IDL Guesser:从封闭源码的Solana程序中恢复指令布局
- Sec3dev
- 发布于 2025-04-05 20:48
- 阅读 2815
该文章详细介绍了在封闭源码的Solana程序中,利用IDL Guesser工具进行指令定义和账户信息的自动化恢复过程。该工具通过分析Anchor框架生成的代码模式,成功提取指令、帐户和参数信息,旨在帮助安全研究人员发现潜在漏洞,同时指出现有的开发挑战和未来的改进方向。
The Solana 生态系统非常活跃,但许多程序尚未开源。Syndica 在 2024 年 2 月编制的统计数据显示,几乎有 50% 的 Solana 前 100 名计算单元程序发布了其接口定义语言 (IDL)。然而,在前 1000 名程序中,这个数字仅降至 20%。此外,即使已发布的 IDL 有时也并不可靠。已经发生过发布的 IDL 过时且与部署的链上程序不一致的情况。
作为审计员和安全研究人员,当我们识别到潜在的漏洞有趣模式时,通常会寻找其他程序中类似的弱点。然而,缺乏源代码或准确的 IDL,这一过程往往限制在基本的 GitHub 搜索,常常会得到未维护的项目。
大多数 Solana 程序是用 Rust 编写的,并被编译为 Solana 字节码格式 (sBPF),这是一种基于 eBPF 的格式。反向工程编译后的 Rust 是具有挑战性的,sBPF 相关的反向工程工具链仍在发展中。这种不透明性不仅妨碍了恶意行为者的活动,还减缓了白帽黑客和安全研究人员识别和负责任地披露漏洞的工作。
要分析任何闭源的 Solana 程序——无论是动态还是静态——根本前提是理解 如何与之交互。这意味着需要了解其指令、每个指令所需的账户以及这些账户的属性(如签名者或可写状态)。
为了应对这些挑战,我们的安全研究员 Qi Qin 引领了该工作,开发了一个名为 IDL Guesser 的原型工具。该工具旨在自动从闭源 Solana 程序二进制文件中恢复指令定义、所需账户(包括签名/可写标志)和参数信息。
本博客概述了 IDL Guesser 背后的方法,并讨论未来改进的潜在领域。
利用 Anchor 模式进行反向工程
由于大部分 Solana 的开发使用 Anchor 框架——而 IDL 的概念源于此——IDL Guesser 当前特别关注基于 Anchor 的程序。Anchor 通过为常见任务和检查提供宏和辅助函数,显著简化了开发。更重要的是,这导致了可预测、标准化的代码结构在编译输出中出现,这些特征我们可以通过模式匹配来利用。
为了调试目的,Anchor CLI 甚至提供了一个 anchor expand 命令,可以揭示其宏生成的代码。查看这些扩展代码可以为我们所采用的 Anchor 模式提供宝贵的洞察,从而指导我们的反向工程工作。
入口点和调度逻辑
让我们来看看典型 Anchor 程序在宏扩展后的入口点结构:
#[no_mangle]
pub unsafe extern "C" fn entrypoint(input: *mut u8) -> u64 {
let (program_id, accounts, instruction_data) = unsafe {
::solana_program::entrypoint::deserialize(input)
};
match entry(&program_id, &accounts, &instruction_data) {
Ok(()) => ::solana_program::entrypoint::SUCCESS,
Err(error) => error.into(),
}
}
pub fn entry<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::solana_program::entrypoint::ProgramResult {
try_entry(program_id, accounts, data)
.map_err(|e| {
e.log();
e.into()
})
}
fn try_entry<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::Result<()> {
if *program_id != ID {
return Err(anchor_lang::error::ErrorCode::DeclaredProgramIdMismatch.into());
}
if data.len() < 8 {
return Err(anchor_lang::error::ErrorCode::InstructionMissing.into());
}
dispatch(program_id, accounts, data)
}
fn dispatch<'info>(
program_id: &Pubkey,
accounts: &'info [AccountInfo<'info>],
data: &[u8],
) -> anchor_lang::Result<()> {
let mut ix_data: &[u8] = data;
let sighash: [u8; 8] = {
let mut sighash: [u8; 8] = [0; 8];
sighash.copy_from_slice(&ix_data[..8]);
ix_data = &ix_data[8..];
sighash
};
use anchor_lang::Discriminator;
match sighash {
instruction::InitializeConfig::DISCRIMINATOR => {
__private::__global::initialize_config(program_id, accounts, ix_data)
}
instruction::InitializePool::DISCRIMINATOR => {
__private::__global::initialize_pool(program_id, accounts, ix_data)
}
// ... 其他指令
}
}
程序首先反序列化原始输入。它执行基本检查(例如验证 _program_id_ 和确保 _instruction_data_ 至少有 8 个字节)然后进入 dispatch 函数。在 dispatch 内, _instruction_data_ 的前 8 个字节被解释为指令 discriminator。这个 discriminator 决定了应该执行哪个特定的指令处理函数。
根据 Anchor 的文档,这个 8 字节的 discriminator 是从指令的命名空间和名称导出的(例如,_global:initialize_config_),通过取其 SHA-256 哈希的前 8 个字节。IDL Guesser 采用了一种更简单的方法:专注于首先提取 指令名称,然后通过 Anchor 的标准哈希方法计算相应的 discriminators,而不是试图从编译代码中提取这些原始 discriminator 字节(这可能很复杂)。
识别指令处理器
我们如何找到指令名称及其对应的处理函数?Anchor 提供了另一个有用的模式。考虑一个典型指令处理器的开头:
pub fn initialize_config<'info>( /* ... */ ) -> anchor_lang::Result<()> {
// 记录指令名称 - 对我们来说是一个关键模式!
