Filecoin SpaceRace 一阶段踩坑记录
- 阳建
- 发布于 2020-09-24 17:15
- 阅读 7721
Filecoin 发起的 SpaceRace 一阶段已经在 9月14日结束。全球数百名矿工,投入了上万机器,居然在 3 个星期完成了 210PB 的数据密封。成绩超出我们的预测,也亮瞎了官方的眼了。 我们还是低估了全球矿工(应该是中国矿工)的热情了。各路矿工各显神通的拼命干,你 996,我就 007,直接目的大家都是一样的,就是在这次测试中跑出一个好成绩。 只不过大家背后的初衷是所有区别的,有的矿工参加比赛是为销售服务的,而有的矿工(比如我们)就是为了更好的测试自己方案和产品的稳定性。
测试的过程中大家都遇到了各种问题,链的问题,网络的问题,存储的问题,订单成功率的问题... 有趣的是,官方最后居然放水,"雨露均沾",让大部分的矿工或多或少都分到了一些奖励。
不管如何,比赛终于结束了,趁着周末有点时间把本次 SpaceRace 做个挖(踩)矿(坑)总(记)结(录)。
顺便说一下:SpaceRace Phase2 的赛道 1 已经于 9 月15号开始,时间也是三周,主要鼓励存储矿工继续测试和扩大网络规模。 赛道 2 将于 9月24日启动,10月15日截至,仅适用于存储客户和开发者群体。同时官方也透露赛道 2 的信息会记入主网,意味着可以主网上线无缝对接,说明主网上线大局已定。
1. 硬件兼容问题
凡是报类似指令错误的,一般都是因为编译的机器和运行的机器的 CPU 指令架构不一样。
(1). 众所周知,用 Intel CPU 编译的 Lotus 即使在 AMD 机器上跑也是不能发挥 sha256 加速功能的。想要启动 AMD 机器的 sha 加速,需要使用 AMD 机器编译,并且需要加上 FFI_BUILD_FROM_SOURCE=1
环境变量:
env RUSTFLAGS="-C target-cpu=native -g" FFI_BUILD_FROM_SOURCE=1 make clean all(2). Intel 机器需要去掉 FFI_BUILD_FROM_SOURCE=1 环境变量(SR1之前的版本可以加这个变量),直接使用 make clean all 就行了,否则运行 lotus daemon 的时候可能会报 asm 指令错误。
(3). 不同的指令集合的 Intel CPU 之间要在各自的机器单独编译,比如我们测试的 Intel E5 V2, V3, V4 机器之间就互相不兼容。同一个型号的机器要单独编译一个版本。 AMD CPU 系列的机器只需要编译一个版本就可以在不同的机器(家用机和服务器)上跑,至少我们测试的几款机器是这样的(Ryzen 3600x,3800x,3950/60/70x, EPYC 73xx,74xx,75xx,7fxx)。
2. 同步问题
这是一个非常重要而又常常容易被人忽视的问题。因为同步不仅涉及到你的消息能否正常上链的问题,还可能影响到你出块是否稳定。SR1 期间,由于版本更新比较频繁,所以同步的问题也层不穷。 尤其是最后一周的演习,如果你不跟着官方的指示及时升级客户端的话,你几乎就没法正常同步区块。我们也曾被同步问题困扰过好几天,那几天我们矿工的算力几乎就没有增长。反而因为同步问题 消息无法正常上链,导致连续几天出现负增长。一般来说,引起同步出错的直接原因有以下几个:
- lotus 软件的Bug
- lotus 客户端的版本太低,需要升级到最新版本
