1 个人 + AI:如何日处理 300+ 信息源并自动化运营“青岚新闻”?
- 青岚加密课堂
- 发布于 2026-01-08 11:27
- 阅读 458
在Web3领域,信息就是金钱。但现实是:每天我们要面对300+篇来源各异的新闻、推文和研报。90%的内容是重复的通稿或无意义的噪音。很多朋友订阅了我的青岚BTC新闻或Telegram早报,常问我:每天这么高强度的脱水总结,是怎么做出来的?其实,背后的核心是一套自动化Pi
<!--StartFragment-->
在 Web3 领域,信息就是金钱。但现实是:每天我们要面对 300+ 篇来源各异的新闻、推文和研报。90% 的内容是重复的通稿或无意义的噪音。
很多朋友订阅了我的 青岚BTC新闻 或 Telegram 早报,常问我:每天这么高强度的脱水总结,是怎么做出来的?
其实,背后的核心是一套 自动化 Pipeline。今天我把这套基于 Python + LLM 的工程实践拆解开,分享给社区的朋友们。
一、 为什么不能直接把原始数据喂给 LLM?
初学者常觉得 AI 处理新闻很简单:抓取 -> 丢给 GPT -> 产出总结。 但在生产环境下,这种做法会让你亏掉裤子,且输出极差:
- Token 浪费:网页里的 Header、Footer、广告标签会占用大量上下文,导致有效信息被稀释。
- 信息冗余:同一件事,不同媒体会发 20 遍。不经过向量去重,AI 会翻来覆去说车轱辘话。
- 翻译腔严重:AI 默认喜欢长难句,缺乏专业编辑的干练感。
二、 核心架构设计
我的方案舍弃了复杂的 Agent 框架,采用了极简的 ETL(提取-转化-加载) 思路:
- 精准采集:Playwright 异步抓取 + BeautifulSoup 结构化提取。
- 向量去重:本地
text-embedding-3-small聚类,砍掉 60% 重复数据。 - 精简处理:对标“青岚风格”的提示词工程。
- 自动分发:GitHub Actions 定时触发,推送 Telegram Bot API。
三、 关键代码实现
1. 结构化抓取与清洗
为了让 AI 读到最干净的数据,我们需要对 HTML 进行“剔骨”处理。
<!---->
Python
<!---->
from bs4 import BeautifulSoup
def clean_news_content(html):
soup = BeautifulSoup(html, 'html.parser')
# 剔除噪音标签,防止干扰 AI
for noise in soup(['script', 'style', 'nav', 'footer', 'header']):
noise.decompose()
# 仅提取正文前 800 字,足以覆盖核心事实
return soup.get_text().strip()[:800]<!---->
<!---->
2. 融入“青岚风格”的提示词逻辑
这是实现自动化早报的核心。我们需要强制 AI 按照 青岚新闻 的视觉规范进行输出。
<!---->
Python
<!---->
import openai
def generate_report(news_list):
# 强制 AI 输出 10 条精选
system_prompt = """
你现在是“青岚早报”的高级编辑。
任务:从以下 300 条信息池中筛选出今天最重要的 10 件事。
规范:
1. 格式:数字. [标题] | [核心事实/数据]。
2. 风格:参考 qinglan.org/24news/ 的极简主义,禁止废话。
3. 专有名词:Rollup, MEV, TVL 等行业术语保持原样,禁止乱翻译。
4. 结尾:必须包含一段 100 字左右的 [🤖 青岚简评],分析当天的宏观情绪。
"""
# ... 调用 OpenAI API 逻辑
# 建议使用 gpt-4o-mini,性价比最高且逻辑极稳四、 实战效果验证
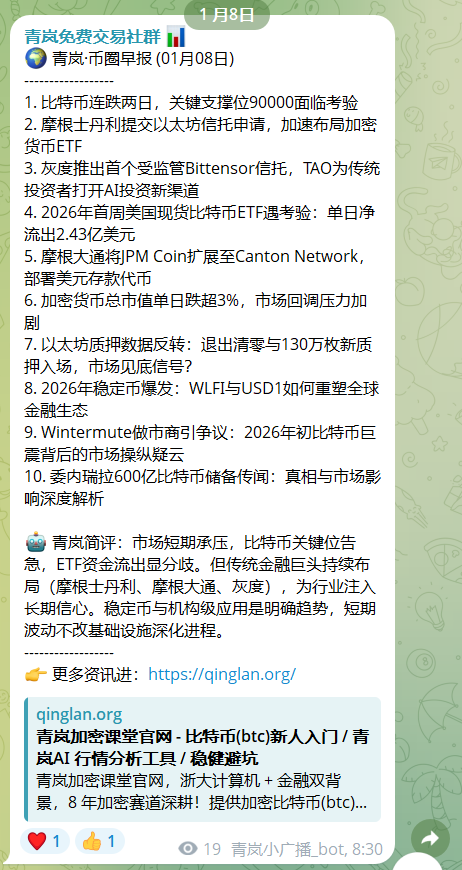
目前这套 Pipeline 已经稳定运行在我的 Telegram 社群中。以下是 2026 年 1 月 8 日的自动化产出截图:
<!--EndFragment-->
 <!--StartFragment-->
<!--StartFragment-->
技术点解析:
- 10 条精选:通过 Embedding 计算权重,优先选出权重最高的信息点。
- 青岚简评:这不是 AI 瞎编,而是基于当天所有 300 条新闻全文本的聚类分析,AI 总结出了机构(摩根、灰度)的布局动向,这种宏观视角是人工筛选很难瞬间完成的。
五、 部署与工程细节
- 零成本运行:整个脚本挂在 GitHub Actions 上,每 2 小时运行一次。生成的静态数据通过 JSON 形式推送到 Vercel 渲染的页面。
- 异常处理:Web3 媒体的 HTML 经常变动,建议增加
Pydantic进行数据校验,防止因为抓取失败导致推送到群里的格式乱码。 - 向量数据库:如果数据量更大(比如日更 1000+),建议在本地起一个
FAISS索引,通过相似度阈值(如 0.85)进行硬过滤。
结语
AI 的真正价值不在于“写文章”,而在于“帮人节省注意力”。
青岚新闻的本质,就是利用 AI 把信息密度做大、把阅读体积做小。目前这套系统在处理长推文聚类时还有优化空间,如果你有更硬核的去重算法或者 Prompt 调优心得,欢迎在评论区留言交流。
<!--EndFragment-->
- 原创
- 学分: 0
- 分类: AI
- 标签:





