在Polymarket上交易所需的数学知识(完整指南)- 第二部分
- Eyad
- 发布于 2026-02-05 20:35
- 阅读 998
本文是Polymarket交易数学基础的第二部分,深入探讨了在Polymarket等预测市场上进行交易所需的关键数学知识和实际应用。文章详细讲解了如何初始化算法、防止崩溃、计算精确的利润保证以及市场定价的原理,为读者提供了一套将理论转化为实际盈利的完整框架,并概述了构建可扩展至七位数的生产系统的关键步骤和资源。
在 Polymarket 上交易所需的数学知识(完整路线图)- 第 2 部分
我将分解在 Polymarket 上交易所需的基本数学知识。我还将分享亲自帮助我的确切路线图和资源。让我们直奔主题 第 1 部分的浏览量超过 220 万。这种回应清楚地表明了一件事:如果你想像顶级套利机器人一样赚到真正的钱,那么从系统层面理解像 Polymarket 这样的预测市场至关重要。仅靠理论无法让你成功。执行才能。
收藏此内容 - 我是 Roan,一名后端开发人员,从事系统设计、HFT 风格的执行和量化交易系统。我的工作重点是预测市场在负载下的实际表现。如有任何建议、周到的合作、合作,欢迎私信。
在继续之前:如果你还没有阅读第 1 部分,请在此处停止并首先阅读它。第 1 部分涵盖了边缘多面体、Bregman 投影和 Frank-Wolfe 优化。本文直接建立在这些基础之上。当你理解 Frank-Wolfe 通过迭代优化解决 Bregman 投影时,你会想“我可以实现这一点”。你是对的。大多数人永远不会意识到的是,当他们陷入第 1 次迭代,试图找出有效的起始顶点时,生产系统已经使用算法 3(本文中将解释)进行了初始化,使用自适应收缩防止了梯度爆炸,在达到最大利润的 90% 时停止,并执行了交易。当你手动开始第一次迭代时,这些系统已经跨多个市场捕获了套利机会,根据订单簿深度调整了头寸规模,并转向了下一个机会。区别不仅仅是数学知识。这是实现精度。在本文结束时,你将确切地知道如何构建提取了超过 4000 万美元的相同系统。第 1 部分为你提供了关于整数规划、边缘多面体、Bregman 投影的理论。第 2 部分为你提供了关于如何从头开始实际启动算法、防止导致业余尝试失败的崩溃、在执行之前计算精确的利润保证以及为什么像 Polymarket 这样的平台故意留下这些机会的实现方法。数学是公开的。4000 万美元就放在那里。交易员提取它和其他人之间的唯一区别是首先解决了四个关键的实现问题。这是将方程式转化为数百万美元的确切剧本。注意:这不是粗略浏览。如果你真的想构建可以扩展到七位数的系统,请从头到尾阅读它。如果你在这里是为了快速获胜或随性编码,那么这不适合你。
第 I 部分:初始化问题(设置市场状态)
你不能只用随机数启动 Frank-Wolfe,并希望它能工作。该算法需要一个有效的起点,该起点是你已知的来自边缘多面体 $M$ 的一组可行顶点。这就是初始化问题,它比听起来更难。为什么初始化很重要 -
回想一下第 1 部分,Frank-Wolfe 算法维护了一个已发现顶点的活动集 $Z_t$。在每次迭代中,它解决 $Z_t$ 的凸包上的凸优化,然后通过解决整数程序来找到新的下降顶点。但是第 1 次迭代存在问题:$Z_0$ 是什么?你需要至少一个有效的收益向量才能开始。理想情况下,你需要多个顶点来跨越结果空间的不同区域。至关重要的是,你需要一个内部点 $u$ - 一个连贯的价格向量,其中每个未结算证券的价格严格在 0 到 1 之间。为什么?因为我们使用的 Barrier Frank-Wolfe 变体(本文第 II 部分介绍)将多面体向该内部点收缩,以控制梯度增长。如果你的内部点的任何坐标恰好位于 0 或 1,则收缩将失败并且算法将中断。算法 3:InitFW 解释