- 机器同步的速度不够快,因为 lotus chain 每个 tipset(同一个高度) 一般都包含了几个区块,所以一旦你落后比较多,你就不知道该跟谁走了,走着走着你就迷路了,然后就离大部队 月来越远,卡在某个分叉点无法同步数据了。
至于机器为什么同步不够快,这个跟网速,CPU 和硬盘都有关系,篇幅原因,这里就不具体展开了。有兴趣的同学可以给邮件或者 WeChat 探讨。
3. 消息(Message)上链问题
信息上链失败的原因有很多,典型的有以下几种:
- 钱包余额不够支付 Gas 费(手续费),这种除了充值别无他法。
- 钱包余额足够,但是给的手续费太低了,这种你需要提高手续费。使用
lotus mpool replace命令可以修改指定交易的手续费。 - 区块链待打包的交易太多,也就是说链的 TPS 太低了,导致交易打包排队时间太长,这种情况是人力不可控的。
- 链本身不堵,但是部分大矿工只打包自己的交易,甚至宁愿不赚手续费打包空块。这种是损人不利己,为正道矿工所不齿。遗憾的是这种情况也是没有人可以干预和阻止的。 只能指望大矿工不作恶(那是不可能的)或者调整 Filecoin 经济模型来解决。
值得一提的是,官方还是预留了一些接口(lotus-miner actor control),让我们可以采取一些措施来尽量提高自己消息(有其实时空证明消息)上链的成功率的,本人试过,效果很明显。
4. Worker 掉线问题
这是一个很糟心的问题,Filecoin 其实在任务调度这块的设计模式是很先进的,通过调度窗口的形式,只是在实现的时候代码写的有点粗糙,不过也可以理解, 因为目前这个阶段官方的主要是目标是“实现”而不是“优化”。就我们测试的情况来看,造成 worker 掉线的原因有以下几种:
- Miner 和 worker 之间网络连接不稳,这个主要是硬件问题,要靠网络工程师去解决。
- 软件依赖的问题,Lotus 使用的那个版本的 jsonRPC 库不稳定,可以试下升级或者降级到稳定版本。不过这个不一定有效。
- 软件设计问题,目前 worker 掉线之后不会自动去重新连接 miner,有开发能力的可以添加重连机制(我们采取的就是这种)。
不过我相信上面除了第 1 条之外,官方后期都会很好地解决,只是他们现在腾不出时间。
这里顺便体提一下,据 Filecoin 项目负责人 Why 在 slack 上说,他们已经把 P1 优化到 2 个小时,如果消息属实那么这对矿工来说真是一个好消息。
5. 各种掉算力问题
我相信在整个 SpaceRace 过程中,Miner 掉算力的问题应该一直是困扰这广大矿工的噩梦,运维人员每天早上起床地一件事情应该就是:打开区块浏览器,看昨晚掉了算力没有, 24 小时的算力增量是多少。 最怕看到的就是算力增长 -xxxTB。真是心累!!! 运气好的同学一般都能在第二天恢复算力,运气不好的就必须面对每天早上算力清零的折磨。那真是辛辛苦苦几十年,一下回到解放前。
很荣幸,我们是属于“运气好”那一波同学。其实掉算力的问题,说简单也不简单,但是说复杂也不算复杂。首先你要知道,掉算力的直接原因只有两个:
- 矿工自己发现错误的扇区,然后主动上报,请求扣除错误扇区的有效算力,这种相当于是自首。
- 矿工没法按时完成时空证明挑战,并将结果上链,这种属于被强制执行扣减算力。
其中,上面两种情况的发生,又是由于各种原因引起的。比如上报的错误扇区可能是证明无法读取(被删除,或者不可读),也可能是路径错误,甚至是程序的 Bug...
