使用 Console API 监控 RPC 使用量并设置警报
- QuickNode
- 发布于 2026-02-02 13:18
- 阅读 608
本文介绍了如何使用Quicknode Console API构建一个主动预警系统,该系统可以监控RPC credit的使用情况,并在达到限制之前发送多渠道通知。该系统通过抓取API数据、计算使用趋势和预测何时达到信用额度,从而让你能够及时优化使用情况或升级计划,同时还支持集成Prometheus监控和构建Grafana仪表板。
概述
管理 RPC 使用情况对于维持可预测的成本和避免服务中断至关重要。默认情况下,Quicknode 发送使用情况通知邮件,但许多团队需要更高的灵活性:向 Slack 频道发出警报、与 PagerDuty 等事件管理工具集成、同时向多个团队成员发送通知,或在现有监控仪表板中提供可见性。
本指南向你展示如何构建一个主动警报系统,该系统监控你的 RPC 信用使用情况并在你达到限制之前发送多渠道通知。该系统会计算使用趋势并预测你何时会达到信用额度,从而让你有时间优化使用情况或升级你的套餐。
你将学到什么
- 如何从 Quicknode 控制台 API 获取 RPC 使用数据
- 如何计算使用预测并确定警报严重程度
- 如何配置多渠道警报(Slack、Discord、PagerDuty、Opsgenie、电子邮件、Webhooks)
- 如何使用 cron 或 GitHub Actions 安排自动使用情况检查
- 如何公开指标以进行 Prometheus 监控并构建 Grafana 仪表板
你需要什么
- 任何付费计划的 Quicknode 帐户
- 具有
CONSOLE_REST权限的 Quicknode API 密钥 - 已安装 Node.js v18+
- 访问至少一个警报通道(Slack、Discord、PagerDuty、Opsgenie、SendGrid 或自定义 webhook)
注意: 控制台 API 适用于所有付费帐户。有关详细信息,请查看定价。
为什么需要主动使用情况警报?
基于控制台 API 构建的自定义警报解决方案为你提供强大的功能:
- 多渠道交付:将警报发送到 Slack、Discord、PagerDuty、Opsgenie 或你的团队使用的任何 webhook 端点
- 预测分析:根据当前的消耗趋势,提前几天知道你何时会达到限制
- 团队可见性:同时在正确的渠道上提醒正确的人
- 自定义阈值:设置与你的运营需求相匹配的警告和严重级别
- 基础设施集成:使用 Prometheus 和 Grafana 将使用情况数据连接到你现有的监控堆栈
了解 Usage API
Quicknode 控制台 API 提供了 v0/usage/rpc 端点 来检索你的 RPC 信用使用情况数据。此端点返回有关你正在查询的时间段的信息。
API 请求
curl -X GET "https://api.quicknode.com/v0/usage/rpc?start_time=START_TIMESTAMP&end_time=END_TIMESTAMP" \
-H "x-api-key: YOUR_API_KEY_HERE" \
-H "Content-Type: application/json"参数:
start_time:周期开始的 Unix 时间戳(以秒为单位)(默认为当前结算周期的开始)end_time:周期结束的 Unix 时间戳(以秒为单位)(默认为当前时间)
API 响应
该端点返回一个 JSON 对象,其中包含以下字段:
{
"start_time": 1704067200,
"end_time": 1705363200,
"credits_used": 1000000,
"credits_remaining": 4000000,
"limit": 5000000,
"overages": null
}| 字段 | 描述 |
|---|---|
start_time |
周期开始的 Unix 时间戳 |
end_time |
周期结束的 Unix 时间戳 |
credits_used |
结算周期内消耗的总 RPC 信用 |
credits_remaining |
达到套餐限制之前的可用信用 |
limit |
你的套餐在结算周期内的总信用分配 |
overages |
超出你限制的信用(会产生额外费用) |
借助这些数据,警报系统可以计算你的使用百分比,预测你何时会达到限制,并将警报发送到你配置的渠道。让我们设置项目并探讨每个组件的工作原理。
设置项目
步骤 1:克隆存储库
git clone https://github.com/quiknode-labs/qn-guide-examples.git
cd qn-guide-examples/console-api/usage-alerting步骤 2:安装依赖项
