构建高效的Solana程序
- blockmagnates
- 发布于 2025-06-05 11:47
- 阅读 1321
本文深入探讨了Solana链上开发的架构设计,强调了高效数据处理和避免并行执行中的瓶颈。文章讨论了通过优化数据大小、利用Box和Zero-Copy来管理大型账户,以及智能的账户设计(如数据排序、版本控制和索引),以实现更快的速度、更低的成本、更高的安全性和更好的功能性Solana程序。

引言
Solana 开发需要的不仅仅是好的代码;它还需要为性能而周全的系统设计。作为一名 Solana 开发者,你是一名架构师,必须考虑:
- 你的代码应该做什么?
- 你如何实现它?
- 每种方法的优缺点是什么,尤其是在 Solana 上?
区块链开发,尤其是在 Solana 上,具有独特的限制(存储成本、数据限制、计算单元)和高风险(管理资产)。你将探索构建快速、经济、安全和功能强大的 Solana 程序的关键架构概念。
高效数据处理的策略
在典型的编程中,数据大小通常感觉是无限的。想要一个长字符串或一个方便的整数类型?没问题!但是,Solana 在更严格的规则下运行。我们需要为链上存储的每个字节付费(租金),并且面临堆栈、堆和账户大小的限制。这需要一种更具战略性的数据管理方法,尤其是在处理可能被认为是“大型”账户时。
在 Solana 上处理较大数据时,会出现两个主要问题:
- 最小化占用空间(大小): 由于我们按字节付费,因此尽可能保持数据结构小巧对于成本效益至关重要。
- 克服堆栈和堆限制: 操作大数据可能会超出 Solana 的堆栈和堆的约束。我们将探讨
Box和 Zero-Copy 作为解决方案。
大小
在 Solana 上,账户所有者为其账户中存储的数据支付租金。虽然术语“租金”有点误导(它更像是免租金的最低余额),但核心原则仍然是:链上数据存储是有成本的。 这就是 NFT 图像等资产通常存储在链下的原因。
你的目标是在程序功能和用户存储链上必要数据所产生的成本之间取得平衡。优化空间的第一步是了解数据结构的大小。这是一个参考:
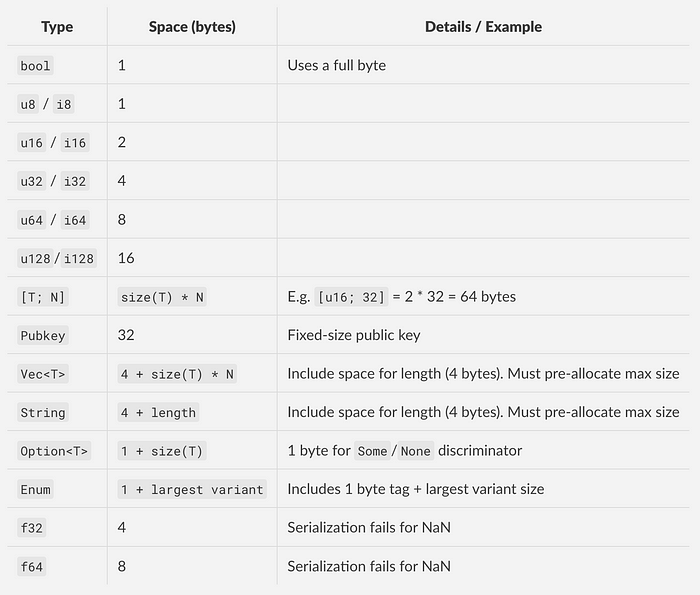
有了这些知识,你就可以开始进行小而重要的优化。例如,如果一个字段永远不会超过 100,那么使用 u8(最大值为 255)而不是 u64(范围很大)每次实例可以节省整整 7 个字节!同样,如果不需要负值,请选择无符号类型(u*)。
注意: 在优化大小的同时,请注意较小数字类型可能出现的溢出。u8 递增超过 255 将会回绕到 0,这可能会导致意外行为。
Box
现在,让我们来解决处理真正大型数据账户的挑战。考虑一下这种结构体:
##[account]
pub struct BigData {
pub big_data: [u8; 5000],
}
##[derive(Accounts)]
pub struct CreateBigData<'info>
pub big_data: Account<'info, BigData>,
}在 Solana 上,每个函数调用的堆栈大小限制在 4KB 左右。如果传递一个像 BigData 这样的大型结构体(例如,带有 5KB 的数组),它可能会溢出堆栈,从而触发编译器警告,甚至导致程序挂起。发生这种情况是因为默认情况下,较大的值是在堆栈上分配的。
解决方案?输入 Box<T>。
##[account]
pub struct BigData {
pub big_data: [u8; 5000],
}
##[derive(Accounts)]
pub struct CreateBigData<'info>
pub big_data: Box<Account<'info, BigData>>,
}在 Anchor 中,将 Account<'info, T> 包装在 Box<> 中会指示 Anchor 在堆上分配账户数据,堆是一个更大的内存区域(在 Solana 上约为 32KB)。Box 的优点在于它的无缝集成。你无需更改与函数中数据交互的方式。只需在 Accounts 结构体中将大型账户类型包装在 Box<...> 中即可。
但是,Box 并不是真正大型账户的灵丹妙药。如果数据足够大,你仍然会遇到堆限制。为此,我们需要转向 Zero-Copy。
Zero Copy (零拷贝)
如果需要使用接近 Solana 账户最大大小(10MB)的账户,该怎么办?即使使用 Box,你也会遇到限制。考虑一下:
##[account]
