniswap V3 的主要理念是给予流动性提供者更精确地配置其资产的能力,目标是期望的价格范围,例如将其流动性集中在稳定币兑换的“1.0”附近。
为了实现这一目标,所有的价格范围应该被划分为多个部分(“ticks”),并在兑换过程中,价格应“跨越”多个价格 ticks,只使用“属于”当前 tick 的流动性。让我们来看一下如何实现这一目标。
基础数学
第一步:Uniswap V3 白皮书 和关键定义。token0 和 token1 之间的汇率(无论是对于整个池还是在特定的 tick 中)被定义为价格。整个价格范围被划分为所谓的“ticks”,每个 tick 表示 1.0001 的整数次方。第 i 个 tick 的价格定义如下:
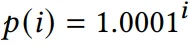
因此,每个 tick i(签名)表示价格从 tick i=0 的 0.01%(1 个基点)移动。价格可以在整数空间中以小的 0.01% 步长在“1.0”上方和下方移动(−∞,+∞)。
另外两个重要定义为 流动性 和 sqrtPrice:
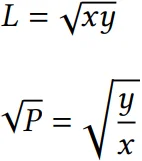
其中 x 和 y 分别是 token0 和 token1 的储备。
Uniswap V3 池由多个“小”兑换池组成,每个池通过单独的 tick 进行区分。每个“小”池的行为像 Uniswap V2 池,具有恒定乘积,拥有自己的储备,但有一个重要的不同点——tick 的储备是可耗尽的,具有最大和最小兑换价格,并且 token0 和 token1 的数量有限。当 token0 和 token1 的所有储备完全从池中移除时,其流动性降至零,因为 x∗y=0。因此,UniV3 中的恒定乘积方程略有不同(双曲线向零移动),变为:
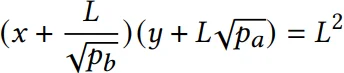
(其中 P a 和 P b 是给定的 tick 范围内可以达到的最低和最高价格)
该函数的图形如下所示:
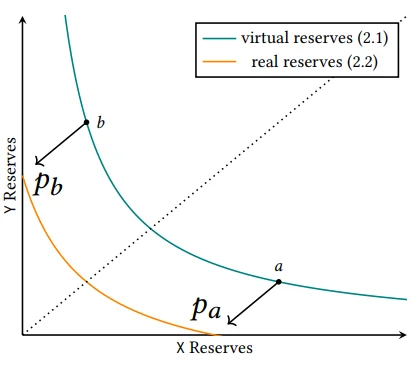
如果某个储备被耗尽且兑换过程尚未完成(所需的数量或价格未达到),UniV3 将继续到下一个活动的 tick 并执行下一个“跳跃”,在下一个 tick 中进行兑换。这些兑换将继续进行,直到收到目标数量的代币或达到目标兑换价格。
跨 tick 兑换
让我们开始使用这个简单的图片来说明跨 tick 兑换:
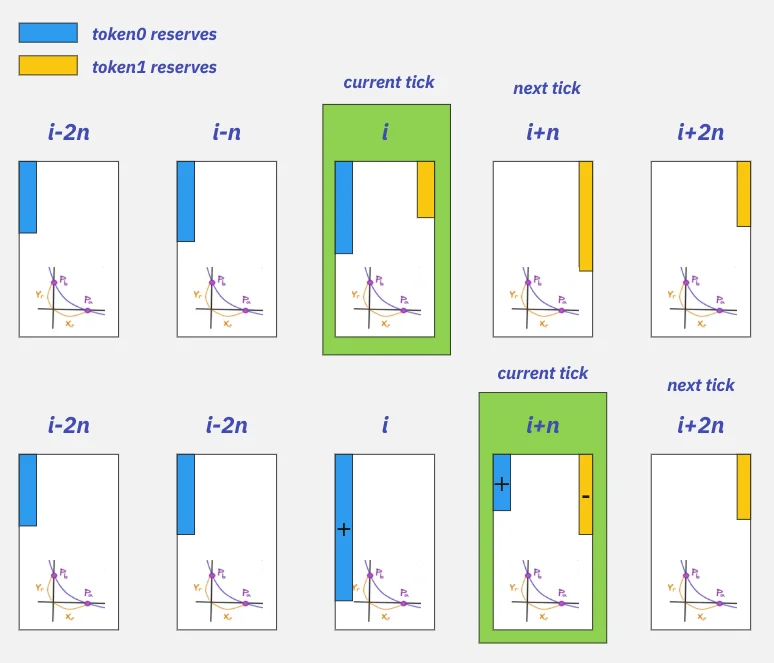
该池具有当前状态:当前价格(tick)和兑换从当前 tick 开始(绿色),用户给予 token0(蓝色)并接收 token1(黄色)。如果兑换量小,且价格未超过 $P_a$ 或 $P_b$ (当前 tick 的最低和最高价格),则目标数量根据恒定乘积公式进行更改。否则,当将 token0 兑换为 token1