无法提交时空证明的情况也有很多种,一种是生成时空证明失败,另一种是生成成功了,但是无法上链。上链不成功的原因有可能证明结果(Proof)没有被验证通过,也可能是链堵住了,无法在规定的 epoch
之前提交,出现类似 PoSt chain commitment 50938 too far in the past, must be after 51152 (RetCode=16) 错误,等等。
所以,碰到算力丢失不要慌,按照流程一步一步排查就是了,只要你的数据没有删除,总有办法可以找回的。
在这里请允许我讲一个众所周知的神医扁鵲的故事:
魏文王曾求教于名医扁鹊:"你们家兄弟三人,都精于医术,谁是医术最好的呢?" 扁鹊说:"大哥最好,二哥差些,我是三人中最差的一个。" 魏王不解地说:"请你介绍的详细些。" 扁鹊解释说:"大哥治病,是在病情发作之前,那时候病人自己还不觉得有病,但大哥就下药铲除了病根,使他的医术难以被人认可,所以没有名气,只是在我们家中被推崇备至。 我的二哥治病,是在病初起之时,症状尚不十分明显,病人也没有觉得痛苦,二哥就能药到病除,使乡里人都认为二哥只是治小病很灵。 我治病,都是在病情十分严重之时,病人痛苦万分,病人家属心急如焚。此时,他们看到我在经脉上穿刺,用针放血,或在患处敷以毒药以毒攻毒,或动大手术直指病灶, 使重病人病情得到缓解或很快治愈,所以我名闻天下。"
说实话,我们在整个 SpaceRace 的过程中最不担心的就是掉算力问题,因为我们采取的是扁鵲大哥的策略。
我们开发了一个小工具,能够在做时空证明之前,检测出那些扇区可能无法完成时空证明挑战,然后想办法修复,如果无法修复就不让这个扇区参与时空证明。
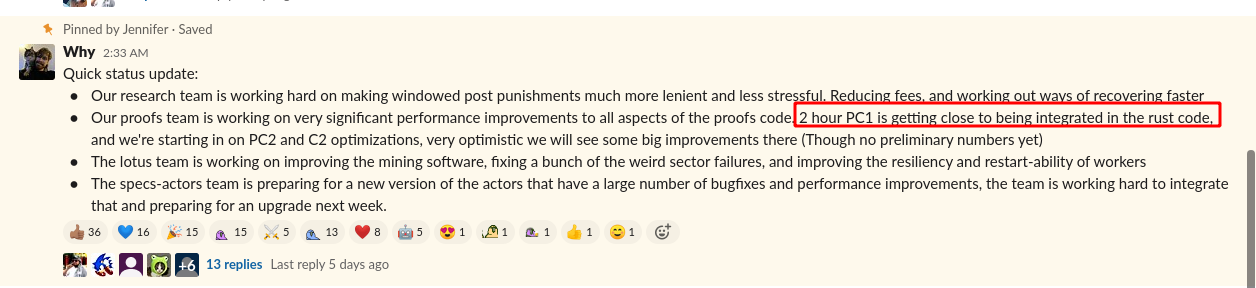
下面是我们的小工具检测出的 lotus github 上著名的 sanity check failed 错误。
2020-09-13T22:53:06.162+0800 ^[[34mINFO^[[0m miner miner/miner.go:358 Time delta between now and our mining base: 6s (nulls: 0)
2020-09-13T22:53:13.797+0800 ^[[31mERROR^[[0m storageminer storage/wdpost_run.go:65 runPost failed: running post failed:
3226625 github.com/filecoin-project/lotus/storage.(*WindowPoStScheduler).runPost
3226626 /golang/src/lotus/storage/wdpost_run.go:415
3226627 - sanity check failed
3226628 github.com/filecoin-project/filecoin-ffi.GenerateWindowPoSt
3226629 /golang/src/lotus/extern/filecoin-ffi/proofs.go:580
3226630 github.com/filecoin-project/lotus/extern/sector-storage/ffiwrapper.(*Sealer).GenerateWindowPoSt
3226631 /golang/src/lotus/extern/sector-storage/ffiwrapper/verifier_cgo.go:43
3226632 github.com/filecoin-project/lotus/storage.(*WindowPoStScheduler).runPost
3226633 /golang/src/lotus/storage/wdpost_run.go:413
3226634 github.com/filecoin-project/lotus/storage.(*WindowPoStScheduler).doPost.func1
