Filecoin - 深入理解存储管理
- Star Li
- 发布于 2020-08-04 12:21
- 阅读 7781
Filecoin的存储单元称为扇区(Sector)。对传统硬盘结构理解的小伙伴,对这个术语应该比较亲切,传统硬盘的最小存储单元就叫Sector。为了证明Sector的存储,Filecoin进行了一系列的处理,传说中的P1/P2/C1/C2。在处理过程中,一个Sector的计算会生成若干文件,最终会生成replica。相关文件是如何组织的?Cache都是由哪些文件组成,分别是多大?本文就从存储的角度看看这些过程和逻辑。
Filecoin的存储单元称为扇区(Sector)。对传统硬盘结构理解的小伙伴,对这个术语应该比较亲切,传统硬盘的最小存储单元就叫Sector。为了证明Sector的存储,Filecoin进行了一系列的处理,传说中的P1/P2/C1/C2。在处理过程中,一个Sector的计算会生成若干文件,最终会生成replica。相关文件是如何组织的?Cache都是由哪些文件组成,分别是多大?本文就从存储的角度看看这些过程和逻辑。
Filecoin的存储管理的逻辑主要实现在sector-storage项目中。在深入理解Sector存储逻辑之前,先讲讲Worker和Manager。
01 相关术语
-
Worker - 处理P1/P2/C1/C2的服务,Worker又分为两种:local worker和remote worker。local worker处理本地服务处理,remote worker支持远程服务处理
-
Manager - 管理多个Worker
-
Scheduler - 调度器,调度多个Worker,一个Manager通常有一个Scheduler
