批量存储提取
- Dedaub
- 发布于 2024-02-08 11:34
- 阅读 1830
本文介绍了如何利用 Geth 的“状态覆盖集”功能,通过修改区块链状态来批量提取智能合约的存储槽,从而减少了传统 eth_getStorageAt 方法的延迟。文章还展示了一个优化的智能合约,用于最大化单次交易中可以读取的存储槽数量,并提供了理论计算和实际测试结果,证明了此方法的有效性。
TONY ROCCO VALENTINE
批量存储提取

大多数 Dapp 开发者都听说过,并且可能使用过优秀的 Multicall 合约来捆绑他们的 eth_call,以减少其应用中批量 ETL 的延迟(我们也是,我们甚至为此开发了一个 Python 库:Manifold)。
不幸的是,在获取存储槽时,我们不能使用同样的技巧。正如我们在开发 存储浏览器 时发现的那样,这迫使开发者为他们想要查询的每个槽发出 eth_getStorageAt 请求。幸运的是,Geth 有个诀窍,即 “State Override Set”,通过一些巧妙的方法,我们可以利用它来进行批量存储提取。
批量存储提取 | Geth 技巧
Geth 的 eth_call 实现的 “state-override set” 参数是一个强大但鲜为人知的功能。(该功能也存在于其他基于 Geth 的节点中,这些节点构成了大多数 EVM 链的基础设施!)此功能支持在修改后的区块链状态上进行交易模拟,而无需本地分叉或其他机制!
使用此功能,我们可以更改任何地址的余额或 nonce,以及设置任何合约的存储或代码。后一种修改在这里很重要,因为它允许我们将想要查询存储的地址上的代码替换为我们自己的合约,该合约实现任意存储查找。
以下是 state-override set 条目的详细结构:
| 字段 | 类型 | 字节 | 可选 | 描述 |
|---|---|---|---|---|
| balance | Quantity | <32 | 是 | 在执行调用之前为帐户设置的虚假余额。 |
| nonce | Quantity | <8 | 是 | 在执行调用之前为帐户设置的虚假 nonce。 |
| code | Binary | 任意 | 是 | 要在执行调用之前注入到帐户中的虚假 EVM 字节码。 |
| state | Object | 任意 | 是 | 要覆盖帐户存储中所有槽的虚假键值映射。 |
| stateDiff | Object | 任意 | 是 | 要覆盖帐户存储中单个槽的虚假键值映射。 |
批量存储提取 | 合约优化器
以下手写智能合约经过优化,旨在最大化我们可以在给定交易中读取的存储槽数量。在深入研究结果之前,我想先讨论一下这个合约,因为它是优化的一次性合约的一个很好的例子,其中包含一些巧妙的(或者至少我们认为是)的快捷方式。
[00] PUSH0 # [0], 初始循环计数器为 0
[01] JUMPDEST
[02] DUP1 # [loop_counter, loop_counter]
[03] CALLDATASIZE # [size, loop_counter, loop_counter]
[04] EQ # [bool, loop_counter]
