介绍 EthIQ
- EthPandaOps
- 发布于 2026-03-06 16:03
- 阅读 475
本文介绍了EthIQ,这是一个旨在评估AI模型对以太坊协议内部机制理解程度的基准测试工具。它通过API和Agentic两种模式,测试AI模型在以太坊常量、EVM执行、共识状态转换等多个类别下的知识和推理能力,并公布了不同AI模型在该基准上的性能表现。
如果你向一个 AI 模型提问关于共识常量、EVM 执行或状态转换的问题,它真的知道自己在说什么吗?我们构建了 EthIQ,这是一个衡量 AI 模型对以太坊协议内部机制理解程度的基准测试。
模型在两种模式下进行测试:API 模式(使用系统提示直接进行 API 调用,不带工具)和 Agentic 模式(在沙盒 Docker 容器中运行 CLI 工具,如 Claude Code 和 Codex,容器中包含 bash、文件 I/O 和 Node.js)。
动机
LLM 现在是 ethPandaOps 的日常工具,我们需要一种方法在我们的特定上下文中评估它们。当新模型发布时,EthIQ 能为我们提供快速的信号,并提供一套有意义的评估套件,以推动我们在代理工具(提示优化、微调、工作流等)方面的投入。
问题
问题集旨在测试两种不同的模型能力:世界知识(通过常量等类别测试)和原始推理(通过EVM 执行等自动生成类别测试)。世界知识问题是刻意设计的。我们希望明确探测以太坊协议知识中有哪些内容进入了模型的训练数据,因为回忆这些值确实很有用。
为了防止原始推理任务中的记忆化,自动生成的问题从官方以太坊规范测试夹具开始,但使用随机种子(余额、存储值、calldata、存款金额等)修改输入。然后使用 Python 参考实现从修改后的输入重新推导出真值答案。如果模型在训练期间看到了原始夹具,其答案将不匹配。新的分叉会获得一个新的种子,从而使基准测试随着时间的推移保持诚实。
问题按数据集组织,与以太坊分叉相关联。第一个数据集是 fusaka,包含 325 个问题,涵盖以下类别:
| 类别 | 它问什么 | 示例 |
|---|---|---|
| 常量 | 精确的协议常量值 | 主网上的 SLOTS_PER_EPOCH 值是多少? |