::solana_program::log::sol_log("Instruction: InitializeConfig");
// 反序列化特定指令参数
let ix = instruction::InitializeConfig::deserialize(&mut &__ix_data[..])
.map_err(|_| /* ... */ )?;
let instruction::InitializeConfig { /* ... 参数 ... */ } = ix;
// 通过 try_accounts 处理账户
let mut __bumps = /* ... */;
let mut __reallocs = /* ... */;
let mut __remaining_accounts: &[AccountInfo] = __accounts;
let mut __accounts = InitializeConfig::try_accounts(
__program_id,
&mut __remaining_accounts,
__ix_data,
&mut __bumps,
&mut __reallocs,
)?;
// ...
}
Anchor 在每个处理器开头插入了一个 _sol_log_ 调用,以记录指令的名称(例如 "Instruction: InitializeConfig"),用于日志解析。这种日志记录提供了一个我们可以在编译的二进制文件中搜索的独特签名。
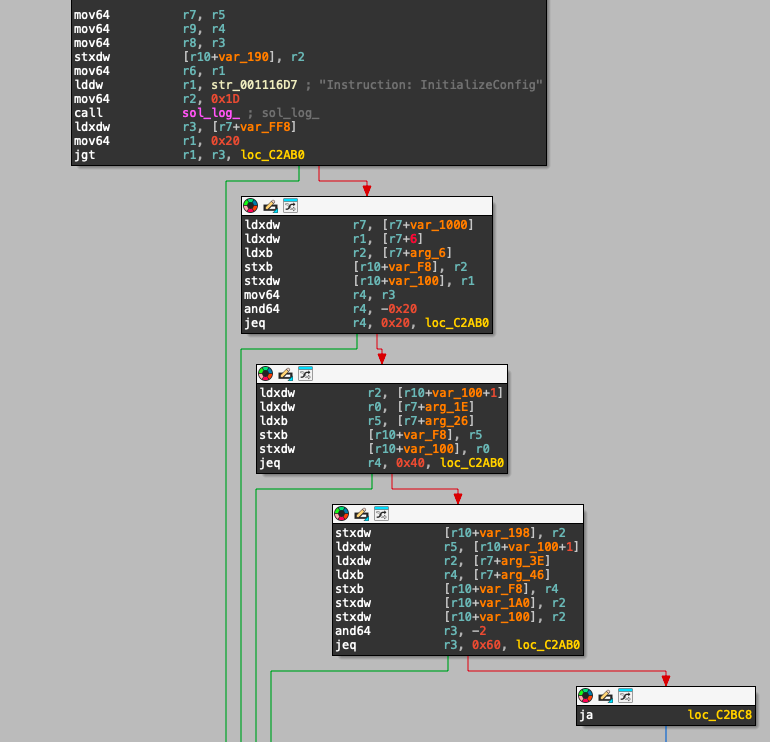
用于记录指令名称 InitializeConfig 的 sol_log 系统调用序列。
在汇编层面(如上所示),这个日志调用通常会转换成特定的 lddw、 mov64 和 call 指令集合,以使用指令名称字符串调用 _sol_log_ 系统调用。
通过识别这些模式,IDL Guesser 可以可靠地定位指令处理器的入口点并提取它们的名称。
提取账户信息
在初始日志记录和参数反序列化后(这通常被编译器内联),处理器通常会调用一个对应的 _try_accounts_ 函数。这个函数负责解析和验证指令所需的账户。
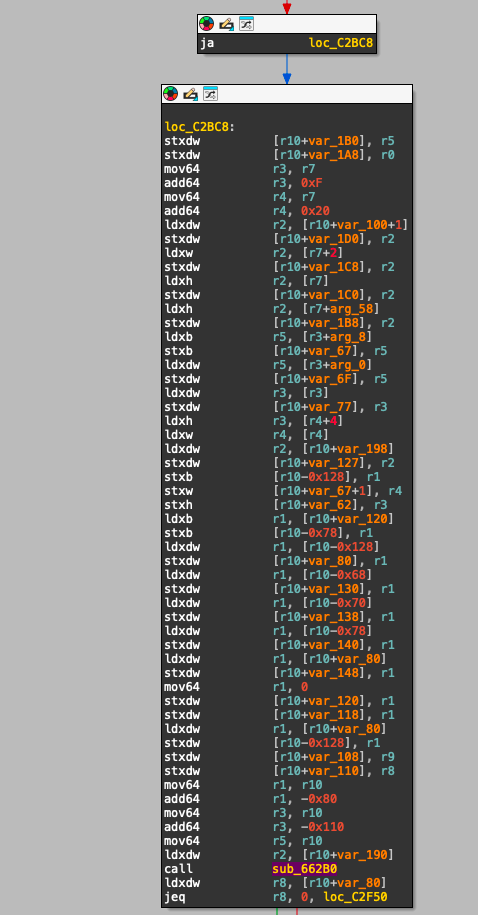
参数反序列化后的 try_accounts 函数调用( sub_662B0 这里)。
让我们看看 Accounts 结构及生成的 _try_accounts_ 函数,以 _initialize_config_ 为例:
// 账户定义
#[derive(Accounts)]
pub struct InitializeConfig<'info> {
