用 Rust 从零写一个分布式 ID 生成服务
- King
- 发布于 2026-03-05 08:28
- 阅读 353
做后端开发的同学应该都遇到过这个问题:分库分表之后,数据库自增ID就没法用了。每个库都从1开始自增,合并数据的时候ID就会冲突。这时候就需要一个分布式ID生成服务。今天我们就用Rust从零开始写一个,支持三种主流算法:Snowflake、ULID、NanoID。先聊聊几种
做后端开发的同学应该都遇到过这个问题:分库分表之后,数据库自增 ID 就没法用了。每个库都从 1 开始自增,合并数据的时候 ID 就会冲突。
这时候就需要一个分布式 ID 生成服务。今天我们就用 Rust 从零开始写一个,支持三种主流算法:Snowflake、ULID、NanoID。
先聊聊几种常见方案
UUID 很方便,但问题是太长了(36 个字符),而且无序。数据库索引会很痛苦,因为每次插入都要重新排序。
数据库号段模式 性能不错,但强依赖数据库。数据库挂了,整个服务就不可用了。
Snowflake 是 Twitter 开源的方案,生成的是 64 位整数。性能高,而且按时间有序。缺点是依赖机器时钟,时钟回拨会出问题。
ULID 是这几年比较火的方案,26 个字符,字典序可排序。比起 UUID,它有序且更短。
NanoID 更简单,就是一个随机字符串。短小精悍,URL 安全,适合做短链接之类的场景。
我们今天就实现这三个算法。
项目结构怎么设计
先想清楚整体架构。核心思路是分三层:
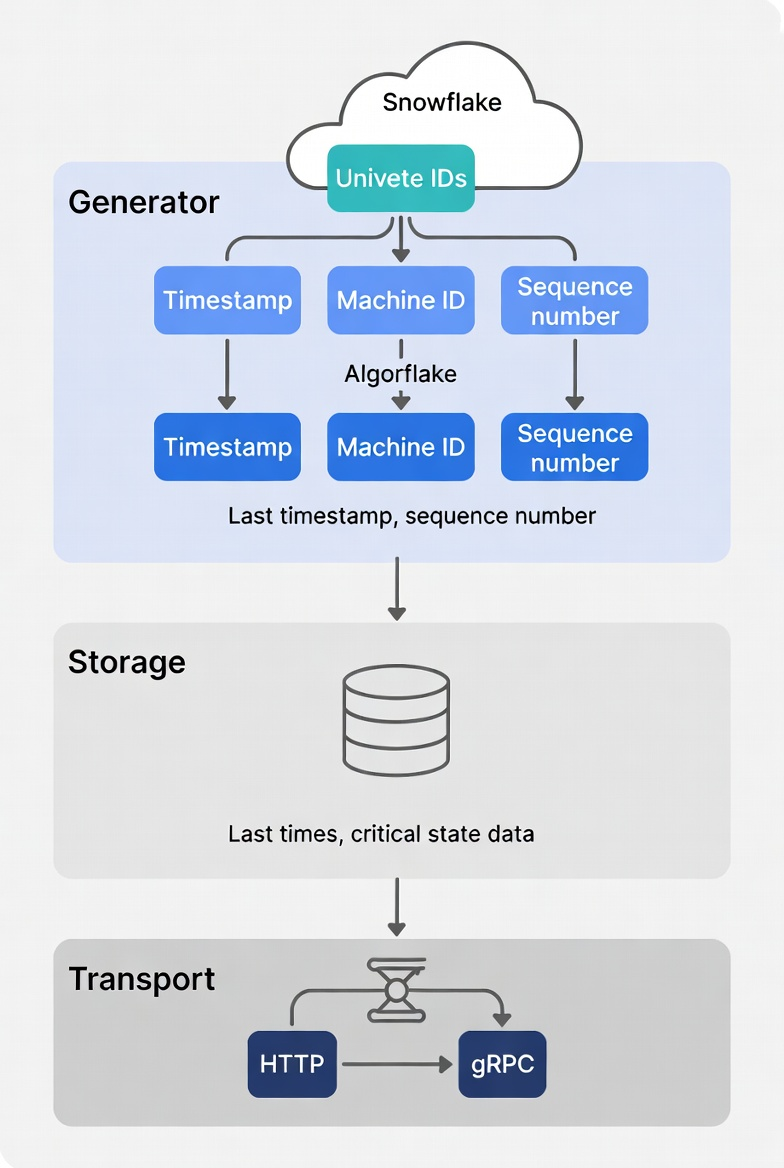
Generator 负责生成 ID,Storage 负责持久化状态(Snowflake 需要记住上次的时间戳和序列号),Transport 负责对外提供服务(HTTP 和 gRPC)。
这样做的好处是每一层都可以替换。想换存储?写个 RedisStorage 实现 Storage trait 就行。想换 HTTP 框架?改 Transport 层就好,生成器代码不用动。
项目目录结构:
src/
├── lib.rs # 库入口,导出公共接口
├── bin/
│ └── globuid.rs # CLI 入口
├── generator/
│ ├── mod.rs # IdGenerator trait
│ ├── snowflake.rs # Snowflake 实现
│ ├── ulid.rs # ULID 实现
│ └── nanoid.rs # NanoID 实现
├── storage/
│ ├── mod.rs # Storage trait
│ ├── memory.rs # 内存存储
│ └── file.rs # 文件存储
├── http/
│ └── server.rs # HTTP 服务
└── grpc/
└── server.rs # gRPC 服务定义核心接口
先定义统一的 ID 生成接口。不同算法生成的 ID 格式不一样,Snowflake 是数字,ULID 和 NanoID 是字符串。我们用一个枚举来统一:
pub enum Id {
Numeric64(u64),
String(String),
}
impl Id {
pub fn as_string(&self) -> String {
match self {
Id::Numeric64(n) => n.to_string(),
Id::String(s) => s.clone(),
}
}
}然后是生成器的 Trait:
pub trait IdGenerator: Send + Sync {
type Error: std::error::Error + Send + Sync + 'static;
fn generate(&self)
-> Pin<Box<dyn Future<Output = Result<Id, Self::Error>> + Send + '_>>;
fn generate_batch(&self, count: usize)
-> Pin<Box<dyn Future<Output = Result<Vec<Id>, Self::Error>> + Send + '_>> {
// 默认实现:循环调用 generate
Box::pin(async move {
let mut ids = Vec::with_capacity(count);
for _ in 0..count {
ids.push(self.generate().await?);
}
Ok(ids)
})
}
}这里用到了 Rust 的异步 trait 模式。因为 Rust 不直接支持 async trait,所以返回 Pin<Box<dyn Future>>。虽然写起来有点繁琐,但性能和原生 async 差不多。
存储层的 Trait 比较简单:
#[derive(Default, Serialize, Deserialize)]
pub struct GeneratorState {
pub worker_id: u16,
pub last_timestamp: u64,
pub last_sequence: u64,
}
pub trait Storage: Send + Sync {
