11种高级Solidity Gas优化技巧
- Cyfrin
- 发布于 2024-10-31 13:43
- 阅读 2157
本指南介绍了11种高级的Solidity gas优化技巧,强调优化智能合约的gas成本能够显著提升协议的可扩展性和用户体验。通过减少链上数据、使用映射而非数组、利用常量和不可变变量等方法,开发者可以实现高达90%的gas节省。这些优化策略不仅能降低成本,还能提升合约的安全性。
11 个高级 Solidity Gas优化技巧
在本指南中,你将学习到 11 种先进的、经过实际应用和测试的 Solidity Gas优化策略。
优化你的 Solidity 智能合约的Gas成本 可以为你和用户 节省超过 90% 的交易费用,使你的协议更加可扩展、更便宜,并在长期内获得成功。
在本指南中,你将学习到 11 种由顶尖 web3 开发人员教授的 Solidity Gas优化技巧和技术,以 降低智能合约的Gas成本。
请务必注意,本指南中的示例来自非常简单的合约,仅用于演示目的,并且在大多数情况下只考虑了运行时的Gas成本,因为部署成本可能会因智能合约的大小而有很大差异。
在实际场景中,我们强烈建议 每个智能合约都应经过完整且深入的 审计流程 。
有关本文中的所有示例和测试,你可以参考 Github Gas优化提示库。

Solidity Gas优化提示信息图
在开始本 web3 开发指南 之前,先简要回顾一下 Gas优化的重要性!
Solidity Gas优化的重要性
Gas优化对开发人员、用户以及项目和协议的长期成功至关重要。有效优化智能合约的Gas 会使你的协议 更具成本效益,并且 可扩展,同时 减少如拒绝服务(DoS)等安全风险。
Gas高效的合约提高了产品的可用性和用户体验,即使在网络拥堵的情况下也能实现更快更便宜的交易。
简单来说,优化Gas成本使 Solidity 智能合约、协议和项目变得:
- 成本有效
- 高效
- 可用
同时提高采用率并为更高效的解决方案提供竞争优势。
此外,改进智能合约代码 有助于揭示潜在漏洞,使你的协议及其用户更加安全。
注意:本指南并不替代由 顶尖智能合约审计公司 进行的全面安全审查。
总之,Gas优化应该是开发过程中的一个关键焦点,因为这不仅是一个 nice-to-have,而是智能合约长期成功和安全的 must-have。
废话不多说,让我们深入探讨优化Gas使用的最有效技术。
免责声明:本指南中的所有 测试均使用 Foundry 进行,并使用以下配置:
- Solidity 版本:^0.8.13;
- 本地区块链节点: Anvil
- 使用的命令: forge test
- 优化运行次数: 100
每个测试运行了 100 次,本指南中的所有结果是所有测试结果的平均值。
Solidity Gas优化技巧
1. 最小化链上数据
作为开发人员,质疑记录所有用户数据、NFT 游戏统计或任何其他 Solidity 智能合约可能处理的广泛信息的必要性至关重要。
通过为变量分配更少的存储,你可以显著减少智能合约的Gas消耗。
一个有效的方法是:使用事件将数据存储在链外而不是直接存储在链上。
使用事件将不可避免地增加每笔交易的Gas成本,因为增加了额外的 emit 函数。然而,不将信息存储在链上的节省远远超过了这个成本。
考虑这个合约,每次执行 vote 函数时都会将所有数据推入 struct。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract InefficientVotingStorage {
struct Vote {
address voter;
bool choice;
}