pub struct ReallyBigData {
pub really_big_data: [u128; 1024], // 16,384 bytes
}即使是 boxed (装箱)的账户,也可能会导致问题。这就是 zero-copy deserialization (零拷贝反序列化) 发挥作用的地方,它利用 zero_copy 和 AccountLoader。
##[account(zero_copy)]
pub struct ReallyBigData {
pub really_big_data: [u128; 1024], // 16,384 bytes
}
pub struct ConceptZeroCopy<'info> {
#[account(zero)]
pub really_big_data: AccountLoader<'info, ReallyBigData>,
}这里的诀窍是:使用 zero-copy (零拷贝),你的程序不会将账户数据加载到堆栈或堆中。相反,它会获得对账户内存的直接指针访问权限。AccountLoader 安全地包装此原始数据,因此你可以像使用普通结构体一样使用它。
主要优势: Zero-copy (零拷贝) 通过跳过反序列化来避免堆栈/堆限制。与将所有数据复制到内存中的 Borsh 不同,zero-copy (零拷贝) 使你可以有效地处理大型账户类型。
Zero Copy (零拷贝) 的注意事项:
- 没有
init约束: 在Accounts结构体中定义 zero-copy (零拷贝) 账户时,不能使用init约束。这是因为 CPI 对大于 10KB 的账户有限制。你需要从客户端代码中的单独指令中创建和资助这些大型账户。相反,你的客户端会在与 zero-copy (零拷贝) 账户交互之前执行createAccount系统指令: - 加载账户数据: 在 Rust 指令处理程序中,你需要使用
AccountLoader上的以下方法之一显式加载 zero-copy (零拷贝) 账户数据:
load_init(): 用于初始化新的 zero-copy (零拷贝) 账户(忽略初始创建时缺少的账户鉴别器)。load(): 用于加载不可变的 zero-copy (零拷贝) 账户。load_mut(): 用于加载可变的 zero-copy (零拷贝) 账户。
设计有效的 Solana 账户
在 Solana 上,一切都存在于一个账户中 —— 用户钱包、Token Mint、程序数据,甚至是程序本身。这就是为什么智能账户设计对于构建高效、可维护和可扩展的 Solana 应用程序至关重要。以下是一些需要牢记的关键考虑因素。
数据顺序
这可能看起来是一个小细节,但账户结构体中字段的顺序会显着影响你查询和筛选链上账户的难易程度。一般的经验法则是简单的:将所有可变长度字段放在账户结构的末尾。
考虑一下这种结构不良的数据:
##[account]
pub struct BadState {
pub flags: Vec<u8>, // Variable length (可变长度)
pub id: u32, // Fixed length (固定长度)
}BadState 中的 flags 字段是一个 Vec<u8>,这意味着它的大小可能会有所不同。这种灵活性是有代价的:它会影响你查询账户的方式。
Solana 支持 memcmp 过滤器,可让你通过匹配账户数据中特定偏移量处的字节序列来搜索账户。问题是?偏移量必须是固定的。
在 BadState 中,id 字段位于 flags 之后,因此它在内存中的位置会随着 flags 的增长而发生变化。这使得使用 memcmp 进行可靠的过滤变得不可能。
让我们可视化一下原始数据中发生的情况:
场景 1: flags 有 4 个元素
0000: [8 bytes discriminator (鉴别器)]
0008: [4 bytes Vec length (Vec 长度)] [4 bytes flags data (flags 数据)]
0010: [4 bytes id]场景 2: flags 有 8 个元素
0000: [8 bytes discriminator (鉴别器)]
0008: [4 bytes Vec length (Vec 长度)] [8 bytes flags data (flags 数据)]
0014: [4 bytes id]正如你所看到的,id 字段的偏移量发生了变化。这使得根据 id 的固定偏移量可靠地查询账户变得不可能。
