快还不够:为什么你的交易机器人总“打空枪”
- Mr.RC
- 发布于 2025-09-18 13:50
- 阅读 2123
你的机器人很快,优先费也给得高,slot也盯着刷。可交易还是老失败?原因很简单:执行从来不只是“快”或“多给钱”。真正的优势在于“聪明的执行”。认清Solana的执行现实,找准你的执行瓶颈一笔交易从构造到落块,每个环节都可能翻车,路径大概是这样的:
本文由Astralane社区支持提供
你的机器人很快,优先费也给得高,slot 也盯着刷。
可交易还是老失败?
原因很简单:执行从来不只是“快”或“多给钱”。真正的优势在于“聪明的执行”。
认清 Solana 的执行现实,找准你的执行瓶颈
一笔交易从构造到落块,每个环节都可能翻车,路径大概是这样的:
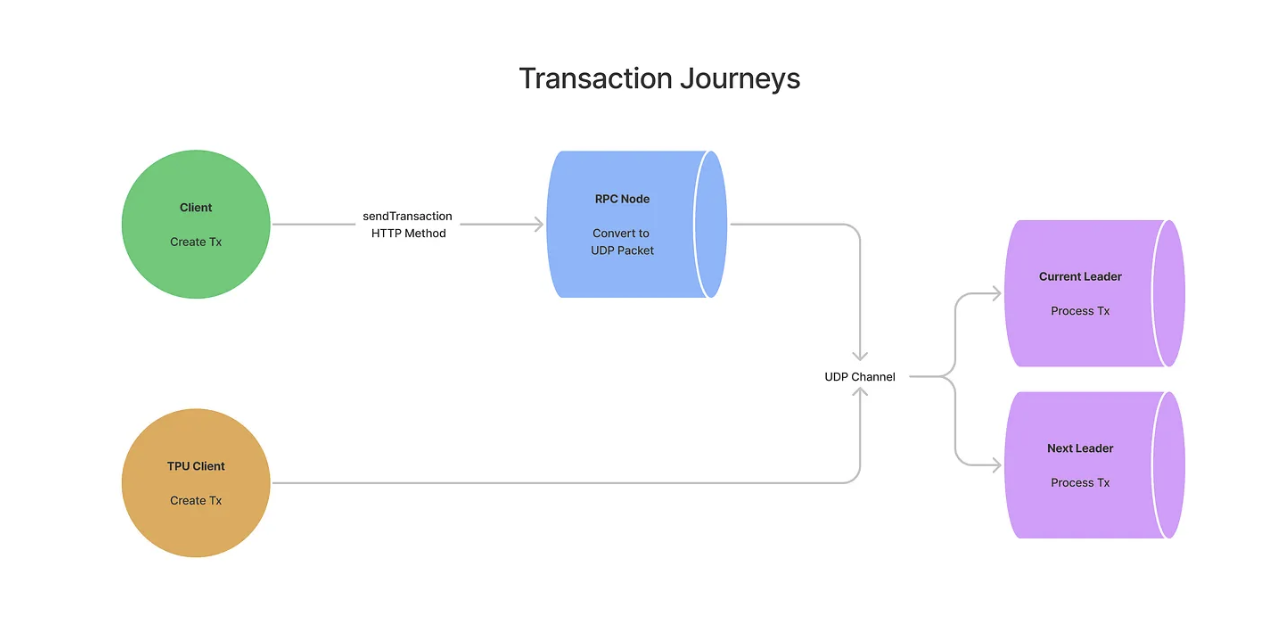 图片来源:solana.com
图片来源:solana.com
1. Solana 的并行运行时
Solana 的智能合约运行时 Sealevel 是完全并行的。每笔交易都会声明自己要读写哪些账户。运行时利用这些声明判断两笔交易能否并行执行,还是必须串行。
如果两笔交易都要写同一个账户,或者一读一写同一个账户,它们就会互相“锁住”,排队串行。 如果没有读写冲突,就可以同时跑。
对你而言,这意味着:只要你的交易触达的是高热度账户(比如代币金库、LP 池、基于 PDA 的订单簿等),而此时槽位里已经有其他交易先一步触达了这些账户,你的交易要么:
- 被排队,只有在该槽位还剩足够的 CU(Compute Units,计算单元)时才有机会执行;要么
- 为了避免锁冲突,直接被跳过(skip)。
你承受不起,而运行时也不会提醒你。它只会跳过然后继续往前跑。
于是就来到下一部分:CU。
2. 每个槽位都有硬性的 Compute 预算
Solana 每个 400ms 的槽位,都有硬性的 CU 上限。一旦该槽位的验证者打满了 CU,就不再接收新的交易——不管你多快、多给优先费、格式多完美。
你的交易大概率是到 slot 时间 +250ms 才抵达,这时 CU 早被花光了。你试着“加小费”(优先费)补救,但当执行窗口已关闭,优先费根本无济于事。