(在图片中向右移动)时,当前 tick 中的 token1(黄色)储备被完全耗尽,仅留下 token0(蓝色)。然后当前 tick 移动到下一个 tick,拥有 token1 储备(“i+n”在图片中),并继续兑换。这导致当前 tick 左侧的所有 ticks 仅包含 token0,而右侧的 ticks 则仅包含 token1。相反方向的兑换(token1 兑换 token0)以类似的方式工作。
[注意] 图中的 n 参数(表示 ticks 之间的步长)与池的 tickSpacing 参数有关,稍后将讨论。
向实现迈进
直接实现这种逻辑,使用单独的 tick 储备、每次兑换和流动性变化的更新,以及 Uniswap V2 风格的费用计算,会导致大量变量和高Gas费用。
因此,我们需要一种数学方法,使跨 tick 兑换和流动性提供/费用计算变得便宜。我们的目标是实现接近恒定的Gas费用和最小的存储使用。这些要求是使用流动性(L 和 ΔL)和 **sqrtPrice*(√P 和 Δ√P**)而不是直接代币数量的主要原因(就像在 Uniswap v2 中那样)。
使用单一流动性(L)和平方价格(√P)的第一个重要方面是,在兑换和铸造/销毁流动性时,只有这两个值中的一个发生变化。√P 在 tick 内执行兑换时发生变化,L 在跨越 tick 或铸造/销毁流动性时发生变化。
此外,使用 √P 而不是 P 避免了需要使用平方根(sqrt())函数,因为该函数并没有恒定的Gas费用。在 Uniswap V2 中,sqrt() 是通过使用没有恒定Gas费用的巴比伦方法来实现的。在 Uniswap V3 中,你根本找不到 sqrt() 的计算;相反,使用了在 TickMath.sol 中预先计算好的值(这里)。
使用 √P 和 L 允许在兑换过程中以非常简单的公式计算接收的代币数量和 √P 价格的变化:
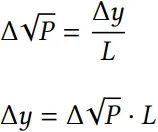
对于 token1(Δy),和
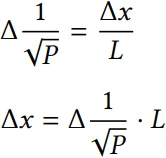
对于 token0(Δx)
你可以在计算兑换功能 getAmount0Delta() 和 getAmount1Delta() 中找到这些计算。
UniswapV3 实现的下一个重要点是 tickSpacing。此变量设置允许拥有流动性的 ticks 之间的“步长”。例如,如果 tickSpacing 设置为 60,则只有 0、60、-60、120、-120 等 ticks 可以被初始化并拥有来自提供者的真实流动性。tickSpacing 为池创建者提供了选择,看看他们是否希望在 ticks 之间设置更小的步长和更“密集”的池(更细化的价格步长,但通过跨越更多的 ticks 导致更高的费用)还是更“稀疏”的池,这将使价格步长更大(跨越的 ticks 较少=费用较少,但 LPs 的精确度更差)。
兑换过程
让我们跟踪 UniswapV3 的兑换过程,在代码中的有趣地方停下来并描述它们。在这一阶段,我们将跳过或简要提及与流动性、价格、代币数量和 tick 跨越不直接相关的逻辑分支。