-
Store - Sector存储系统
02 Sector存储
Sector处理相关的文件存储在Store中。Store通过sectorstore.json进行配置:
cat sectorstore.json
{
"ID": "98bd61f8-f52d-45a3-af2c-b8596cbd693d",
"Weight": 10,
"CanSeal": true,
"CanStore": true
}CanSeal表明Store可以用来Seal(存储Seal相关的临时文件),CanStore表面Store可以持久存储Seal的结果(replica)。Weight 是权重,在多个Store选择时使用。ID是Store的UUID编号。
一个Store中存在三种存储,分别对应三种目录:unsealed (未封存的文件),cache(缓存文件),sealed(封存后的文件)。
03 Worker & Store
sector-storage项目的README中的这张图很好的解释了sector storage的各个模块以及相互的关系:
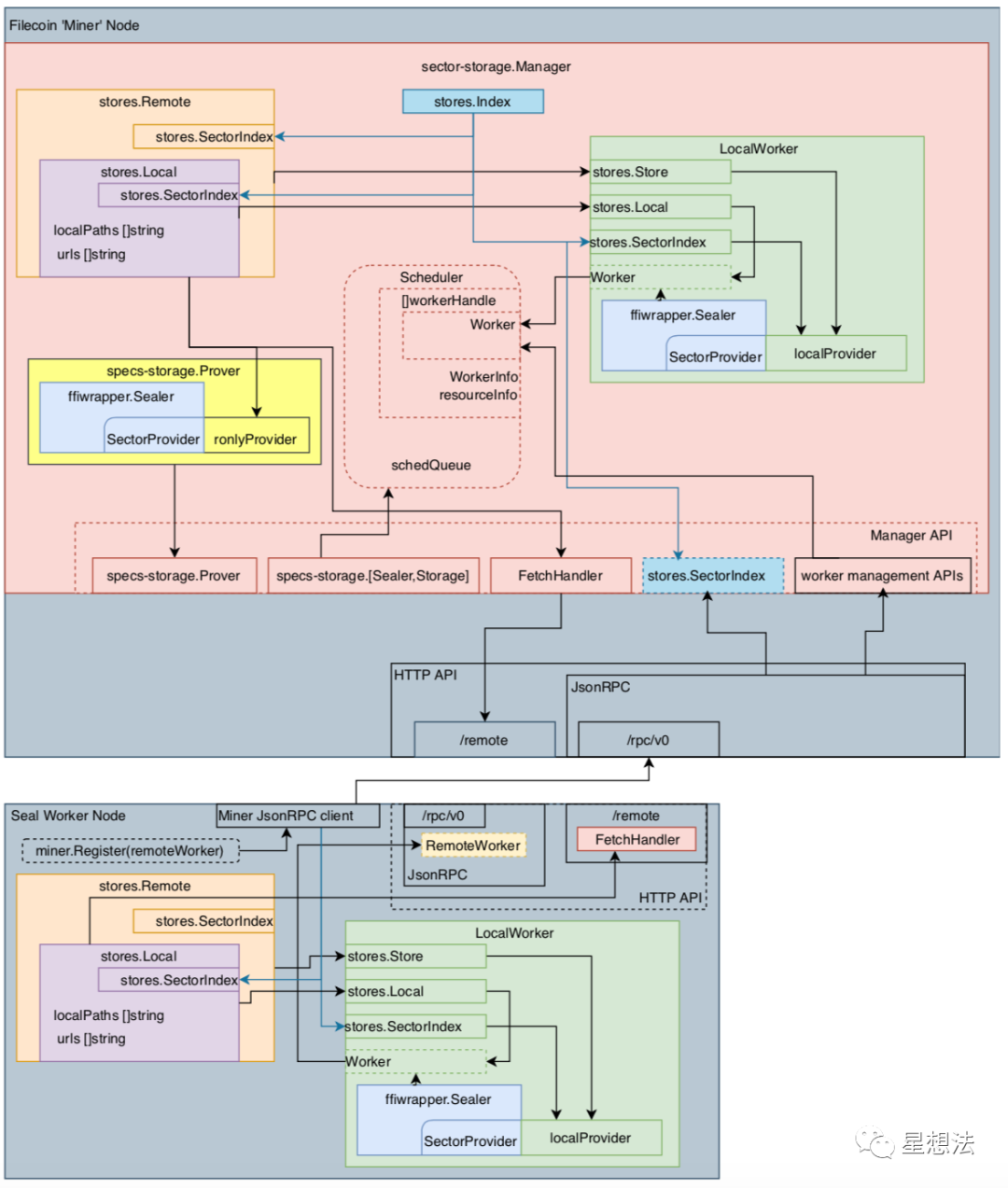
整幅图分为上下两个部分:上部分是Manager,下部分是Remote Worker。Manager中包括一个Local Worker。stores.Index是所有Sector存储的索引。Scheduler,上部分的中间,管理所有的Worker,并且调度Sector相关的存储。