Vote[] public votes;
function vote(bool _choice) external {
votes.push(Vote(msg.sender, _choice));
}
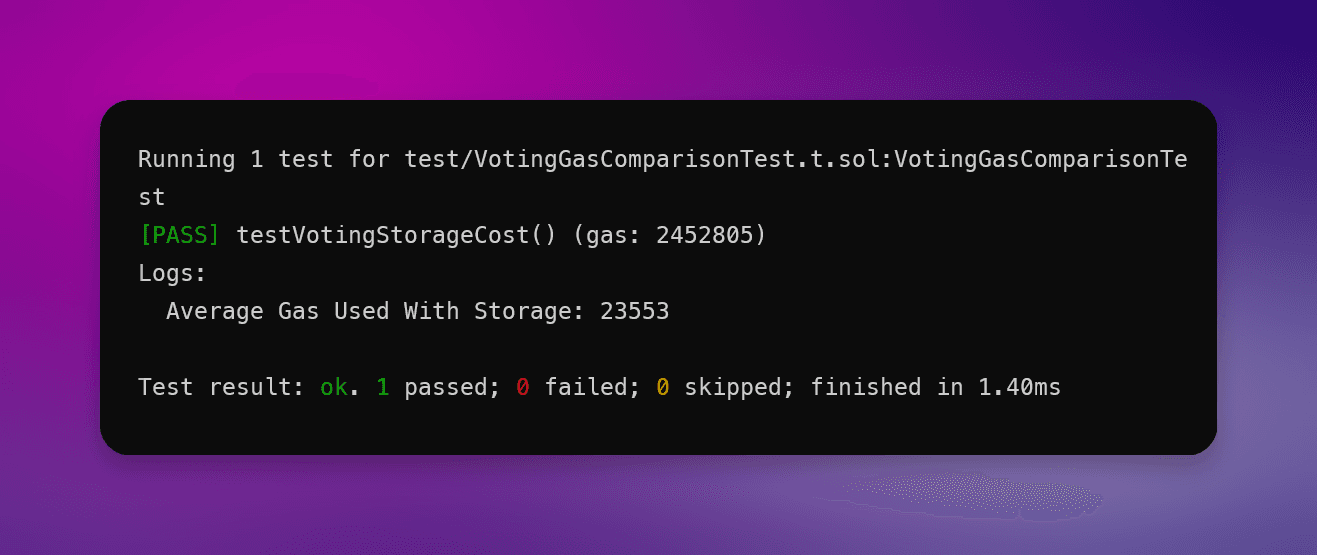
}使用 Foundry 测试 vote 函数 100 次,我们得到以下结果:
另一方面,还有另一个智能合约不会将信息存储在链上,而只是每次调用投票函数时触发一个事件。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract EfficientVotingEvents {
event Voted(address indexed voter, bool choice);
function vote(bool _choice) external {
emit Voted(msg.sender, _choice);
}
}如你所见,仅仅通过最小化链上数据,我们平均节省了 超过 90.34% 的Gas。
如果你想获取离链存储的数据,可以使用类似 Chainlink functions 的方法。
Solidity 最小化链上数据测试:
优化前的Gas使用 : 23,553
优化后的Gas使用 : 2,274
Gas使用平均减少: 90.34%
2. 使用映射而非数组
在 Solidity 中,映射是建立多个信息片段之间关系的极好工具。当涉及数据列表时,Solidity 提供了两种数据类型:数组和映射。
数组存储项目集合,每个项目都分配一个特定索引。另一方面,映射是键值数据结构,通过唯一键提供直接访问数据。
虽然数组在存储向量和类似数据时可能有用,但通常建议尽量使用映射,特别是在需要按需检索的情况下,例如名称、钱包和余额。
理解原因时,我们需要记住, 即使在 EOA 中调用 Solidity 智能合约的读取函数是免费的,在作为交易调用时,仍然会 收取其消耗的Gas费用。如果要检索一个值,我们需要循环访问数组中的每个项目,这样 每消耗的Gas都需支付相关的 EVM 操作码 费用。
为说明这一概念,以下是展示使用数组及其等效映射的示例:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract UsingArray {
struct User {
address userAddress;
uint256 balance;
}
User[] public users;
function addUser(address _user, uint256 _balance) public {
users.push(User(_user, _balance));
}
// 模拟用户检索的函数
function getBalance(address _user) public view returns (uint256) {
for (uint256 i = 0; i < users.length; i++) {
if (users[i].userAddress == _user) {
return users[i].balance;
}
}
return 0;
}
}在上述示例中,我们使用 数组来存储用户地址及其相应的余额。当我们需要检索用户的余额时,我们必须循环迭代每个项目,查看 userAddress 是否与 _userAddress 参数匹配,如果匹配则返回余额。
这不是很麻烦吗?
相反,我们可以使用映射直接访问特定用户的余额,而无需遍历所有数组元素:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract UsingMapping {