更麻烦的是,CU 估算还会随程序逻辑分支、账户大小而动态变化。
3. 领导者槽位(Leader Slots)
每个槽位都有一个“领导者”(leader)验证者,只有它负责构建并提议该槽位的区块。如果你通过:
- 公共 RPC,
- 跟随者(follower),
- 验证者,
来发送交易,你就得靠二传手把交易转发给真正的 slot leader。
这个中转会慢——在某些情况下能慢到 100–300ms。等你的交易送到实际的区块构建者手里,这个槽位可能已经过去大半了。
若 CU 基本被吃光,或者区块规划已经开始,你就已经“晚了”。
4. Bundle 覆写与 nonce 冲突
Solana 没有全局 mempool,也不保证 leader 收到之前的任何队列内排序。若多笔交易用了相同的 nonce,先到队列的会被接受,后到的会被悄悄丢弃。
这在用同一密钥对频繁重发交易的机器人里非常常见。更糟的是,其他机器人可以观察你的交易,然后抢先发一笔替换交易“顶掉”你。
如何“卷”在别人前面?
1. CU 优化
你可能觉得自己的代码已经“很优化”了,但它是否为“landing 成功率”做过 CU 级别的优化?可以从以下几方面入手:
数据类型(Datatypes): 类型越大,CU 开销越高。像 u64 这样的宽类型,仅在确有必要时才使用。
序列化(Serialization): 零拷贝(zero-copy)序列化/反序列化让你可以直接访问账户数据,不用把它们复制到内存结构里。这样能显著降低 CPU 开销、节省内存,并使指令执行更高效。引入 zero-copy,CU 开销往往能减半甚至更多。
// 6302 CU
pub fn initialize(_ctx: Context) -> Result<()> {
Ok(())
}
// 5020 CU
pub fn initialize_zero_copy(_ctx: Context) -> Result<()> {
Ok(())
}
// 108 CU - 含序列化总 CU 约 2600
let counter = &mut ctx.accounts.counter;
