死磕以太坊源码分析之downloader同步
- 链上无名
- 发布于 2021-02-24 08:47
- 阅读 7544
死磕以太坊源码分析之downloader同步
死磕以太坊源码分析之downloader同步
需要配合注释代码看:https://github.com/blockchainGuide/ 给个star哦
这篇文章篇幅较长,能看下去的是条汉子,建议收藏
希望读者在阅读过程中,指出问题,给个关注,一起探讨。
概览
downloader 模块的代码位于 eth/downloader 目录下1。主要的功能代码分别是:
-
downloader.go:实现了区块同步逻辑 -
peer.go:对区块各个阶段的组装,下面的各个FetchXXX就是很依赖这个模块。 -
queue.go:对eth/peer.go的封装 -
statesync.go:同步state对象
同步模式
full sync
full 模式会在数据库中保存所有区块数据,同步时从远程节点同步 header 和 body 数据,而state 和 receipt 数据则是在本地计算出来的。
在 full 模式下,downloader 会同步区块的 header 和 body 数据组成一个区块,然后通过 blockchain 模块的 BlockChain.InsertChain 向数据库中插入区块。在 BlockChain.InsertChain 中,会逐个计算和验证每个块的 state 和 recepit 等数据,如果一切正常就将区块数据以及自己计算得到的 state、recepit 数据一起写入到数据库中。
fast sync
fast 模式下,recepit 不再由本地计算,而是和区块数据一样,直接由 downloader 从其它节点中同步;state 数据并不会全部计算和下载,而是选一个较新的区块(称之为 pivot)的 state 进行下载,以这个区块为分界,之前的区块是没有 state 数据的,之后的区块会像 full 模式下一样在本地计算 state。因此在 fast 模式下,同步的数据除了 header 和 body,还有 receipt,以及 pivot 区块的 state。
因此 fast 模式忽略了大部分 state 数据,并且使用网络直接同步 receipt 数据的方式替换了 full 模式下的本地计算,所以比较快。
light sync
light 模式也叫做轻模式,它只对区块头进行同步,而不同步其它的数据。
SyncMode:
- FullSync:从完整区块同步整个区块链历史
- FastSync:快速下载标题,仅在链头处完全同步
- LightSync:仅下载标题,然后终止
区块下载流程
图片只是大概的描述一下,实际还是要结合代码,所有区块链相关文章合集,https://github.com/blockchainGuide/
同时希望结识更多区块链圈子的人,可以star上面项目,持续更新
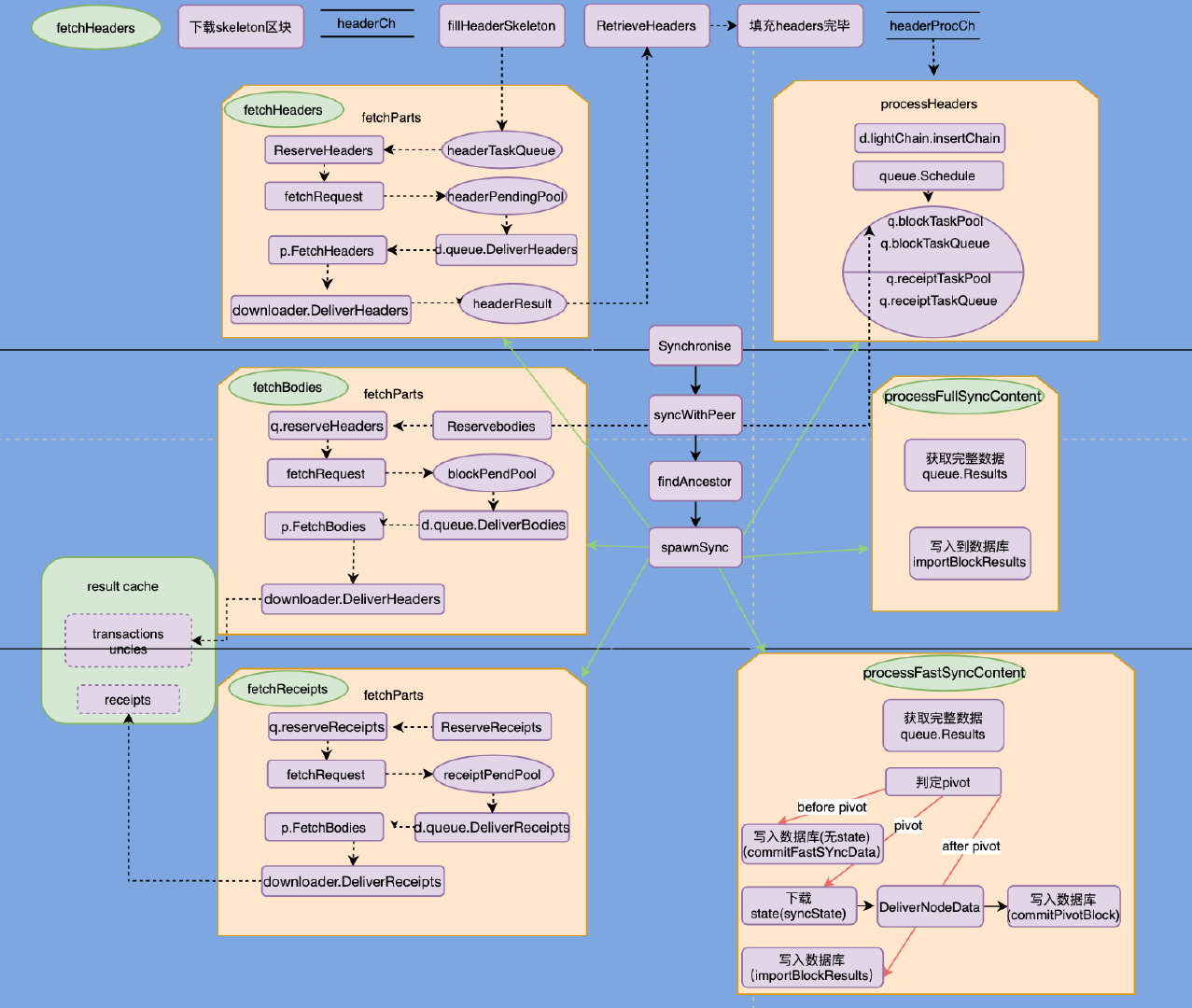
首先根据Synchronise开始区块同步,通过findAncestor找到指定节点的共同祖先,并在此高度进行同步,同时开启多个goroutine同步不同的数据:header、receipt、body。假如同步高度为 100 的区块,必须先header同步成功同步完成才可以唤醒body和receipts的同步。
而每个部分的同步大致都是由FetchParts来完成的,里面包含了各个Chan的配合,也会涉及不少的回调函数,总而言之多读几遍每次都会有不同的理解。接下来就逐步分析这些关键内容。
synchronise
①:确保对方的TD高于我们自己的TD
currentBlock := pm.blockchain.CurrentBlock()
td := pm.blockchain.GetTd(currentBlock.Hash(), currentBlock.NumberU64())
pHead, pTd := peer.Head()
if pTd.Cmp(td) <= 0 {
return
}②:开启downloader的同步
pm.downloader.Synchronise(peer.id, pHead, pTd, mode)进入函数:主要做了以下几件事:
d.synchronise(id, head, td, mode):同步过程- 错误日志输出, 并删除此
peer。
进入到d.synchronise,走到最后一步d.syncWithPeer(p, hash, td)真正开启同步。
func (d *Downloader) synchronise(id string, hash common.Hash, td *big.Int, mode SyncMode) error {
...