mapping(address => uint256) public userBalances;
function addUser(address _user, uint256 _balance) public {
userBalances[_user] = _balance;
}
// 从映射直接获取用户余额的函数
function getBalance(address _user) public view returns (uint256) {
return userBalances[_user];
}
}通过用映射替换数组,我们节省了Gas成本,因为我们不再需要循环访问所有元素,以获取所需的数据。
在本测试中,仅通过将数组替换为映射,我们的Gas优化了 平均 93%。
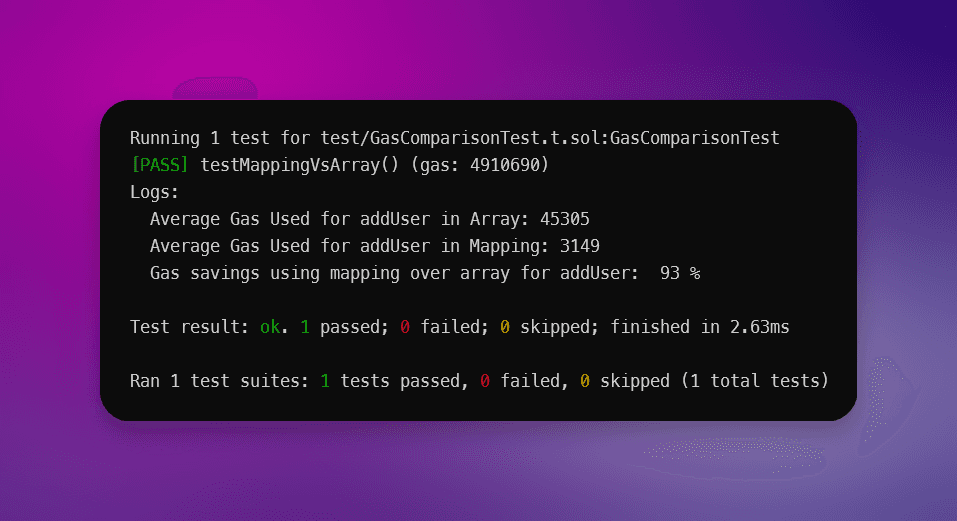
这同样适用于具有高达 89% 节省Gas成本的检索函数。

Solidity 映射 vs 数组测试:
优化前的Gas使用:30,586
优化后的Gas使用:3,081
节省的Gas:89%
测试链接在 Github。
3. 使用常量和不可变变量以降低智能合约的Gas成本
另一个优化 Solidity 智能合约Gas成本的提示是使用常量和不可变变量,因为与其他变量不同,它们不会在以太坊虚拟机(EVM)中消耗存储空间。
它们的值直接编译进智能合约的 bytecode 中,从而 减少与存储操作相关的Gas成本。
在 Solidity 中将变量声明为 "immutable" 或常量,值在合约创建时分配,并且此后变为只读,这使得不可变和常量变量比常规状态变量更具成本效益,因为它们减少了 SLOAD 操作 所需的Gas。
考虑以下示例:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract InefficientRegularVariables {
uint256 public maxSupply;
address public owner;
constructor(uint256 _maxSupply, address _owner) {
maxSupply = _maxSupply;
owner = _owner;
}
}正如你所看到的,我们在不使用常量或不可变关键字的情况下声明了变量 maxSupply 和 owner。运行我们测试 100 次,将获得平均Gas成本 112,222 单元:
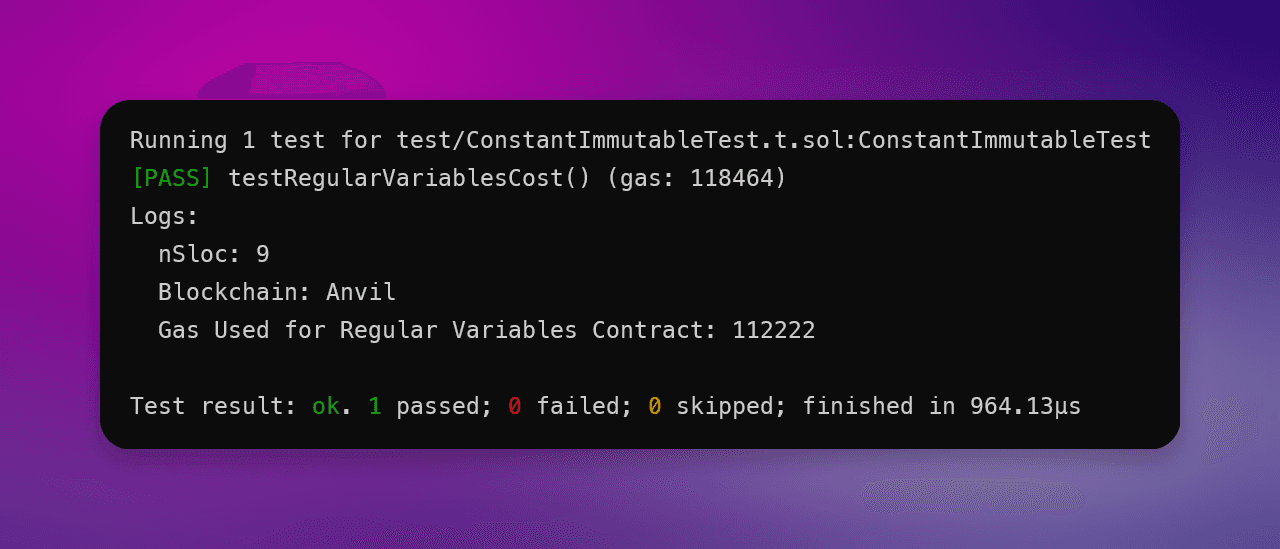
因为 maxSupply 和 owner 是已知值,不打算进行更改,所以我们可以为智能合约声明最大供应量和所有者,这样就不会消耗存储空间。
让我们添加 constant 和 immutable 关键字,稍微改动声明:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract ConstantImmutable {
uint256 public constant MAX_SUPPLY = 1000;
address public immutable owner;
constructor(address _owner) {
owner = _owner;
}
}通过简单地向 Solidity 智能合约中的变量添加 immutable 和 constant 关键字,我们现已使平均Gas消耗优化了 显著 35.89%。
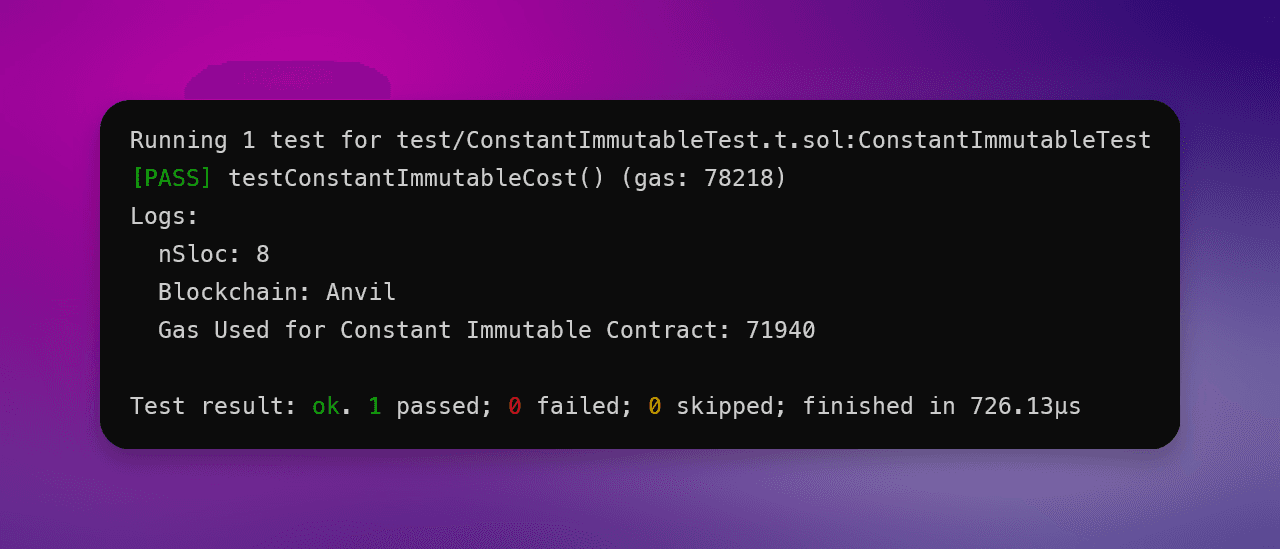