让我们从 swap() 功能开始。与兑换相关的输入参数设定了兑换的方向(zeroForOne)和目标值:兑换要么达到指定的目标金额(amountSpecified),要么达到价格(sqrtPriceLimitX96)。这些值用于设置滑点限制,作为在达到所需的代币数量或价格限制时停止兑换的障碍。
在初始化兑换缓存和设定起始值后,我们在 这里 进入主要的兑换循环,运作条件为
(state.amountSpecifiedRemaining != 0 && state.sqrtPriceX96 != sqrtPriceLimitX96)。
兑换的核心是 这个 部分(computeSwapStep() 函数):

在这里,我们收到新的 state.sqrtPriceX96 并计算新的 state.amountSpecifiedRemaining,如果达到了目标值,兑换将停止下一个 tick 的跨越。
深入 computeSwapStep() 函数,我们会遇到确定下一个价格的代码段 在这里(仅显示一个分支):
因此,computeSwapStep() 函数返回新的 sqrtPriceX96 和处理当前 tick 后“剩余”的代币的输入/输出数量。
让我们回到 swap() 函数中。我们在这里检查价格是否已更改为下一个可用的价格。如果价格已更改并达到下一个初始化的 tick,我们在这里执行 tick 跨越:
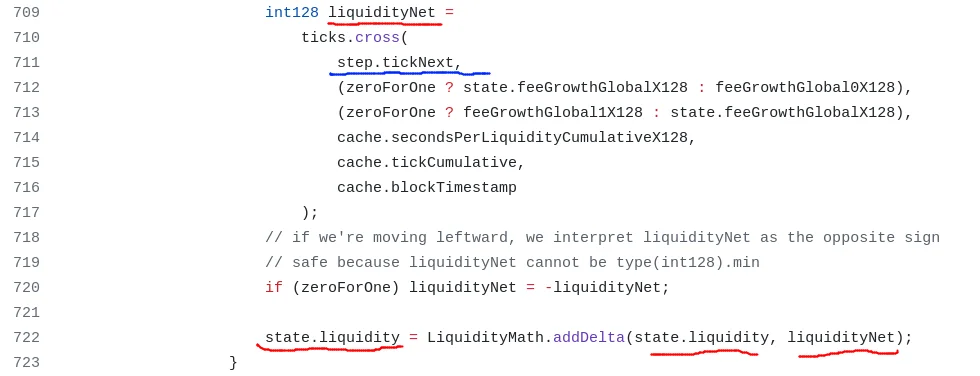
ticks.cross 在 ticks 映射中存储新值(费用、时间戳、预言机值)(我们稍后将讨论),并返回将用于增加/减少兑换流动性的 liquidityNet(state.liquidity),随后再影响池的全局流动性(在这里)。
在兑换结束时,我们在 这里 计算目标数量(amount0 和 amount1)并执行回调。
提供流动性
在 Uniswap V3 中,流动性是通过创建“位置”进行提供的,用户拥有这些位置。这种机制不同于 Uniswap V2,在 Uniswap V2 中,流动性所有权是通过 ERC20 LP 代币实现的。在 Uniswap V3 中,“位置”是一个由用户拥有的对象,持有一定数量的流动性加上一系列的 ticks(从 tickLower 到 tickUpper)。正如可以看到的那样,mint 和 burn 操作非常相似。在铸造的情况下,流动性被 添加 到一个位置,而在销毁的情况下,流动性则被 删除。
现在,让我们深入研究创建/删除位置的 _updatePosition() 功能。它接受 tickLower 和 tickUpper,添加/移除的流动性 (liquidityDelta) 和当前池的 tick。
UniswapV3 数学的一个非常有效的例子在 这部分 的 _updatePosition() 中显而易见。你可能认为 LP 应该在从 tickLower 到 tickUpper 的范围内分配流动性到所有 ticks(当然要匹配 tickSpacing),但在代码中,我们只看到两个更新:
flippedLower = ticks.update(
tickLower,
...