return d.syncWithPeer(p, hash, td)
}syncWithPeer大概做了以下几件事:
- 查找祖先
findAncestor - 开启单独
goroutine分别运行以下几个函数:- fetchHeaders
- processHeaders
- fetchbodies
- fetchReceipts
- processFastSyncContent
- processFullSyncContent
接下来的文章,以及整个Downloader模块主要内容就是围绕这几个部分进行展开。
findAncestor
同步首要的是确定同步区块的区间:顶部为远程节点的最高区块,底部为两个节点都拥有的相同区块的最高高度(祖先区块)。findAncestor就是用来找祖先区块。函数分析如下:
①:确定本地高度和远程节点的最高高度
var (
floor = int64(-1) // 底部
localHeight uint64 // 本地最高高度
remoteHeight = remoteHeader.Number.Uint64() // 远程节点最高高度
)
switch d.mode {
case FullSync:
localHeight = d.blockchain.CurrentBlock().NumberU64()
case FastSync:
localHeight = d.blockchain.CurrentFastBlock().NumberU64()
default:
localHeight = d.lightchain.CurrentHeader().Number.Uint64()
}②:计算同步的高度区间和间隔
from, count, skip, max := calculateRequestSpan(remoteHeight, localHeight) from::表示从哪个高度开始获取区块count:表示从远程节点获取多少个区块skip:表示间隔,比如skip为 2 ,获取第一个高度为 5,则第二个就是 8max:表示最大高度
③:发送获取header的请求
go p.peer.RequestHeadersByNumber(uint64(from), count, skip, false)④:处理上面请求接收到的header :case packet := <-d.headerCh
- 丢弃掉不是来自我们请求节的内容
- 确保返回的
header数量不为空 - 验证返回的
headers的高度是我们所请求的 - 检查是否找到共同祖先
//----①
if packet.PeerId() != p.id {
log.Debug("Received headers from incorrect peer", "peer", packet.PeerId())
break
}
//-----②
headers := packet.(*headerPack).headers
if len(headers) == 0 {
p.log.Warn("Empty head header set")
return 0
}
//-----③
for i, header := range headers {
expectNumber := from + int64(i)*int64(skip+1)
if number := header.Number.Int64(); number != expectNumber { // 验证这些返回的header是否是我们上面请求的headers
p.log.Warn("Head headers broke chain ordering", "index", i, "requested", expectNumber, "received", number)
return 0, errInvalidChain
}
}
//-----④
// 检查是否找到共同祖先
finished = true
//注意这里是从headers最后一个元素开始查找,也就是高度最高的区块。
for i := len(headers) - 1; i >= 0; i-- {
// 跳过不在我们请求的高度区间内的区块
if headers[i].Number.Int64() < from || headers[i].Number.Uint64() > max {
continue
}
// //检查我们本地是否已经有某个区块了,如果有就算是找到了共同祖先,
//并将共同祖先的哈希和高度设置在number和hash变量中。
h := headers[i].Hash()
n := headers[i].Number.Uint64()
⑤:如果通过固定间隔法找到了共同祖先则返回祖先,会对其高度与 floor 变量进行验证, floor 变量代表的是共同祖先的高度的最小值,如果找到共同祖先的高度比这个值还小,就认为是两个节点之间分叉太大了,不再允许进行同步。如果一切正常,就返回找到的共同祖先的高度 number 变量。
if hash != (common.Hash{}) {
if int64(number) <= floor {
return 0, errInvalidAncestor
}
return number, nil
}⑥:如果固定间隔法没有找到祖先则通过二分法来查找祖先,这部分可以思想跟二分法算法类似,有兴趣的可以细看。
queue详解
queue对象和Downloader对象是相互作用的,Downloader的很多功能离不开他,接下来我们介绍一下这部分内容,但是本节,可以先行跳过,等到了阅读下面的关于Queue调用的一些函数部分再回过来阅读这部分讲解。
queue结构体
type queue struct {
mode SyncMode // 同步模式
// header处理相关
headerHead common.Hash //最后一个排队的标头的哈希值以验证顺序
headerTaskPool map[uint64]*types.Header //待处理的标头检索任务,将起始索引映射到框架标头
headerTaskQueue *prque.Prque //骨架索引的优先级队列,以获取用于的填充标头
headerPeerMiss map[string]map[uint64]struct{} //已知不可用的对等头批处理集
headerPendPool map[string]*fetchRequest //当前挂起的头检索操作
headerResults []*types.Header //结果缓存累积完成的头
headerProced int //从结果中拿出来已经处理的header
headerContCh chan bool //header下载完成时通知的频道
blockTaskPool map[common.Hash]*types.Header //待处理的块(body)检索任务,将哈希映射到header
blockTaskQueue *prque.Prque //标头的优先级队列,以用于获取块(bodies)
blockPendPool map[string]*fetchRequest //当前的正在处理的块(body)检索操作
blockDonePool map[common.Hash]struct{} //已经完成的块(body)
receiptTaskPool map[common.Hash]*types.Header //待处理的收据检索任务,将哈希映射到header
receiptTaskQueue *prque.Prque //标头的优先级队列,以用于获取收据
receiptPendPool map[string]*fetchRequest //当前的正在处理的收据检索操作
receiptDonePool map[common.Hash]struct{} //已经完成的收据
resultCache []*fetchResult //下载但尚未交付获取结果
resultOffset uint64 //区块链中第一个缓存的获取结果的偏移量
resultSize common.StorageSize // 块的近似大小
lock *sync.Mutex
active *sync.Cond
closed bool
}主要细分功能
数据下载开始安排任务
ScheduleSkeleton:将一批header检索任务添加到队列中,以填充已检索的header skeletonSchedule:用来准备对一些body和receipt数据的下载