Solidity 常量 vs 不可变测试:
优化前的Gas使用:112,222
优化后的Gas使用:71,940
节省的Gas:35.89%
4. 优化未使用的变量
优化 Solidity 智能合约中的变量是一个明显的Gas优化建议。事实上,很多时候在智能合约中保留不必要的变量会导致 产生不必要的Gas成本。
看看以下例子,展示 一个不当使用变量的情况:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract InefficientContract {
uint public result;
uint private unusedVariable = 10;
function calculate(uint a, uint b) public {
result = a + b; // 作为测试使用的简单操作
// 下一行不必要地改变了状态,浪费了Gas。
unusedVariable = unusedVariable + a;
}
}在这个合约中,unusedVariable 被声明并在 calculate 函数中进行了操作,但它未在其他地方使用,无论是同一个函数还是合约中的其他地方。
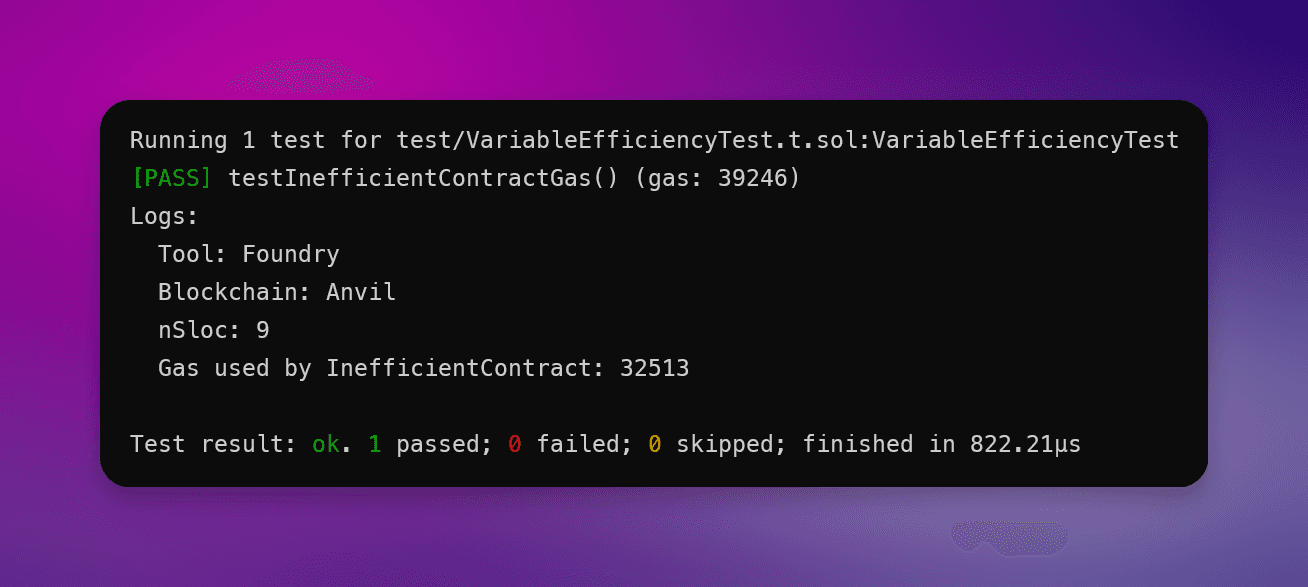
让我们看一下 未使用变量给我们带来了多少Gas成本:
现在让我们通过删除 unusedVariable 来优化我们的合约:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract EfficientContract {
uint public result;
function calculate(uint a, uint b) public {
result = a + b; // 仅执行必要的操作
}
}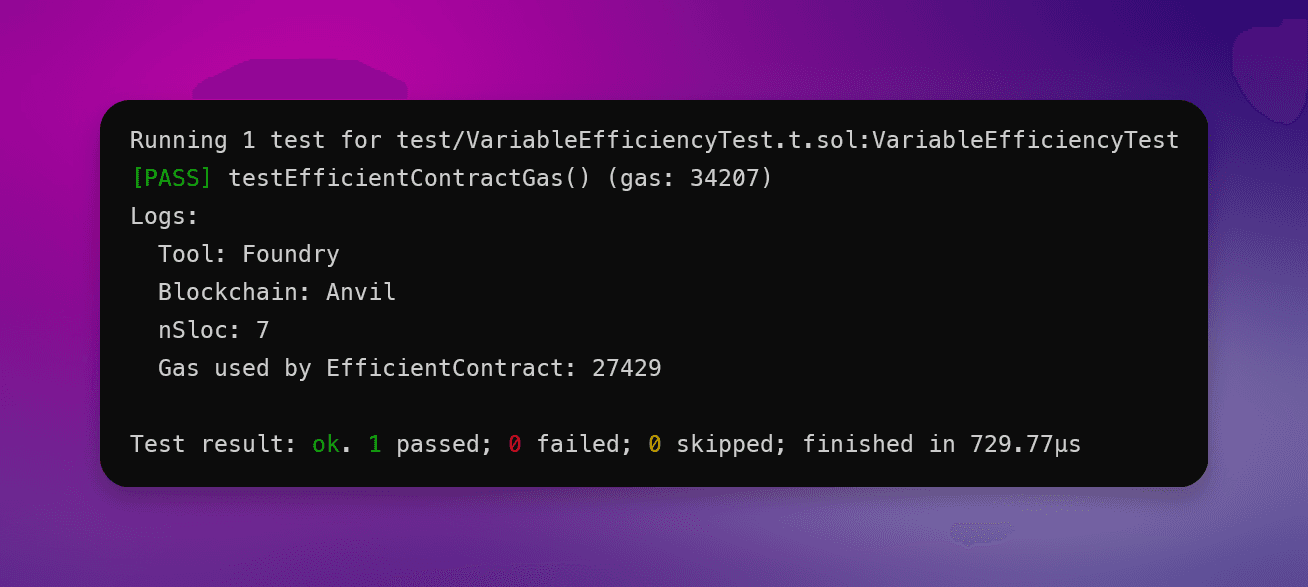
正如你所看到的,仅通过删除一个未使用的变量,我们在智能合约中的Gas成本就 平均减少了 18%。
Solidity 优化未使用变量测试:
优化前的Gas使用:32,513
优化后的Gas使用:27,429
节省的Gas:18%
5. Solidity Gas退款删除未使用的变量
删除未使用的变量并不意味着“删除”它们,因为这会导致内存中的指针出现各种问题--更像是将一个 默认值 重新分配给变量,执行后可以让你获得 15,000 单位的Gas退款。
例如,向 uint 变量发出 delete 指令会简单地将变量的值设置为 0。
让我们看看一个简单的示例,其中我们有一个名为 data 的变量,可以存储一个 uint:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract WithoutDelete {
uint public data;
function skipDelete() public {
data = 123; // 示例操作
// 在这里我们没有使用 delete
}
}在这种情况下,函数结束后我们并未删除“data”变量,平均支出Gas总计为 100,300 单位--仅仅分配给该变量。
现在让我们看看使用 delete 关键字 会发生什么:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract WithDelete {
uint public data;
function useDelete() public {
data = 123; // 示例操作
delete data; // 重置数据为其默认值