compute_fn! { "Borsh Serialize" =>
counter.count = counter.count.checked_add(1).unwrap();
}
// 151 CU - 含序列化总 CU 约 1254
let counter = &mut ctx.accounts.counter_zero_copy.load_mut()?;
compute_fn! { "Zero Copy Serialize" =>
counter.count = counter.count.checked_add(1).unwrap();
}程序派生地址(PDA): 这点常被忽略,但 find_program_address 的耗时会直接抬高你的 CU。bump 与 CU 近似成反比——bump 越低,CU 越高。把 bump 持久化存到账户里,初始化后复用,能让后续查找快速命中,大幅降低 CU。
用 Pinocchio 替代 solana-program:Pinocchio 通过“零拷贝访问账户数据”帮助开发者降 CU。它基于指针/引用而不是完整反序列化移动数据,例如对 AccountInfo 调用 .key() 返回的是引用而非拷贝。像 p-token(对 SPL Token 的重构)就借助 Pinocchio 把 CU 降了 88–95%。
少搬数据、少做没必要的反序列化,CU 自然下来了。
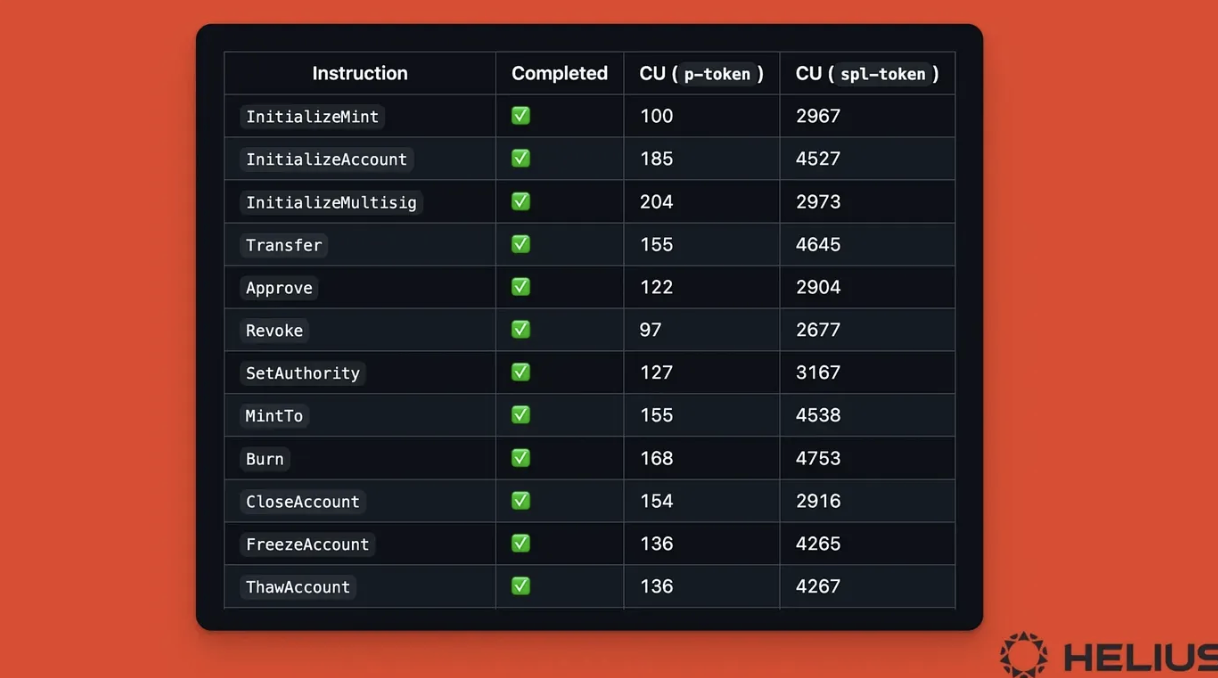 图片来源:helius.com
图片来源:helius.com
2. 槽位感知(slot-aware)执行与领导者感知(leader-aware)路由
在 Solana 的 400ms 槽位里,有一个大约 80–160ms 的“纳入黄金窗”。多数机器人要么:
- 按本地定时器“傻发”(比如“每 400ms 发一次”),
- 要么等日志/确认事件再反应(等你动手,信息已陈旧)。
当你准备出手时,这个槽位往往已经提交,CU 也被吃个干净。即便你是“世界上最快的机器人”,如果发错了验证者,还是白搭。
开发者能做什么?
