Sunnyside Devnet 更新 - 03/11
- testinprod
- 发布于 2025-04-20 17:58
- 阅读 1491
该报告详细描述了 Sunnyside devnet 的测试结果,主要评估了高带宽节点处理高 blob 交易负载的能力,最高达到 72 个 blob。测试结果表明,网络能够维持高达每块 72 个 blob 的交易量而不会破坏共识。不同执行客户端在 blobpool 管理方面存在差异,尤其是在 geth 和 reth/besu 之间。此外,lodestar 客户端显示出较慢的区块传播时间。
概述
本报告详细介绍了 devnet 的结果,评估了高带宽节点如何处理高达 72 个 blob 的高 blob 交易负载。
该网络在不破坏共识的情况下,每个区块最多支持 72 个 blob。
观察到执行客户端之间的 blobpool 管理存在差异,尤其是在 geth 和 reth/besu 之间。
像 lodestar 这样的一些客户端显示出较慢的区块传播时间。
资源使用情况(带宽、CPU 和内存)保持在可接受的范围内,尽管一些客户端显示出进一步优化的空间。
背景
Sunnyside 目前正在运行 2 个 devnet:https://github.com/testinprod-io/ethereum-devnets/tree/main
pectra-devnet-ssl-1
peerdas-devnet-ssl-1
它们都部署在 digitalocean 的多个区域。你可以在此处找到节点计数和验证器范围:
测试场景
每个 devnet 都配置了 tx-fuzz,以将模糊的 blob 交易发送到网络,从每个区块 1 个 blob 开始,到每个区块 72 个 blob,每 10 分钟增加一个 blob。我们还在网络中填充了每个区块 20-30 个常规交易。
