基于 EL mempool 的 blob 交易理论命中率 - 网络传输
- 以太坊中文
- 发布于 2025-04-15 15:18
- 阅读 1008
本文分析了以太坊公共 mempool 中 blob 交易的理论命中率,通过研究 EthPandaOps 的 Xatu 数据库中的数据,发现大部分 blob 交易在区块到达前已在 mempool 中可见,尤其是在美国等网络连接较好的地区。

基于 EL mempool 的理论 Blob 命中率
这项工作由我在 ProbeLab 的同事合作完成,并得到了以太坊基金会的支持。本报告旨在分析共识客户端在查询其执行层客户端关于提议的信标区块中包含的 blob 交易时,可以预期的理论 blob 命中率。
非常感谢以太坊基金会网络团队和 EthPandaOps 团队的宝贵反馈。
动机
以太坊正在寻求通过 PeerDAS 来扩大其 blob 吞吐量,这是一个有希望的步骤,可以在不需要每个节点都下载和处理所有数据的情况下,显著提高 blob 计数。虽然这对可扩展性来说是好事,但它给本地构建区块的验证者带来了新的挑战。这些本地构建者仍然需要在 4 秒的区块传播窗口内广播他们引用的所有 blob,这在带宽限制下并不总是可行的。
为了减轻这种负担,有人提出了 分布式区块构建 的概念。这种方法允许本地验证者包含他们已经知道的任何 blob 交易,假设网络中的其他人可能也看到了这些 blob。与其通过 GossipSub 重新广播整个 blob 集合,不如依靠网络来帮助填补空白。当一个节点发现一个区块中包含一个它本地也持有的 blob 交易(通过 engine_getBlobs RPC 调用 EL 进行验证)时,它可以承担起启动其 GossipSub 广播的责任,从而有效地减轻原始区块提议者的负担。
为了评估这种协作式 blob 分发在实践中是否可行,我们的目标是量化在区块提议时 blob 交易的理论可用性。这项研究将调查 mempool 的趋势和 blob 交易的可见性,以了解分布式区块构建是否能够实际支持更高的 blob 计数,而不会使本地验证者不堪重负。
总结
- 假设美国和澳大利亚代表了网络中连接最好和最差的区域(就网络延迟而言),我们发现公共 mempool 中的
99%的 blob 交易在 blob 交易第一次和最后一次被看到之间有 1 秒延迟的情况下,分别在两个位置的 mempool 中被看到。 - 总结一下,我们的结果显示,在提议的 blob 交易中:
14.5%在区块到达之前没有在公共 mempool 中看到,81.91%的 blob 交易不仅是公开的,而且在 slot 开始之前就到达了,- 只有
4,12%的 blob 交易在 slot 开始之后才在公共 mempool 中看到。
- 这些数字表明,至少在理论上,只要公共 blob 交易保持在当前速率,分布式区块构建应该可以正常工作。
- 分布式区块构建的潜在优化:本地构建者可以按照到达 mempool 的相反顺序开始通过 GossipSub 广播 blob-sidecar。这将确保人们可能不知道的 blob 与需要它们的区块共享。
研究
方法论
以下研究依赖于 EthPandaOps 团队通过其公共 Xatu 数据库提供的数据。我们使用了以下 Xatu schema 或表来计算分析:
- Xatu - Beacon API events · ethPandaOps
- Xatu - Mempool events · ethPandaOps
- Xatu - Canonical Beacon chain events · ethPandaOps
研究结果对应于以下日期:
- 日期:从
2025-03-01到2025-03-15 - slot:从