算法 3:InitFW
InitFW 的目标有三个:
-
找到初始活动顶点集 $Z_0$
-
构建一个有效的内部点 $u$
-
扩展部分结果 $\sigma$ 以包括任何可以逻辑结算的证券
这是它的工作原理。你从部分结果 $\sigma$(已结算为 0 或 1 的证券集)开始,并迭代每个未结算证券 $i$。
对于每个证券 $i$,你向整数规划求解器提出两个问题:
-
问题 1:“给我一个有效的收益向量 $z$,其中 $z_i = 1$”
-
问题 2:“给我一个有效的收益向量 $z$,其中 $z_i = 0$”
IP 求解器要么找到这样的向量,要么证明不存在。
情况 1:求解器找到 $z_i = 0$ 和 $z_i = 1$ 的有效向量。这意味着证券 $i$ 确实不确定 - 它可以以任何一种方式解决。将这两个向量添加到 $Z_0$。证券 $i$ 仍未结算。
情况 2:求解器找到 $z_i = 1$ 的向量,但找不到 $z_i = 0$ 的向量。这意味着每个有效结果都有 $z_i = 1$。证券 $i$ 必须解析为 1。将其作为 $(i, 1)$ 添加到扩展的部分结果 $\hat{\sigma}$。
情况 3:求解器找到 $z_i = 0$ 的向量,但找不到 $z_i = 1$ 的向量。每个有效结果都有 $z_i = 0$。证券 $i$ 必须解析为 0。将其作为 $(i, 0)$ 添加到 $\hat{\sigma}$。
在迭代所有未结算证券后,你将拥有:
-
扩展的部分结果 $\hat{\sigma}$,其中结算的证券多于开始时的证券
-
一组顶点 $Z_0$,其中每个未结算证券在不同向量中都显示为 0 和 1
内部点 $u$ 只是 $Z_0$ 中所有顶点的平均值:
$u = (1/|Z0|) \times \Sigma{z \in Z_0} z$
因为每个未结算证券在 $Z_0$ 中都显示为 0 和 1,所以平均值保证所有未结算 $i$ 的 $u_i$ 严格介于 0 和 1 之间。
真实示例:NCAA 锦标赛初始化
考虑第 1 部分中杜克大学对阵康奈尔大学的市场。每支球队都有 7 个证券(0 到 6 场胜利)。最初,没有进行任何比赛,因此 $\sigma = \emptyset$。
InitFW 迭代所有 14 个证券:
-
对于“杜克大学:0 场胜利”,求解器找到同时包含 0 和 1 的有效向量(杜克大学可能赢得 0 场比赛,也可能不赢得比赛)
-
对于“杜克大学:6 场胜利”,求解器找到同时包含 0 和 1 的有效向量(杜克大学可能赢得冠军,也可能不赢得冠军)
-
康奈尔大学的所有证券也是如此
但有一个约束:杜克大学和康奈尔大学不能都进入决赛(各自赢得 5 场以上比赛),因为他们会在半决赛中相遇。当 InitFW 要求一个向量,其中杜克大学:5 场胜利 = 1 且康奈尔大学:5 场胜利 = 1 时,IP 求解器返回不可行。
这不会结算任何证券(两支球队都可以赢得 5 场比赛,只是不能同时)。但它会使用尊重依赖关系的向量填充 $Z_0$。该算法现在在任何迭代开始之前都知道结果空间的结构。
初始化后:
-
$Z_0$ 包含所有可能的锦标赛结果的有效收益向量
-
$u$ 是一个价格向量,其中所有坐标都介于 0 和 1 之间(对于每支球队的 0-6 场胜利概率,类似于 0.14)
-
$\hat{\sigma} = \sigma = \emptyset$(尚未结算任何比赛)
一旦比赛开始结算,后续对 InitFW 的调用会扩展 $\hat{\sigma}$。如果杜克大学在第一轮失利,则下一次 InitFW 调用会检测到所有有效向量都具有“杜克大学:1 场以上胜利”= 0,并将这些证券添加到 $\hat{\sigma}$。已结算证券的价格永久锁定在 0 或 1。
为什么此步骤至关重要?