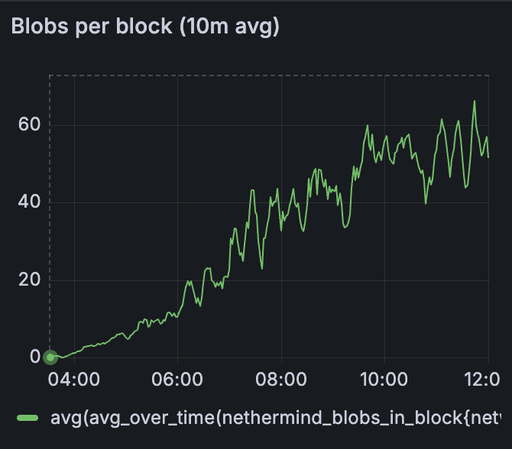
请注意,blob 的增量及其在区块中的包含并不一致,因为 blob 有时无法及时包含。我们稍后可以改进 fuzzing 方法,以提供对交易更精细和一致的控制。
目标客户端是:
CL
lighthouse: 18 个节点
prysm: 18 个节点
lodestar: 6 个节点
teku: 10 个节点
EL
geth: 20 个节点
nethermind: 20 个节点
reth: 6 个节点
besu: 6 个节点
结果
以下结果来自 pectra devnet
在 peerdas-devnet 中,即使设置了 TARGET_BLOBS_PER_BLOCK=48 和 MAX_BLOBS_PER_BLOCK=72,我们也无法在单个 blob 中获得 >6 个 blob。我们将单独跟踪这个问题,即如何在 fusaka 中配置 blob 参数。