worker management APIs通过/rpc/v0的jsonRPC接口实现remote worker的管理。通过/remote的HTTP API实现存储的Fetch操作,简单的说,传输文件。specs-storage.Prover/Sealer/Storage是Manager暴露出来的接口,实现Sector的证明,封存和存储。
每个连接到Manager的Worker会和Manager同步它的内存/CPU以及显存的信息。Scheduler在接受到新的请求时,会针对请求(Task)的类型以及资源的需求,从当前Worker中挑选最合适的Worker进行请求的处理。如何选择Worker,感兴趣的小伙伴,可以查看selector的相关逻辑。
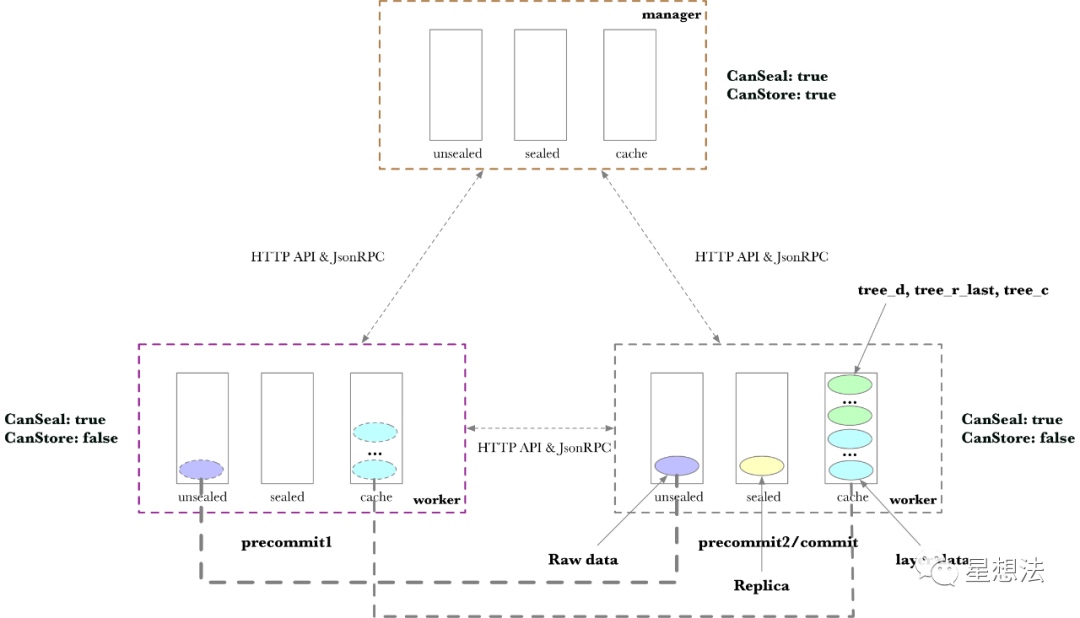
从存储的角度,重新整理一下,这些关系:
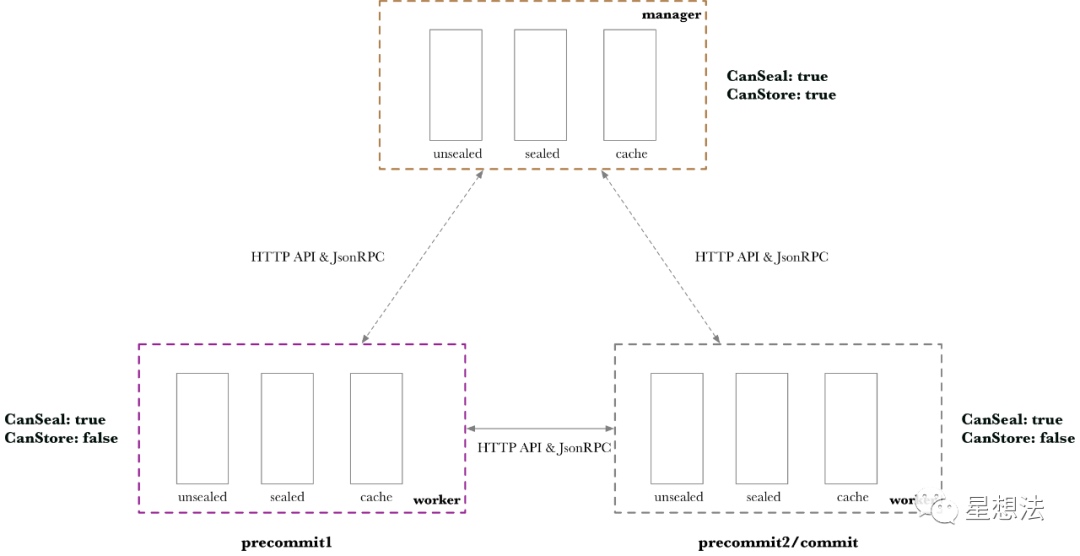
以一个Manager连接两个Worker为例。Worker只能Seal,但是不能Store。为了更清楚展示Worker之间的数据传输,第一个Worker只做Precommit1,第二个Worker做Precommit2和Commit。
04 Seal Task
理解Seal Task,最好对照了Sector的状态管理一起看。对Sector状态管理还不熟悉的小伙伴,可以查看之前的文章:
const (
TTAddPiece TaskType = "seal/v0/addpiece"
TTPreCommit1 TaskType = "seal/v0/precommit/1"
TTPreCommit2 TaskType = "seal/v0/precommit/2"
TTCommit1 TaskType = "seal/v0/commit/1"