如果没有适当的初始化,Frank-Wolfe 可能会在三个方面失败:
失败 1:空 $Z_0$ 如果你没有找到任何有效的顶点,你将无法优化。算法无法启动。
失败 2:边界内部点 如果你的内部点 $u$ 的任何坐标位于 0 或 1,则 Barrier Frank-Wolfe 中的收缩未定义。梯度爆炸。算法发散。
失败 3:错过结算 如果你不扩展 $\hat{\sigma}$ 以包括逻辑结算的证券,那么你将浪费计算资源来优化应该固定的价格。更糟糕的是,你会错过套利消除机会,因为根据定义,已结算证券没有套利。
Kroer 等人的实验表明,即使在全尺寸(63 场比赛,2^63 个结果)下,InitFW 也能在 1 秒内完成 NCAA 锦标赛。IP 求解器可以有效地处理这些查询,因为它只是检查可行性,而不是优化任何东西。
主要收获:如果没有有效的初始化,你将无法运行 Frank-Wolfe。算法 3 同时解决了三个问题:它构造了一个有效的起始活动集 $Z_0$,构建了一个内部点 $u$,其中所有未结算坐标严格介于 0 和 1 之间,并扩展了部分结果 $\sigma$ 以包括可以逻辑结算的证券。IP 求解器正在进行可行性检查,而不是优化,因此即使对于巨大的结果空间,此步骤也很快。InitFW 允许 Frank-Wolfe 开始运行,并且随着结果的解析,它使算法能够随着时间的推移而加速。错过此步骤,你的投影要么永远不会开始,要么立即发散。现在让我们谈谈为什么内部点如此重要。
第 II 部分:自适应收缩和受控增长(为什么 FW 不会中断)
标准 Frank-Wolfe 假设目标函数的梯度是 Lipschitz 连续的,具有有界常数 $L$。此假设支持收敛证明:该算法保证以 $O(L \times diam(M) / t)$ 的速率减小间隙 $g(\mu_t)$。但是 LMSR(对数市场评分规则)以灾难性的方式违反了此假设。
梯度爆炸问题 -
回想一下第 1 部分,对于 LMSR,Bregman 散度是 KL 散度:
$D(\mu||\theta) = \Sigma_i \mu_i \ln(\mu_i / p_i(\theta))$
为了通过 Frank-Wolfe 最小化此值,我们需要关于 $\mu$ 的梯度 $\nabla D$。求导:
$\nabla R(\mu) = \ln(\mu) + 1$
仅当 $\mu > 0$ 时才定义此梯度。当任何坐标 $\mu_i$ 接近 0 时,梯度分量 $(\nabla R)_i = \ln(\mu_i) + 1$ 变为负无穷大。
这是一个问题。边缘多面体 $M$ 具有一些坐标恰好为 0 的顶点。解析为 False 的证券在相应的收益向量中具有 $\mu_i = 0$。当 Frank-Wolfe 迭代接近这些边界顶点时,梯度会爆炸。
标准 FW 收敛分析需要有界 Lipschitz 常数。在这里,$L$ 是无界的。算法可能会发散、振荡或卡住。
Kroer 等人的解决方案:使用自适应收缩的 Barrier Frank-Wolfe。
受控增长条件 我们不是要求全局有界 Lipschitz 常数,而是仅在 $M$ 的收缩子集上局部要求它。
定义收缩多面体:
$M' = (1 - \varepsilon)M + \varepsilon u$
其中 $\varepsilon \in (0,1)$ 是收缩参数,$u$ 是来自 InitFW 的内部点。
在几何上,$M'$ 是向点 $u$ 收缩的多面体 $M$。$M$ 的每个顶点 $v$ 都被拉向 $u$:
$v' = (1 - \varepsilon)v + \varepsilon u$
因为 $u$ 的所有坐标都严格介于 0 和 1 之间(通过 InitFW 中的构造),并且 $\varepsilon > 0$,所以 $v'$ 的每个坐标都严格介于 0 和 1 之间。收缩的多面体 $M'$ 远离边界。
现在梯度 $\nabla R(\mu)$ 在 $M'$ 上是有界的。具体来说,$M'$ 上的 Lipschitz 常数是:
$L_\varepsilon = O(1/\varepsilon)$
$\varepsilon$ 越小(越接近真实多面体 $M$),$L\varepsilon$ 越大。但至关重要的是,对于任何固定 $\varepsilon > 0$,$L\varepsilon$ 都是有限的。
这给了我们一个权衡:
-
大 $\varepsilon$:快速收敛(小 $L_\varepsilon$),但我们正在优化错误的多面体(远离 $M$)
-
小 $\varepsilon$:慢速收敛(大 $L_\varepsilon$),但我们正在优化接近 $M$ 的东西
自适应收缩方案通过从大 $\varepsilon$ 开始并随着时间的推移减小它来解决此问题。
自适应 Epsilon 规则 Kroer 论文中的算法 2 实现了这一点。在每次迭代 $t$ 时,该算法维护 $\varepsilon_t$ 并根据以下公式更新它:
如果 $g(\mu_t) / (-4gu) < \varepsilon{t-1}$:$\varepsilon_t = \min{g(\mu_t) / (-4gu), \varepsilon{t-1} / 2}$ 否则:$\varepsilont = \varepsilon{t-1}$
这是什么意思?$g(\mu_t)$ 是迭代 $t$ 处的 Frank-Wolfe 间隙($\mu_t$ 的次优程度)。$g_u$ 是在内部点 $u$ 处评估的间隙。
比率 $g(\mu_t) / (-4g_u)$ 衡量我们相对于内部点与真实最优值的接近程度。如果此比率很小(我们正在取得良好进展),则我们将 $\varepsilon$ 缩小一半。如果比率很大(我们仍然远离最优值),则我们保持 $\varepsilon$ 不变。
关键见解:$\varepsilon$ 基于收敛自适应地减小,而不是基于固定的计划。
随着迭代的进行:
-
早期迭代:$\varepsilon$ 很大(可能是 0.1)。我们优化严重收缩的多面体 $M'$。收敛速度很快。
-
中期迭代:$\varepsilon$ 缩小到 0.05、0.025 等。我们越来越接近真实多面体 $M$。收敛速度减慢。
-
后期迭代:$\varepsilon$ 接近 0。我们正在优化几乎真实的 $M$。收敛速度很慢,但精度很高。
Krishnan 等人 2015 年的分析证明 $\varepsilon_t \rightarrow 0$,因为 $t \rightarrow \infty$,因此该算法收敛到 $M$ 上的真实 Bregman 投影,而不仅仅是收敛到某些收缩的近似值。
为什么这有效:Hessian 界限
受控增长条件适用于 LMSR,因为 $R(\mu)$ 的 Hessian 在 $M'$ 上表现良好。
Hessian 是一个对角矩阵,其条目为:
$H_{ii} = \partial^2 R / \partial \mu_i^2 = 1/\mu_i$
在收缩的多面体 $M'$ 上,每个坐标 $\mu_i \geq \varepsilon$(因为向 $u$ 收缩)。因此:
$H_{ii} \leq 1/\varepsilon$
Hessian 的算子范数(它限制了梯度的 Lipschitz 常数)是:
$||H|| = \max_i (1/\mu_i) \leq 1/\varepsilon$
这给了我们 $L_\varepsilon = O(1/\varepsilon)$,正如所声称的那样。
对于其他成本函数(如 LMSR 的总和),同样的分析也适用。只要成本函数的共轭 $R$ 的 Hessian 在收缩的多面体上以最多 $O(1/\varepsilon)$ 的速度增长,Barrier Frank-Wolfe 就会收敛。
具有自适应收缩的收敛速度
Barrier FW 的收敛速度为:
$O(L_\varepsilon \times diam(M') / t) = O(1/(\varepsilon \times t))$
随着 $\varepsilon$ 的缩小,收敛速度减慢。但是自适应规则确保我们仅在足够接近最优值时才缩小 $\varepsilon$,此时精度比速度更重要。
在实践中(来自 Kroer 实验):
-
前 10 次迭代:$\varepsilon$ = 0.1,朝着粗略解决方案快速取得进展
-
迭代 10-50:$\varepsilon$ 缩小到 0.01,优化解决方案
-
迭代 50-150:$\varepsilon$ 接近 0.001,收敛到高精度
总迭代次数:对于具有数千个证券的 NCAA 锦标赛市场,迭代次数为 50 到 150 次。总时间:30 分钟,一旦结果空间缩小到足以让 IP 求解快速完成。
没有自适应收缩会发生什么?如果你仅在 $M$ 上运行标准 Frank-Wolfe(没有收缩),则可能会发生两种情况:
情景 1:该算法遇到某个 $i$ 的顶点,其中 $\mu_i = 0$。梯度分量变为 -∞。数值溢出。算法崩溃。
情景 2:该算法稍微停留在 $M$ 内部(数值舍入使 $\mu_i > 0$,但非常小)。梯度变得巨大。步长不稳定。收敛不稳定或不存在。
该研究论文明确指出:“如果没有自适应收缩,FW 不会针对 LMSR 收敛。”
具有自适应收缩的 Barrier FW 不是一种优化。这是一种必要条件。
主要收获:标准 Frank-Wolfe 在 LMSR 上失败,因为梯度在价格边界爆炸,其中 $\mui$ 接近零。Barrier Frank-Wolfe 通过优化收缩的多面体 $M' = (1-\varepsilon)M + \varepsilon u$ 来解决此问题,其中所有坐标都与零保持一定距离,从而给出有限的 Lipschitz 常数 $L\varepsilon = O(1/\varepsilon)$。自适应 epsilon 规则从较大的 $\varepsilon$ 开始以实现快速的早期收敛,并随着时间的推移缩小 $\varepsilon$,以接近 $M$ 上的真实投影。这种机制保持了梯度的受控增长,同时保证了渐近收敛到正确的解决方案。如果没有这种机制,该算法要么因数值溢出而崩溃,要么因不稳定的梯度而发散。现在你知道如何保持算法的稳定了。但是你何时真正停止并执行?