在整个实验过程中,区块高度和区块时间基本保持一致,这意味着网络能够处理高达 72 个的 blob 计数。
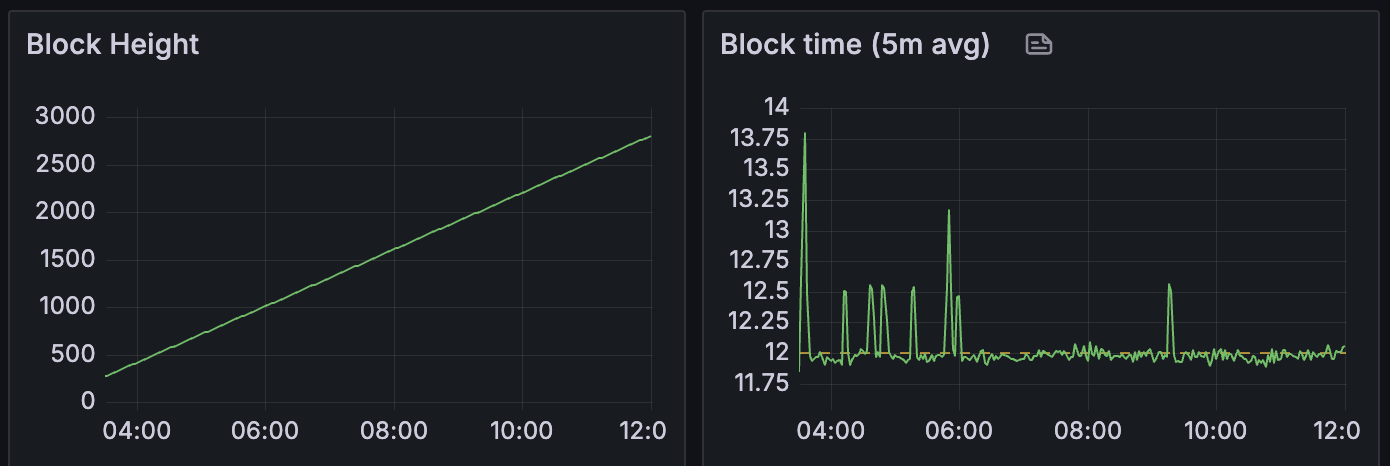
如果我们查看节点消耗的带宽,在高 blob 吞吐量(>60 个 blob)期间,上传/下载带宽约为 10MB/s。
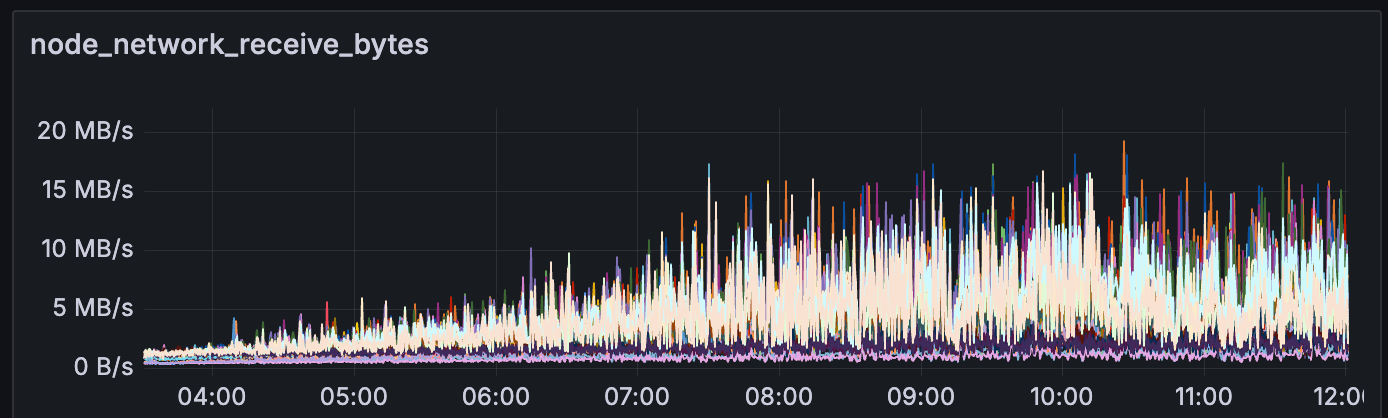
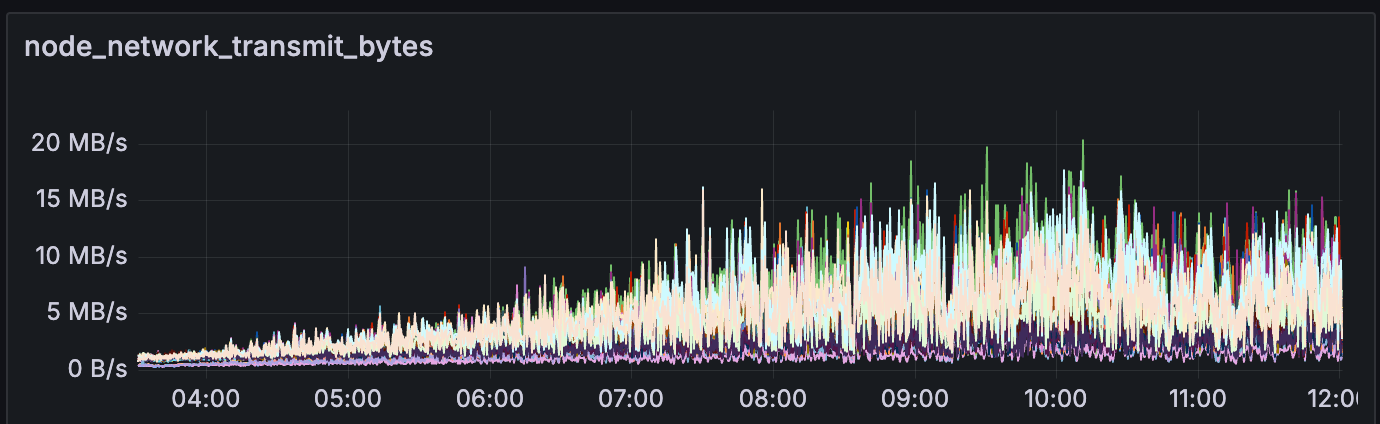
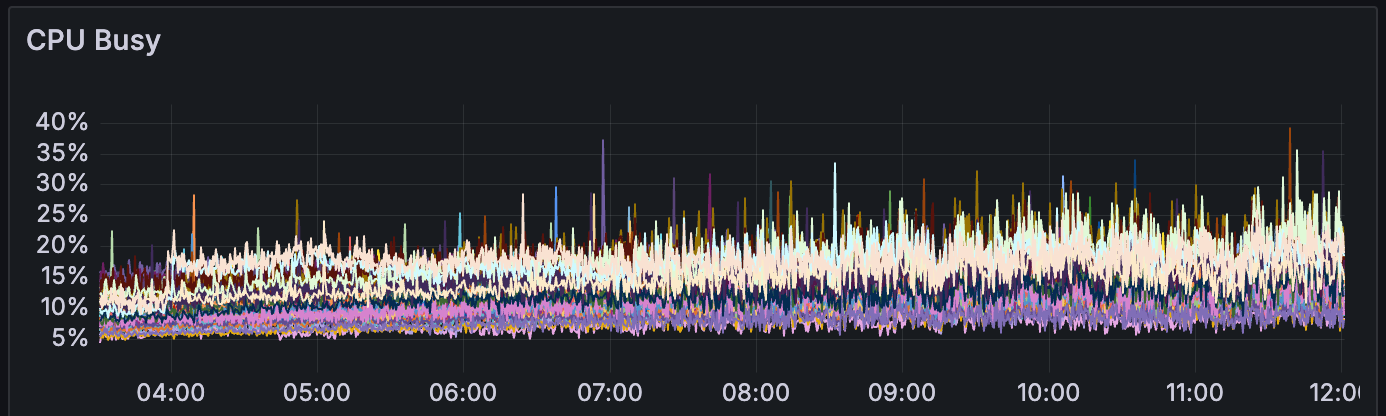
我们还观察到,在此期间,CPU 使用率始终保持在 30-40% 以下(在 digitalocean 的 s-4vcpu-8gb-amd 上)
Xatu sentry 配置在每个节点上,我们能够收集以下数据:
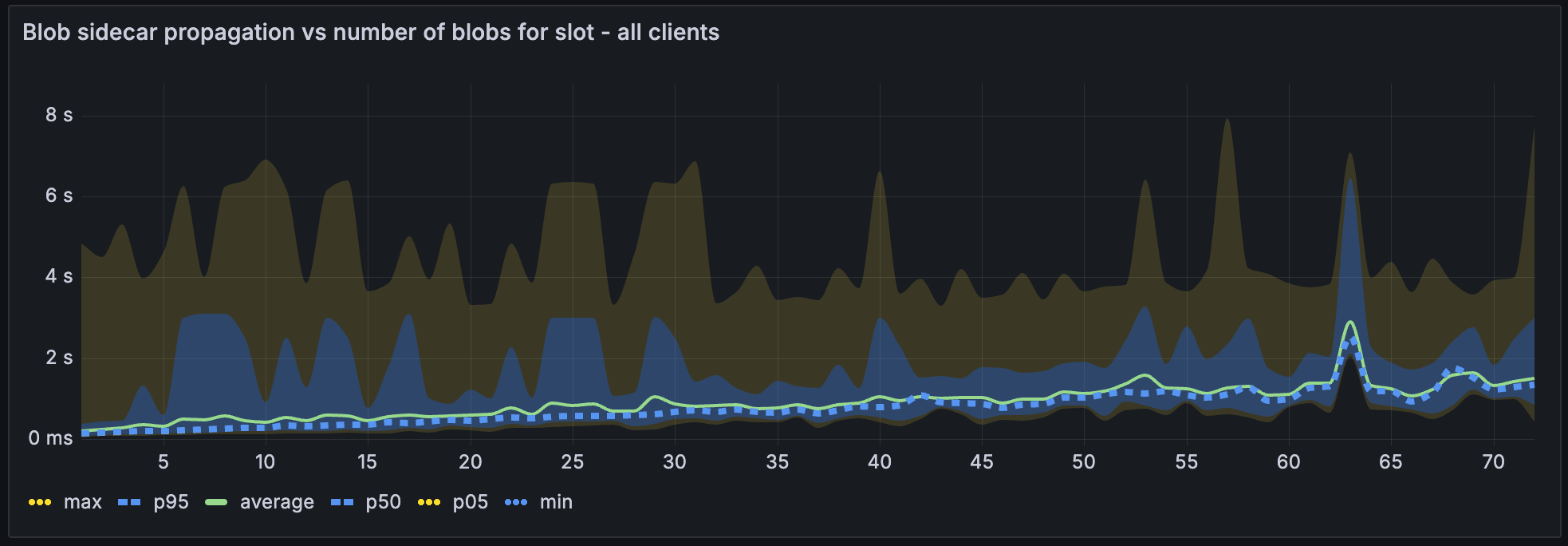
在所有 blob 计数低于 60 的情况下,blob sidecar 传播在 4 秒内完成,p95 为
发现
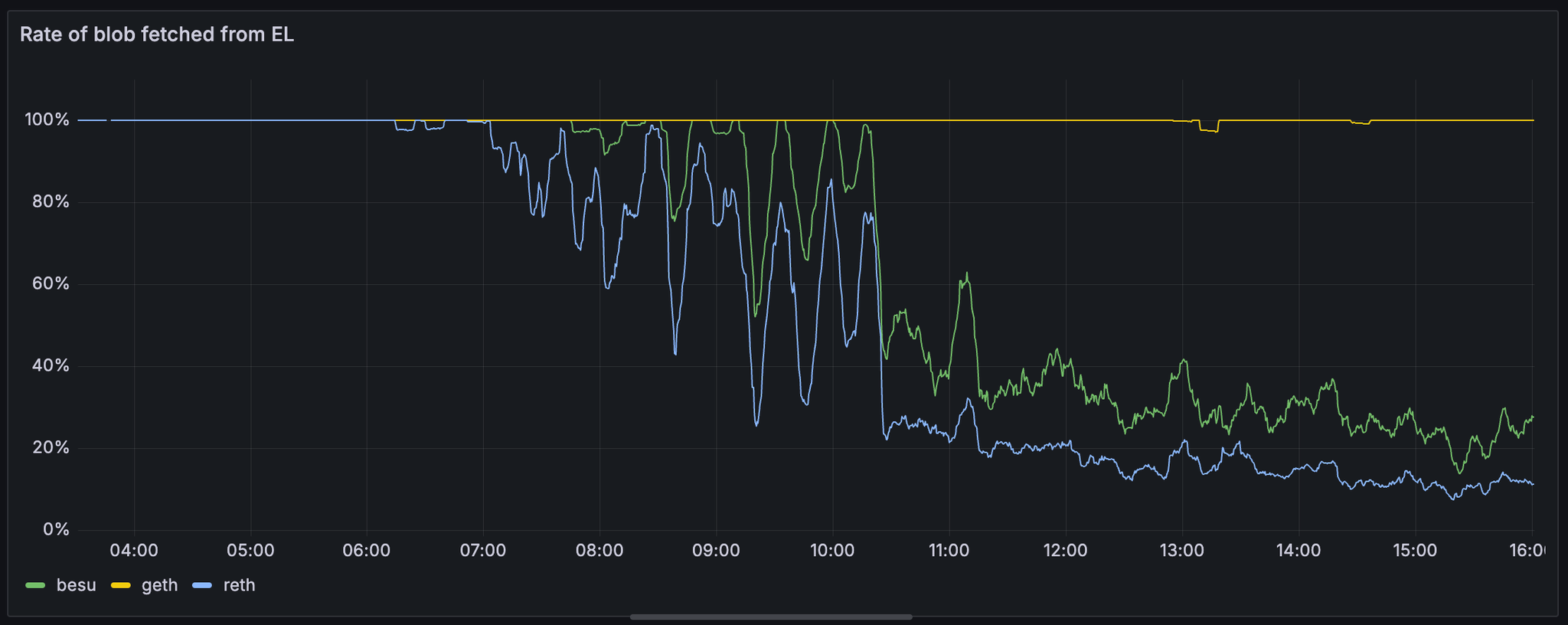
从 EL 获取的 blob 速率在执行客户端之间差异很大。请注意,geth 保持 100% 的命中率,而 reth 和 besu 随着 blob 计数的增加下降到接近 20%。
我们还可以观察到,geth 的 blobpool 数据大小明显小于 reth
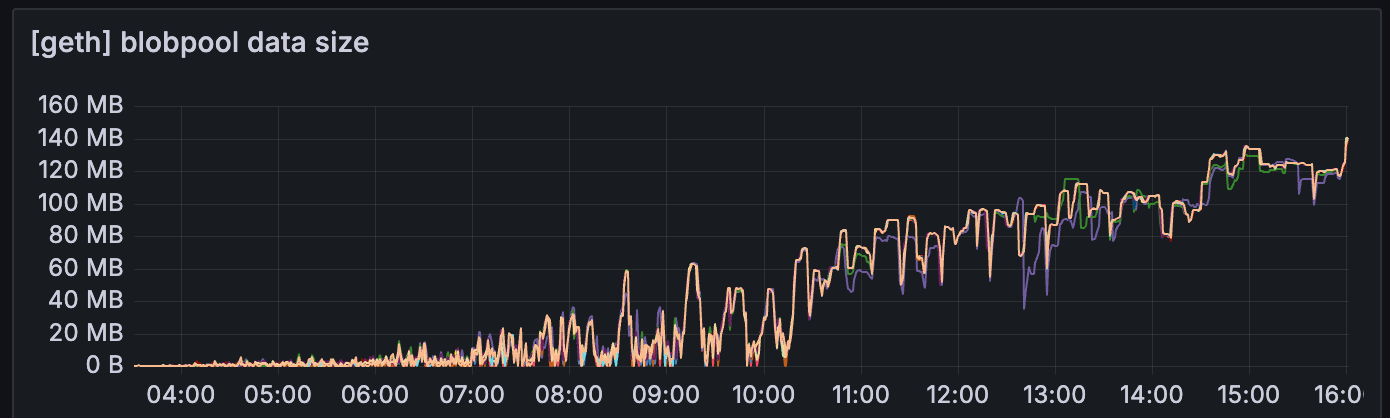
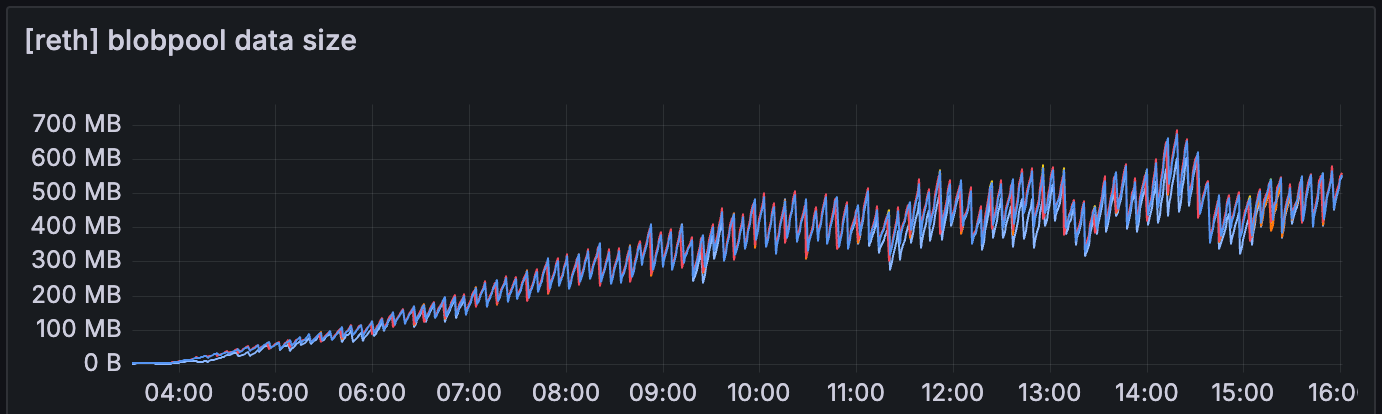
最好了解 geth 和其他 EL 的 blobpool 实现之间的区别。
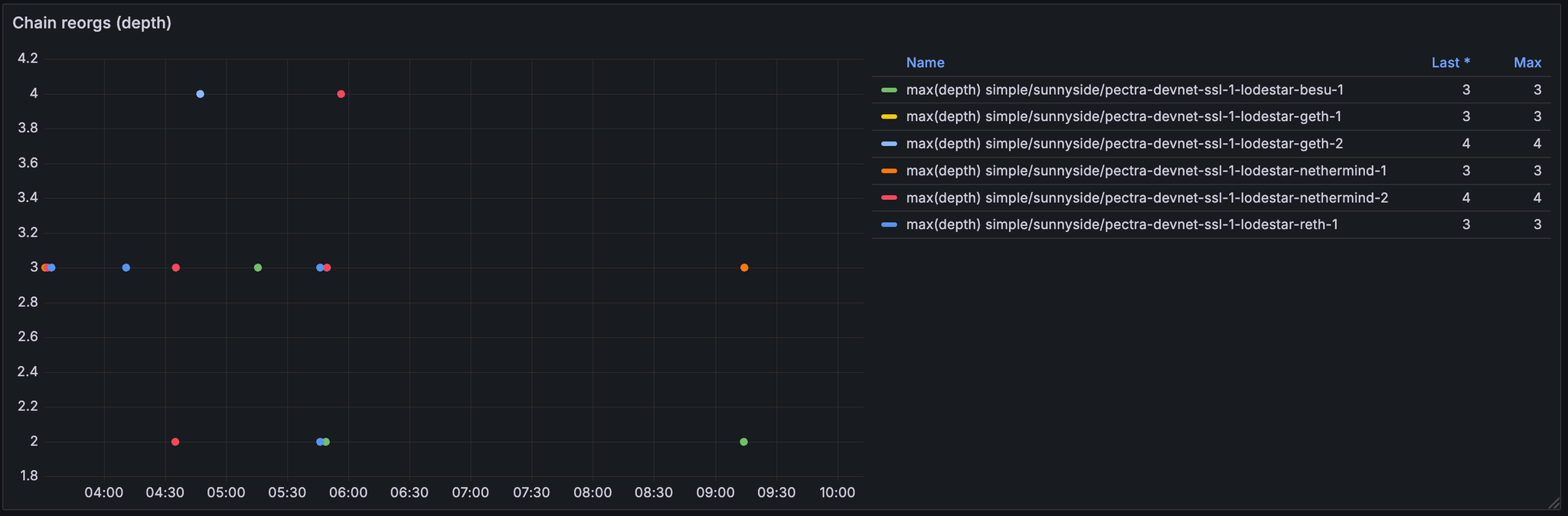
