8个最佳 Hyperliquid RPC 节点供应商
- imperator
- 发布于 2025-10-15 07:51
- 阅读 2027
本文介绍了多个 Hyperliquid RPC 节点供应商,包括 Imperator (HypeRPC)、Chainstack、Lava Network、QuickNode、Alchemy、GetBlock、dRPC 和 Stakely。文章对比了它们在延迟、正常运行时间、可靠性以及其他关键特性方面的表现,旨在帮助开发者选择最适合其需求的 RPC 供应商。
探索顶级 Hyperliquid RPC 节点提供商,从 Imperator (HypeRPC) 到 Alchemy。 了解哪个能提供延迟、正常运行时间和可靠性的最佳平衡。

什么是 Hyperliquid 以及为什么 RPCs 很重要
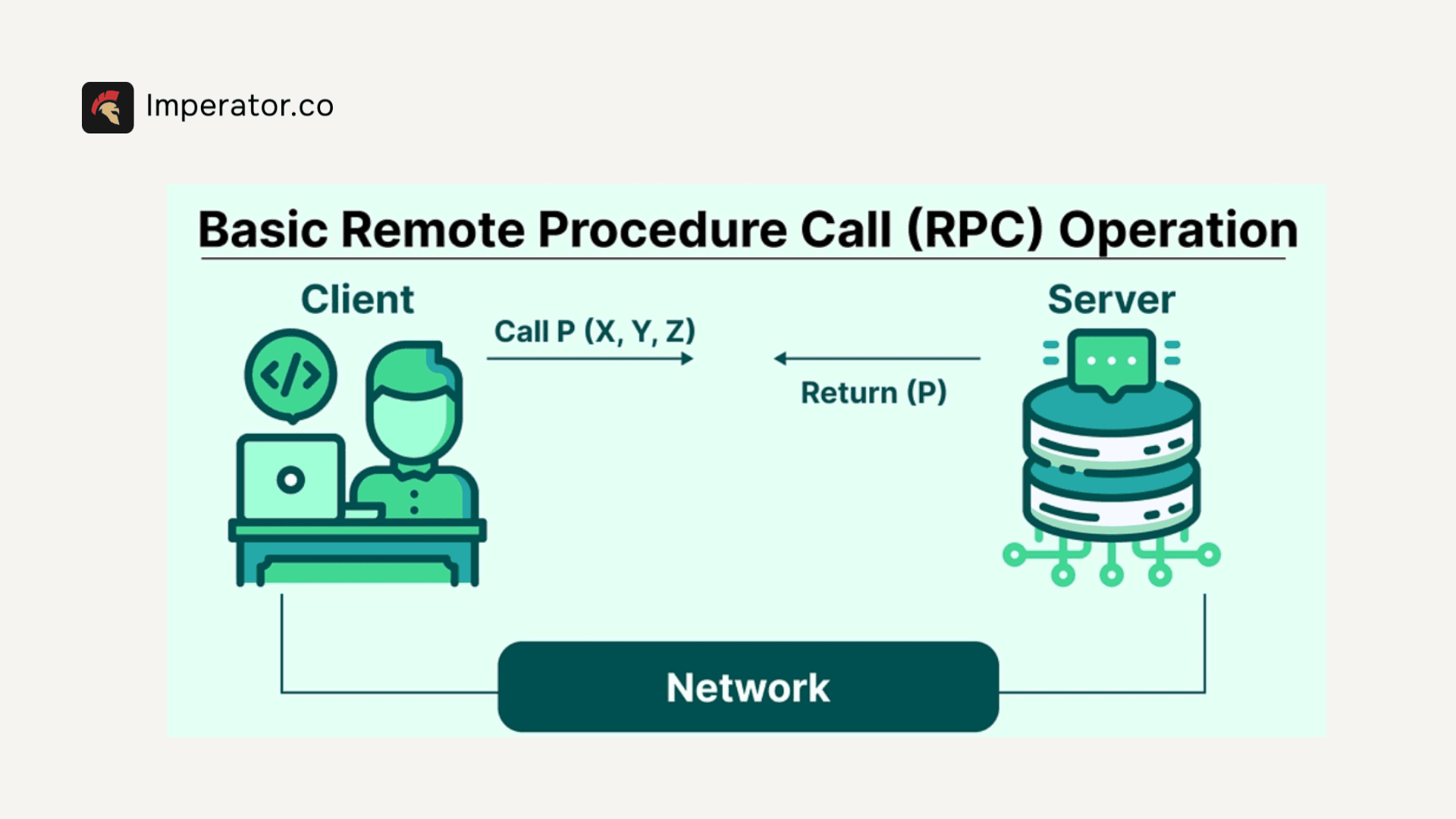
Hyperliquid 是一个为实时、高频交易构建的 Layer-1 区块链。它由两层组成:
-
HyperCore:一个免 gas 的链上订单簿,交易可以即时结算。
-
HyperEVM:一个嵌入式的以太坊风格的层,开发者可以使用 HYPE 作为 gas 来部署合约。
这种组合使其像中心化交易所一样快速,但仍然是去中心化和透明的。
要与任何区块链(包括 Hyperliquid)进行交互,应用程序需要远程过程调用 (RPC) 连接。 将 RPC 视为你的应用程序和区块链之间的通信桥梁。
1. Imperator (HypeRPC)
HypeRPC 由 Imperator 开发,是我们领先的 Hyperliquid RPC 提供商,专为专业级性能而构建。 它利用 Imperator 的验证器基础设施来实现低延迟连接、可靠的吞吐量和无缝集成,使构建者、交易系统和分析工具能够在 Hyperliquid 上高效运行。 以下是更多关键特征:
-
使用 hlnode 和 nanoreth 的双二进制架构,用于稳定的读取和写入操作
-
由 Web3 中最大的多链验证器之一 Imperator 运营
-
Hyperliquid 网络中验证器级别的对齐,以减少延迟
-
跨 欧盟 和 日本 地区的 99.99% 正常运行时间,并自动路由到最快的集群
-
WebSocket 和 HTTPS 支持,用于实时交易、机器人和分析工作负载
-
企业级安全标准,确保生产可靠性
Imperator (HypeRPC) 将验证器级基础设施与构建者友好的工具相结合。 对于任何认真对待在 Hyperliquid 上运行生产工作负载的人来说,这是标准的选择。
2. Chainstack
Chainstack 专注于协作和控制。 它是需要有组织的访问和可预测性能的团队的首选。 它为什么强大:
-
基于项目的管理,具有针对开发人员、分析师和管理员的角色权限。