第 III 部分:利润保证(何时停止和交易)
你正在运行 Frank-Wolfe。第 50 次迭代。间隙 $g(\mu_t)$ 正在减小。IP 求解器仍在运行。
你什么时候停止?
停止过早 → 错过大部分利润 停止过晚 → 市场变动,机会消失
你需要保证利润的停止条件。
命题 4.1:公式

从市场状态 $\theta$ 移动到 $\hat{\theta}$(其中 $p(\hat{\theta}) = \hat{\mu}$)的保证利润是:
利润 $\geq D(\hat{\mu}||\theta) - g(\hat{\mu})$
其中:
-
$D(\hat{\mu}||\theta)$ = Bregman 散度(如果 $\hat{\mu}$ 完美,则为最大套利)
-
$g(\hat{\mu})$ = Frank-Wolfe 间隙($\hat{\mu}$ 当前的次优程度)
这就是一切。
$D(\hat{\mu}||\theta)$ 是你通过完美优化获得的利润。$g(\hat{\mu})$ 是你因 $\hat{\mu}$ 尚未完美而损失的利润。即使使用近似解决方案,差额也是保证的利润。
为什么这很重要
在传统的优化中,当 $g(\hat{\mu})$ 很小时,你就会停止。你不在乎 $D(\hat{\mu}||\theta)$。
在套利中,你同时关心两者:
情况 1:$D(\hat{\mu}||\theta) = 0.15$,$g(\hat{\mu}) = 0.20$ 保证利润 = 0.15 - 0.20 = -0.05 不要交易。你的近似值太差。
情况 2:$D(\hat{\mu}||\theta) = 0.15$,$g(\hat{\mu}) = 0.02$ 保证利润 = 0.15 - 0.02 = 0.13 立即交易。你正在捕获 87% 的可用套利。
情况 3:$D(\hat{\mu}||\theta) = 0.0001$,$g(\hat{\mu}) = 0.00001$ 保证利润 = 0.00009 技术上为正,但执行成本超过利润。跳过。
三个停止条件
条件 1:$\alpha$-提取
$g(\mu_t) \leq (1-\alpha) \times D(\mu_t||\theta)$
重新排列为:
$D(\mu_t||\theta) - g(\mu_t) \geq \alpha \times D(\mu_t||\theta)$
解释:保证的利润至少是最大可能利润的 $\alpha$ 分数。
研究实现:$\alpha = 0.9$
“当你保证捕获至少 90% 的可用套利时,停止。”
为什么是 90% 而不是 100%?获得最后的 10% 可能需要再进行 50 次迭代。IP 求解器可能会超时。市场可能会变动。现在就拿走 90%。
条件 2:接近无套利
$D(\mu_t||\theta) \leq \varepsilon_D$
如果可用的最大套利低于阈值 $\varepsilon_D$,则不要打扰。
研究值:$\varepsilon_D = 0.05$
“如果利润低于每美元 5 美分,则跳过它。”
为什么?执行风险和 Gas 费会消耗掉它。
条件 3:强制中断
新交易到达或达到时间限制 → 返回到目前为止找到的最佳迭代。
跟踪所有迭代:
$t^* = \text{argmax}{\tau \leq t} [D(\mu\tau||\theta) - g(\mu_\tau)]$
即使在第 5 次迭代时中断,你也会在这些迭代中返回具有最大保证利润的迭代。
至关重要的是:$D(\mu_t||\theta) - g(\mu_t) \geq 0$ 始终(通过凸对偶性证明)。