TTCommit2 TaskType = "seal/v0/commit/2"
TTFinalize TaskType = "seal/v0/finalize"
TTFetch TaskType = "seal/v0/fetch"
TTUnseal TaskType = "seal/v0/unseal"
TTReadUnsealed TaskType = "seal/v0/unsealread"
)接下来,看看每个Seal Task对应的存储数据的变化。
AddPiece
如果其中左边的Worker接收到任务,AddPiece任务会在unsealed目录中创建原始数据。
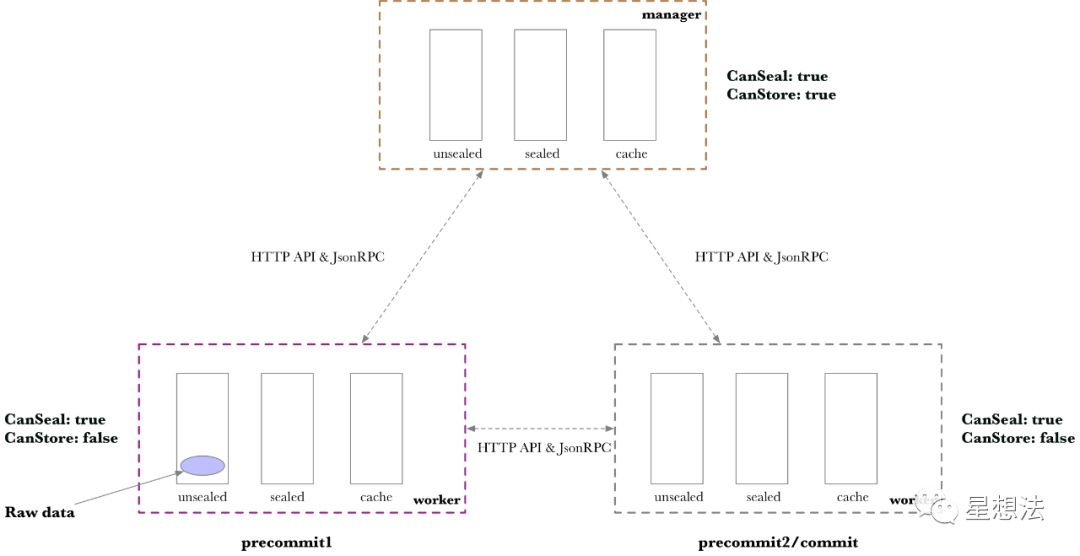
PreCommit1
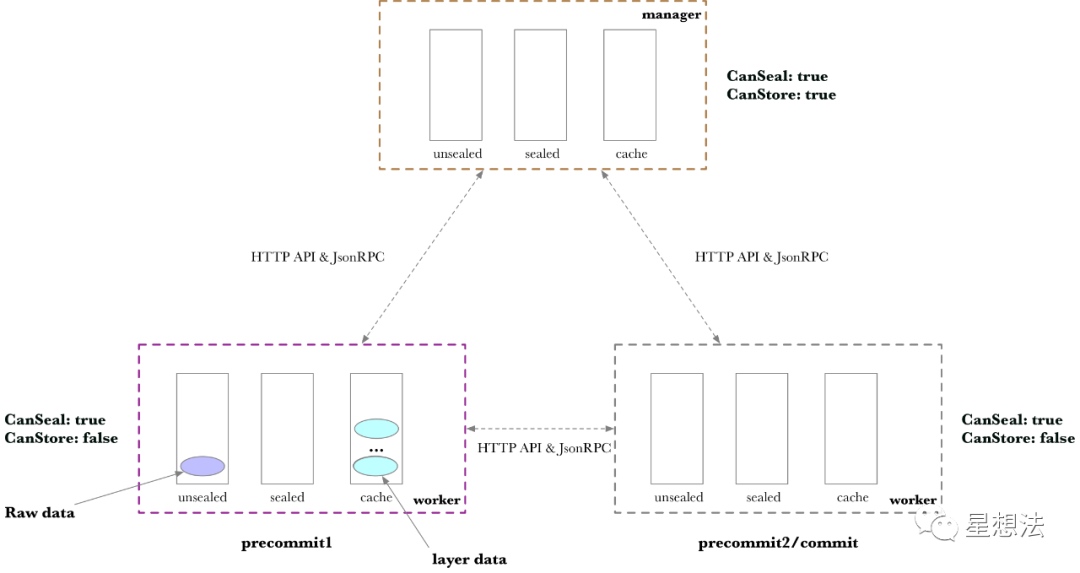
PreCommit1阶段,简称P1,针对SDR算法,计算若干层数据。如果Sector是32G,需要计算11层。对SDR算法不熟悉的小伙伴,可以看看之前的文章:
经过PreCommit1,生成的数据存储在Cache中:
PreCommit2
PreCommit2的阶段,简称P2,生成Replica,计算Column Hash,并生成Merkle树(tree_d, tree_c, tree_r_last)。因为P2,不在同一个Worker处理,在进行处理之前,需要先传输给合适的Worker,处理的结果同样存储在Cache中:
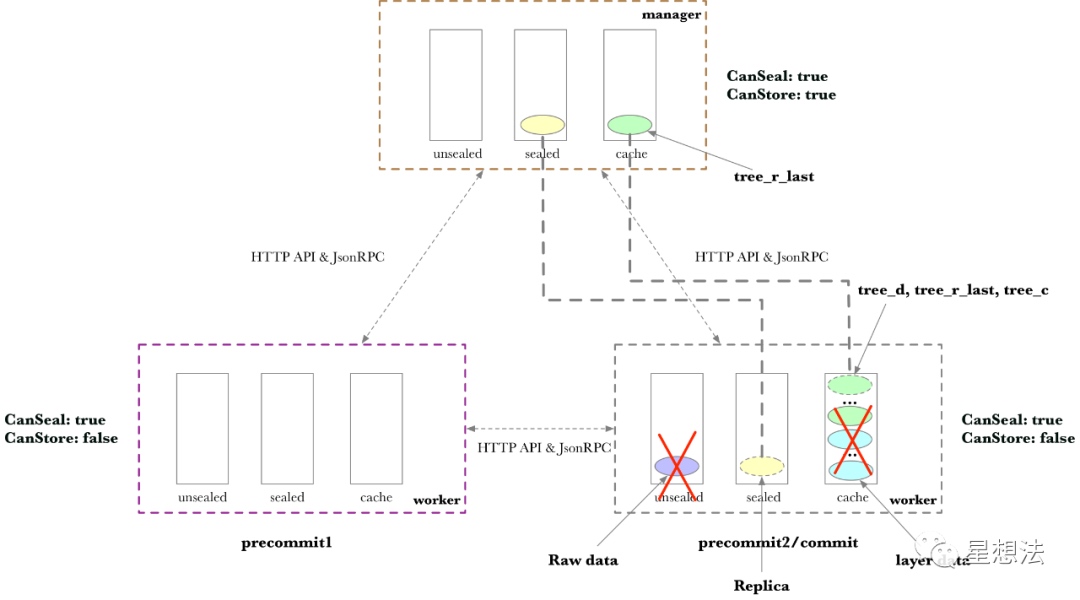
Commit 和Finalize