订阅又快又靠谱的 RPC 推送:
a. slotSubscribe:当验证者处理到新槽位时推送通知
{
"jsonrpc": "2.0",
"id": 1,
"method": "slotSubscribe"
}
通知包含字段:
parent: 父槽位
root: 当前根槽位
slot: 新的槽位号
b. slotsUpdatesSubscribe:关于槽位状态变化的“闪电级”推送
{
"jsonrpc": "2.0",
"id": 1,
"method": "slotsUpdatesSubscribe"
}
通知包含字段:
err: <string|undefined> 若类型为 "dead" 则包含错误信息
parent: <u64|undefined> 若类型为 "createdBank" 则包含父槽位
slot: 被更新的槽位
stats: <object|undefined> 若类型为 "frozen" 则包含统计:
maxTransactionsPerEntry: ,
numFailedTransactions: ,
numSuccessfulTransactions: ,
numTransactionEntries:
timestamp: 毫秒级 Unix 时间戳
type: 更新类型之一:
firstShredReceived
completed
createdBank
frozen
dead
optimisticConfirmation
root
c. getSlotLeader:返回当前槽位的 leader
curl https://api.devnet.solana.com -s -X
POST -H "Content-Type: application/json" -d '{
"jsonrpc":"2.0","id":1,"method":"getSlotLeader",
"params":[{"commitment":"finalized"}]
}'
3. 止盈/止损场景的交易批处理
止损/止盈机器人通常需要:先撤现有单,再挂新单,有时还要对冲。行情一动、机器人齐发,原本“三步走”的小流程分分钟塌掉。
为什么?因为你在:
- 连续背靠背发多笔交易,
- 用的是同一个 nonce,
- 每笔都消耗 CU, 一起往拥堵的槽位里挤。
对策:
- 能合批的依赖动作尽量打包到一笔交易里。
- 非关键交易跨槽位小幅错开发送。
- 预估总 CU,合理分批,不要把单槽位打爆。
- 追踪 tx-1 的确认,再发 tx-2,避免竞态。
4. Durable Nonces(持久随机数)
Durable nonce 是 recent blockhash 的替代方案,用于签名 Solana 交易。 Durable nonce 不会像 blockhash 一样很快过期,何时作废由你控制; 但同一个 durable nonce 只能用一次。
这就能让你:发出“最优优先费”的“最快落地交易”,而无需为多路尝试反复给小费或过度给费。 拆两种典型用法:
a. 以最优优先费实现“最快落地” 你可以构造多笔交易,设定不同的优先费,但共用同一个 durable nonce。由于 nonce 只能用一次,最先落地的那笔会成功,其余的都会因 nonce 无效而失败。你只需为那一笔付费。 优先费可以通过 getRecentPrioritizationFees 来估。它会返回最近区块的优先费样本:
curl https://api.devnet.solana.com -s -X
POST -H "Content-Type: application/json" -d '{
"jsonrpc":"2.0","id":1,"method":"getRecentPrioritizationFees",
"params":[["CxELquR1gPP8wHe33gZ4QxqGB3sZ9RSwsJ2KshVewkFY"]]
}'b. 多路发送服务并行试跑,但只为最快者付费 你可以同时接入多家交易发送通道,让它们发同一笔“共享 durable nonce”的交易,谁先落地谁赢,其余因 nonce 无效而失败,从而只付一次费用。长期看,你还能由此评估各发送服务的真实落地表现。
若通过 Astralane 发送,还可用 sendIdeal:为同一意图并行构造两笔交易,例如“一笔偏向 Jito,一笔偏向 SwQOS”。由于共用 durable nonce,只有最优路径那笔会落地。
请求示例:
{
"id": 1,
"jsonrpc": "2.0",
"method": "sendIdeal",
"params": [[
"transction_with_large_tip_low_priority_fee",
"transaction_with_large_priority_fee_low_tip"
]]
}关于生成 nonce 指令与提交交易的细节,可以查阅我们的文档: https://astralane.gitbook.io/docs/low-latency/submit-transactions#sendideal
5. Keep-Alive 长连
不要每次请求都重新建连、断连。HTTP/TCP 等协议支持长连接(Keep-Alive):在一条长寿命通道上反复收发数据。 长连能避免频繁建连的握手/加密开销,对低时延体系尤为关键。 为什么要用 Keep-Alive?