你永远不会返回具有负保证利润的交易。
证明概要
保证的利润是:
$\min{\omega} [\text{结果 } \omega \text{ 中的利润}] = \min{\mu \in M} [(\hat{\theta}-\theta) \cdot \mu - C(\hat{\theta}) + C(\theta)]$
使用共轭($\hat{\theta} = \nabla R(\hat{\mu})$)并简化:
$= D(\hat{\mu}||\theta) + \min_{\mu \in M} [(\hat{\theta}-\theta) \cdot (\mu-\hat{\mu})]$
根据 FW 间隙的定义,项 $\min_{\mu \in M} [(\hat{\theta}-\theta) \cdot (\mu-\hat{\mu})]$ 等于 $-g(\hat{\mu})$。
因此:
保证利润 = $D(\hat{\mu}||\theta) - g(\hat{\mu})$
证毕。
来自 NCAA 实验的真实数字
早期锦标赛(结算了 16 场比赛):迭代 10:D = 0.0045,g = 0.0042,保证利润 = 0.0003 迭代 50:D = 0.0045,g = 0.0004,保证利润 = 0.0041
$\alpha$-提取检查:$g(\mu_{50}) = 0.0004 \leq 0.9 \times 0.0045 = 0.00405$ ✓
停止。保证利润:最大利润的 91%。
后期锦标赛(结算了 56 场比赛):
迭代 20:D = 0.0002,g = 0.00001,保证利润 = 0.00019
$\alpha$-提取检查:$g(\mu_{20}) = 0.00001 \leq 0.9 \times 0.0002 = 0.00018$ ✓
停止。保证利润:最大利润的 95%。
后期锦标赛收敛速度更快,因为结果空间更小(128 种可能性与数十亿种可能性)。
何时不交易
如果出现以下情况,则中止:
-
$D(\mu_t||\theta) < \varepsilon_D$ → 无套利,无利润
-
$D(\mu_t||\theta) - g(\mu_t) < 0$ → 间隙超过散度,继续迭代
-
$D(\mu_t||\theta) - g(\mu_t) < \text{执行阈值}$ → 利润太小,无法承担风险
研究中的 0.05 最小值阈值考虑了:
-
非原子执行(一条腿可能充满,另一条腿可能不充满)
-
Gas 费(在 Polygon 上,每笔多腿交易约 0.02 美元)
-
滑点和订单簿变动
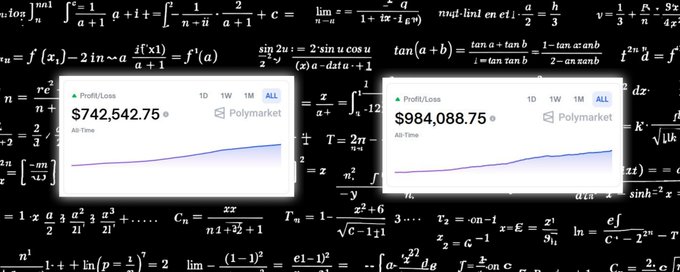
主要收获:命题 4.1 将抽象优化转化为具体的交易决策。利润保证 $D(\hat{\mu}||\theta) - g(\hat{\mu})$ 准确地告诉你何时停止 Frank-Wolfe。$\alpha$-提取停止条件($\alpha = 0.9$)确保你捕获 90% 的利润,而无需等待完美收敛。跨迭代跟踪最佳迭代 $t^*$ 意味着即使强制中断也会返回有利可图的交易。这就是顶级套利交易者通过 4,049 笔交易赚取 2,009,631.76 美元的方式。每笔交易在执行之前都有保证的最低利润。没有赌博。没有希望。在停止容差范围内数学上的确定性。
现在你知道:如何初始化(第 I 部分)、如何防止崩溃(第 II 部分)、何时停止和交易(第 III 部分)。
但是还有最后一块。做市商实际上是如何首先设置这些价格的?