11163298到11264098
* 注意: *
* - 所有来自 mempool 的交易都经过过滤,仅跟踪 blob-tx,因此,该研究仅包含类型为 type == 3 的 tx。*
* - 为了使分布尽可能干净(我试图从中清除异常值),该代码包含一个过滤器,用于删除在第一次到达后 12 秒(1 个 slot)之后发生的到达事件。*
blob-tx 在公共 mempool 上的传播延迟
与在 p2p 网络上分发的信标区块或其他消息类似,网络中不同 peer 的消息的第一次到达和最后一次到达之间始终存在时间差。在下图中,我们展示了 Xatu 为每个公共 blob-tx 收集的测量延迟的 CDF。
更具体地说,该图显示了 tx 第一次被 peer 看到和数据集中跟踪的最后一次到达(即 tx 最后一次被 peer 看到)之间的时间。该图显示,超过 99% 的交易在 1 秒的延迟内被看到。如果我们将分布的平均值或第 50 个百分位数,则此值将减少到 235ms 或更少。
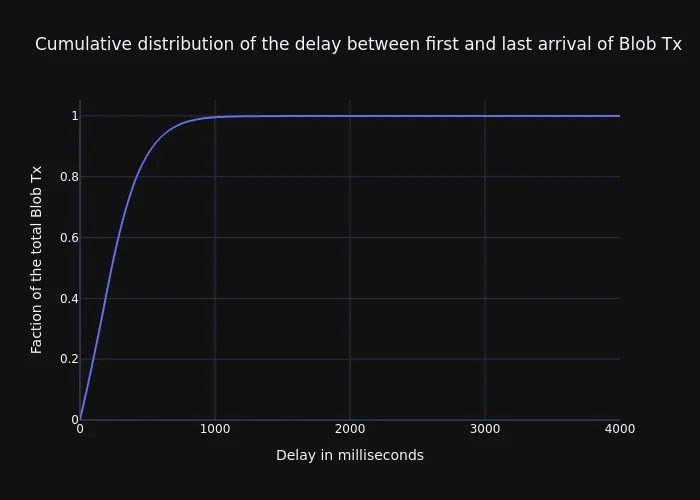 \
image700×500 47.1 KB
\
image700×500 47.1 KB基于节点所在国家/地区的 Blob Tx 到达延迟
尽管以太坊是一个分布式和去中心化的网络,但仍然存在一些突出的网络集群,这些集群可能会影响消息到达在这些集群和位置内运行的节点的时间(当前分布 来自 probelab.io)。下图显示了 blob-tx 的到达时间,使用第一次和最后一次到达之间的平均值作为参考。我们看到的是,美国的节点往往是较早接收到这些消息的节点,如果 CL 通过 engine_getBlobs RPC 调用请求那些更接近信标区块提议共享的 blob,则它们有更高的成功机会。
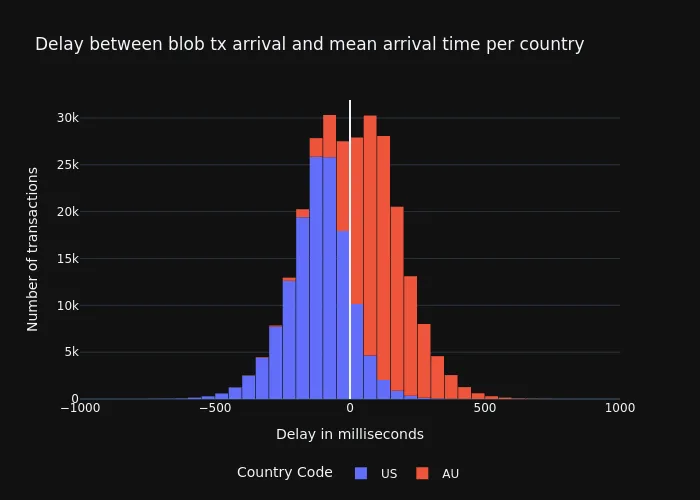 \
image700×500 54.7 KB
\
image700×500 54.7 KBTx 在 mempool 中公开和 slot 开始之间的时间差
一旦我们知道 blob 交易的到达时间和它们被包含的 slot,我们就可以可视化这些交易最初何时到达(最佳情况)、网络的平均值(平均情况)和最差情况(最坏情况),与 slot 开始时间相比。
在结果图表中,我们可以看到最大的公共 blob-txs 块在 slot 之前的 12 秒内到达,最大的峰值发生在 slot 开始时间之前的 3 秒处。有趣的是,甚至有一些 blob-txs 在几个 slot 之前就到达了。
观察:
- 由于 tx 传播的延迟较低,最佳情况和最坏情况之间,或不同国家/地区之间没有太大差异。
- 也许更重要的是,超过
slot-start-time的公共 blob-txs 的百分比仅为4.12%(更多数字在下一节中),而这些 tx 中的大多数仍然在 slot 的前 2 秒内到达。
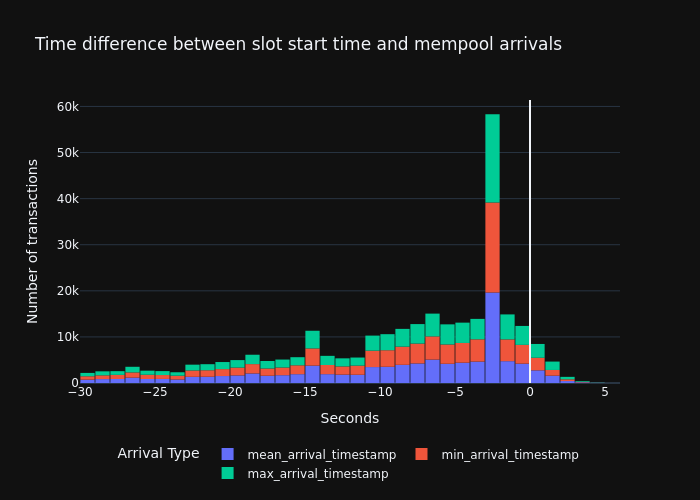 \
image700×500 20.2 KB
\
image700×500 20.2 KBblob tx 的流动
我们已经看到了公共 blob-tx 在它们发布的 slot 开始之前如何在本地 EL mempool 中“可用”。但是,这仍然不足以给我们“分布式区块构建”是否可以工作的大局。换句话说,如果公共交易确实在提议之前可用,但它们仅代表总包含的 blob-txs 的 10%,这意味着 90% 的总 blob-txs 来自私有 mempool。如果是这种情况,peer 将无法在没有首先通过 GossipSub 通道接收它们的情况下发布 blob-sidecar。