数据下载中的各类状态
-
pendingpending表示待检索的XXX请求的数量,包括了:PendingHeaders、PendingBlocks、PendingReceipts,分别都是对应取XXXTaskQueue的长度。 -
InFlightInFlight表示是否有正在获取XXX的请求,包括:InFlightHeaders、InFlightBlocks、InFlightReceipts,都是通过判断len(q.receiptPendPool) > 0来确认。 -
ShouldThrottleShouldThrottle表示检查是否应该限制下载XXX,包括:ShouldThrottleBlocks、ShouldThrottleReceipts,主要是为了防止下载过程中本地内存占用过大。 -
ReserveReserve通过构造一个fetchRequest结构并返回,向调用者提供指定数量的待下载的数据的信息(queue内部会将这些数据标记为「正在下载」)。调用者使用返回的fetchRequest数据向远程节点发起新的获取数据的请求。包括:ReserveHeaders、ReserveBodies、ReserveReceipts。 -
CancelCance用来撤消对fetchRequest结构中的数据的下载(queue内部会将这些数据重新从「正在下载」的状态更改为「等待下载」)。包括:CancelHeaders、CancelBodies、CancelReceipts。 -
expireexpire检查正在执行中的请求是否超过了超时限制,包括:ExpireHeaders、ExpireBodies、ExpireReceipts。 -
Deliver当有数据下载成功时,调用者会使用
deliver功能用来通知queue对象。包括:DeliverHeaders、DeliverBodies、DeliverReceipts。
数据下载完成获取区块数据
RetrieveHeaders在填充skeleton完成后,queue.RetrieveHeaders用来获取整个skeleton中的所有header。Resultsqueue.Results用来获取当前的header、body和receipt(只在fast模式下) 都已下载成功的区块(并将这些区块从queue内部移除)
函数实现
ScheduleSkeleton
queue.ScheduleSkeleton主要是为了填充skeleton,它的参数是要下载区块的起始高度和所有 skeleton 区块头,最核心的内容则是下面这段循环:
func (q *queue) ScheduleSkeleton(from uint64, skeleton []*types.Header) {
......
for i, header := range skeleton {
index := from + uint64(i*y)
q.headerTaskPool[index] = header
q.headerTaskQueue.Push(index, -int64(index))
}
}假设已确定需要下载的区块高度区间是从 10 到 46,MaxHeaderFetch 的值为 10,那么这个高度区块就会被分成 3 组:10 - 19,20 - 29,30 - 39,而 skeleton 则分别由高度为 19、29、39 的区块头组成。循环中的 index 变量实际上是每一组区块中的第一个区块的高度(比如 10、20、30),queue.headerTaskPool 实际上是一个每一组区块中第一个区块的高度到最后一个区块的 header 的映射
headerTaskPool = {
10: headerOf_19,
20: headerOf_20,
30: headerOf_39,
}ReserveHeaders
reserve 用来获取可下载的数据。
reserve = func(p *peerConnection, count int) (*fetchRequest, bool, error) {
return d.queue.ReserveHeaders(p, count), false, nil
}func (q *queue) ReserveHeaders(p *peerConnection, count int) *fetchRequest {
if _, ok := q.headerPendPool[p.id]; ok {
return nil
} //①
...
send, skip := uint64(0), []uint64{}
for send == 0 && !q.headerTaskQueue.Empty() {
from, _ := q.headerTaskQueue.Pop()
if q.headerPeerMiss[p.id] != nil {
if _, ok := q.headerPeerMiss[p.id][from.(uint64)]; ok {
skip = append(skip, from.(uint64))
continue
}
}
send = from.(uint64) // ②
}
...
for _, from := range skip {
q.headerTaskQueue.Push(from, -int64(from))
} // ③
...
request := &fetchRequest{
Peer: p,
From: send,
Time: time.Now(),
}
q.headerPendPool[p.id] = request // ④
}①:根据headerPendPool来判断远程节点是否正在下载数据信息。
②:从headerTaskQueue取出值作为本次请求的起始高度,赋值给send变量,在这个过程中会排除headerPeerMiss所记录的节点下载数据失败的信息。
③:将失败的任务再重新写回task queue
④:利用send变量构造fetchRequest结构,此结构是用来作为FetchHeaders来使用的:
fetch = func(p *peerConnection, req *fetchRequest) error {
return p.FetchHeaders(req.From, MaxHeaderFetch)
}至此,ReserveHeaders会从任务队列里选择最小的起始高度并构造fetchRequest传递给fetch获取数据。
DeliverHeaders
deliver = func(packet dataPack) (int, error) {
pack := packet.(*headerPack)
return d.queue.DeliverHeaders(pack.peerID, pack.headers, d.headerProcCh)
}①:如果发现下载数据的节点没有在 queue.headerPendPool 中,就直接返回错误;否则就继续处理,并将节点记录从 queue.headerPendPool 中删除。
request := q.headerPendPool[id]
if request == nil {
return 0, errNoFetchesPending
}
headerReqTimer.UpdateSince(request.Time)
delete(q.headerPendPool, id)②:验证headers
包括三方面验证:
- 检查起始区块的高度和哈希
- 检查高度的连接性
- 检查哈希的连接性
if accepted {
//检查起始区块的高度和哈希
if headers[0].Number.Uint64() != request.From {
...
accepted = false
} else if headers[len(headers)-1].Hash() != target {
...
accepted = false
}
}
if accepted {
for i, header := range headers[1:] {
hash := header.Hash() // 检查高度的连接性
if want := request.From + 1 + uint64(i); header.Number.Uint64() != want {
...
}
if headers[i].Hash() != header.ParentHash { // 检查哈希的连接性
...