);
flippedUpper = ticks.update(
tickUpper,
...
);对 Lower 和 Upper ticks 的更新。这种方式非常高效,但这里发生了什么?如何在不在每个 tick 中存储流动性值的情况下收集所有 ticks 的费用?首先,我们先解决费用问题。
关于费用分配的非常详细的文章在 这里。
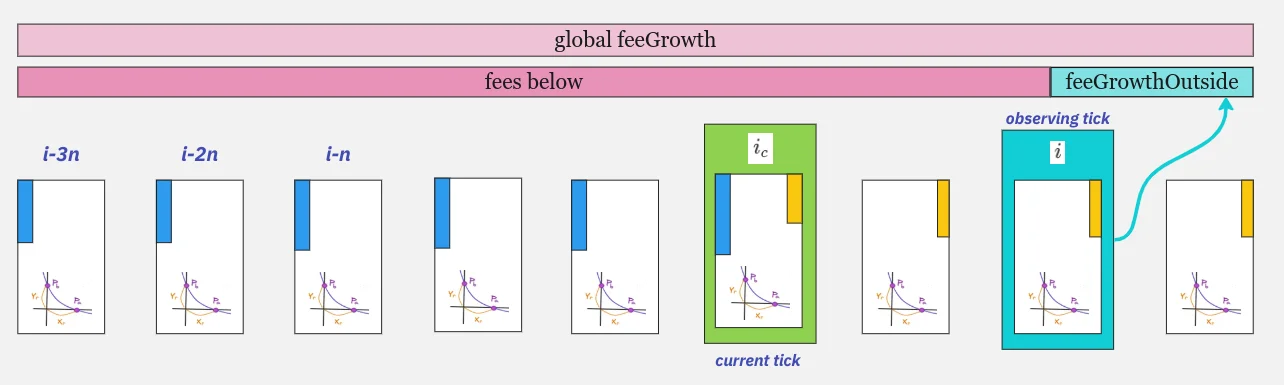
Uniswap V3 费用的主要概念涉及跟踪 ticks 上方和下方的“外部”费用金额,并将这些值存储在 tick 中。这些费用金额使用白皮书中的以下公式计算:
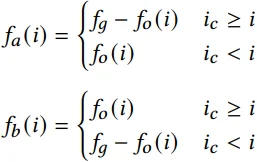
(其中 f_o(i) 为由第 i 个 tick 存储的 feeGrowthOutside 值,f_g 为池中累积的费用总额)
但实现仅使用一个值来跟踪这些费用量,即 ticks 内的 feeGrowthOutside* 值(我们只讨论一个,因为针对 token0 和 token1 存储了两个值)。
根据上述公式,给定 tick 的“外部费用”值(feeGrowthOutside*)相当于:
- 低于 tick i 的费用累积总数,如果它在 i_c 的左侧
- 高于 tick i 的费用累积总数,如果它在 i_c 的右侧
(i_c - 当前价格 tick,i - 观察的 tick)
第一种情况:i <= i_c,我们向右移动,feeGrowthOutside 存储左侧费用的部分:
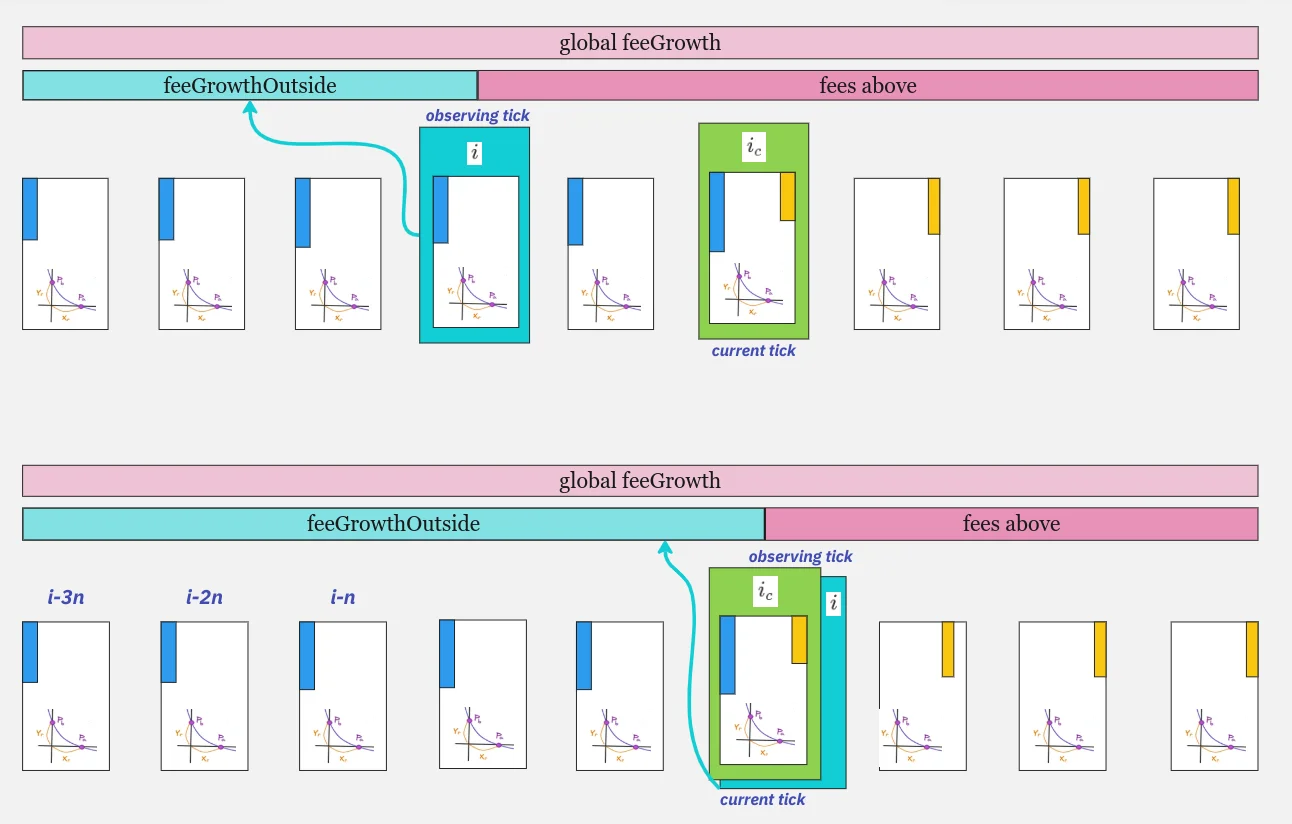
第二种情况,i > i_c,我们跨越当前价格 tick,feeGrowthOutside 现在存储右侧的费用部分:
ticks 是顺序跨越的,因此每次跨越 tick 时,feeGrowthOutside 会变化,指向全局费用的“左”或“右”部分。
这种设计极大简化了计算属于给定范围(i_l - 下限 tick,i_u - 上限 tick)内的费用的过程:
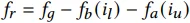
我们只需从全局中减去“低于下限 tick 的费用”和“高于上限 tick 的费用”。
另外,回顾一下 feeGrowth* 是以“每单位流动性计的代币”来测量的,因此计算目标费用金额也变得相对简单。我们通过从流动性中移除(在这里)然后在 ticks.getFeeGrowthInside() 函数中计算费用(在这里),该函数实现了如上所述的公式(在这里):