}
}仅仅通过删除我们的“data”变量,即 将其值设置为 0, 我们平均节省了 19%的Gas!

Solidity 删除未使用变量测试:
优化前的Gas使用:100,300
优化后的Gas使用:80,406
节省的Gas:19%
6. 使用固定大小的数组而非动态数组以降低智能合约的Gas成本
正如前面提到的,为了优化 Solidity 智能合约的Gas,你应尽量使用映射。
然而,如果你发现需要在合同中使用数组,最好是尝试 使用固定大小的数组,避免使用动态数组,因为动态数组可以无限增长,从而导致更高的Gas成本。
简单来说,固定大小的数组具有已知长度,因此当 EVM 需要存储时,不需要在存储中随时保持数组的长度信息:

另一方面,动态大小的数组可以增加大小,因此 EVM 每次添加新条目时都需要跟踪和更新它们的长度:

让我们看一下以下代码,其中我们声明一个动态大小的数组并通过 updateArray 函数更新它:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract DynamicArray {
uint256[] public dynamicArray;
constructor() {
dynamicArray = [1, 2, 3, 4, 5]; // 初始化动态数组
}
function updateArray(uint256 index, uint256 value) public {
require(index < dynamicArray.length, "Index out of range");
dynamicArray[index] = value;
}
}注意我们使用了 require 语句来确保提供的索引不是超出固定大小数组的范围。
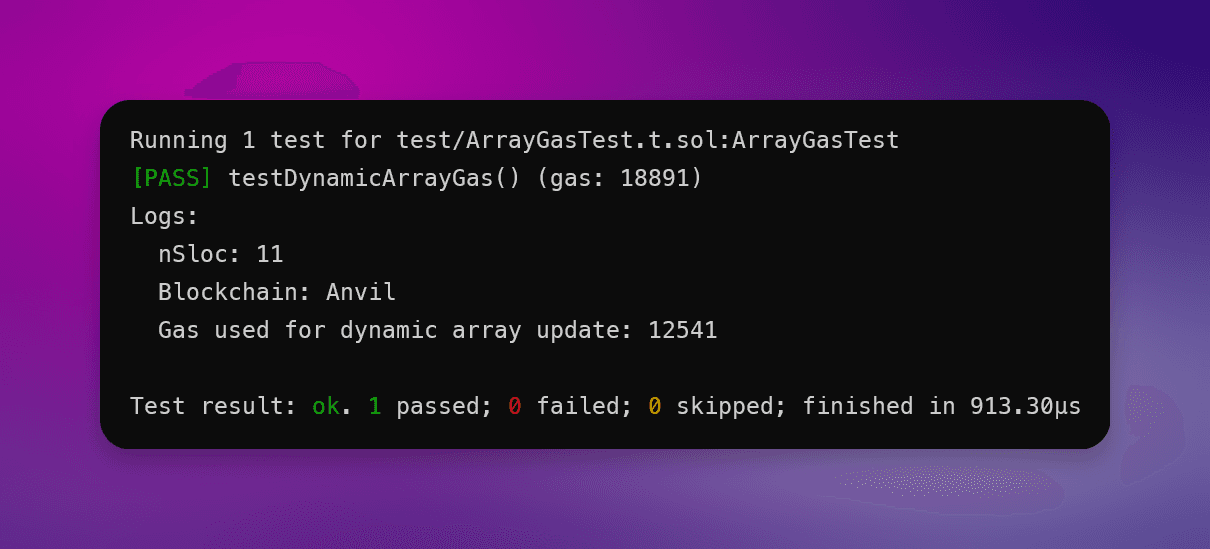
对测试进行 100 次运行,平均支出 12,541 单位Gas。
现在,让我们将我们的数组修改为固定大小的 5:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract FixedArrayContract {
uint256[5] public fixedArray;
constructor() {
fixedArray = [1, 2, 3, 4, 5]; // 初始化固定大小的数组
}
function updateArray(uint256 index, uint256 value) public {
require(index < fixedArray.length, "Index out of range");
fixedArray[index] = value;
}
}在此示例中,我们定义了一个长度为 5 的 uint256 类型固定大小数组。updateArray 函数与以前一样,允许我们更新数组中特定索引的值。
EVM 现在将知道状态变量 fixedArray 的大小为 5,并将为其分配 5 个槽,而不需要在存储中保存其长度。
进行相同的测试 100 次,仅通过使用固定数组而非动态数组,我们节省了 17.99% 的Gas成本。

优化未使用变量测试:
优化前的Gas使用:12,541
优化后的Gas使用:10,284
节省的Gas:17.99%
7. 避免使用低于 256 位的变量
在 Solidity 中,使用 uint8 而不是 uint256 在某些上下文中可能效率较低并且潜在的成本更高,主要是 由于以太坊虚拟机(EVM)的运行方式。