}
}
}③: 将无效数据存入headerPeerMiss,并将这组区块起始高度重新放入headerTaskQueue
if !accepted {
...
miss := q.headerPeerMiss[id]
if miss == nil {
q.headerPeerMiss[id] = make(map[uint64]struct{})
miss = q.headerPeerMiss[id]
}
miss[request.From] = struct{}{}
q.headerTaskQueue.Push(request.From, -int64(request.From))
return 0, errors.New("delivery not accepted")
}④:保存数据,并通知headerProcCh处理新的header
if ready > 0 {
process := make([]*types.Header, ready)
copy(process, q.headerResults[q.headerProced:q.headerProced+ready])
select {
case headerProcCh <- process:
q.headerProced += len(process)
default:
}
}⑤:发送消息给.headerContCh,通知skeleton 都被下载完了
if len(q.headerTaskPool) == 0 {
q.headerContCh <- false
}DeliverHeaders 会对数据进行检验和保存,并发送 channel 消息给 Downloader.processHeaders 和 Downloader.fetchParts的 wakeCh 参数。
Schedule
processHeaders在处理header数据的时候,会调用queue.Schedule 为下载 body 和 receipt 作准备。
inserts := d.queue.Schedule(chunk, origin)func (q *queue) Schedule(headers []*types.Header, from uint64) []*types.Header {
inserts := make([]*types.Header, 0, len(headers))
for _, header := range headers {
//校验
...
q.blockTaskPool[hash] = header
q.blockTaskQueue.Push(header, -int64(header.Number.Uint64()))
if q.mode == FastSync {
q.receiptTaskPool[hash] = header
q.receiptTaskQueue.Push(header, -int64(header.Number.Uint64()))
}
inserts = append(inserts, header)
q.headerHead = hash
from++
}
return inserts
}这个函数主要就是将信息写入到body和receipt队列,等待调度。
ReserveBody&Receipt
在 queue 中准备好了 body 和 receipt 相关的数据, processHeaders最后一段,是唤醒下载Bodyies和Receipts的关键代码,会通知 fetchBodies 和 fetchReceipts 可以对各自的数据进行下载了。
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select {
case ch <- true:
default:
}
}而fetchXXX 会调用fetchParts,逻辑类似上面的的,reserve最终则会调用reserveHeaders,deliver 最终调用的是 queue.deliver.
先来分析reserveHeaders:
①:如果没有可处理的任务,直接返回
if taskQueue.Empty() {
return nil, false, nil
}②:如果参数给定的节点正在下载数据,返回
if _, ok := pendPool[p.id]; ok {
return nil, false, nil
}③:计算 queue 对象中的缓存空间还可以容纳多少条数据
space := q.resultSlots(pendPool, donePool)④:从 「task queue」 中依次取出任务进行处理
主要实现以下功能:
- 计算当前 header 在
queue.resultCache中的位置,然后填充queue.resultCache中相应位置的元素 - 处理空区块的情况,若为空不下载。
- 处理远程节点缺少这个当前区块数据的情况,如果发现这个节点曾经下载当前数据失败过,就不再让它下载了。
注意:resultCache 字段用来记录所有正在被处理的数据的处理结果,它的元素类型是 fetchResult 。它的 Pending 字段代表当前区块还有几类数据需要下载。这里需要下载的数据最多有两类:body 和 receipt,full 模式下只需要下载 body 数据,而 fast 模式要多下载一个 receipt 数据。
for proc := 0; proc < space && len(send) < count && !taskQueue.Empty(); proc++ {
header := taskQueue.PopItem().(*types.Header)
hash := header.Hash()
index := int(header.Number.Int64() - int64(q.resultOffset))
if index >= len(q.resultCache) || index < 0 {
....
}
if q.resultCache[index] == nil {
components := 1
if q.mode == FastSync {
components = 2
}
q.resultCache[index] = &fetchResult{
Pending: components,
Hash: hash,
Header: header,
}
}
if isNoop(header) {
donePool[hash] = struct{}{}
delete(taskPool, hash)
space, proc = space-1, proc-1
q.resultCache[index].Pending--
progress = true
continue
}
if p.Lacks(hash) {
skip = append(skip, header)
} else {
send = append(send, header)
}
}最后就是构造 fetchRequest 结构并返回。
DeliverBodies&Receipts
body 或 receipt 数据都已经通过 reserve 操作构造了 fetchRequest 结构并传给 fetch,接下来就是等待数据的到达,数据下载成功后,会调用 queue 对象的 deliver 方法进行传递,包括 queue.DeliverBodies 和 queue.DeliverReceipts。这两个方法都以不同的参数调用了 queue.deliver 方法:
①:如果下载的数据数量为 0,则把所有此节点此次下载的数据标记为「缺失」
if results == 0 {
for _, header := range request.Headers {
request.Peer.MarkLacking(header.Hash())
}
}②:循环处理数据,通过调用reconstruct 填充 resultCache[index] 中的相应的字段
for i, header := range request.Headers {
...