npm install这将安装所需的软件包:
dotenv:从.env文件加载环境变量typescript:TypeScript 编译器ts-node:直接运行 TypeScript 文件
步骤 3:配置环境变量
复制示例环境文件并添加你的配置:
cp .env.example .env打开 .env 并配置你的设置:
## Quicknode API 密钥(必需)
## 从以下位置获取你的 API 密钥:https://dashboard.quicknode.com/api-keys
## 所需权限:CONSOLE_REST
QUICKNODE_API_KEY=your_api_key_here
## 警报阈值(限制的百分比)
## 当使用量 >= 阈值时触发警报
ALERT_THRESHOLD_WARNING=80
ALERT_THRESHOLD_CRITICAL=95
## 警报通道(配置你要使用的通道)
## 有关每个通道的设置说明,请参见下面的部分
SLACK_WEBHOOK_URL=
PAGERDUTY_ROUTING_KEY=
DISCORD_WEBHOOK_URL=
OPSGENIE_API_KEY=
SENDGRID_API_KEY=
SENDGRID_FROM_EMAIL=
ALERT_EMAIL_RECIPIENTS=
GENERIC_WEBHOOK_URL=至少,你需要设置 QUICKNODE_API_KEY 并配置至少一个警报通道。为了进行测试,你可以对 GENERIC_WEBHOOK_URL 使用 Webhook.site 或 TypedWebhook 等在线 webhook 测试器。
了解代码
警报系统由三个主要组件组成:获取使用情况数据、计算预测和发送警报。每个组件都作为代码库中的一个单独函数实现,从而使其易于理解和修改。你可以在项目的 src/index.ts 文件中找到这些函数。
获取使用情况数据
fetchUsage 函数从控制台 API 检索你当前结算周期的使用情况数据。它接受可选的 startTime 和 endTime 参数来查询特定时间范围,并返回使用情况响应,包括已用信用、剩余信用和你的套餐限制。如果未提供时间参数,则默认为你当前的结算周期。
计算预测
calculatePrediction 函数分析你当前的使用率并预测你是否会超出限制。它从 API 获取使用情况响应并计算几个有用的指标:
- 每日平均:基于已用时间,你每天的平均信用消耗量
- 预计每月:如果当前速率持续,则结算周期的估计总使用量
- 达到限制前的天数:按照当前速率,你还有多少天达到限制
- 预计超额:超出你限制的估计信用额度
该函数使用基于你的平均每日消耗量的简单线性预测,对于大多数具有相对一致的使用模式的用例来说,效果良好。
确定警报严重程度
determineAlertLevel 函数使用可配置的阈值来确定何时发出警报以及以什么严重程度发出警报。它同时考虑你当前的使用百分比和上面计算的预测:
| 条件 | 严重程度 |
|---|---|
| 已经产生超额费用 | 严重 |
| 使用量 >= 严重阈值(默认 95%) | 严重 |
| 预计在 3 天或更短时间内达到限制 | 严重 |
| 使用量 >= 警告阈值(默认 80%) | 警告 |
| 预计本月将超出限制 | 警告 |
配置警报通道
该项目包括六个预构建的警报通道。根据你的团队的需求配置一个或多个。这些集成作为示例,你可以轻松地扩展代码库以添加其他渠道,如 Microsoft Teams、Datadog 或接受 webhook 有效负载的任何其他服务。
- Slack
- PagerDuty
- Discord
- Opsgenie
- 电子邮件 (SendGrid)
- 通用 Webhook
Slack
Slack 集成使用传入的 webhook 将格式化的消息发布到频道。
设置:
- 转到 Slack API:传入 Webhook
- 为你的工作区和频道创建一个新的 webhook
- 将 webhook URL 复制到你的
.env文件:
SLACK_WEBHOOK_URL=https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX警报格式:
Slack 警报包括颜色编码的附件,其中包含以结构化布局显示的使用情况统计信息和预测。
PagerDuty
PagerDuty 集成使用 Events API v2 触发事件。
设置:
- 在 PagerDuty 中,转到服务并创建或选择一个服务
- 添加集成并选择“Events API v2”
- 将路由密钥复制到你的
.env文件:
PAGERDUTY_ROUTING_KEY=your_routing_key_here警报行为:
- 严重警报会触发 P1 事件
- 警告警报会触发 P3 事件