EVM 的字长为 256 位。 这意味着对 256 位整数 ( uint256) 的操作通常是最有效的,因为它们与 EVM 的本机字大小对齐。当使用较小的整数,如 uint8 时,Solidity 通常需要执行额外的操作以将这些较小类型与 EVM 的 256 位字大小对齐。因此,这可能导致更复杂的代码和更低的效率。
虽然在优化存储时使用像 uint8 这样的较小类型(因为 多个 uint8 变量可以打包到单个 256 位存储槽中)可能有利,但这种好处通常只体现在存储中,而不体现在内存或堆栈操作中。
此外,对于计算,转换成和从 uint256 的转换可能会抵消存储节省。
uint8 public a = 12;
uint256 public b = 13;
uint8 public c = 14;
// 由于 EVM 对 256 位操作的优化,
// 这样可能导致效率低下和增加的Gas成本。
总之,尽管使用 uint8 似乎是节省空间并可能降低成本的好方法,但实际上,由于 EVM 对 256 位操作的优化,它可能导致效率低下和增加的Gas成本。
uint256 public a = 12;
uint256 public b = 14;
uint256 public c = 13;
// 更好的解决方案
你可以创建调用函数 f(uint8 x) 的事务,传递原始字节参数 0xff000001 和 0x00000001。这两者都被提供给合约,并将对 x 显示为数 1。然而,msg.data 在两种情况下都会有所不同。因此,如果你的代码实现了一些诸如 keccak256(msg.data) 的逻辑,则会获得不同的结果。
8. 将小于 256 位的变量打包在一起
正如以前所说,通常使用低于 256 位的整数或无符号整数变量被认为比 256 位的变量效率低,但在某些情况下,你被迫使用较小的类型,例如当 使用布尔值时,布尔值 占用 1 字节或 8 位。
在这些情况下,通过根据存储空间声明你的状态变量,Solidity 将允许你打包它们,并将它们全部存储在同一个槽中。
注意:变量打包的好处通常只在存储中可见,而不在内存或堆栈操作中。
让我们考虑以下示例:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract NonPackedVariables {
bool public a = true;
uint256 public b = 14;
bool public c = false;
function setVariables(bool _a, uint256 _b, bool _c) public {
a = _a;
b = _b;
c = _c;
}
}考虑之前提到的 Solidity 中每个存储槽具有 32 字节(等于 256 位)的空间,在上面的示例中,我们将须需 3 个存储槽来存储我们的变量:
- 1 个存储我们的布尔值 “a” (1 字节)
- 1 个存储我们的 uint256 “b”(32 字节)
- 1 个存储我们的布尔值 “c” (1 字节)。
每个使用的存储槽都会产生Gas成本,因此我们花费的Gas是以前的 3 倍。
考虑到两个布尔变量的组合大小为 16 位,比单个存储槽的容量少 240 位,我们可以指导 Solidity 将变量“a”和“c”存储在同一个槽中,也就是说:我们可以“打包”它们。
将变量打包可降低智能合约部署的Gas成本,因为减少了存储状态变量所需的槽位数量。
我们可以通过重新排序声明来打包这些变量,如下所示:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract PackedVariables {