-
稳定的吞吐量,可以处理生产工作负载,而不会出现意外的延迟峰值。
-
内置日志记录、跟踪和访问仪表板。
-
用于更一致的响应时间的区域节点。
如果你在结构化环境中工作或有多个贡献者,Chainstack 通过组织和可靠性让你安心。
3. Lava Network
Lava Network 提供了一种不同的模型:一个去中心化的 RPC 市场,多个提供商竞争以服务你的请求。 为什么这是一个选择:
-
自动将流量路由到最快的节点以实现低延迟。
-
将多个提供商组合在一个端点后面,以实现内置的故障转移。
-
通过其网关界面显示正常运行时间和提供商性能指标
-
一次集成使你可以访问各种基础设施来源。
如果你想要弹性而又不想受供应商锁定,那么 Lava 的市场设置值得探索。
\
4. QuickNode
QuickNode 除了支持许多其他网络之外,还支持 Hyperliquid。 它专为规模和简单性而设计。 以下是一些优点:
-
在几分钟内创建一个 Hyperliquid 端点。
-
使用情况仪表板显示请求量、延迟和错误率。
-
区域路由可确保全球范围内的快速响应时间。
-
如果你管理多个网络,则统一计费。
QuickNode 最适合已经运行多链基础设施并希望轻松插入 Hyperliquid 的团队。
5. Alchemy
Alchemy 为 Hyperliquid RPCs 带来了企业级的润色。 它以其流畅的开发人员体验和高级工具而闻名。
它为什么脱颖而出:
-
跨主要网络的广泛多链端点支持
-
具有请求指标、延迟跟踪和详细日志的内置可观察性
-
一个平台来管理钱包、汇总和应用程序后端
-
通过简化的控制台进行快速设置和密钥管理
-
价格从入门级到 企业计划 不等
Alchemy 感觉就像使用高级产品:直观、可靠,并且专为重视性能可见性的构建者而设计。
6. GetBlock
GetBlock 简单、快速,非常适合需要快速行动的小团队或内部项目。 用户为什么支持它:
-
在几分钟内启动一个端点,无需设置麻烦。
-
清晰的速率限制和基本分析来监控使用情况。
-
简单的仪表板,用于查看请求和错误。
-
适用于测试、仪表板和机器人的经济实惠的层。
如果你需要一个干净的 RPC 端点而无需管理复杂的系统,GetBlock 可让你快速运行。
7. dRPC
dRPC 专为需要在多个区域实现路由灵活性和稳定性能的团队而构建。 它旨在保持你的 RPC 流量快速且可靠,即使某个位置的速度减慢。 人们为什么使用它:
-
多区域设置,可自动平衡请求以实现更平滑的延迟。
-
适用于不同可靠性需求的主动-主动和主动-被动故障转移模式。
-
内置日志和指标有助于跟踪请求并快速发现错误。
-
区域转向将用户发送到最近的集群以获得更快的响应时间。
如果你的项目在不同的时区运行机器人或仪表板,dRPC 可以保持一切一致,而无需手动负载平衡。