#[account(init, payer = funder, space = WhirlpoolsConfig::LEN)]
pub config: Account<'info, WhirlpoolsConfig>, // 要初始化
#[account(mut)]
pub funder: Signer<'info>, // 必须是可变并且是签名者
pub system_program: Program<'info, System>, // 系统程序
}
// 生成的 try_accounts 函数(简化)
fn try_accounts( /* ... */ ) -> anchor_lang::Result<Self> {
// 检查是否提供了足够的账户
if __accounts.is_empty() {
// 错误 3005
return Err(anchor_lang::error::ErrorCode::AccountNotEnoughKeys.into());
}
// 处理 'config' 账户(索引 0) - 后续的检查应用
let config = &__accounts[0];
*__accounts = &__accounts[1..];
// 使用签名者的 try_accounts 处理 'funder' 账户
let funder: Signer = anchor_lang::Accounts::try_accounts(/* ... */)
.map_err(|e| e.with_account_name("funder"))?; // 将 "funder" 添加到错误信息中
// 处理 'system_program' 账户
let system_program: Program<System> = anchor_lang::Accounts::try_accounts(/* ... */)
.map_err(|e| e.with_account_name("system_program"))?; // 添加 "system_program"
// 应用约束检查
if !config.is_writable { // 通过 init 间接定义的检查
// 错误 2000
return Err(anchor_lang::error::ErrorCode::ConstraintMut.into().with_account_name("config"));
}
if !config.is_signer { // 通过 init 间接定义的检查
// 错误 2002
return Err(anchor_lang::error::ErrorCode::ConstraintSigner.into().with_account_name("config"));