在整个测试过程中,只有 lodestar 显示了 reorg 的实例。
与其他共识客户端相比,lodestar 显示出整体较慢的区块传播时间。
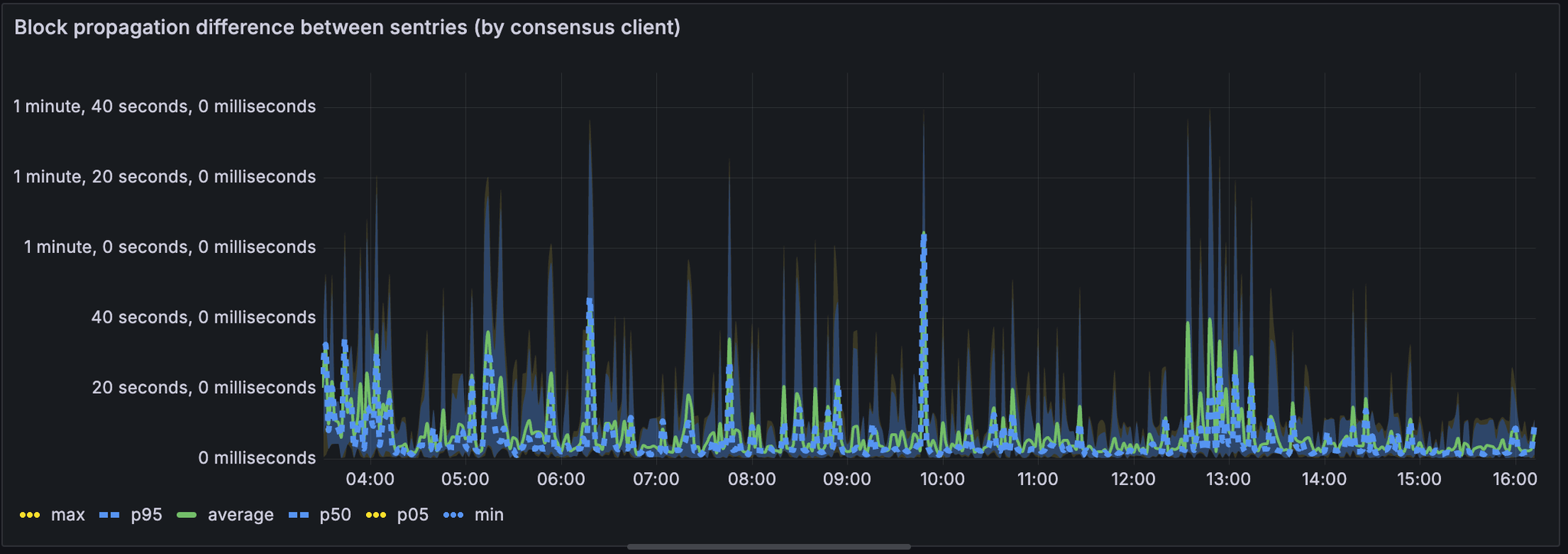
lodestar
ALT
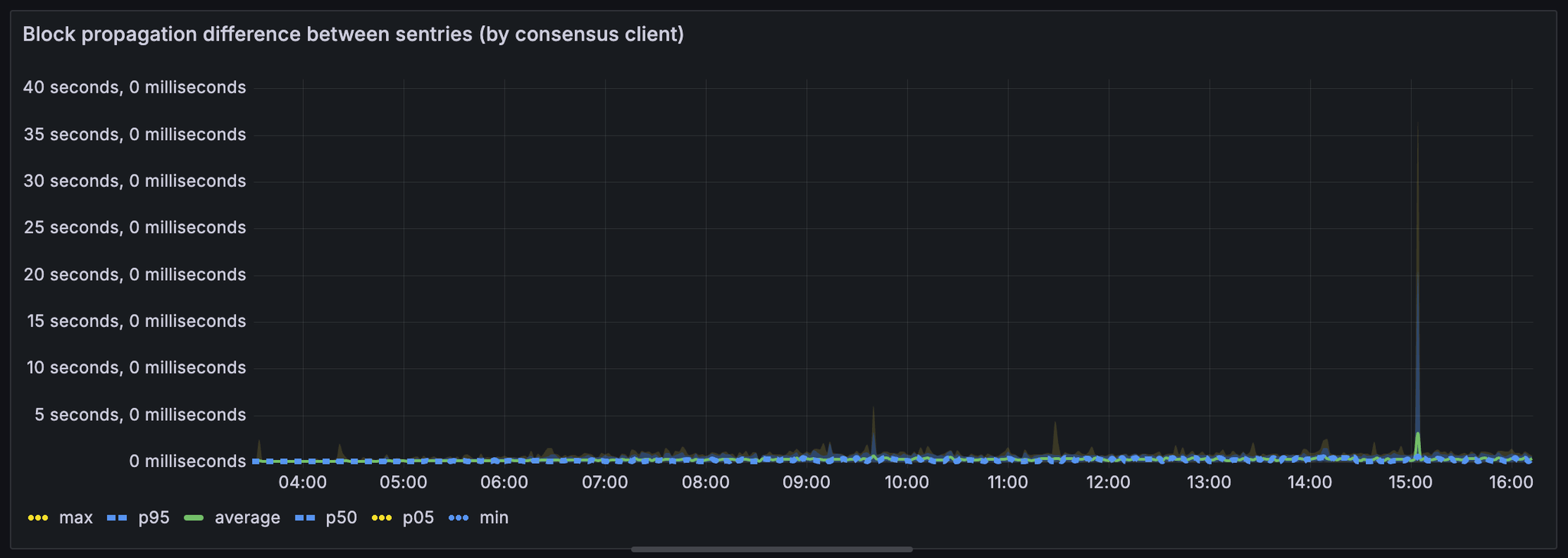
prysm, lighthouse, teku
ALT
了解 lodestar 在处理大量 blob 方面是否存在任何特定限制可能会很有用。
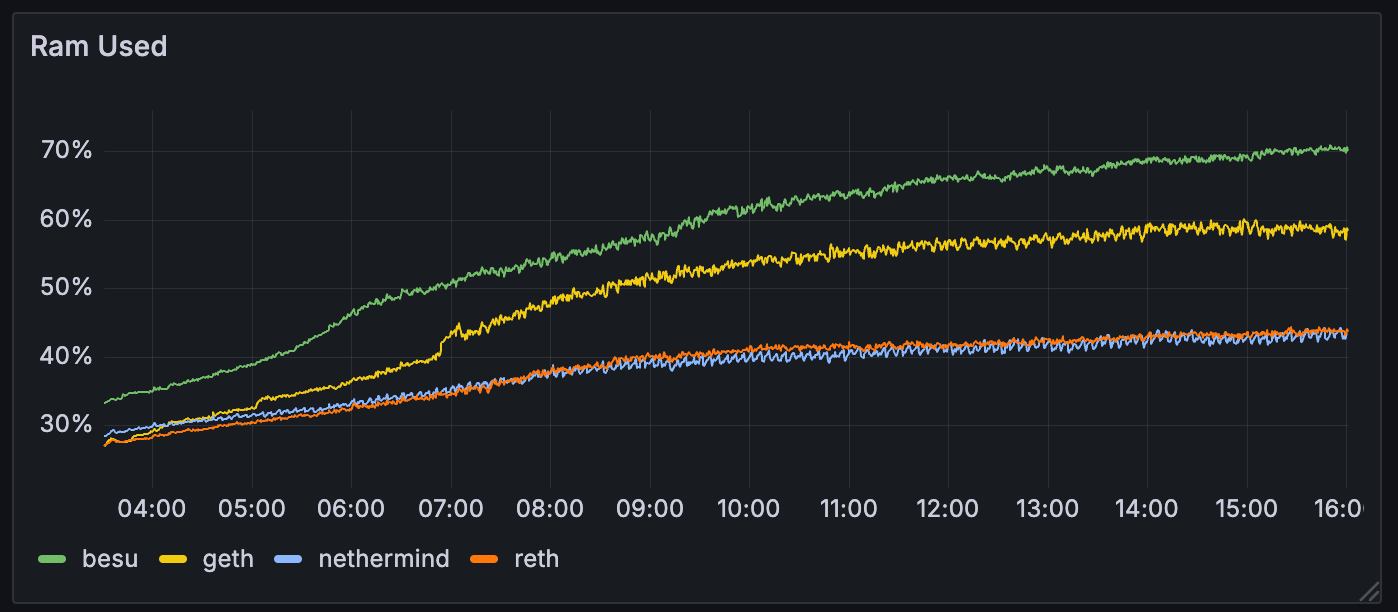
客户端之间的内存使用情况有所不同。例如,besu 达到了 70% 的内存使用率(从 8GB 开始)。虽然对于 >60 个 blob 达到 70% 可能不是特别重要,但我们可能需要评估客户端在高吞吐量条件下的内存使用情况。