我们可能仍然认为这在任何情况下都不会影响本地构建者,因为他们只能提议公共 blob-tx,并且我们可以预期与呈现的数字相似的数字。尽管如此,下图显示了在这些日期内看到的所有 blob 交易的桑基图。
我们可以从中提取的亮点是:
14.76%的提议 blob-tx 来自“私有来源”(*),其他85.78%来自公共 mempool16.28%的公共 blob-tx 从未包含在后续的信标区块 payload 中81.91%的提议 blob-tx 在它们包含的 slot 开始之前在公共 mempool 中看到,只有4.12%在之后到达(其余的是私有的)
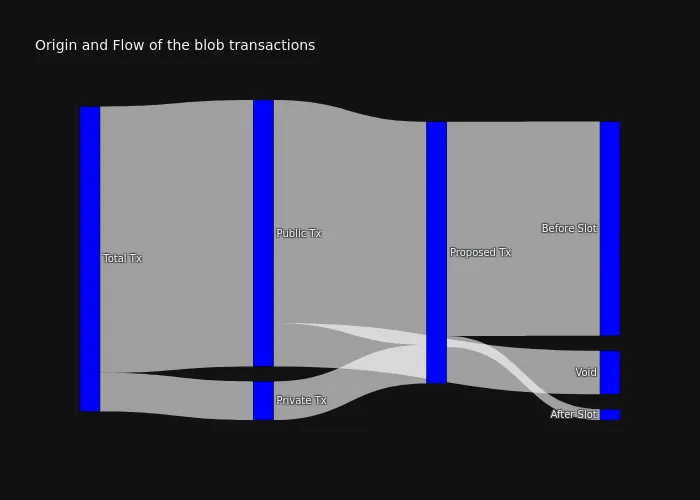 \
image700×500 39.8 KB
\
image700×500 39.8 KB注意: (*)因为我们需要定义我们正在请求的数据的日期,所以我们认为“私有”的某些交易可能之前已经被 mempool 看到过,但是我们无法获取它们,因为它们落在请求的时间之前(这是我们可以根据 Xatu 的查询参数获得的最佳结果)。这最终可能会在识别“私有 tx”时产生误报。
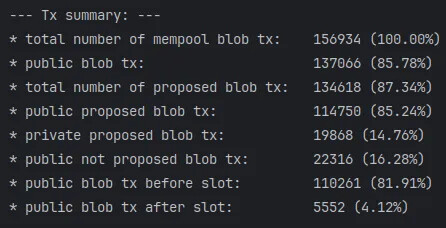 \
image446×228 32.4 KB
\
image446×228 32.4 KB注意: 图中显示的交易百分比是指它们“父”集的总表示。
常见问题
那些“无效”交易发生了什么?
以太坊中的交易可以被回滚或替换,只要它们仍然在 mempool 中并且尚未包含在链上。可以通过提交一个具有相同 nonce 和更高费用的新交易来覆盖交易。这也适用于 blob 交易——只要 nonce 保持不变,它们就可以更新。
我们认为图中标记为“无效”的交易属于这一类,而不是任何形式的审查的结果。
那些“私有 Tx”发生了什么?
(非常感谢 @pop 在这个问题上的投入。)私有 mempool 的使用在以太坊中很常见——作为对抗第三方 MEV 提取的对策,为了实现更快的包含,或者只是为了在包含之前保持交易私有。(有关更多信息,请参阅 @nero_eth 的 帖子)。
但是,blob 交易的性质与通用交易截然不同。它们主要由 L2 使用,用于提交其操作的证明或数据 blob——对于网络中的大多数,这些只是任意字节。这减少了保持它们私有或保护它们免受 MEV 侵害的动机。
我们的研究表明,一般来说,网络依靠公共 mempool 来广播这些交易,至少在绝大多数情况下是这样。也就是说,大约 15% 的 blob 交易似乎来自私有 mempool,其中 Taiko (ZK-rollup) 是主要贡献者(参考图)。
结论
-
该研究表明,目前,网络通常处理公共 blob 交易,节点在它们最终包含的区块到达之前就知道这些交易。
-
以当前的公共 blob tx 速率及其到达 mempool 的时间,像分布式区块构建这样的解决方案可以更容易地更快地处理和传播更高的 blob 计数。
-
这也意味着网络正在分配资源来传播冗余信息,因为大多数提议的 blob tx 首先通过 EL mempool 传播,然后通过 CL 的 gossipsub 主题重新广播。
-
不可避免地,这可能导致大型 blob tx 消费者削减一些资源,因为他们可以只将他们的 blob 一次提交到私有 mempool 或构建者,将那些仅在发布区块时发生的 blob 的传播委托给他们。
-
尽管这对网络有利,因为它意味着有更多的可用带宽(节点不必下载和传播相同的信息两次),但这可能会为 MEV 构建者带来一些中心化风险。
- 原文链接: ethresear.ch/t/theoretic...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