[05] PUSH1 0x13 # [0x13, bool, loop_counter]
[07] JUMPI # [loop_counter]
[08] DUP1 # [loop_counter, loop_counter]
[09] CALLDATALOAD # [, loop_counter]
[0a] SLOAD # [, loop_counter]
[0b] DUP2 # [loop_counter, , loop_counter]
[0c] MSTORE # [loop_counter]
[0d] PUSH1 0x20 # [0x20, loop_counter]
[0f] ADD # [loop_counter] 我们将 32 添加到它,以移动 1 个字
[10] PUSH1 0x1 # [0x1, loop_counter]
[12] JUMP # [loop_counter]
[13] JUMPDEST
[14] CALLDATASIZE # [size]
[15] PUSH0 # [0, size]
[16] RETURN # []为了更好地理解发生了什么,我们可以看一下高级代码(这实际上是由我们的 反编译器 生成的)
function function_selector() public payable {
v0 = v1 = 0;
while (msg.data.length != v0) {
MEM[v0] = STORAGE[msg.data[v0]];
v0 += 32;
}
return MEM[0: msg.data.length];
}浏览代码我们可以看到,我们循环遍历 calldata,读取每个字,查找相应的存储位置,并将结果写入内存。
主要的优化是:
- 删除对分发函数的需求
- 重用循环计数器来跟踪用于写入结果的存储器位置
- 通过假设输入是连续的字数组(32 字节元素)并使用
calldatalength来计算元素数量,从而删除 abi 编码
如果你认为你可以编写更短或更优化的字节码,请将 PR 提交到 storage-extractor 并在 twitter 上 @ 我们。
批量存储提取 | 结果
理论结果
要计算我们可以提取的最大存储槽数,我们需要三个等式:执行成本(计算为恒定成本加上每次迭代的成本)、内存扩展成本 (3x+(x2/512))(3x+(x^2/512))(3x+(x2/512)) 和 calldata 成本。
我们可以将执行成本分解如下:
- 启动、范围检查和退出将始终至少运行一次
- 每个存储位置将导致 1 个范围检查和 1 个查找
计算 calldata 成本稍微复杂一些,因为它的价格是可变的:空(零字节)calldata 的价格为每字节 4 gas,非零 calldata 的价格为 16 gas。因此,我们需要计算一个字(32 字节)的平均价格的占位符。
zero_byte_gas = 4
non_zero_byte_gas = 16
## 我们将其计算为字节的每个位为 0 的概率
prob_rand_byte_is_zero = (0.5**8) # 0.00390625