- 警报使用重复数据删除密钥来防止重复事件
Discord
Discord 集成将嵌入的消息发布到频道。
设置:
- 在你的 Discord 服务器中,转到服务器设置 > 集成 > Webhooks
- 创建一个新的 webhook 并选择目标频道
- 将 webhook URL 复制到你的
.env文件:
DISCORD_WEBHOOK_URL=https://discord.com/api/webhooks/000000000000000000/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxOpsgenie
Opsgenie 集成创建具有适当优先级级别的警报。
设置:
- 在 Opsgenie 中,转到设置 > API 密钥管理
- 创建一个新的 API 密钥,并具有“创建和更新”权限
- 将 API 密钥复制到你的
.env文件:
OPSGENIE_API_KEY=your_api_key_here警报行为:
- 严重警报会创建 P1 优先级警报
- 警告警报会创建 P3 优先级警报
- 警报标记有
quicknode、usage和严重级别
电子邮件 (SendGrid)
电子邮件集成通过 SendGrid 发送 HTML 格式的警报。
设置:
- 创建一个 SendGrid 帐户
- 转到设置 > API 密钥并创建一个具有“邮件发送”权限的密钥
- 验证发件人电子邮件地址
- 配置你的
.env文件:
SENDGRID_API_KEY=SG.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
SENDGRID_FROM_EMAIL=alerts@yourdomain.com
ALERT_EMAIL_RECIPIENTS=team@yourdomain.com,oncall@yourdomain.com多个收件人以逗号分隔。
通用 Webhook
对于自定义集成,通用 webhook 将 JSON 有效负载发送到任何 HTTP 端点。
设置:
GENERIC_WEBHOOK_URL=https://your-service.com/webhook/quicknode-alerts有效负载格式:
{
"timestamp": "2024-01-15T12:00:00.000Z",
"source": "quicknode-usage-monitor",
"severity": "warning",
"title": "Quicknode RPC Usage Warning",
"message": "Your Quicknode RPC usage has reached 82.5% of your limit...",
"data": {
"usage_percent": 82.5,
"credits_used": 4125000,
"credits_remaining": 875000,
"limit": 5000000,
"overages": 0
},
"prediction": {
"daily_average": 275000,
"projected_monthly": 8250000,
"projected_percent": 165.0,
"days_until_limit": 3,
"projected_overages": 3250000
}
}运行脚本
检查模式
在检查模式下运行以查看你的使用情况和预测,而不发送警报:
npm run check示例输出:
在检查模式下运行(不会发送警报)
正在获取 Quicknode RPC 使用情况...
=== Quicknode RPC 使用情况报告 ===
周期:2024 年 1 月 1 日 - 2024 年 1 月 15 日
周期天数:已用 15 天,剩余 16 天
----------------------------------
已用信用:4,125,000
剩余信用:875,000
限制:5,000,000
当前使用量:82.5%
----------------------------------
预测
每日平均:275,000 信用/天
预计每月:8,525,000 信用 (170.5%)
达到限制前的天数:约 3 天
预计超额:3,525,000 信用
==================================
阈值:警告=80%,严重=95%
将触发:警告警报此示例显示了一种情况,你已使用 82.5% 的信用,已过去 15 天。按照当前速率,预计你将在大约 3 天内超出限制。
警报模式
在警报模式下运行以检查使用情况,如果超过阈值则发送警报:
npm run dev或者用于生产环境:
npm run build
npm start发送警报时的示例输出:
正在获取 Quicknode RPC 使用情况...