| EVM 执行 | 追踪字节码,报告结果 | 给定 0x...,存储槽 0x1 中有什么? |
| 共识状态转换 | 应用惩罚(slashings)、存款等,并计算结果状态 | 在此 Attester 惩罚后,验证者 6 的余额是多少? |
| 共识周期处理 | 计算奖励、罚金和余额变化 | 处理完此周期后,奖励/罚金变化是多少? |
| 共识分叉选择 | 重放区块树并确定规范头 | 在这些证明(attestations)之后,哪个区块是头区块? |
| 共识洗牌 | 计算验证者委员会分配 | 在槽位 4 中,委员会索引 2 中有哪些验证者? |
| 计算 | 使用协议常量的多步骤算术 | 一个以太坊周期有多少秒? |
| 概念性 | 由 LLM 评分标准评级的开放式解释 | 解释 RANDAO 偏差在验证者洗牌中如何运作 |
| 跨分叉 | 分叉之间有什么变化 | Electra 中最大有效余额有什么变化? |
| EIP 交互 | 特定 EIP 如何相互作用 | EIP-4844 blob 承诺如何出现在信标区块中? |
| 陷阱 | 带有错误前提的问题 | “Verkle Trees 是何时在主网上发布的?”(它们没有。) |
结果
🔍 点击放大
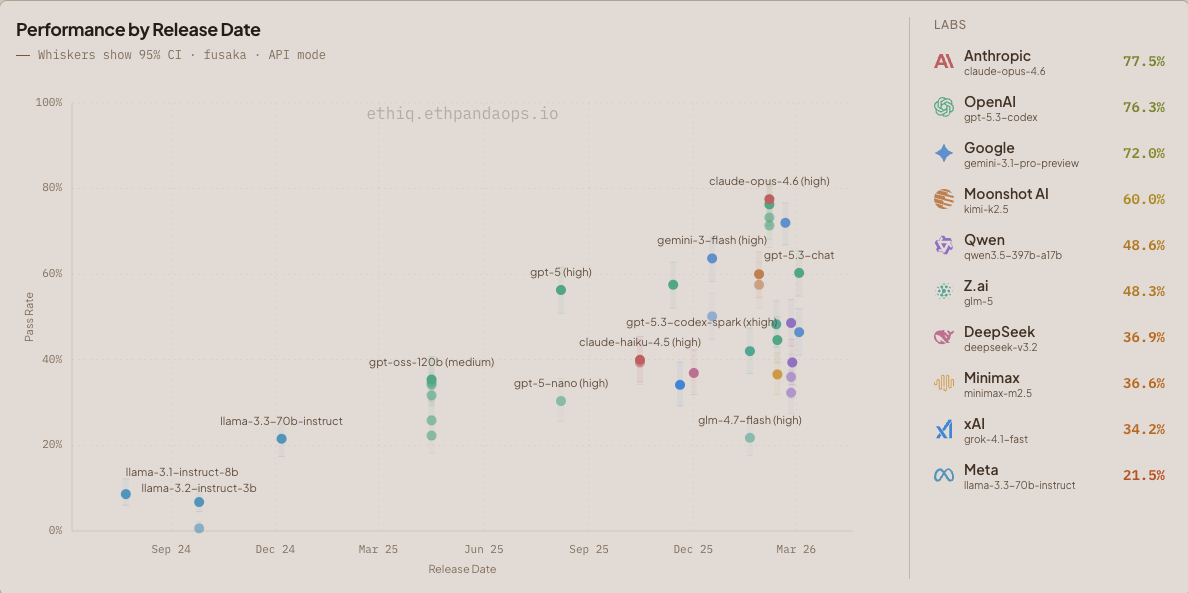
图 1:fusaka 数据集(325 个问题)上模型按发布日期划分的性能。须线显示 95% 置信区间。
前沿
在 API 模式下,Anthropic 的 claude-opus-4.6-high 以 77.5% 的得分领先,其次是 OpenAI 的 gpt-5.3-codex-xhigh(76.3%)和 Google 的 gemini-3.1-pro-preview-high(72.3%)。claude-sonnet-4.6-high 仍在进行中。
当包含 Agentic 运行结果时,gpt-5.3-codex-xhigh 通过 Codex CLI 以 83.7% 的得分领先。