- 更低延迟
- 更高吞吐
- 更少资源消耗 如何用 Astralane 的 Keep-Alive 方式发送交易? 示例(Rust):
async fn send_txn_with_keep_alive() -> Result<(), Box> {
let client = reqwest::Client::builder()
.pool_idle_timeout(Some(Duration::from_secs(85))) // 连接保活 85 秒
.build()?;
// ... 使用 client 发送
Ok(())
}更多信息请看文档:https://astralane.gitbook.io/docs/low-latency/submit-transactions#sendideal
6. 绕开 Agave 调度瓶颈与自定义 TPU 端口
Solana 的 Agave 客户端在 TPU 内部使用中心化调度器:SigVerify 之后,对交易按 CU 单价(优先费)排序,同时遵守账户锁与 CU 预算。但一旦拥堵,这个调度器会成为瓶颈;若 bundle(例如 Jito)持有独占锁,会进一步导致冲突交易被串行化、延迟纳入。
像 Paladin 这样的自定义 TPU 实现,会开辟专门端口接收 “drop-on-revert” 类型交易——这类交易如执行失败则不收费用,并直接接入调度器做公平排序。实战建议:
- “广撒网争纳入”:用相对高的优先费(例如 getRecentPrioritizationFees 的 75 百分位)+ 适度 Jito 小费(~0.001–0.01 SOL),同时参与两条队列竞争。
- “MEV 敏感场景”:优先费低一些,但给高小费(0.1+ SOL)走 bundle,利用其原子性。
- 用 durable nonce 覆盖相邻多个 leader 槽位重试(可轮询 getLeaderSchedule 获取未来 4–8 个槽位),避免 blockhash 过期问题。
注意:Paladin 目前只覆盖部分验证者;严肃部署应跟踪活跃的 Paladin leaders。当前 paladin tpu 端口接入有门槛:需要质押较多 PAL(如10万+为高吞吐),主要面向早期合作方。
7. 监控你发往服务端的交易质量
大流量发送方要用 getSignatureStatuses 等 RPC 或观测面板跟踪纳入率与时延。如果失败率高(如因 spam 或低质量交易),服务商侧可能触发降权——例如基于最近 X 分钟成功率的动态计分,差评会被降低队列优先级、限制突发,避免冲击网络。优化手段:链下先模拟、限制重试上限、识别并规避账户锁冲突等模式,维持高质量流,避免被“降权”。
8. MEV 保护
Solana 没有私有 mempool。你通过公共 RPC 或未受保护路径发送的交易,会立刻被验证者和其他机器人看到。你若抢在第一时间去清算、打价差或抓 AMM 失衡,这种“可见性”就会变成“被针对”的漏洞。
如何规避?
- 对敏感交易(如清算或套利腿),避免走公共 RPC。
- 尽量使用直连 TPU 或私有转发通道。
- 发单时间加入随机抖动,避免暴露固定节奏。
- 若自建节点,监控验证者日志,警惕“影子跟单”“覆盖提交”等。
在 Astralane,我们在构建 MEV Protect:从槽位层面抵御抄单、覆盖冲突和前置交易。
结语
在 Solana 高强度执行的战场里,把这些优化拿捏到位,才能把“快”真正变成“无可匹敌”。不管你是在和前置博弈的交易机器人开发者,还是在拥堵中扩张的做市商,耐久 nonce、零拷贝范式、以及“领导者感知 + 槽位感知”的策略,都会显著降低被跳过的概率、压低成本、稳住你的优势。Astralane 也在持续推进工具链,比如 Iris:我们的“0 slot”广播服务。
欢迎加入我们的 Discord,一起交流实战、分享经验、与 Solana 同步进化。在这个生态里,胜者从来不只是“更快”,而是“更会跑”,更会“赢在执行”。
加入我们的社区: https://discord.gg/N4MvNqSARc
参考资料: https://solana.com/ru/developers/guides/advanced/how-to-optimize-compute https://solana.com/ru/docs/rpc/websocket https://www.quicknode.com/guides/solana-development/transactions/how-to-optimize-solana-transactions https://www.helius.dev/blog/optimizing-solana-programs https://www.temporal.xyz/writings/durable-nonces https://x.com/chrischang43/status/1945953443006279699