fn load(&self) -> Pin<Box<dyn Future<Output = Result<GeneratorState, Box<dyn Error>>> + Send + '_>>;
fn save(&self, state: GeneratorState) -> Pin<Box<dyn Future<Output = Result<(), Box<dyn Error>>> + Send + '_>>;
}Snowflake 实现
Snowflake 的核心是一个 64 位的整数,结构如下:
| 1 bit 符号位 | 41 bits 时间戳 | 10 bits 机器 ID | 12 bits 序列号 |时间戳占 41 位,毫秒级,大概能用 69 年。机器 ID 占 10 位,支持 1024 台机器。序列号占 12 位,同一毫秒内最多生成 4096 个 ID。
核心逻辑:
pub async fn generate_u64(&self) -> Result<u64, SnowflakeError> {
let mut state = self.state.lock().await;
let current_timestamp = self.current_timestamp()?;
let (timestamp, sequence) = if current_timestamp < state.last_timestamp {
// 时钟回拨了,这很危险
return Err(SnowflakeError::ClockMovedBackwards);
} else if current_timestamp == state.last_timestamp {
// 同一毫秒,序列号加 1
let sequence = state.last_sequence + 1;
if sequence > 4095 {
// 这一毫秒的 ID 用完了,等下一毫秒
(self.wait_for_next_millis(state.last_timestamp).await, 0)
} else {
(current_timestamp, sequence)
}
} else {
// 新的一毫秒,序列号从 0 开始
(current_timestamp, 0)
};
// 拼装 ID
let id = ((timestamp - self.config.epoch) << 22)
| (self.config.worker_id as u64) << 12
| sequence;
// 保存状态
state.last_timestamp = timestamp;
state.last_sequence = sequence;
self.storage.save(...).await?;
Ok(id)
}有几个坑要注意:
时钟回拨:服务器时钟如果往回跳,可能会生成重复 ID。处理方式是直接报错,或者等待时钟追上。生产环境建议配合 NTP 使用,或者用 ZooKeeper 做时钟同步。
序列号耗尽:同一毫秒内生成超过 4096 个 ID,就得等下一毫秒。这个场景虽然少见,但高并发时可能发生。
状态持久化:每次生成 ID 都要保存状态,这样才能在重启后继续,不会重复。
ULID 实现
ULID 的结构:
| 48 bits 时间戳 | 80 bits 随机数 |时间戳是毫秒级,能用到公元 10889 年。随机部分 80 bits,每毫秒能生成 2^80 个 ID,不用担心不够用。
ULID 用 Crockford's Base32 编码,最终是 26 个字符。这个编码的特点是:
- 没有 I、L、O、U 这些容易混淆的字母
- 字典序就是时间序,方便排序
- URL 安全,没有特殊字符
pub fn generate_string(&self) -> Result<String, UlidError> {
let timestamp = Self::current_timestamp()?;
let mut bytes = [0u8; 16];
// 前 48 位放时间戳
bytes[0..6].copy_from_slice(×tamp.to_be_bytes()[2..8]);
// 后 80 位放随机数
getrandom::fill(&mut bytes[6..16])?;
// 单调递增模式:同一毫秒内,随机部分递增
if self.config.monotonic {
let last_ts = self.last_timestamp.load(Ordering::SeqCst);
if timestamp == last_ts {
// 递增随机部分,确保有序
// ...
}
}
Ok(Self::encode_ulid(&bytes))
}
fn encode_ulid(bytes: &[u8; 16]) -> String {
const ALPHABET: &[u8; 32] = b"0123456789ABCDEFGHJKMNPQRSTVWXYZ";
// 128 bits 编码成 26 个字符(每字符 5 bits)
// ...
}ULID 有个「单调递增」模式。开启后,同一毫秒内生成的 ID 会递增,这样能保证严格的有序性。默认是开启的。
NanoID 实现