解决方案很简单:将固定大小的字段放在可变长度字段之前:
##[account]
pub struct GoodState {
pub id: u32, // Fixed length (固定长度)
pub flags: Vec<u8>, // Variable length (可变长度)
}现在,id 字段将始终位于一致的偏移量(在初始 8 字节鉴别器之后),从而可以进行高效的查询。
账户灵活性和面向未来
软件会不断发展,Solana 程序也是如此。设计考虑到 升级和向后兼容性 的账户结构是避免痛苦迁移的关键。
一个可靠的策略包括向账户添加一个 version 字段,以便你的程序可以安全地处理不同的数据布局。对新字段使用 Option<T>,以保持与旧版本的兼容性。
Anchor 通过 InitSpace 等工具简化了这一点,InitSpace 可以自动计算账户大小,并为 Vec 字段使用 #[max_len] 来强制执行限制。
##[account]
##[derive(InitSpace)]
pub struct GameState { // V1
pub version: u8,
pub health: u64,
pub mana: u64,
pub experience: Option<u64>,
#[max_len(50)]
pub event_log: Vec<String>
}当你需要升级此结构(例如,增加 event_log 大小或添加新字段)时,你可以修改该结构并在专用升级指令中使用 Anchor 的 realloc 约束:
##[account]
##[derive(InitSpace)]
pub struct GameState { // V2
pub version: u8,
pub health: u64,
pub mana: u64,
pub experience: Option<u64>,
#[max_len(100)] // Increased length (长度增加)
pub event_log: Vec<String>,
pub new_field: Option<u64>, // New field (新字段)
}
##[derive(Accounts)]
pub struct UpgradeGameState<'info> {
#[account(\
mut,\
realloc = GameState::INIT_SPACE,\
realloc::payer = payer,\
realloc::zero = false,\
)]
pub game_state: Account<'info, GameState>,
#[account(mut)]
pub payer: Signer<'info>,
pub system_program: Program<'info, System>,
}
pub fn upgrade_game_state(ctx: Context<UpgradeGameState>) -> Result<()> {
let game_state = &mut ctx.accounts.game_state;
match game_state.version {
1 => {
game_state.version = 2;
game_state.experience = Some(0); // Initialize new field (初始化新字段)
msg!("Upgraded to version 2 (已升级到版本 2)");
},
_ => return Err(ErrorCode::AlreadyUpgraded.into()),
}
Ok(())
}realloc 约束将账户大小调整为 GameState::INIT_SPACE,付款人支付任何额外租金。设置 realloc::zero = false 可在调整大小期间保留现有数据。
Data Optimization (数据优化)
我们已经讨论了选择正确的数据类型以最大限度地减少字节使用量。但是,通常可以通过注意这些字节中浪费的位来进一步优化。
例如,如果你有一个表示年份中月份的字段,那么使用 u64 就有点过头了。u8 (0-255) 绰绰有余(月份为 0-11,可能 0 表示未初始化的状态)。更好的是,考虑使用 u8 枚举以获得更好的可读性和类型安全性。
考虑具有多个布尔标志的场景:
##[account]