我们观察到一些模型(minimax-m2.5-high)随着其 reasoning_effort 的增加而表现下降。经过调查,我们发现这些模型耗尽了其最大 token 输出分配,有效地思考过度而死。
API 模式下的 EVM 执行问题是衡量模型能力的一个特别好的情绪检查。看着 Kimi K2.5 在其思考轨迹中逐步执行 EVM 是一种相当的体验(阅读:令人担忧!)。我们对要求 llama-3.2-1b 做同样的事情感到抱歉。总的来说,我们没想到模型在上下文中执行 EVM 的能力如此之强。幸运的是,我们在生成时限制了 EVM 问题的难度(基于一些启发式方法),因此一旦这个数据集饱和,我们就可以提高这些限制并推出一类新的非常困难的问题。
开源模型
🔍 点击放大
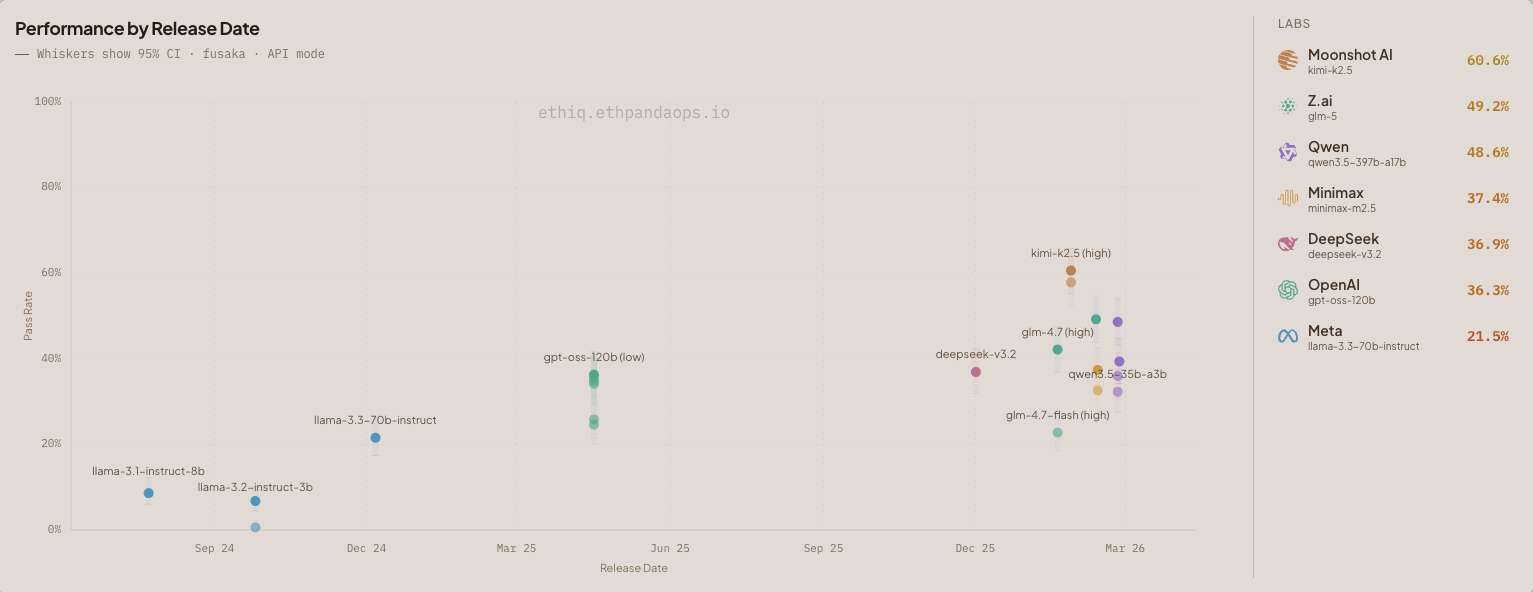
图 2:fusaka 数据集(325 个问题)上开源模型按发布日期划分的性能。须线显示 95% 置信区间。
以太坊和开源模型相得益彰,因此我们增加了仅显示开源模型的功能。Kimi 的 k2.5-high 在开源模型中表现突出,得分 60.6%。
minimax-m2.5-high 的表现令人失望,得分 37.4%。这种差异主要体现在共识常量方面,k2.5-high 得分 94.7%,而 minimax-m2.5-high 得分 58.9%。k2.5 是一个更大的模型,拥有 1 万亿参数,而 minimax-m2.5 只有 2300 亿参数。在使用 LLM 进行以太坊相关任务时,世界知识是一个重要因素!
金丝雀 🐦
幸运的是,所有 API 评估在共识洗牌方面都返回了失败。这需要模型在上下文中计算 SHA256。如果这只金丝雀死了,你会在远离任何电力的地方找到 ethPandaOps 团队。
尝试一下
在 ethiq.ethpandaops.io 浏览完整结果。你可以按问题类别、难度和评估模式进行筛选。
请继续关注,我们将在新的分叉发布和模型发布时更新此内容!
- 原文链接: ethpandaops.io/posts/int...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