=== Quicknode RPC 使用情况报告 ===
周期:2024 年 1 月 1 日 - 2024 年 1 月 15 日
周期天数:已用 15 天,剩余 16 天
----------------------------------
已用信用:4,125,000
剩余信用:875,000
限制:5,000,000
当前使用量:82.5%
----------------------------------
预测
每日平均:275,000 信用/天
预计每月:8,525,000 信用 (170.5%)
达到限制前的天数:约 3 天
预计超额:3,525,000 信用
==================================
警报级别:警告
正在向 2 个渠道发送警报...
[确定] slack
[确定] pagerduty安排警报
由于控制台 API 是一种 REST 服务,因此警报是在你查询它时生成的,而不是自动推送的。这使得安排对于主动监控至关重要。如果没有定期检查,你将不会收到警报,直到你手动运行脚本。
安排脚本以与你的使用模式和响应需求相匹配的间隔运行。更频繁的检查(每隔几个小时)可以及早发现使用高峰,而不太频繁的检查(每天)对于可预测的工作负载可能就足够了。
使用 Cron (Linux/macOS)
添加一个 cron 作业以每 6 小时运行一次检查:
crontab -e添加以下行(调整你安装的路径):
0 */6 * * * cd /path/to/usage-alerting && npm start >> /var/log/quicknode-alerts.log 2>&1使用 GitHub Actions
在 .github/workflows/usage-alerts.yml 创建一个工作流程文件:
name: Quicknode Usage Alerts
on:
schedule:
# Run every 6 hours
- cron: '0 */6 * * *'
workflow_dispatch: # Allow manual triggers
jobs:
check-usage:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install dependencies
working-directory: console-api/usage-alerting
run: npm install
- name: Run usage check
working-directory: console-api/usage-alerting
env:
QUICKNODE_API_KEY: ${{ secrets.QUICKNODE_API_KEY }}
ALERT_THRESHOLD_WARNING: '80'
ALERT_THRESHOLD_CRITICAL: '95'
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
run: npm run dev设置密钥:
- 转到你的存储库的设置 > 密钥和变量 > Actions
- 添加以下密钥:
QUICKNODE_API_KEY:你的 Quicknode API 密钥SLACK_WEBHOOK_URL:你的 Slack webhook URL(或其他渠道密钥)
替代方案:Prometheus AlertManager
如果你的团队已经使用 Prometheus,你可以完全跳过基于 cron 的安排。相反,使用本项目中包含的 Prometheus 导出器,并配置 AlertManager 以根据指标阈值处理通知。这种方法将警报逻辑集中在你现有的监控基础设施中。
高级:Prometheus 集成
对于使用 Prometheus 和 Grafana 进行监控的团队,本项目包含一个自定义 Prometheus 导出器,用于公开 Quicknode 使用情况指标。此导出器将 v0/usage/rpc API 数据转换为 Prometheus 格式,允许你:
- 构建 Grafana 仪表板,显示使用限制和剩余信用
- 通过 AlertManager 设置 Prometheus 警报规则
- 将 Quicknode 使用情况指标与其他供应商指标合并到单个 Prometheus 实例中
注意: Quicknode 还为企业客户提供 Prometheus Exporter,该导出器公开了其他指标,如 RPC 请求、端点响应状态和延迟。请按照该指南了解 Prometheus 的基础知识并构建全面的 Grafana 仪表板。本项目中的导出器专门关注所有付费计划可用的账单和使用情况指标。
导出器如何工作
该导出器遵循标准的 Prometheus 模式。它运行一个简单的 HTTP 服务器,该服务器按需响应抓取请求:
-
被动操作:导出器运行一个 HTTP 服务器并等待请求。它不会按照自己的计划获取数据或运行后台作业。
-
Prometheus 控制计时:Prometheus 被配置为以你指定的间隔(例如,每五分钟)抓取
/metrics端点。 -
按需获取:当 Prometheus 访问
/metrics端点时,导出器会调用 Quicknode API,将响应格式化为 Prometheus 指标,然后返回它。 -
无状态设计:导出器不会在请求之间缓存或存储数据。每次抓取都会从 API 返回新数据。
这意味着你可以通过 Prometheus 配置完全控制抓取频率。根据你需要更新指标的频率调整 scrape_interval。
启动导出器
npm run exporter这会在端口 9091 上启动一个指标服务器(可以通过 EXPORTER_PORT 配置):
Quicknode Prometheus Exporter 正在 http://localhost:9091 上运行
指标端点:http://localhost:9091/metrics
运行状况端点:http://localhost:9091/health可用指标
| 指标 | 类型 | 描述 |
|---|---|---|
quicknode_credits_used |
gauge | 当前结算周期内使用的总 RPC 信用 |
quicknode_credits_remaining |
gauge | 当前结算周期内剩余的 RPC 信用 |
quicknode_credits_limit |
gauge | 结算周期的总 RPC 信用限制 |
quicknode_usage_percent |
gauge | 已使用的 RPC 信用限制的百分比 |
quicknode_overages |
gauge | 超出限制使用的 RPC 信用 |
quicknode_exporter_scrape_success |
gauge | 上次抓取是否成功 |
Prometheus 配置
在你的 prometheus.yml 中将导出器添加为抓取目标:
scrape_configs:
- job_name: 'quicknode-usage'
scrape_interval: 5m
static_configs:
- targets: ['localhost:9091']如果你在 Docker 中运行 Prometheus 并在你的主机上运行导出器,请更新目标以使用 host.docker.internal:9091,并将以下 extra_hosts 添加到你的 Docker Compose 文件:
services:
prometheus:
image: prom/prometheus:latest
extra_hosts:
- "host.docker.internal:host-gateway"构建仪表板
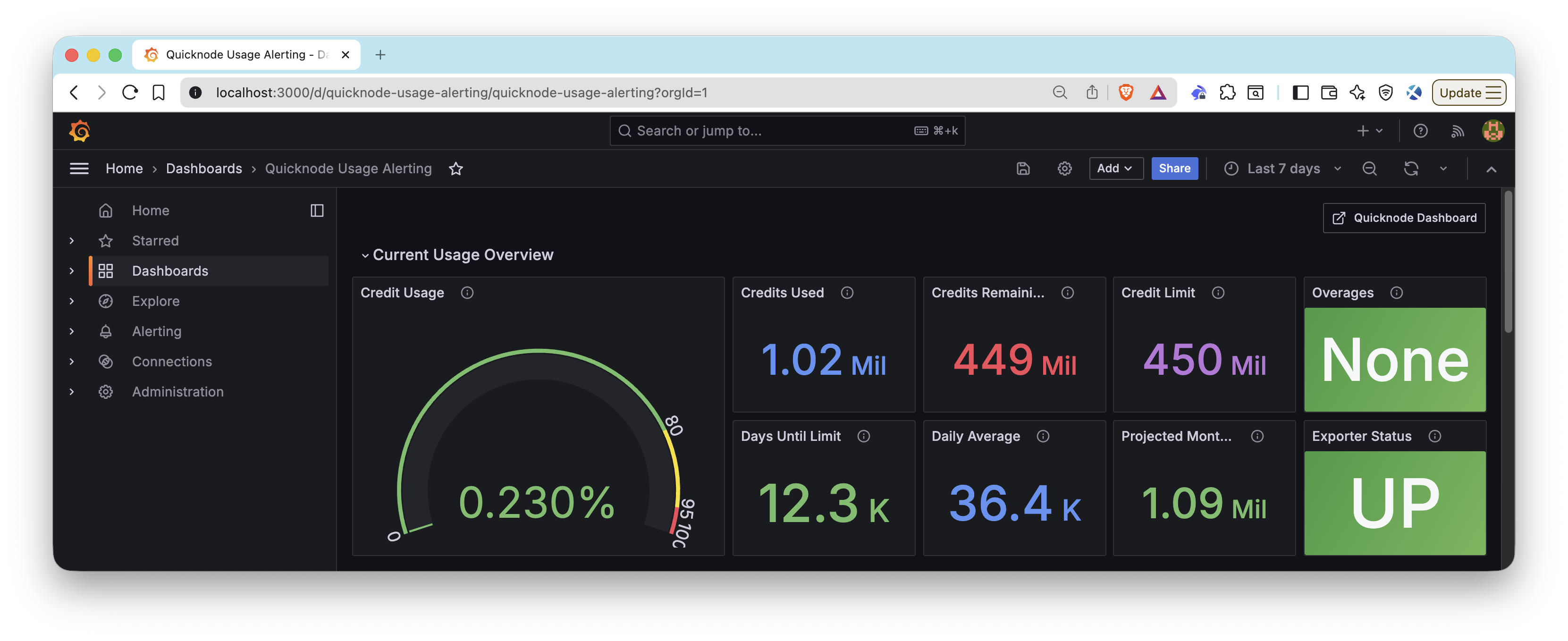