pub struct BadGameFlags { // 8 bytes
pub is_frozen: bool,
pub is_poisoned: bool,
pub is_burning: bool,
pub is_blessed: bool,
pub is_cursed: bool,
pub is_stunned: bool,
pub is_slowed: bool,
pub is_bleeding: bool,
}虽然一个 bool 在概念上只需要一位,但 Borsh(Solana 的序列化库)通常会为每个布尔值分配一个完整的字节。这意味着这八个标志消耗了八个字节。
一种更节省空间的方法是使用单个 u8 并利用 bitwise operations (按位运算):
const IS_FROZEN_FLAG: u8 = 1 << 0; // 0b00000001
const IS_POISONED_FLAG: u8 = 1 << 1; // 0b00000010
// ... and so on (等等)
##[account]
pub struct GoodGameFlags { // 1 byte
pub status_flags: u8,
}在此示例中,此优化节省了大量的 7 个字节。权衡是在代码中添加了按位运算的复杂性,但对于经常访问的或大量的标志集合,节省的空间可能非常值得。
Indexing (索引)
最后一个账户设计概念是 indexing (索引),而这正是 Program Derived Addresses (PDAs) (程序派生地址) 发光的地方。你可以使用一组种子 deterministicly derive (确定性地派生) 它们,而不是直接存储账户地址。这使得账户地址 可预测、可发现,并消除了手动查找的需要。
一个典型的例子是 Associated Token Accounts (ATAs) (关联Token账户)。它们的地址是从以下内容派生的:
- 钱包地址
- Token 程序 ID
- Token Mint
这种模式允许程序(和用户)即时计算 ATA 地址,而无需存储它们。
你可以在自己的程序中应用类似的模式:
- One-Per-Program (Global Account) (每个程序一个(全局账户)): 使用像
b"GLOBAL_SETTINGS"这样的固定种子可以确保对于你的程序,只能存在一个具有该用途的账户。这对于存储全局配置很有用。 - One-Per-Owner (每个所有者一个): 使用用户的公钥来播种账户(例如,
seeds = [b"PLAYER_DATA", owner.key().as_ref()])可以保证每个用户都有一个唯一的账户用于特定目的。 - Multiple-Per-Owner (每个所有者多个): 通过在种子中包含一个额外的唯一标识符(例如,
seeds = [b"ORDER", owner.key().as_ref(), order_id.to_be_bytes().as_ref()]),你可以为每个用户创建多个唯一可识别的账户。 - One-Per-Owner-Per-Account (每个所有者每个账户一个): 这是 ATA 模式,允许你为一个用户和另一个账户(如 Token Mint)创建一个唯一的关联账户。
Designing for Parallel Execution (为并行执行而设计)
Solana 的突出之处在于它 in parallel (并行) 处理交易,这与许多按顺序运行交易的区块链不同。只要交易不尝试同时修改同一个账户,它们就可以并发执行。设计你的程序以利用这一点对于最大限度地提高吞吐量和提供流畅的用户体验至关重要。
如果你见过流行的 NFT Mint 在运行,你就会知道当许多用户同时针对同一个“糖果机”账户时会发生什么。这种沉重的争用会产生瓶颈,导致交易失败并让用户感到沮丧。
Solana 可以 并行 处理交易 只要它们不同时修改同一个账户。让我们通过一些例子来探讨这意味着什么。
No Contention (无争用)
Alice 想要将 SOL 发送给 Carol,而 Bob 想要将 SOL 发送给 Dean:
Alice --> Carol
Bob --> Dean这些交易影响不同的账户,可以并行处理,从而加快整体执行速度。
Shared Account Bottleneck (共享账户瓶颈)
如果 Alice 和 Bob 试图同时向 Carol 付款,该怎么办?