}
// ... 其他检查,如租金豁免(错误 2005)、所有者等。
if !funder.is_writable { // 通过 #[account(mut)] 定义的检查
// 错误 2000
return Err(anchor_lang::error::ErrorCode::ConstraintMut.into().with_account_name("funder"));
}
// ... funder.is_signer 的检查发生在其自己的 try_accounts 内
Ok(Self { config, funder, system_program })
}
_try_accounts_ 函数执行了几项关键操作:
- 它迭代预期的账户,尝试根据其类型(
Account、Signer、Program等)进行解析。如果在嵌套的 _try_accounts_ 调用内解析失败(例如对于funder),Anchor 会便利地将 账户名称(例如 "funder")附加到错误信息中。这使我们可以通过查找这些特定错误处理模式来提取账户名称。 - 它根据在
Accounts结构中定义的属性应用约束检查(mut、signer、 _has_one_、seeds、owner、租金豁免等)。重要的是,每个约束违反通常映射到 Anchor 的 唯一ErrorCode(例如,ConstraintMut是 2000,ConstraintSigner是 2002)。
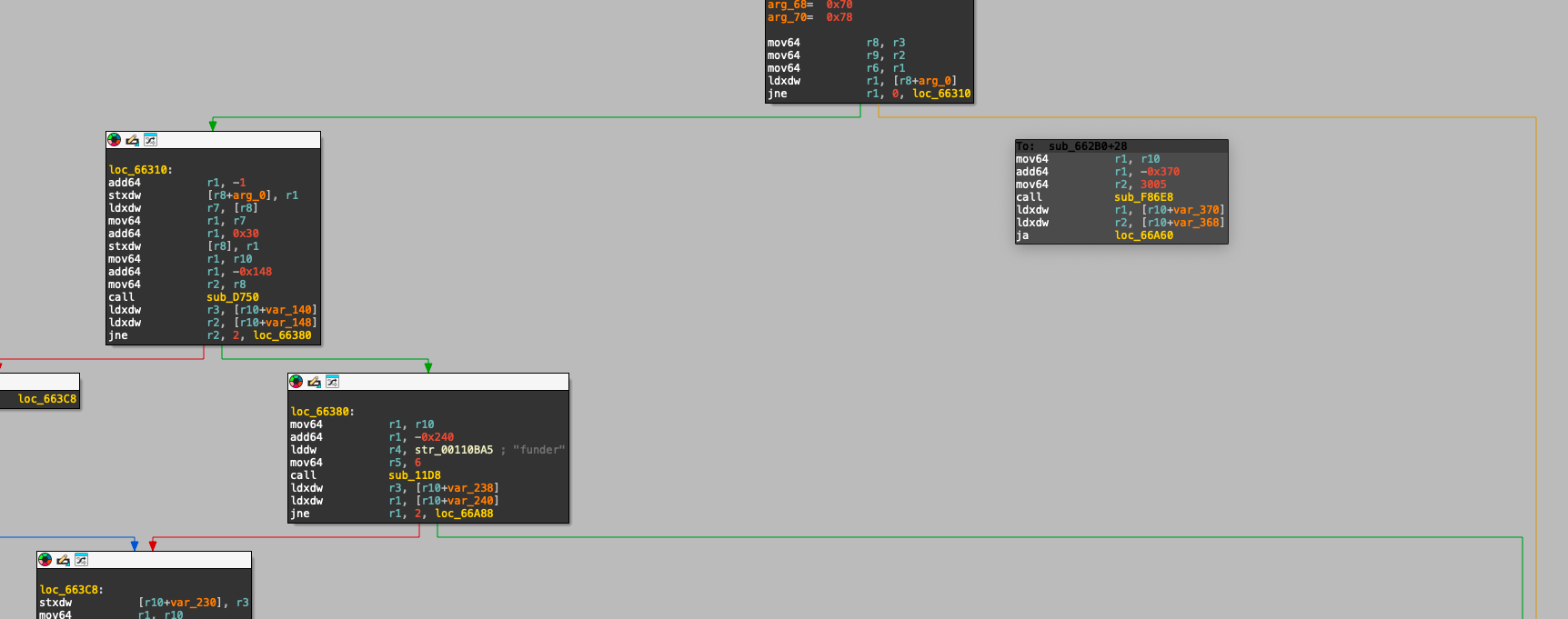
检查账户的密钥数量是否足够,以防需要初始化账户,如果失败则转向错误 3005。
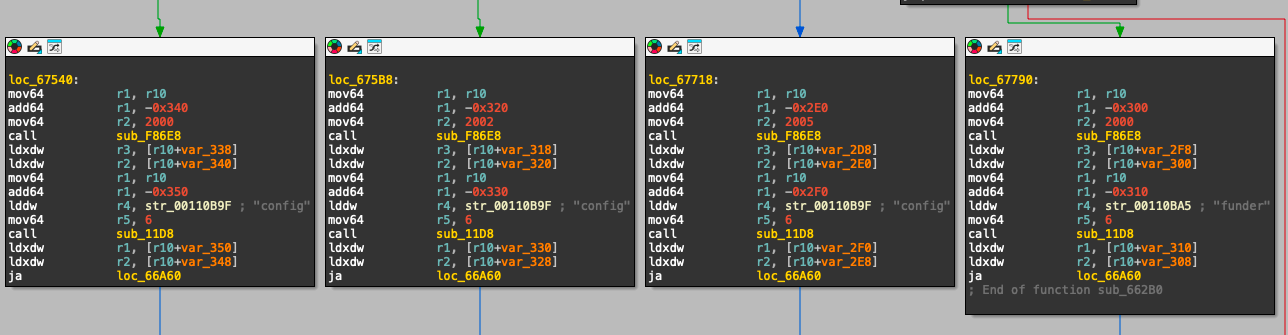
约束检查条件跳转,导致特定错误代码,如 2000( ConstraintMut)或 2002( ConstraintSigner)。
通过分析 _try_accounts_ 函数的控制流图 (CFG),特别是遵循 "happy path"(成功执行),IDL Guesser 可以大致拼凑出所需的账户:
- 账户处理的顺序揭示了预期的账户顺序。
- 与错误信息关联的字符串字面量(如 "funder")揭示了账户名称。
- 达到失败路径的特定错误代码(如 2000、2002、2005)表明应用于每个账户的约束(可变、签名者等)。
提取参数
尽管提取指令名称和账户详细信息依赖于相对明显的模式(日志字符串、错误代码、特定函数调用),但恢复 指令参数 的信息却更困难。
Anchor 通常不会生成特定于单个参数反序列化失败的详细错误信息。这意味着在 Rust 源代码中定义的原始参数名称在编译过程中通常会丢失。此外,负责从 _ix_data_ 切片顺序反序列化参数的代码通常会被编译器优化和内联,使得可靠的汇编级模式匹配非常困难。