if err := reconstruct(header, i, q.resultCache[index]); err != nil {
failure = err
break
}
}③:验证resultCache 中的数据,其对应的 request.Headers 中的 header 都应为 nil,若不是则说明验证未通过,需要假如到task queue重新下载
for _, header := range request.Headers {
if header != nil {
taskQueue.Push(header, -int64(header.Number.Uint64()))
}
}④:如果有数据被验证通过且写入 queue.resultCache 中了(accepted > 0),发送 queue.active 消息。Results 会等待这这个信号。
Results
当(header、body、receipt)都下载完,就要将区块写入到数据库了,queue.Results 就是用来返回所有目前已经下载完成的数据,它在 Downloader.processFullSyncContent 和 Downloader.processFastSyncContent 中被调用。代码比较简单就不多说了。
到此为止queue对象就分析的差不多了。
同步headers
fetchHeaders
同步headers 是是由函数fetchHeaders来完成的。
fetchHeaders的大致思想:
同步header的数据会被填充到skeleton,每次从远程节点获取区块数据最大为MaxHeaderFetch(192),所以要获取的区块数据如果大于192 ,会被分成组,每组MaxHeaderFetch,剩余的不足192个的不会填充进skeleton,具体步骤如下图所示:
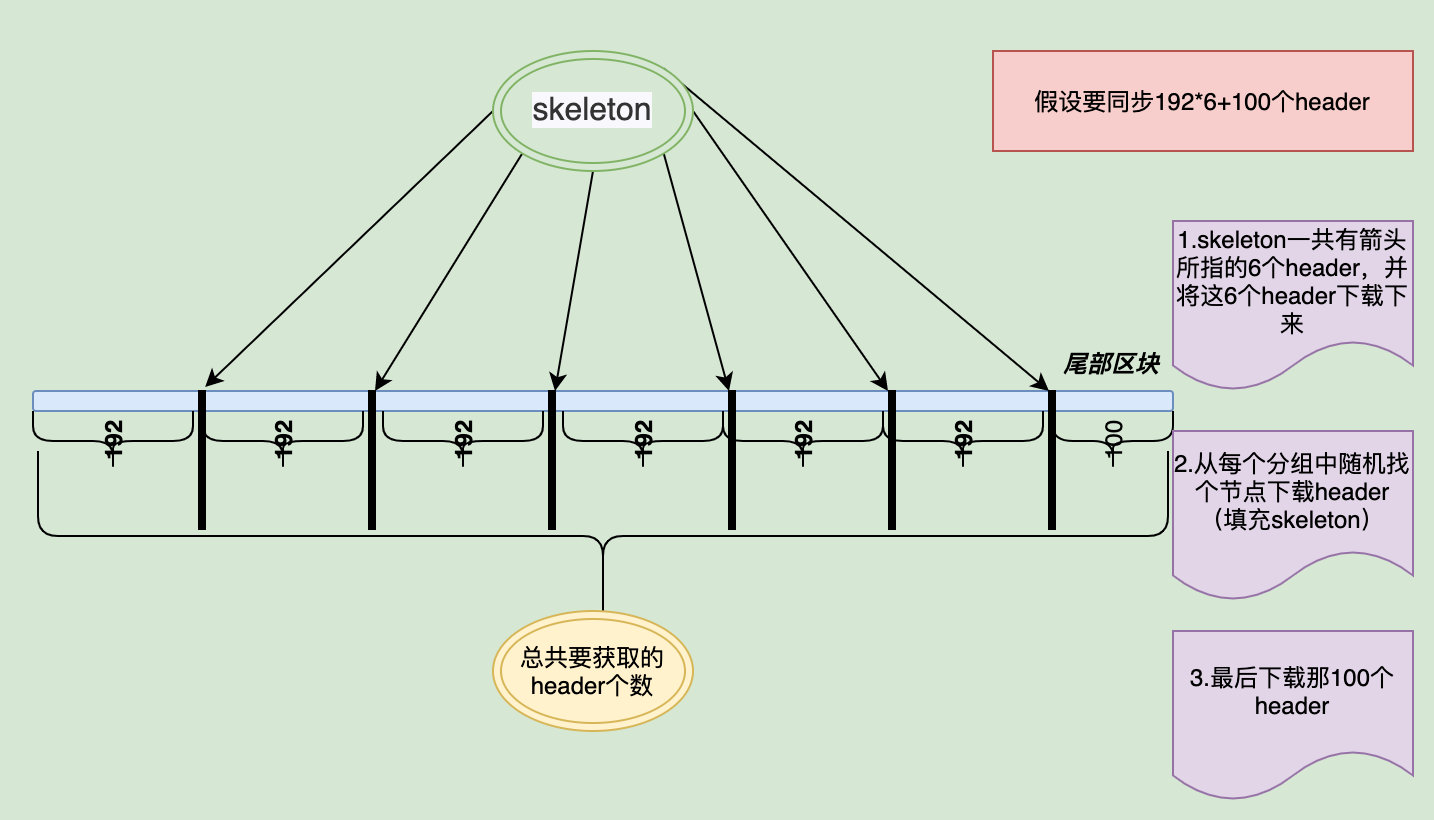
此种方式可以避免从同一节点下载过多错误数据,如果我们连接到了一个恶意节点,它可以创造一个链条很长且TD值也非常高的区块链数据。如果我们的区块从 0 开始全部从它那同步,也就下载了一些根本不被别人承认的数据。如果我只从它那同步 MaxHeaderFetch 个区块,然后发现这些区块无法正确填充我之前的 skeleton(可能是 skeleton 的数据错了,或者用来填充 skeleton 的数据错了),就会丢掉这些数据。
接下来查看下代码如何实现:
①:发起获取header的请求
如果是下载skeleton,则会从高度 from+MaxHeaderFetch-1 开始(包括),每隔 MaxHeaderFetch-1 的高度请求一个 header,最多请求 MaxSkeletonSize 个。如果不是的话,则要获取完整的headers 。
②:等待并处理headerCh中的header数据
2.1 确保远程节点正在返回我们需要填充skeleton所需的header
if packet.PeerId() != p.id {
log.Debug("Received skeleton from incorrect peer", "peer", packet.PeerId())
break
}2.2 如果skeleton已经下载完毕,则需要继续填充skeleton
if packet.Items() == 0 && skeleton {
skeleton = false
getHeaders(from)
continue
}2.3 整个skeleton填充完成,并且没有要获取的header了,要通知headerProcCh全部完成
if packet.Items() == 0 {
//下载pivot时不要中止标头的提取
if atomic.LoadInt32(&d.committed) == 0 && pivot <= from {
p.log.Debug("No headers, waiting for pivot commit")
select {
case <-time.After(fsHeaderContCheck):
getHeaders(from)
continue
case <-d.cancelCh:
return errCanceled
}
}
//完成Pivot操作(或不进行快速同步),并且没有头文件,终止该过程
p.log.Debug("No more headers available")
select {
case d.headerProcCh <- nil:
return nil
case <-d.cancelCh:
return errCanceled
}
}2.4 当header有数据并且是在获取skeleton的时候,调用fillHeaderSkeleton填充skeleton
if skeleton {
filled, proced, err := d.fillHeaderSkeleton(from, headers)
if err != nil {
p.log.Debug("Skeleton chain invalid", "err", err)
return errInvalidChain
}
headers = filled[proced:]
from += uint64(proced)
}2.5 如果当前处理的不是 skeleton,表明区块同步得差不多了,处理尾部的一些区块
判断本地的主链高度与新收到的 header 的最高高度的高度差是否在 reorgProtThreshold 以内,如果不是,就将高度最高的 reorgProtHeaderDelay 个 header 丢掉。
if head+uint64(reorgProtThreshold) < headers[n-1].Number.Uint64() {
delay := reorgProtHeaderDelay
if delay > n {
delay = n
}
headers = headers[:n-delay]
}2.6 如果还有 header 未处理,发给 headerProcCh 进行处理,Downloader.processHeaders 会等待这个 channel 的消息并进行处理;
if len(headers) > 0 {
...