已知局限性 & 限制
这是在单个基础设施提供商中配置的节点上执行的,具有高带宽可用性。
为了更全面地了解网络,我们应该在具有不同网络带宽限制(模拟真实世界场景)的不同云提供商中部署节点。
下一步
sunnyside 的下一步是运行 2 个新的 devnet:
相同的测试,但启用了网络带宽。
评估具有带宽限制的性能(例如,典型家庭 staker 网络在 ~20Mbps 或 2.5MB/s),旨在确定此类网络实际可以处理多少个 blob。
将 blob 目标设置为 6,并使用 blob 交易测试 mempool 负载。
虽然以上测试表明网络能够处理每个区块 >60 个 blob,但我们希望确保网络也能处理 mempool 中高负载的情况。
在高 blobpool 使用情况下,监控 EL 中潜在的问题,如 OOM 或网络不稳定。
最重要的是,我们还将致力于使用工具轻松实现不同功能的测试,例如分布式 blob 发布。我们希望能够在类似的网络条件下测试不同的功能。
客户特定观察
Reth:与 geth 相比,哪些因素导致 blobpool 使用率较低和 blobpool 数据大小较高?
Besu:与 geth 相比,哪些因素导致 blobpool 使用率较低?
Lodestar:哪些因素导致更高的区块传播时间和 reorgs?
需求
我们将非常感谢客户端团队的反馈,内容包括:
你希望看到的其他指标或数据点。
有关进一步测试场景或配置的建议。
有关客户特定行为的任何见解(例如,blobpool 管理中的差异)。
你的意见对于改进我们的测试和确保未来的迭代提供更可操作的见解将是非常宝贵的。
- 原文链接: testinprod.notion.site/S...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