有关使用 Quicknode 指标构建 Grafana 仪表板的完整指南,请参阅我们的指南:如何构建 Grafana 仪表板来监控你的 RPC 基础设施。
该配套存储库包括预构建的仪表板配置:
- 使用情况警报仪表板:在
console-api/usage-alerting/dashboards/quicknode-usage-alerting-grafana.json中找到 Grafana 仪表板 JSON。将此直接导入到你的 Grafana 实例中,或将其放置在你的预配文件夹中。 - 完整监控堆栈:
console-api/grafana-dashboard目录包括一个 Docker Compose 设置,用于完整的 Prometheus 和 Grafana 监控堆栈。
结论
你现在已经为你的 Quicknode RPC 使用情况设置了一个主动警报系统。借助此系统,你可以:
- 监控整个组织的使用情况
- 在你的团队实际使用的渠道上接收警报
- 预测你何时会达到限制,并在它发生之前
- 避免意外的超额费用
多渠道警报和使用情况预测的结合使你能够获得有效管理 RPC 基础设施所需的可见性。
下一步
既然你已经设置了使用情况警报,请考虑以下增强功能:
- 构建全面的仪表板:请按照我们的 Grafana 仪表板指南 可视化一段时间内的使用趋势
- 以编程方式管理基础设施:使用 控制台 API 自动执行端点管理以及使用情况监控
- 查看你的套餐限制:如果你经常接近你的限制,请查看 Quicknode 定价 以了解你的选择
- 探索完整的控制台 API:查看 控制台 API 文档 以获取其他端点和功能
常见问题解答
如何以编程方式检查我当前的 Quicknode RPC 信用使用情况?
使用 Console API,对 https://api.quicknode.com/v0/usage/rpc 发出 GET 请求,包括你的 API 密钥,以检索当前结算周期的 credits_used、credits_remaining 和 limit。
Console API 在 Quicknode 中用于什么?
Console API 允许以编程方式管理 Quicknode 中的所有操作,包括创建、更新和删除端点、设置速率限制以及获取详细的使用情况数据,如按端点、方法或区块链划分的信用额度。
如何将 Quicknode 使用情况指标与 Prometheus 和 Grafana 集成?
该项目包括一个自定义 Prometheus 导出器,用于在 /metrics 端点上公开 Quicknode 使用情况指标。使用 npm run exporter 运行导出器,配置 Prometheus 来抓取它,并导入提供的 Grafana 仪表板 JSON 以可视化已用信用、剩余信用、使用百分比和超额费用。
此使用情况监控系统支持哪些警报通道?
该系统支持六个预构建的通道:Slack、Discord、PagerDuty、Opsgenie、电子邮件(通过 SendGrid)和通用 webhook。你可以配置一个或多个通道,并扩展代码库以添加其他集成。
我可以按端点或方法细分 RPC 信用使用情况吗?
可以,使用对 /v0/usage/rpc/by-endpoint 或类似端点的 GET 请求,以查看跨端点、方法或区块链的信用消耗的详细细分。
如果你有疑问或遇到问题,请在我们的 Discord 中联系。通过在 Twitter (@Quicknode) 或我们的 Telegram 公告频道 上关注我们,了解最新信息。
我们 ❤️ 反馈!
如果你有任何反馈或对新主题的请求,请告诉我们。我们很乐意听取你的意见。
- 原文链接: quicknode.com/guides/qui...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 17
- 分类: 通识
- 标签: QuickNode RPC Console API 监控 Prometheus grafana 预警