prob_rand_byte_non_zero = 1 - prob_rand_byte_is_zero # 0.99609375
avg_cost_byte = (non_zero_byte_gas * prob_rand_byte_non_zero) + \
(zero_byte_gas * prob_rand_byte_is_zero) # (16 * 0.99609375) + (04 * .00390625) = 15.953125因此,平均字成本:15.953125∗32∗x15.953125 * 32 * x15.953125∗32∗x
我们可以将所有这些等式组合起来并求解 gas 限制,以获得可以在一次调用中读取的最大存储槽数。
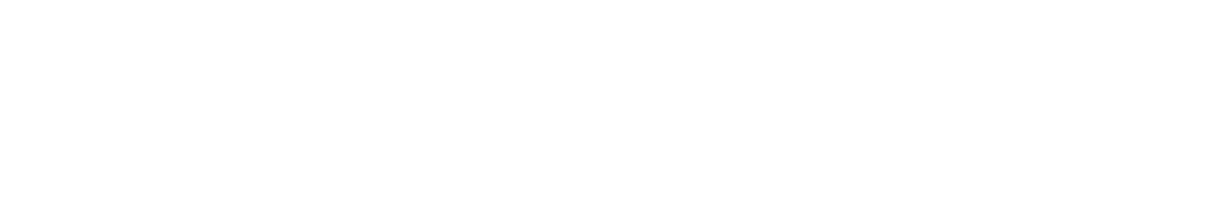
因此,给定 5000 万的 gas 限制(这是 Geth 的默认值),我们可以读取平均 18514 个槽。
这个数字会根据实际访问的存储槽而变化,大多数用户能够访问更多。这是因为大多数存储变量都在合约的初始槽中,只有映射和动态数组被推送到随机槽(或者人们使用高级存储布局,例如 Diamond 代理中使用的布局)。
实践结果
为了展示这种方法的影响,我们编写了一个 Python 脚本,该脚本查询了许多存储槽,首先使用普通 RPC 请求和批量 RPC 请求进行普通 eth_getStorageAt,然后与优化的 eth_call 和 state-override set 进行比较。所有测试代码都可以在 storage-extractor 仓库中找到,以及字节码和结果。
为了将变量延迟作为一个考虑因素隔离出来,我们在与节点相同的机器上运行了测试,并通过使用 asyncio.sleep 重新添加了延迟,以获得受控的测试环境。为了正确理解结果,让我们看一下 200 个并发连接的最佳情况。
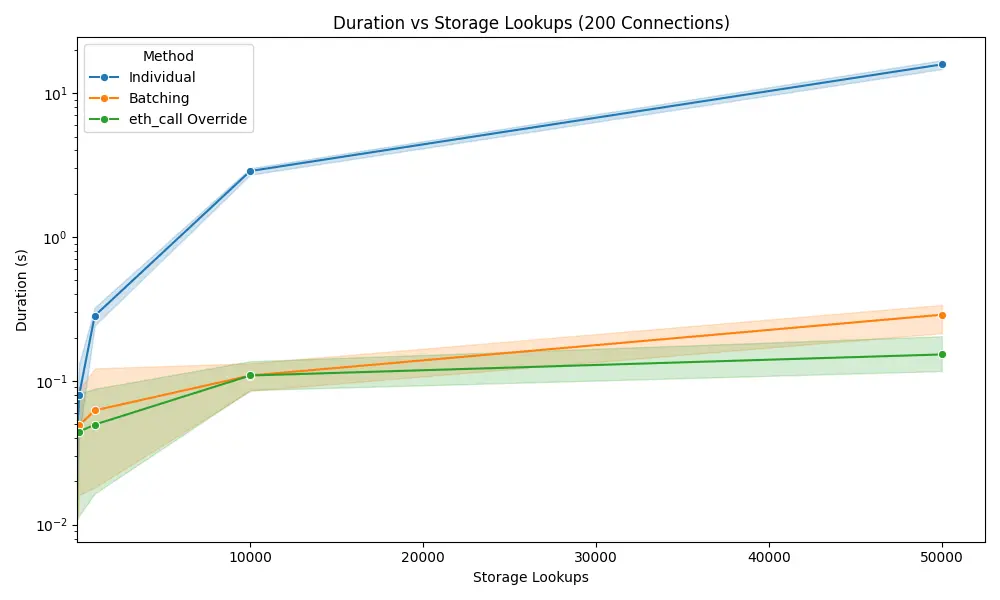
为了正确表示这三种方法,我们需要将 y 轴设置为对数,因为标准并行 eth_getStorageAt 太慢了。正如你所看到的,即使有 200 个连接,标准 RPC 调用也比 RPC 批处理慢 57 倍,比使用 state-override 的 eth_call 慢 103 倍。
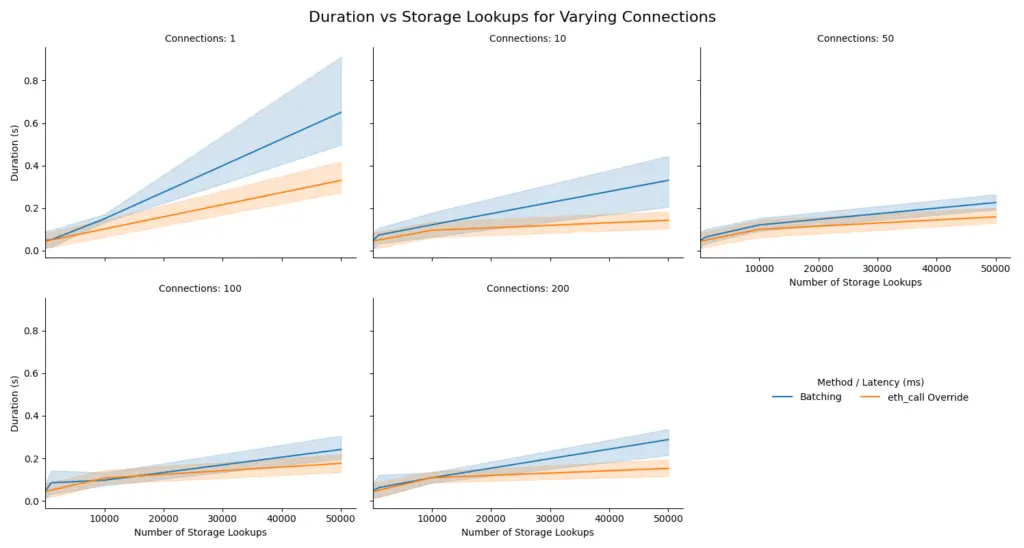
我们可以在下一个图中仔细查看批处理和调用覆盖之间的差异。正如你所看到的,调用覆盖在所有情况下都更快,因为它们需要的连接更少,这在左上角的图中最为明显,该图突出了延迟对总持续时间的影响。
结论
为了总结这篇 Dedaub 博客文章,我想感谢 Geth 开发者所做的所有辛勤工作,以及他们对 RPC 的额外考虑,使我们能够做像这样的时髦的事情,以最大限度地提高我们应用程序的性能。
如果你对 state-override set 有很酷的用法,请在推特上告诉我们,如果你想合作,你可以在随附的 github 仓库(storage-extractor)上提交 PR。
- 原文链接: dedaub.com/blog/bulk-sto...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