NanoID 是最简单的,就是生成一个随机字符串。默认 21 个字符,使用 URL 安全的字母表。
但有个问题:怎么保证随机字符均匀分布在字母表里?
直接用取模运算会有偏差。比如字母表有 64 个字符,随机字节范围是 0-255,取模后 0-63 和 64-127 都映射到同一个字符,这样前 64 个字符出现的概率是后 64 个的两倍。
NanoID 用的是「掩码 + 拒绝采样」的方法:
pub fn new(config: NanoIdConfig) -> Self {
let alphabet_len = config.alphabet.len();
// 计算掩码:找到最小的 (2^n - 1) >= alphabet_len - 1
// 比如字母表 64 个字符,掩码就是 63 (0b111111)
let mask = {
let mut m = 1u8;
while m < alphabet_len as u8 - 1 {
m = m * 2 + 1;
}
m
};
Self { config, mask }
}
pub fn generate_string(&self) -> Result<String, NanoIdError> {
let mut result = String::with_capacity(self.config.length);
let mut bytes = vec![0u8; self.step * 2];
while result.len() < self.config.length {
getrandom::fill(&mut bytes)?;
for &byte in &bytes {
let index = byte & self.mask; // 用掩码过滤
if (index as usize) < self.config.alphabet.len() {
// 索引有效,使用这个字符
result.push(self.config.alphabet[index as usize] as char);
if result.len() >= self.config.length {
break;
}
}
// 索引无效,丢弃这个字节,继续下一个
}
}
Ok(result)
}掩码把随机字节映射到一个比字母表稍大的范围,然后拒绝掉超出字母表范围的索引。这样每个字符出现的概率就相等了。
存储层实现
Snowflake 需要存储状态,我们实现了两种存储:
MemoryStorage:存在内存里,重启就没了。适合单实例部署,或者测试环境。
pub struct MemoryStorage {
state: Arc<RwLock<GeneratorState>>,
}FileStorage:存在文件里,JSON 格式。重启后能恢复状态,适合生产环境。
pub struct FileStorage {
path: PathBuf,
}
impl Storage for FileStorage {
fn save(&self, state: GeneratorState) -> Pin<Box<...>> {
Box::pin(async move {
let data = serde_json::to_vec_pretty(&state)?;
let mut file = fs::File::create(&self.path).await?;
file.write_all(&data).await?;
file.sync_all().await?; // 确保刷到磁盘
Ok(())
})
}
}如果需要分布式部署,可以实现 RedisStorage 或者数据库存储。
HTTP 服务
用 Axum 框架,写几个路由就行:
pub fn create_router<G: IdGenerator + 'static>() -> Router<Arc<ServerState<G>>> {
Router::new()
.route("/id", get(generate_id))
.route("/id/batch", get(generate_batch))
.route("/health", get(health_check))
}
async fn generate_id<G: IdGenerator>(
State(state): State<Arc<ServerState<G>>>,
) -> Result<Json<IdResponse>, (StatusCode, Json<ErrorResponse>)> {
let id = state.generator.generate().await
.map_err(|e| (StatusCode::INTERNAL_SERVER_ERROR, Json(ErrorResponse { error: e.to_string() })))?;
Ok(Json(IdResponse { id: id.as_string() }))
}接口很简单:
GET /id生成一个 IDGET /id/batch?count=100批量生成GET /health健康检查
gRPC 服务
gRPC 性能更好,适合内部服务调用。先定义 proto:
syntax = "proto3";
package globuid;