Alice --> |
|--> Carol
Bob --> |由于两者都修改了 Carol 的账户,Solana 将 serialize (序列化) 这些交易。首先通过一个;另一个等待。这会产生瓶颈,尤其是在规模上。
High Traffic Bottleneck (高流量瓶颈)
想象一下,1000 个用户试图一次性支付给 Carol:
Alice --> |
1000x --> |--> Carol
Bob --> |所有这些交易都排队以按顺序更新 Carol 的账户。早期交易会快速成功,但由于超时,许多交易将面临延迟甚至失败。
这不仅仅是理论上的。将许多操作 funnel (导入) 到 single shared account (单个共享账户) 中的程序(例如,收集费用的财务钱包)可能会成为性能瓶颈。
Boosting Parallelism (提高并行性)
避免争用的关键是将 core user interactions (核心用户交互) 与 shared account updates (共享账户更新) 分开。
Example: Donation Tally Program (示例:捐赠统计程序)
Suboptimal approach (欠佳方法):
pub fn run_concept_shared_account_bottleneck(ctx: Context<ConceptSharedAccountBottleneck>, lamports_to_donate: u64) -> Result<()> {
let donation_tally = &mut ctx.accounts.donation_tally;
// Transfer directly to the shared community wallet (contention point) (直接转移到共享社区钱包(争用点))
let cpi_context = CpiContext::new(
ctx.accounts.system_program.to_account_info(),
Transfer {
from: ctx.accounts.owner.to_account_info(),
to: ctx.accounts.community_wallet.to_account_info(),
}
);
transfer(cpi_context, lamports_to_donate)?;
// Update tally on the shared account (also contention) (更新共享账户上的统计数据(也是争用))
donation_tally.lamports_donated = donation_tally.lamports_donated.checked_add(lamports_to_donate).unwrap();
donation_tally.lamports_to_redeem = 0;
Ok(())
}每个捐赠交易都直接写入同一个 community_wallet 账户,从而在高负载下引起争用。
Optimized approach (优化方法):
pub fn run_concept_shared_account(ctx: Context<ConceptSharedAccount>, lamports_to_donate: u64) -> Result<()> {
let donation_tally = &mut ctx.accounts.donation_tally;
// Transfer to a unique PDA instead of the shared wallet (转移到唯一的 PDA 而不是共享钱包)
let cpi_context = CpiContext::new(
ctx.accounts.system_program.to_account_info(),
Transfer {
from: ctx.accounts.owner.to_account_info(),
to: donation_tally.to_account_info(),
}
);
transfer(cpi_context, lamports_to_donate)?;
// Update tally on PDA (更新PDA上的计数)
donation_tally.lamports_donated = donation_tally.lamports_donated.checked_add(lamports_to_donate).unwrap();
donation_tally.lamports_to_redeem = donation_tally.lamports_to_redeem.checked_add(lamports_to_donate).unwrap();
Ok(())
}
pub fn run_concept_shared_account_redeem(ctx: Context<ConceptSharedAccountRedeem>) -> Result<()> {
let transfer_amount: u64 = ctx.accounts.donation_tally.lamports_donated;
// Withdraw from PDA balance (从 PDA 余额中提取)
**ctx.accounts.donation_tally.to_account_info().try_borrow_mut_lamports()? -= transfer_amount;
// Deposit into the shared community wallet (less frequent) (存入共享社区钱包(不那么频繁))
**ctx.accounts.community_wallet.to_account_info().try_borrow_mut_lamports()? += transfer_amount;
// Reset redeemable tally (重置可赎回计数)
ctx.accounts.donation_tally.lamports_to_redeem = 0;
Ok(())
}在这里,每个捐赠都进入 dedicated PDA (专用 PDA),从而消除了对社区钱包的争用。一个单独的赎回步骤(调用频率较低)将资金整合到共享钱包中。
结论
我们已经讨论了许多重要的程序架构注意事项:字节、账户、瓶颈等等。无论你是否遇到这些特定问题,我希望这些示例和讨论能够激发新的想法。最终,你才是系统的设计者。你的角色是仔细权衡不同解决方案的优缺点。向前看,但要保持实用。没有一种“正确”的方法来设计任何东西——只需了解所涉及的权衡即可。
如果你对去中心化基础设施、链上数据系统或构建现实世界的项目感兴趣,请继续关注:
- 原文链接: blog.blockmagnates.com/b...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