在Commit生成证明后,进入Finalize状态,Finalize可以理解成“归档”。因为在Worker上没有Store能力,删除不需要持久化的数据,需要持久化存储的数据,将传输回Manager。
05 数据存储量
以32G的Sector为例,在处理过程中需要存储的数据如下:
-
原始数据 - 32G
-
原始数据Merkle - 32G
-
P1 layer - 32*11G
-
P2 - Column Hash & tree_c - 32*2 G
-
P2 - Replica & tree_r_last - 32G + 9.2M*8
总共:512G多一点。
06 持久化数据
Sector经过P1/P2/C1/C2处理后,也就是说,经过PoREP处理后,需要持久化存储Replica的数据和tree_r_last的数据。tree_r_last的数据需要存储的原因是PoSt要用到。特别注意的是,tree_r_last的数据并不是完整的Merkle树数据,删除了其中一些层的数据。
32G的Sector,对应的tree_r_last分成了8棵子树,每棵子树是8叉树,默认存储的时候,忽略了最低的两层。也就是,去除最低两层的存储量为:
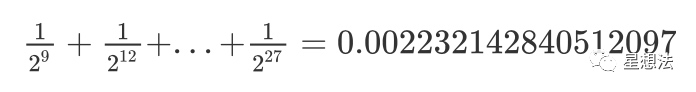
所以每棵子树的存储数据为4G*0.00223 = 9.13M。
也就是说,Sector持久化存储比例在1.0022左右。
总结:
Filecoin存储管理的逻辑主要在sector-storage中。Sector的处理任务,可以通过多个Worker完成。每个Worker的存储目录结构一致,Sector数据可以在多个Worker之间通过Http服务传输。Sector处理过程中,最大的存储需求量在512G左右。持久化存储比例为1.0022。