service GlobUid {
rpc Generate(GenerateRequest) returns (GenerateResponse);
rpc GenerateBatch(GenerateBatchRequest) returns (GenerateBatchResponse);
}
message GenerateRequest {}
message GenerateResponse { string id = 1; }
message GenerateBatchRequest { uint32 count = 1; }
message GenerateBatchResponse {
repeated string ids = 1;
uint32 count = 2;
}用 Tonic 框架实现:
pub struct GlobUidService<G: IdGenerator> {
generator: Arc<G>,
}
#[tonic::async_trait]
impl<G: IdGenerator + 'static> GlobUid for GlobUidService<G> {
async fn generate(&self, _: Request<GenerateRequest>) -> Result<Response<GenerateResponse>, Status> {
let id = self.generator.generate().await
.map_err(|e| Status::internal(e.to_string()))?;
Ok(Response::new(GenerateResponse { id: id.as_string() }))
}
}命令行工具
最后写个 CLI,方便直接运行:
#[derive(Parser)]
struct Args {
#[arg(short = 'a', long, default_value = "snowflake")]
algorithm: String, // snowflake / ulid / nanoid
#[arg(short, long, default_value = "0")]
worker_id: u16,
#[arg(short, long, default_value = "8080")]
port: u16,
#[arg(short = 'P', long, default_value = "http")]
protocol: String, // http / grpc
}使用方法:
# 编译
cargo build --release --features full
# 启动 Snowflake HTTP 服务
./globuid --algorithm snowflake --worker-id 1 --port 8080
# 启动 ULID gRPC 服务
./globuid -a ulid -P grpc -p 50051
# 用文件存储
./globuid --storage file --storage-path ./state.json作为库使用
除了运行服务,也可以当作库在代码里直接用:
use globuid::{Snowflake, SnowflakeConfig, MemoryStorage, Ulid, NanoId};
#[tokio::main]
async fn main() {
// Snowflake
let config = SnowflakeConfig { worker_id: 1, ..Default::default() };
let storage = Arc::new(MemoryStorage::new());
let snowflake = Snowflake::new(config, storage).await.unwrap();
println!("Snowflake: {}", snowflake.generate_u64().await.unwrap());
// ULID
let ulid = Ulid::with_default();
println!("ULID: {}", ulid.generate_string().unwrap());
// NanoID
let nanoid = NanoId::default();
println!("NanoID: {}", nanoid.generate_string().unwrap());
}总结
这个项目体现了 Rust 后端开发的几个特点:
类型系统保证正确性。通过 Trait 抽象,编译器会帮我们检查接口是否正确实现。Send + Sync 约束保证了多线程安全。
零成本抽象。泛型会在编译时单态化,没有运行时开销。可选依赖(feature flags)让用户可以只编译需要的功能。
异步优先。所有 I/O 操作都是异步的,用 Tokio 运行时。高并发场景下性能很好。
组合优于继承。Generator + Storage + Transport 三层分离,每层都可以独立替换。比起 OOP 的继承体系,这种设计更灵活。
有兴趣的同学可以看看源码:https://github.com/lispking/globuid