一个更有希望的未来方向可能涉及符号执行,以通过分析 _ix_data_ 的消费方式来确定每个参数的预期字节长度和可能的类型。
然而,在 IDL Guesser 原型中,采用了一种替代且更简单的方法,利用动态分析:由于 Solana 指令数据通常较短,受限于交易大小限制,我们可以逐步探测处理器函数。通过略微增加模拟输入数据的长度,并观察执行踪迹的变化(例如,通过之前失败的检查),我们可能推断边界以及在新的反序列化步骤成功后参数的可能类型。
这种迭代反馈循环技术还用于重建账户的内部布局。具体细节在此不作赘述,但感兴趣的读者可以在源代码中探索相关实现。此外,它可能被用来验证或细化恢复的指令和账户信息。
实现细节
在识别这些模式后,实现涉及对 sBPF 字节码进行反汇编,并在指令序列和 CFG 上进行模式匹配。我们依靠现有的 solana-sbpf 项目构建(见 static_analysis.rs),该项目为 Solana 程序分析提供了基础。
我们对基础静态分析实现进行了某些修改。原始版本往往在每次函数调用后过度分割基本块。我们调整了这一点,以创建更大、更易管理的块。此外,我们还特别处理了类似 abort 或 panic 的系统调用。这些变化导致生成更精确的 CFG,简化了模式匹配过程。
完整实现是开源的,位于 IDLGuesser 代码库。
当前代码处理了许多常见场景,但也包括一些边缘案例的逻辑,如 UncheckedAccount 和 Sysvar 账户。
对于这些的 _try_accounts_ 逻辑通常被编译器内联,创建与 init 账户相似的模式。然而,特别是对于连续的多个 UncheckedAccount 实例或更复杂的结构(如可选账户和嵌套账户上下文),这一原型尚未完全处理。
结论
IDL Guesser 展示了通过利用框架的代码生成模式和简单动态分析,从闭源基于 Anchor 的 Solana 程序中恢复重要结构信息(指令及其相应账户和参数信息)的可行方法。虽然原型存在局限性,并可能在复杂情况下需要手动反向工程和与链上数据的交叉引用,但它成功地为许多程序恢复了类似 IDL 的信息。
我们发现这种能力是有帮助的,使得对交易数据的更广泛分析成为可能,并促进了对与账户约束相关的基本漏洞(例如,缺少签名者检查)的自动扫描。通过揭示闭源程序的内部工作原理,我们希望像 IDL Guesser 这样的工具可以为保护 Solana 生态系统的努力做出贡献。
- 原文链接: sec3.dev/blog/idl-guesse...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