select {
case d.headerProcCh <- headers:
case <-d.cancelCh:
return errCanceled
}
from += uint64(len(headers))
getHeaders(from)
}2.7 如果没有发送标头,或者所有标头等待 fsHeaderContCheck 秒,再次调用 getHeaders 请求区块
p.log.Trace("All headers delayed, waiting")
select {
case <-time.After(fsHeaderContCheck):
getHeaders(from)
continue
case <-d.cancelCh:
return errCanceled
}这段代码后来才加上的,其 commit 的记录在这里,而 「pull request」 在这里。从 「pull request」 中作者的解释我们可以了解这段代码的逻辑和功能:这个修改主要是为了解决经常出现的 「invalid hash chain」 错误,出现这个错误的原因是因为在我们上一次从远程节点获取到一些区块并将它们加入到本地的主链的过程中,远程节点发生了 reorg 操作(参见这篇文章里关于「主链与侧链」的介绍 );当我们再次根据高度请求新的区块时,对方返回给我们的是它的新的主链上的区块,而我们没有这个链上的历史区块,因此在本地写入区块时就会返回 「invalid hash chain」 错误。
要想发生 「reorg」 操作,就需要有新区块加入。在以太坊主网上,新产生一个区块的间隔是 10 秒到 20 秒左右。一般情况下,如果仅仅是区块数据,它的同步速度还是很快的,每次下载也有最大数量的限制。所以在新产生一个区块的这段时间里,足够同步完成一组区块数据而对方节点不会发生 「reorg」 操作。但是注意刚才说的「仅仅是区块数据」的同步较快,state 数据的同步就非常慢了。简单来说在完成同步之前可能会有多个 「pivot」 区块,这些区块的 state 数据会从网络上下载,这就大大拖慢了整个区块的同步速度,使得本地在同步一组区块的同时对方发生 「reorg」 操作的机率大大增加。
作者认为这种情况下发生的 「reorg」 操作是由新产生的区块的竞争引起的,所以最新的几个区块是「不稳定的」,如果本次同步的区块数量较多(也就是我们同步时消耗的时间比较长)(在这里「本次同步的区数数量较多」的表现是新收到的区块的最高高度与本地数据库中的最高高度的差距大于 reorgProtThreshold),那么在同步时可以先避免同步最新区块,这就是 reorgProtThreshold 和 reorgProtHeaderDelay 这个变量的由来。
至此,Downloader.fetchHeaders 方法就结束了,所有的区块头也就同步完成了。在上面我们提到填充skeleton的时候,是由fillHeaderSkeleton函数来完成,接下来就要细讲填充skeleton的细节。
fillHeaderSkeleton
首先我们知道以太坊在同步区块时,先确定要下载的区块的高度区间,然后将这个区间按 MaxHeaderFetch 切分成很多组,每一组的最后一个区块组成了 「skeleton」(最后一组不满 MaxHeaderFetch 个区块不算作一组)。不清楚的可以查看上面的图。
①:将一批header检索任务添加到队列中,以填充skeleton。
这个函数参照上面queue详解的分析
func (q queue) ScheduleSkeleton(from uint64, skeleton []types.Header) {}
②:调用fetchParts 获取headers数据
fetchParts是很核心的函数,下面的Fetchbodies和FetchReceipts都会调用。先来大致看一下fetchParts的结构:
func (d *Downloader) fetchParts(...) error {
...
for {
select {
case <-d.cancelCh:
case packet := <-deliveryCh:
case cont := <-wakeCh:
case <-ticker.C:
case <-update:
...
}
}简化下来就是这 5 个channel在处理,前面 4 个channel负责循环等待消息,update用来等待其他 4 个channel的通知来处理逻辑,先分开分析一个个的channel。
2.1 deliveryCh 传递下载的数据
deliveryCh 作用就是传递下载的数据,当有数据被真正下载下来时,就会给这个 channel 发消息将数据传递过来。这个 channel 对应的分别是:d.headerCh、d.bodyCh、d.receiptCh,而这三个 channel 分别在以下三个方法中被写入数据:DeliverHeaders、DeliverBodies、DeliverReceipts。 看下deliveryCh如何处理数据:
case packet := <-deliveryCh:
if peer := d.peers.Peer(packet.PeerId()); peer != nil {
accepted, err := deliver(packet)//传递接收到的数据块并检查链有效性
if err == errInvalidChain {
return err
}
if err != errStaleDelivery {
setIdle(peer, accepted)
}
switch {
case err == nil && packet.Items() == 0:
...
case err == nil:
...
}
}
select {
case update <- struct{}{}:
default:
}收到下载数据后判断节点是否有效,如果节点没有被移除,则会通过deliver传递接收到的下载数据。如果没有任何错误,则通知update处理。
要注意deliver是一个回调函数,它调用了 queue 对象的 Deliver 方法:queue.DeliverHeaders、queue.DeliverBodies、queue.DeliverReceipts,在收到下载数据就会调用此回调函数(queue相关函数分析参照queue详解部分)。
在上面处理错误部分,有一个setIdle函数,它也是回调函数,其实现都是调用了 peerConnection 对象的相关方法:SetHeadersIdle、SetBodiesIdle、SetReceiptsIdle。它这个函数是指某些节点针对某类数据是空闲的,比如header、bodies、receipts,如果需要下载这几类数据,就可以从空闲的节点下载这些数据。
2.2 wakeCh 唤醒fetchParts ,下载新数据或下载已完成
case cont := <-wakeCh:
if !cont {
finished = true
}
select {
case update <- struct{}{}:
default:
}首先我们通过调用fetchParts传递的参数知道,wakeCh 的值其实是 queue.headerContCh。在 queue.DeliverHeaders 中发现所有需要下戴的 header 都下载完成了时,才会发送 false 给这个 channel。fetchParts 在收到这个消息时,就知道没有 header 需要下载了。代码如下:
func (q *queue) DeliverHeaders(......) (int, error) {
......
if len(q.headerTaskPool) == 0 {
q.headerContCh <- false
}
......
}同样如此,body和receipt则是bodyWakeCh和receiptWakeCh,在 processHeaders 中,如果所有 header 已经下载完成了,那么发送 false 给这两个 channel,通知它们没有新的 header 了。 body 和 receipt 的下载依赖于 header,需要 header 先下载完成才能下载,所以对于下戴 body 或 receipt 的 fetchParts 来说,收到这个 wakeCh 就代表不会再有通知让自己下载数据了.
func (d *Downloader) processHeaders(origin uint64, pivot uint64, td *big.Int) error {
for {
select {
case headers := <-d.headerProcCh:
if len(headers) == 0 {
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select {
case ch <- false:
case <-d.cancelCh:
}
}
...