bool public a = true;
bool public c = false;
uint256 public b = 14;
function setVariables(bool _a, bool _c, uint256 _b) public {
a = _a;
c = _c;
b = _b;
}
}Solidity 将打包两个布尔变量 到同一个槽中,因为它们 小于 256 位 或 32 字节。
话虽如此,请记住,我们仍然可能在储存空间上浪费。EVM 在处理 256 位字时进行操作,并且必须执行操作以规范较小的字。这可能抵消任何潜在的Gas节省。
对 100 次迭代进行测试,得出的 平均优化为 13%。
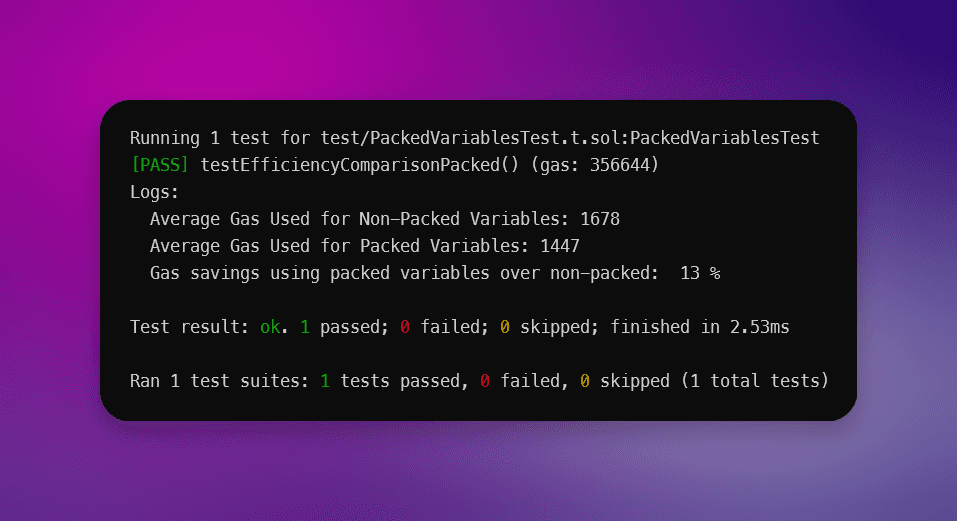
变量打包测试:
优化前的Gas使用:1,678
优化后的Gas使用:1,447
节省的Gas:13%
9. 使用外部可见性修饰符
在 Solidity 中,为函数选择最合适的可见性 是优化智能合约Gas消耗的有效措施。特别是,使用 external 可见性修饰符可能比 public 更节省Gas。
原因与公共函数如何处理参数及如何将数据传递给这些函数有关。
external 函数可以从 calldata 读取, 这是 EVM 中的一个只读的临时区域,用于存储函数调用参数。使用 calldata 对于外部调用更具Gas效率,因为避免了 将数据从交易数据复制到内存。
另一方面,声明为public的函数 可以从内部和外部调用。当外部调用时,它们的行为类似 于external 函数,参数通过交易数据传入。然而,当内部调用时,参数是在内存中传递,而不是在 calldata 中。
简而言之,由于 public 函数需要同时支持内部和外部调用,因此它们 无法限制仅访问calldata。
考虑以下 Solidity 合约:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract PublicSum {
function calculateSum(
uint[] memory numbers
) public pure returns (uint sum) {
for (uint i = 0; i < numbers.length; i++) {
sum += numbers[i];
}
}
}该函数计算数组数字的总和。由于函数是公共的,它必须从内存中接受一个数组,这在 array 较大时将会变得昂贵。
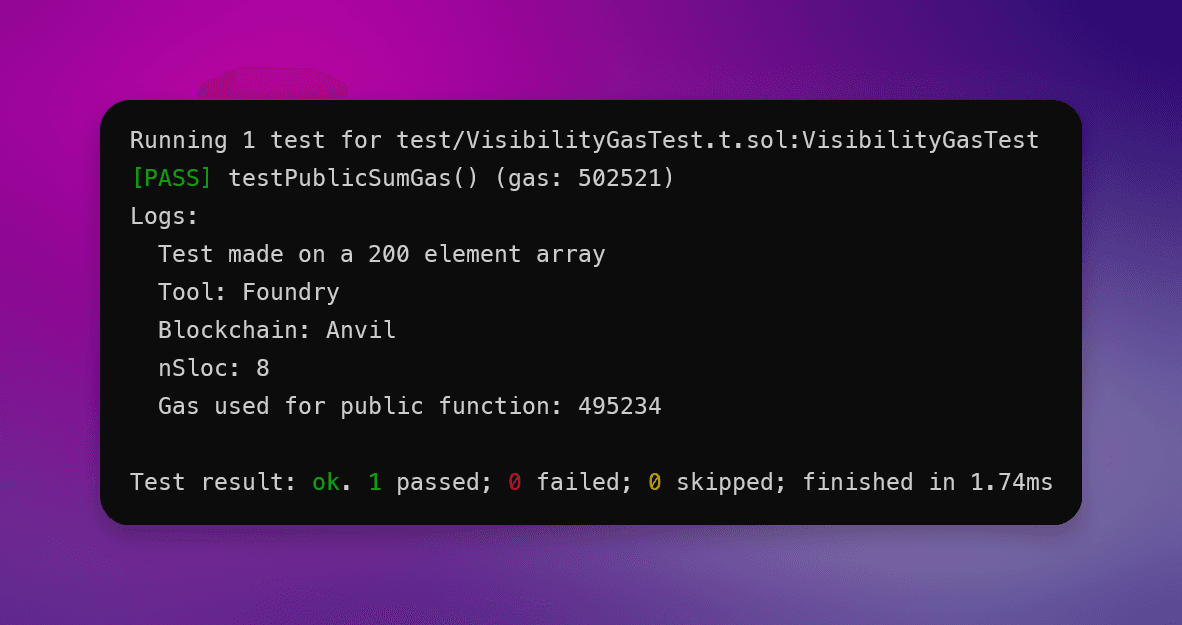
现在让我们通过将该函数修改为外部函数来改进它:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract ExternalSum {
function calculateSum(
uint[] calldata numbers
) external pure returns (uint sum) {
for (uint i = 0; i < numbers.length; i++) {
sum += numbers[i];
}
}
}合约链接。
通过将函数更改为 external,我们现在可以接受来自 calldata 的数组,使处理大型数组时更具Gas效率。
这强调了在 Solidity 智能合约中适当使用可见性修饰符来优化Gas使用的重要性。
在这种情况下,修改你的 Solidity 函数修饰符节省了 平均 0.3% 的Gas单位每次调用。
优化未使用变量测试:
优化前的Gas使用:495,234
优化后的Gas使用:493,693