8. Stakely
Stakely 是一个由验证器运营的基础设施提供商,通过 Web3 API 负载平衡器和托管 RPC 服务提供 Hyperliquid 访问。 团队可以从公共端点开始进行快速测试,并随着流量的增长而转移到专用容量。
-
具有记录的速率限制的快速设置的公共负载平衡端点
-
具有共享或专用节点以及可用时存档选项的托管 RPC
-
具有持续监控的全球基础设施,可实现稳定的延迟和可用性
-
清晰的维护说明和计划的更改窗口,用于可预测的操作
-
在多个网络中的验证器背景和积极参与
-
从免费访问到专用容量和自定义路由的直接升级路径
选择最佳 Hyperliquid RPC 节点提供商
始终进行尽职调查。 适合的 Hyperliquid RPC 提供商 是在你的环境中证明自己的那个。 通过在你的目标区域进行基准测试,验证 p50/p95/p99 延迟、抖动和错误率,审查正常运行时间和事件历史记录,确认速率限制、重试行为和 WebSocket 稳定性,测试负载下的故障转移,并确保定价、配额和支持与你的增长计划保持一致,来选择在你的环境中证明自己的 Hyperliquid RPC 提供商。
常见问题解答
-
哪个是最好的 Hyperliquid RPC 节点提供商?
如果你需要大规模的可靠性,HypeRPC 是最佳选择。 它与 Hyperliquid 的验证器基础设施保持一致,并以记录在案的正常运行时间 SLA 为目标,实现低延迟访问。
-
Hyperliquid 是否收取 gas 费?
这取决于你使用网络的哪个部分。 HyperCore(交易引擎)完全免 gas; 交易仅支付交易费用。 另一方面,HyperEVM 的工作方式类似于以太坊。 在那里部署智能合约的开发人员以 HYPE(原生代币)支付 gas。 这种设置使交易成本低廉,同时仍然支持链上的高级应用程序。
-
为什么要使用多个 RPC 提供商?
使用多个 RPC 提供商可以提高正常运行时间和可靠性。 如果一个节点出现故障,你的系统可以自动将流量重新路由到另一个节点。 这有助于防止网络拥塞或维护期间的中断。 许多团队运行一个用于生产的“主” RPC,一个用于备份或分析的“辅助” RPC - 这是一种即使在停机期间也能保持在线的简单方法。
-
在选择 RPC 提供商之前应该检查什么?
寻找三个主要事项:延迟、可靠性和可见性。 测试请求返回数据的速度(p95 延迟),检查正常运行时间记录,并确认每个提供商如何处理速率限制和故障转移。 此外,请查看它们是否提供仪表板或日志,这有助于你及早发现问题。 良好的 RPC 应该随着你的项目扩展,而不是随着流量的增长而减慢它的速度。
\
- 原文链接: imperator.co/resources/b...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