}
...
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select {
case ch <- true:
default:
}
}
}
}
}2.3 ticker 负责周期性的激活 update进行消息处理
case <-ticker.C:
select {
case update <- struct{}{}:
default:
}
2.4 update (处理此前几个channel的数据)(重要)
2.4.1 判断是否有效节点,并获取超时数据的信息
获取超时数据的节点ID和数据数量,如果大于两个的话,就将这个节点设置为空闲状态(setIdle),小于两个的话直接断开节点连接。
expire 是一个回调函数,会返回当前所有的超时数据信息。这个函数的实际实现都是调用了 queue 对象的 Expire 方法:ExpireHeaders、ExpireBodies、ExpireReceipts,此函数会统计当前正在下载的数据中,起始时间与当前时间的差距超过给定阈值(downloader.requestTTL 方法的返回值)的数据,并将其返回。
if d.peers.Len() == 0 {
return errNoPeers
}
for pid, fails := range expire() {
if peer := d.peers.Peer(pid); peer != nil {
if fails > 2 {
...
setIdle(peer, 0)
} else {
...
if d.dropPeer == nil {
} else {
d.dropPeer(pid)
....
}
}
}2.4.2 处理完超时数据,判断是否还有下载的数据
如果没有其他可下载的内容,请等待或终止,这里pending()和inFlight()都是回调函数,pending分别对应了queue.PendingHeaders、queue.PendingBlocks、queue.PendingReceipts,用来返回各自要下载的任务数量。inFlight()分别对应了queue.InFlightHeaders、queue.InFlightBlocks、queue.InFlightReceipts,用来返回正在下载的数据数量。
if pending() == 0 {
if !inFlight() && finished {
...
return nil
}
break
}2.4.3 使用空闲节点,调用fetch函数发送数据请求
Idle()回调函数在上面已经提过了,throttle()回调函数则分别对queue.ShouldThrottleBlocks、queue.ShouldThrottleReceipts,用来表示是否应该下载bodies或者receipts。
reserve函数分别对应queue.ReserveHeaders、queue.ReserveBodies、queue.ReserveReceipts,用来从从下载任务中选取一些可以下载的任务,并构造一个 fetchRequest 结构。它还返回一个 process 变量,标记着是否有空的数据正在被处理。比如有可能某区块中未包含任何一条交易,因此它的 body 和 receipt 都是空的,这种数据其实是不需要下载的。在 queue 对象的 Reserve 方法中,会对这种情况进行识别。如果遇到空的数据,这些数据会被直接标记为下载成功。在方法返回时,就将是否发生过「直接标记为下载成功」的情况返回。
capacity回调函数分别对应peerConnection.HeaderCapacity、peerConnection.BlockCapacity、peerConnection.ReceiptCapacity,用来决定下载需要请求数据的个数。
fetch回调函数分别对应peer.FetchHeaders、peer.Fetchbodies、peer.FetchReceipts,用来发送获取各类数据的请求。
progressed, throttled, running := false, false, inFlight()
idles, total := idle()
for _, peer := range idles {
if throttle() {
...
}
if pending() == 0 {
break
}
request, progress, err := reserve(peer, capacity(peer))
if err != nil {
return err
}
if progress {
progressed = true
}
if request == nil {
continue
}
if request.From > 0 {
...
}
...
if err := fetch(peer, request); err != nil {
...
}
if !progressed && !throttled && !running && len(idles) == total && pending() > 0 {
return errPeersUnavailable
}简单来概括这段代码就是:使用空闲节点下载数据,判断是否需要暂停,或者数据是否已经下载完成;之后选取数据进行下载;最后,如果没有遇到空块需要下载、且没有暂停下载和所有有效节点都空闲和确实有数据需要下载,但下载没有运行起来,就返回 errPeersUnavailable 错误。
到此为止fetchParts函数就分析的差不多了。里面涉及的跟queue.go相关的一些函数都在queue详解小节里介绍了。
processHeaders
通过headerProcCh接收header数据,并处理的过程是在processHeaders函数中完成的。整个处理过程集中在:case headers := <-d.headerProcCh中:
①:如果headers的长度为0 ,则会有以下操作:
1.1 通知所有人header已经处理完毕
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select {
case ch <- false:
case <-d.cancelCh:
}
}1.2 若没有检索到任何header,说明他们的TD小于我们的,或者已经通过我们的fetcher模块进行了同步。
if d.mode != LightSync {
head := d.blockchain.CurrentBlock()
if !gotHeaders && td.Cmp(d.blockchain.GetTd(head.Hash(), head.NumberU64())) > 0 {
return errStallingPeer
}
}1.3 如果是fast或者light 同步,确保传递了header
if d.mode == FastSync || d.mode == LightSync {
head := d.lightchain.CurrentHeader()
if td.Cmp(d.lightchain.GetTd(head.Hash(), head.Number.Uint64())) > 0 {
return errStallingPeer
}
}②:如果headers的长度大于 0
2.1 如果是fast或者light 同步,调用ightchain.InsertHeaderChain()写入header到leveldb数据库;
if d.mode == FastSync || d.mode == LightSync {
....
d.lightchain.InsertHeaderChain(chunk, frequency);
....
}2.2 如果是fast或者full sync模式,则调用 d.queue.Schedule进行内容(body和receipt)检索。
if d.mode == FullSync || d.mode == FastSync {
...
inserts := d.queue.Schedule(chunk, origin)
...