3226635 /golang/src/lotus/storage/wdpost_run.go:54
3226636 runtime.goexit
3226637 /usr/lib/go-1.14/src/runtime/asm_amd64.s:13736. 各种 Sector 任务 Failed 问题
这种是常规问题,总有一些扇区因为某种原因密封失败的,这个只要查看日志看看报什么错,然后采取对应的措施就好了。 测试过程很多人问我最多的问题就是:“你看我这么多失败的扇区,怎么回事啊,怎么办啊?”然后我一般的回答就是:“别慌,没什么大问题的。” 遇到这些错误要以平常心对待,不要看到这么多扇区错误就急躁。
我这里要提醒的是:如果是一些你无法处理的错误,那么你最好不要再折腾了,直接 remove 扇区就行了。
比较典型的就是你在上链的过程中, daemon 被自动或者手动重启了,那么就会出现 PreCommitFailed, CommitFailed 等类似错误。
报错原因一般是类似: sectorNumber is allocated, but PreCommit info wasn't found on chain。
7. 订单成功率的问题
这个问题一般只有内地机房才会碰到,我们知道太空测试期间,官方安排了机器人一直给矿工发送订单,但是由于某些不可抗力因素,导致订单传输到内地机房很慢,如果传输超时的话,会严重影响你订单的成功率。
这问题处理起来比较简单,你只需要在香港或者国外购买一个云主机,然后把你的云主机的 IP 上链,最后你在云主机上做数据路由转发,把对应端口的数据包全转发到你机房的 Miner 机器就好。
对应的操作如下,假如你购买的云主机 IP 为 123.456.789.110:
首先修改你的 miner 配置(config.toml)
[Libp2p]
ListenAddresses = ["/ip4/0.0.0.0/tcp/6666"]
AnnounceAddresses = ["/ip4/xxx.xxx.xxx.xxx/tcp/6666"]
# NoAnnounceAddresses = []
# ConnMgrLow = 150
# ConnMgrHigh = 180
# ConnMgrGrace = "20s"
#这里的 xxx.xxx.xxx.xxx 是指你机房的公网 IP。
然后将你对外接单的地址上链:
lotus-miner actor set-addrs /ip4/123.456.789.110/tcp/6666这样订单就会发送到你云主机了,然后你再把你云主机 6666 端口的数据包全部转到你的机房 IP 对应的端口就好了。
8. Sector 生命周期点亮问题
一个惨痛的教训是,点亮扇区的生命周期(upgrade sector)要趁早,我们最后一周升级的扇区貌似都失败了。具体原因不详,也许是链的问题,也许是检测工具的问题。
由此延伸出一个结论就是:有条件做某件事情的时候就立即去做,因为你永远不知道明天和意外不知道谁先来,正如你不知道哪天链会开始堵一样。
顺便贴一个升级扇区的命令给新手矿工:
lotus-miner sectors mark-for-upgrade {SectorID}{SectorID} 表示你要标记升级的山区 ID
9. 一个好的运维工具也许是你取胜的关键
Filecoin 挖矿的复杂程度远远高于 BTC 和 ETH 这样的区块连项目,不是准备好硬件,软件后开机就可以做等收币了。这才只是刚刚开始的第一步,后面集群的维护才是比较耗时耗力的。 包括集群节点程序异常推出,以及上面提到的各种 Worker 掉线的问题,都需要运维人员去维护。尤其是本次 SpaceRace 前几天几乎是保持每天 1 到 2个小版本的迭代速度,让人有点无力吐嘈。 尤其那种几百台甚至上千台机器的大集群,那每次升级都能让你感到心力交瘁。
本人在此次 SpaceRace 竞赛中一个人同时维护来自 5 个客户的 6 个挖矿集群,有上百台的中大型集群,也有几十台的小集群。然而我并没有崩溃,相反,我感觉运维工作比较轻松。
原因的话,如果一直有跟读我博客的读者可能会知道,因为我们有 Gamma,一个专门为 Filecoin 挖矿定制的运维软件,用它运维集群简直不要太轻松。有客户反馈的截图为证:
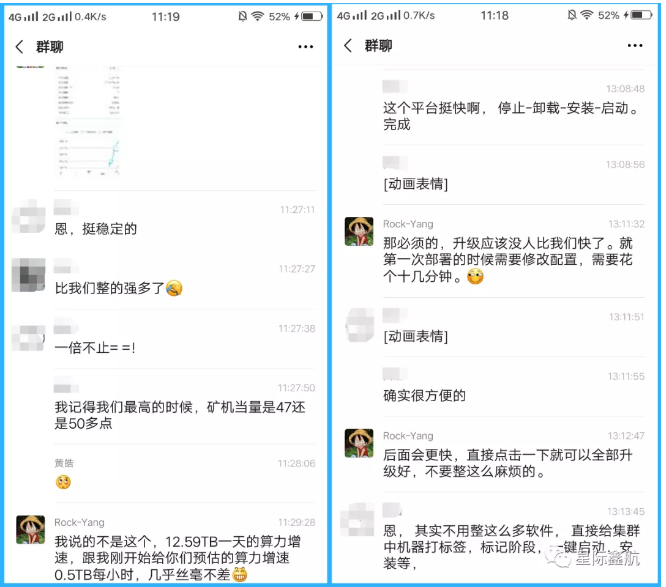
使用 Gamma 搭配我们优化过的 Filecoin 挖矿软件,效率直接翻番,而且算力增速非常稳定。
我觉得如果把 Filecoin 挖矿比作一场考试的话,那么你想要考出好成绩的话你有两种途径:
-
你能做出大部分都做不出来的难题,对应到 Filecoin 挖矿就是你能够优化 P1,P2,C2 的算法,使得你的密封速度远远超过同行其他矿工,说实话这个比较难。 而且正如我们上面所说的,这个优势迟早会被官方给拉平,因为官方团队也在开始优化算法了,预计 P1 在两个小时内可以完成。
-
第二取胜方案就是中考高考之前老师常跟我们说的那样:不要花太多时间去钻研难题,把你该得分全部拿到手,你就能考出很好的成绩。 这对 Filecoin 尤其重要,就是你要跑得稳。 否则老是掉算力的话,你会被罚的血本无归的。本次 SpaceRace 那些算力增速稳定的矿工,最后都取得了比较不错的成绩。就拿我们的一个小矿工来说,虽然才 11.5 TB 的算力,但是算力增速稳定, 订单成功率和检索成功率都很高,所以最终居然拿到了 1800 个FIL 的奖励。
10. 挖到最后还是存储的问题
虽然 Filecoin 是一个去中心化存储网络,但是具体到每个矿工节点,还是必须使用中心化的存储。其实对于大矿工来说,他们最担心的其实存储落地问题,而不是封装速度,网络或者其他问题。
存储主要需要解决两个问题:一个是存储动态扩容,第二个是存储稳定性以及数据恢复问题。目前在矿工中采用的比较多的存储解决方案我觉得的有一下几种:
- RAID 磁盘阵列,这个估计每个矿工都几乎都会用到,小矿工一般用 RAID5 或者 RAID6 做 Miner 的存储最终落地,打矿工也需要在 Worker 机器使用多块磁盘组 RAID0 解决 P1 并发多带来的高的磁盘 IO。
- 单机文件系统,比如 LVM,ZFS 等文件系统,这种一般中小型矿工使用的 Miner 存储方案。优势是搭建简单,对网络的要求也低,缺陷是由于是单击方案,扩容能力非常有限。
- 分布式文件系统,比如 Ceph, 谷歌的 GFS 等。这种一般是中大型矿工使用的存储落地方案,我看本次测试中,大家用 Ceph 的比较多,毕竟 Ceph 的优势摆在那里。 但是需要团队有比较厉害的运维团队,因为 Ceph 虽然比较容易上手,但是坑也不少。一般想要轻松驾驭 PB 级的 Ceph 存储集群,那就需要有专门的团队研究 Ceph 了,或者有一位非常资深的运维工程师来维护。 否则一旦集群崩溃(虽然Ceph自己有恢复工具,但是目前没有经过线上测试),你哭都来不及。本次测试中我知道的就有好几个中型矿工因为 Ceph 崩溃导致数据丢失不得不重新跑的情况。
- 存储柜,存储速度快,稳定性又好,数据重建速度也很快。这种小矿工就不要想了,第一是价格太贵,足够让你望而却步; 第二,你那点算力还远远不到用存储柜的时候。
最后:挖矿有风险,投资需谨慎。太空竞赛的结果能说明一些事情,但是结果也并不能代表什么。比如那些能刷几十 PB 算力的团队肯定是具备管理大型挖矿集群的能力,从侧面也能说明他们的运维能技术是非常扎实的。 但是你无法看到那"光鲜的成绩"背后,人家所投入的人力,物力,财力。而你投资主要是看投入产出,所以说不能以太空竞赛的结果排名作为投资决策依据。
Filecoin 是一个长期项目,因为存储是个长期稳定的需求,所以不要指望 Filecoin 会成为下一个百倍币。相比众多昙花一现的所谓的"区块连存储项目",Filecoin 绝对算是行业正宗。 即使它目前的表现不尽如人意,但大多数人包括我们,都仍然看好 Filecoin。毕竟它真正做了很多很多的尝试。
最后的最后:打一个小广告,我们在招人, 招聘信息在这里:区块链运维工程师。另外我们还招前端开发人员以及区块链工程师,有兴趣的同学可以发邮件(yangjian102621@gmail.com)或者微信私聊。
- 学分: 134
- 分类: FileCoin
- 标签: Filecoin 挖矿