if (tickCurrent >= tickLower) {
feeGrowthBelow0X128 = lower.feeGrowthOutside0X128;
feeGrowthBelow1X128 = lower.feeGrowthOutside1X128;
} else {
feeGrowthBelow0X128 = feeGrowthGlobal0X128 - lower.feeGrowthOutside0X128;
feeGrowthBelow1X128 = feeGrowthGlobal1X128 - lower.feeGrowthOutside1X128;
}因此,为了计算在 tick 范围内收集的费用,我们只需读取两个 ticks 的状态和全局状态,使其效率极高。这种相同的算法也适用于提供流动性、计算并更新下限和上限 ticks 的新 feeGrowthInside* 值。
[注意] 也许你提到过没有位于 tickSpacing 上的任何限制,并且 LP 似乎可以设置任何 tickLower 和 tickUpper。但这个检查是在 _flipTick() 功能内部执行的,该功能用于开启/关闭 ticks。
Ticks 组织
现在让我们看看这些 ticks 是如何组织的。我们第一个停留点是 Tick.sol 中的结构体 Info——关于 tick 的主要信息:

在 tick 内部没有必要跟踪价格,因为 tick 编号本身代表当前价格,并且兑换价格可以有效地从流动性和兑换量中计算得出。
有两个流动性变量:liquidityNet (ΔL) 和 liquidityGross (L_g)。当我们跨越 tick,完全移除一种代币的储备时,该 tick 的 liquidityNet 变为零(L=√xy 而 x=0 或 y=0)。然而,我们仍然需要某种东西来指示一些 LP 仓位正在引用此 tick。因此,我们跟踪的 liquidityGross 值表示 LP 提供给该 tick 的流动性总和。
为了跟踪 ticks 的状态(已初始化或未初始化),我们需要一个“映射”用于搜索当前价格上涨或下跌时下一个 tick。 在 UniswapV3 中,ticks 以 256 位位图组织,采用 uint16 索引(mapping(int16 => uint256)),在此映射中,每个 tick 编号(int24)指向 16 位索引字所在的位,并且占用 256 位的某一特定位:

当我们想要找到下一个已初始化的 tick 时,我们使用来自 TickBitmap.sol 的 nextInitializedTickWithinOneWord() 函数。根据搜索方向,我们将当前 tick 以下或以上的所有位设为零,并检查结果是否非零。然后,我们使用 BitMath.mostSignificantBit() 或 BitMath.leastSignificantBit() 函数识别最近的已初始化的 tick。有趣的是,这些函数使用位的逐步位移,采用二进制搜索的方法,而不是逐位查找。该方法在每次迭代中将搜索空间减半,最多只需 log₂256 次迭代,而不是 256 次。
然后,我们使用下一个 tick 价格在 这里 继续兑换过程,如前面讨论的那样。
结论
在本文中,我们描述了 Uniswap V3 集中流动性的主要技术设计。这种设计是一个优秀的例子,展示了坚实的数学模型如何能够有效地实现相对复杂的算法。这种设计显著降低了类似于兑换和流动性提供的操作的Gas成本,使其接近恒定,即使在涉及协议内部大量实体的情况。
Uniswap V3 有效利用了 ticks 跨越的顺序特性,只更新维持池状态一致性所需的值。同时,费用系统的设计使成千上万的流动性提供者能够在不同价格范围内拥有位置,而无需“订单簿”或单独处理每个位置。
这种方法确实使得 Uniswap V3 的操作对于外部服务更复杂。它们需要执行一些外部计算,以便为最终用户提供必要的信息,例如滑点、价格范围、池的状态等。不过,这在区块链世界中是很常见的。幸运的是,有许多项目和服务可供用户在使用 Uniswap V3 时提供帮助。
“集中流动性”概念确实在现代 DeFi 中广受欢迎,并被许多项目使用。因此,如果你想实现自己的解决方案或审核使用此类算法的项目,请记住现有有效的解决方案。别忘了检查它们,因为在智能合约中处理多个实体的逻辑可能会很棘手。下次见!
- MixBytes 是谁?
MixBytes 是一个由专家区块链审计员和安全研究人员组成的团队,专注于为 EVM 兼容和 Substrate 基础项目提供全面的智能合约审计和技术咨询服务。加入我们在 X 的行列,随时了解最新的行业趋势和洞察。
- 原文链接: mixbytes.io/blog/uniswap...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