节省的Gas:0.3%
测试链接在 Github。
10. 启用 Solidity 编译器优化
Solidity 自带的编译器提供了易于修改的设置来优化你的代码库编译代码。
将 Solidity 编译器 想象成个魔法师的咒语书,你智能修改其选项可以创造出 显著减少Gas使用的优化魔药。
--optimize 选项就是你可以施加的咒语之一。
启用时,它会执行数百次运行,简化你的 bytecode 并将其转化为更节省Gas的 精简版本。
可以调整编译器以在部署成本和运行时成本之间取得平衡。
例如,使用 --runs 命令,你可以定义合约的 预期执行次数。
- 更高的数量:编译器优化以降低合约执行期间的Gas成本。
- 较低的数量:编译器优化以降低合约部署期间的Gas成本。
solc --optimize --runs=200 GasOptimized.sol通过使用 --optimize 标志并指定 --runs=200,我们指示编译器优化代码,以减少执行合约时的Gas消耗,假设 incrementCount 函数周围有大约 200 次执行。
请确保根据你的应用程序的独特需求调整这些设置。
11. 额外的 Solidity Gas优化提示:使用 Assembly*
当你编译一个 Solidity 智能合约时,编译器将其转变为字节码,这是一系列 EVM(以太坊虚拟机)的操作码。
通过使用 assembly,你可以编写在操作码层面上紧密对齐的代码。
虽然在如此低级别编写代码可能不是最容易的任务,但好处在于能够 手动优化操作码,从而 在某些情况下比 Solidity 字节码表现得更好。
这种优化级别使合约执行的 效率 和 有效性 更高。
在一个简单示例中,有两个函数用于添加两个数字,一个使用纯 Solidity,另一个使用 Assembly,虽然有小差别,但 assembly 的成本仍然更低。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract InefficientAddSolitiy {
// 标准 Solidity 函数添加两个数字
function addSolidity(uint256 a, uint256 b) public pure returns (uint256) {
return a + b;
}
}现在实现 Assembly:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract EfficientAddAssembly {
// 使用 assembly 添加两个数字的函数
function addAssembly(
uint256 a,
uint256 b
) public pure returns (uint256 result) {
assembly {
result := add(a, b)
}
}
}我们想特别提到 Huff,这使我们能够用更美观的语法编写 assembly。
注意:即使使用 Assembly 可能有助于优化智能合约的Gas成本,但它也可能导致代码不安全。我们 强烈建议在部署前让你的合约接受 智能合约安全专家 审核。
结论
优化 Solidity 的Gas使用对于 创建成本有效、 高性能且可持续的 Solidity 智能合约 至关重要。通过在本指南中实施你所学习的 Solidity Gas优化提示,你可以降低交易成本,提高可扩展性,并增强合约的整体效率。
- 原文链接: cyfrin.io/blog/solidity-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