}③:如果找到更新的块号,则要发信号通知新任务
if d.syncStatsChainHeight < origin {
d.syncStatsChainHeight = origin - 1
}
for _, ch := range []chan bool{d.bodyWakeCh, d.receiptWakeCh} {
select {
case ch <- true:
default:
}
}到此处理Headers的分析就完成了。
同步bodies
同步bodies 则是由fetchBodies函数完成的。
fetchBodies
同步bodies的过程跟同步header类似,大致讲下步骤:
- 调用
fetchParts ReserveBodies()从bodyTaskPool中取出要同步的body;- 调用
fetch,也就是调用这里的FetchBodies从节点获取body,发送GetBlockBodiesMsg消息; - 收到
bodyCh的数据后,调用deliver函数,将Transactions和Uncles写入resultCache。
同步Receipts
fetchReceipts
同步receipts的过程跟同步header类似,大致讲下步骤:
- 调用
fetchParts() ReserveBodies()从ReceiptTaskPool中取出要同步的Receipt- 调用这里的
FetchReceipts从节点获取receipts,发送GetReceiptsMsg消息; - 收到
receiptCh的数据后,调用deliver函数,将Receipts写入resultCache。
同步状态
这里我们讲两种模式下的状态同步:
- fullSync:
processFullSyncContent,full模式下Receipts没有缓存到resultCache中,直接先从缓存中取出body数据,然后执行交易生成状态,最后写入区块链。 - fastSync:
processFastSyncContent:fast模式的Receipts、Transaction、Uncles都在resultCache中,所以还需要下载"state",进行校验,再写入区块链。
接下来大致的讨论下这两种方式。
processFullSyncContent
func (d *Downloader) processFullSyncContent() error {
for {
results := d.queue.Results(true)
...
if err := d.importBlockResults(results); err != nil ...
}
}func (d *Downloader) importBlockResults(results []*fetchResult) error {
...
select {
...
blocks := make([]*types.Block, len(results))
for i, result := range results {
blocks[i] = types.NewBlockWithHeader(result.Header).WithBody(result.Transactions, result.Uncles)
}
if index, err := d.blockchain.InsertChain(blocks); err != nil {
....
}直接从result中获取数据并生成block,直接插入区块链中,就结束了。
processFastSyncContent
fast模式同步状态内容比较多,大致也就如下几部分,我们开始简单分析以下。
①:下载最新的区块状态
sync := d.syncState(latest.Root)我们直接用一张图来表示整个大致流程:
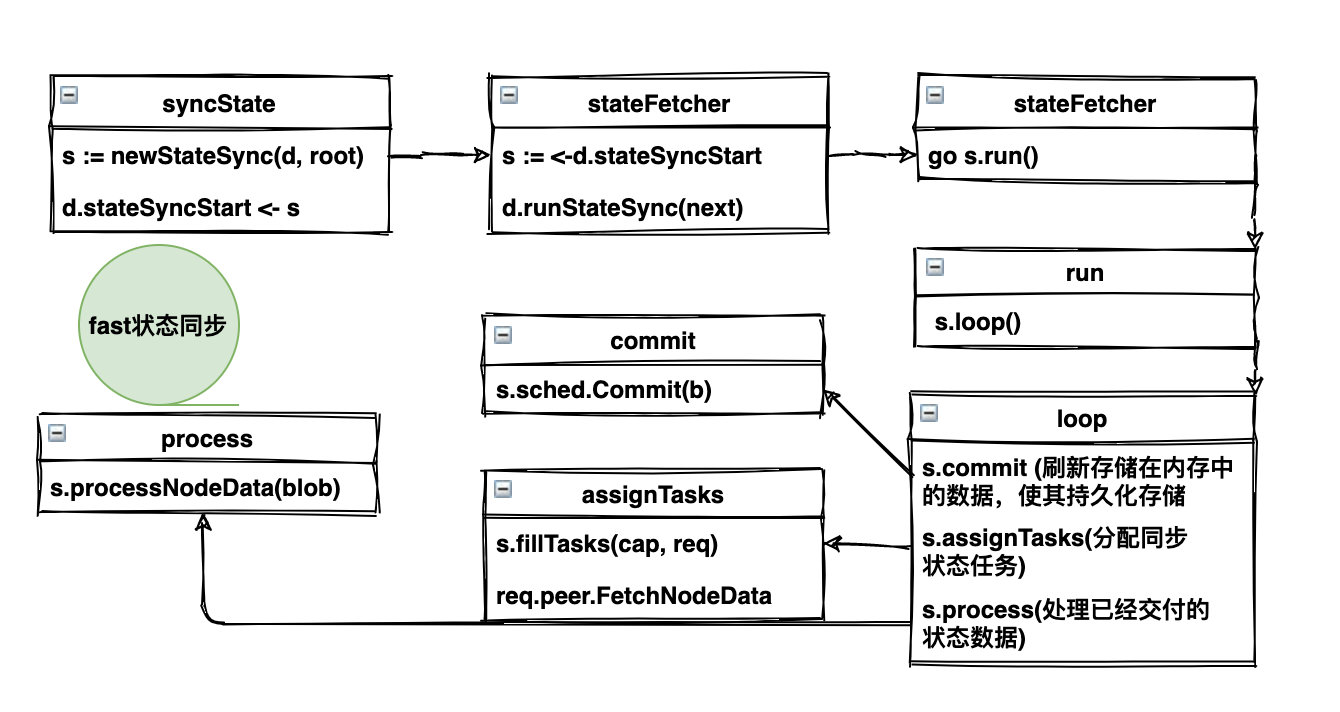
具体的代码读者自己翻阅,大致就是这么个简单过程。
②:计算出pivot块
pivot为latestHeight - 64,调用splitAroundPivot()方法以pivot为中心,将results分为三个部分:beforeP,P,afterP;
pivot := uint64(0)
if height := latest.Number.Uint64(); height > uint64(fsMinFullBlocks) {
pivot = height - uint64(fsMinFullBlocks)
}P, beforeP, afterP := splitAroundPivot(pivot, results)③: 对beforeP的部分调用commitFastSyncData,将body和receipt都写入区块链
d.commitFastSyncData(beforeP, sync); ④:对P的部分更新状态信息为P block的状态,把P对应的result(包含body和receipt)调用commitPivotBlock插入本地区块链中,并调用FastSyncCommitHead记录这个pivot的hash值,存在downloader中,标记为快速同步的最后一个区块hash值;
if err := d.commitPivotBlock(P); err != nil {
return err
}⑤:对afterP调用d.importBlockResults,将body插入区块链,而不插入receipt。因为是最后 64 个区块,所以此时数据库中只有header和body,没有receipt和状态,要通过fullSync模式进行最后的同步。
if err := d.importBlockResults(afterP); err != nil {
return err
}到此为止整个Downloader同步完成了。
参考
公众号:区块链技术栈 (非常推荐关注哦)
https://github.com/ethereum/go-ethereum/pull/1889
https://yangzhe.me/2019/05/09/ethereum-downloader/#fetchparts