第 IV 部分:做市商的视角(为什么价格是错误的)
到目前为止,一切都集中在利用定价错误上。但是定价错误来自哪里?了解做市商的优化问题可以揭示为什么套利会存在。
成本函数框架
Polymarket(像所有自动做市商一样)使用成本函数 $C(\theta)$ 来设置价格。
从第 1 部分开始,LMSR:
$C(\theta) = b \times \log(\Sigma e^{\theta_i/b})$ 价格:$p_i(\theta) = e^{\theta_i/b} / \Sigma_j e^{\theta_j/b}$
参数 $b$ 控制流动性。
小 $b$ → 价格随每次交易快速变动 大 $b$ → 价格变动缓慢
做市商的问题
做市商想要:
-
吸引交易者(提供流动性)
-
保持无套利(不要因套利者而亏钱)
-
限制最大损失(最坏情况下的支出是有限的)
这些目标相互冲突。
如果你通过 Bregman 投影(第 I-III 部分)强制执行无套利价格,则会牺牲流动性。
为什么?因为投影可以解决整数程序。这需要 30 秒到 30 分钟,具体取决于市场规模。
如果每次更新都需要解决 IP,则价格无法实时更新。
权衡:速度与准确性
快速定价(Polymarket 实际执行的操作):
当交易到达时:
-
更新状态:$\theta{new} = \theta{old} + \delta$
-
计算新价格:$p(\theta{new}) = \nabla C(\theta{new})$
-
立即执行
时间:<100 毫秒
但是价格可能会违反逻辑约束。如果杜克大学在第一轮失利,“杜克大学赢得冠军”应立即归零。相反,随着交易者押注反对它,它会逐渐衰减。
准确的定价(来自第 I-III 部分的 FWMM):
当交易到达时:
-
运行 InitFW 以扩展部分结果
-
运行 Barrier FW 以投影到 $M$ 上
-
将状态更新为投影价格
-
执行交易
时间:30 秒到 30 分钟
保证价格无套利。但是它们更新缓慢。在投影完成时,已经有 10 多个交易到达。你总是落后。
Polymarket 选择速度而不是准确性。他们使用具有快速更新的独立 LMSR 市场。这会产生三种类型的定价错误:
类型 1:市场内不一致
对于多条件市场,概率之和 $\neq 1$。
来自经验数据的示例:
-
662 个 NegRisk 市场(占所有多条件市场的 42%)的总和 $\neq 1$
-
中位数偏差:每美元 0.08
类型 2:跨市场不一致
相关市场的定价好像是独立的。
例如:“特朗普赢得宾夕法尼亚州”和“共和党在全国范围内以 5 个以上的优势获胜”应该相关。但是每个市场都根据自己的交易独立更新。
结果:价格违反了逻辑依赖性。存在组合套利。
类型 3:结算滞后
当比赛结算时,价格不会立即锁定。随着交易者押注反对已解决的结果,它们会漂移到 0 或 1。
论文中的示例:阿萨德继续担任叙利亚总统到 2024 年。
-
阿萨德逃离该国(结果已确定)
-
价格:是 = 0.30 美元,否 = 0.30 美元(总和 = 0.60 美元)
-
应该是:是 = 0 美元,否 = 1 美元
-
套利窗口持续数小时,直到足够的交易者将其压低
基本不可能定理(隐含在 Kroer 等人中):
对于具有依赖关系的组合市场上的任何成本函数:
-
快速价格更新 → 存在套利
-
无套利价格 → 缓慢更新
你不能两者兼得。
具有独立子市场的 LMSR 速度很快,但会产生套利。具有整数规划的 FWMM 是无套利的,但速度很慢。
Polymarket 可以做什么(但没有做)
混合方法:
-
对正常交易使用快速 LMSR
-
每 10 秒运行一次 LCMM(来自 Dud´ık 等人 2012 年的线性约束 MM)以部分消除套利
-
每 5 分钟或在部分结果更新时运行完整的 FWMM 投影
这将使套利从每年 4000 万美元减少到约每年 500 万美元。
为什么 Polymarket 不这样做?因为套利会吸引成熟的交易者。 做市商想要交易量。套利者提供持续的交易量。如果你移除所有套利,许多专业交易者会离开。
Polymarket 容忍一些套利,作为流动性激励。
做市商的损失上限
即使有套利,做市商的损失也是有限的。
来自 Abernethy et al. 2011:
最坏情况下的损失 = $\max_{\omega} [D(\varphi(\omega)||\theta_0)]$
其中:
-
$\varphi(\omega)$ 是结果 $\omega$ 中的收益向量
-
$\theta_0$ 是初始市场状态
对于 LMSR,这简化为:
最大损失 = $b \times \log(|\Omega|)$
其中 $|\Omega|$ 是结果的数量。
示例:NCAA 锦标赛
$|\Omega| = 2^{63}$ $b = 150$ (典型的流动性参数)
最大损失 = $150 \times \log(2^{63}) = 150 \times 43.7 = $6,555
无论发生多少交易,存在多少套利,做市商在这个市场上最多损失 $6,555。
这就是 LMSR 被使用的原因。即使在对抗性情景中,损失也是有限的。
这对套利者意味着什么 做市商选择被利用。
他们可以运行 FWMM 并消除套利。他们不这样做,因为:
-
速度比准确性更重要
-
套利者提供流动性
-
无论如何,损失是有限的
对于你作为套利者:
这些机会不是错误。它们是特性。做市商知道价格是错误的。他们接受有限的损失,以换取快速更新和高交易量。
你的工作是以比竞争对手更快的速度提取利润。
现在你有了这些工具:
-
InitFW 启动优化 (第一部分)
-
Barrier FW 处理 LMSR (第二部分)
-
利润保证,以便知道何时交易 (第三部分)
-
理解为什么会存在定价错误 (第四部分)
关键要点:做市商面临一个不可能的权衡:快速更新会产生套利,无套利定价是缓慢的。Polymarket 选择了速度,使用独立的 LMSR 子市场,这些子市场以 <100ms 的速度更新。这产生了市场内的不一致 (总和 $\neq 1$),市场间的不一致 (忽略了依赖关系),以及结算延迟 (价格向真实值漂移)。提取的 $40M 套利不是失败,而是维持流动性和交易量的可接受成本。无论是否存在套利,做市商的损失都受到 $b\times\log(|\Omega|)$ 的限制,因此容忍一些剥削是合理的。对于套利者来说,这意味着机会是系统性的,而不是偶然的。
你检测和执行的速度越快,你提取的就越多。
结论:完整的框架
Part 1 向你展示了数学原理:整数规划、边际多胞形、Bregman 投影、Frank-Wolfe 迭代。
Part 2 向你展示了实现:如何实际启动算法,为什么标准方法会失败,何时停止并保证利润,以及为什么这些机会会存在。
理论和执行之间的差距是四个问题:
-
初始化 (第一部分): 使用带有 IP 求解器的 InitFW 构建有效的 $Z_0$,构建内部点 $u$,扩展部分结果 $\hat{\sigma}$
-
稳定性 (第二部分): 使用带有自适应收缩的 Barrier FW,以防止 LMSR 导致的梯度爆炸
-
执行 (第三部分): 使用利润保证 $D(\hat{\mu}||\theta) - g(\hat{\mu})$ 与 $\alpha$-extraction 结合,在市场变动之前捕获 90% 的套利
-
市场结构 (第四部分): 理解做市商选择速度而不是准确性,从而产生系统性的定价错误
这不是理论上的。最顶尖的套利者使用完全相同的方法赚取了 $2,009,631.76。

按总金额和成功机会数量排名的前 10 个账户
他们没有更好的信息。他们没有内幕消息。他们对每个人都可以在研究论文中读到的相同数学原理进行了更好的实现。问题不再是“这是否可能?”
问题是:你会实现它吗?
接下来是什么?
这是第二部分。我们介绍了初始化、稳定性、利润保证和做市商经济学。
但是我们还没有讨论生产系统。
你实际上如何:
-
从 Polymarket 的 WebSocket API 摄取实时数据?
-
并行运行整数程序而不阻塞?
-
以 <30ms 的延迟将订单提交到 CLOB?
-
同时监控 17,000 多个条件?
-
在资本约束下确定头寸规模?
-
当一条腿执行而另一条腿不执行时,如何处理部分成交?
我应该发布第三部分吗?
第三部分将包括:
-
系统架构(数据管道、执行引擎、监控)
-
代码示例(Python + Gurobi 实现)
-
风险管理(头寸规模、凯利判据、回撤限制)
-
基础设施(AWS 设置、数据库模式、WebSocket 处理)
完整的生产系统,可以扩展到七位数
如果你想要第三部分,请告诉我。现在是关于构建将为你印钞的机器。
资源
研究论文:
-
Kroer et al. 2016: "通过整数规划进行无套利组合做市" (arXiv:1606.02825v2)
-
Saguillo et al. 2025: "解开概率森林:预测市场中的套利" (arXiv:2508.03474v1)
工具:
- Gurobi Optimizer: gurobi.com
- Polymarket CLOB API: docs.polymarket.com 数学是有效的。机会是存在的。唯一的问题是执行。
- 原文链接: x.com/i/status/201913142...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 110
- 分类: DeFi
- 标签: PolyMarket 预测市场 套利 Frank-Wolfe算法 Bregman投影 整数规划





