可执行信标链
- ETH中文网
- 发布于 2021-04-24 20:56
- 阅读 3956
除可执行分片之外,可执行信标链作为替代的 eth2 执行模型,通过在信标链上添加单个执行线程的支持来实现
来源 | ethresear.ch
特别感谢最初提出该想法的 Vitalik Buterin @vbuterin,感谢 Danny Ryan @djrtwo、@zilm 等给本文提供的宝贵意见。
摘要:除可执行分片之外,可执行信标链作为替代的 eth2 执行模型,通过在信标链上添加单个执行线程的支持来实现
Vitalik 此前发布的文章《以 rollup 为中心的路线图》中提到,数据分片作为 eth2 执行中的主要扩容因素,允许在单个执行分片上进行扩容,并简化了总体设计。
Eth1 分片设计基于其通过信标链与数据分片通信。如果阶段 2 的多执行分片功能将在之后推出,那么这个方法就有意义了。有了以 rollup 为中心的路线图,将 Eth1 放在专门的分片上 (即独立于信标链、且频繁与信标链交互) 会给共识层带来不必要的复杂性,并增加在分片上发布数据和在 eth1 中访问数据之间的延迟。
我们提议将 eth1 数据 (交易、状态根等) 嵌入到信标区块中,并且要求信标链区块提议者生成可执行的 eth1 数据,以消除这种复杂性。也就是说将 eth1 执行和有效性作为共识核心的一等公民。
提案概览
- Eth1-引擎由系统中的验证者维持。
- 当验证者打算提议一个信标区块时,他会通过 eth1-引擎创建 eth1 数据。然后 eth1 数据将被嵌入到其提议的信标区块中。
- 如果 eth1 数据无效,其所在的信标区块也同样无效。
Eth1 引擎的修改
根据前面的介绍,eth1 分片为中心的设计中,eth1-引擎和 eth2-客户端是松散耦合的,并通过 RPC 协议实现通信 (查看文章 eth1+eth2 客户端关系 以了解更多信息)。eth1-引擎不断维护着其交易池和状态下载器,这需要它自己的网络堆栈。它还应该存储 eth1 区块。
当前的提案取消了 eth1 区块的概念,eth1-引擎有两种可能的方式来处理这一变化:
- 通过合成的方式,从信标链区块的 eth1 数据中创建 eth1 区块
- 修改引擎:交易处理过程不a需要使用 eth1 区块,而是使用 eth1 数据
- 信标区块根可用于保存当前状态管理所需要的链的概念
两者相比,后者为比较长期的选项。它允许 eth1 客户端更快地转换为 eth1-引擎,且 eth1 分片概念证明 (PoC) 已经证明了这一点。
我们使用术语“可执行数据” (executable data) 来表示包含 eth1 状态根、交易清单 (包括收据根“receipts root“和 bloom filter)、coinbase、时间戳、区块哈希以及 eth1 状态迁移函数所需要的所有其他数据位。可执行数据在 eth2 规范中表示如下:
class ExecutableData(Container):
coinbase: bytes20 # Eth1 address that collects txs fees
state_root: bytes32
gas_limit: uint64
gas_used: uint64
transactions: [Transaction, MAX_TRANSACTIONS]
receipts_root: bytes32
logs_bloom: ByteList[LOGS_BLOOM_SIZE]Eth1-引擎的职责清单与此前 eth1 分片的职责类似。主要有:
- 交易执行。Eth2-客户端向 eth1-引擎发送一笔可执行数据。Eth1-引擎通过处理该数据来更新其内部状态,并且如果通过了共识检查则返回
true,否则返回false。诸如即时存款处理之类的高级用例也可能要求结果中包含完整的交易收据。 - 交易池维护。Eth1-引擎使用 ETH 网络协议来广播信息并跟踪网络上的交易。等待被打包的交易 (pending transactions) 保存在交易池中,然后用于创建新的可执行数据。
- 可执行数据创建。Eth2-客户端发送之前的区块哈希、eth1 状态根、coinbase、时间戳和创建可执行数据的所有其他信息 (交易清单的一部分)。Eth1-引擎返回一个
ExcecutableData实例。 -
状态管理
Eth1-引擎维护状态存储以便能够运行 eth1 状态执行函数。
- 它涉及在最终确定性上触发的状态树修剪机制 (pruning mechanism),该机制要求基于信标区块链的状态树版本控制。
注意:长期无区块敲定会造成大量垃圾数据的堆积,从而消耗额外的磁盘空间。
- 当无状态执行和”区块创建“完成时,eth1 引擎可以选择作为纯状态迁移函数运行,并在此基础上承担一些责任,如,可以禁用状态存储,从而减少使用磁盘空间的需求。
- JSON-RPC 支持。为了可用性和应用性,保留以太坊 JSON-RPC 的支持十分重要。该责任将由 eth2-客户端和 eth1-引擎共同承担,因为 eth1-引擎可能失去了单独处理 JSON-RPC 终端子集的能力,如那些基于区块号和哈希的调用。这种分离将在之后解决。
信标区块处理
可执行数据 ExecutableData 结构代替了信标区块体中的 Eth1Data 。此外,信标链和 eth1 的同步处理允许即时存款。因此,存款可以从信标区块体中移除。
以下是更新了的信标区块体:
class ExecutableBeaconBlockBody(Container):
randao_reveal: BLSSignature
executable_data: ExecutableData # Eth1 executable data
graffiti: Bytes32 # Arbitrary data
# Operations
proposer_slashings: List[ProposerSlashing, MAX_PROPOSER_SLASHINGS]
attester_slashings: List[AttesterSlashing, MAX_ATTESTER_SLASHINGS]
attestations: List[Attestation, MAX_ATTESTATIONS]
voluntary_exits: List[SignedVoluntaryExit, MAX_VOLUNTARY_EXITS]我们修改了 process_block 函数:
def process_block(state: BeaconState, block: BeaconBlock) -> None:
process_block_header(state, block)
process_randao(state, block.body)
# process_eth1_data(state, block.body) used to be here
process_operations(state, block.body)
process_executable_data(state, block.body)在 process_operations 完成之后处理可执行数据是合理的,因为在很多情况下,operation processing 可能会使整个区块无效。虽然,这种方法可能不是最优的,无法让客户端优化达到最优效果。
访问 EVM 的信标状态
我们更改了 BLOCKHASH 操作码 (此前用于返回 eth1 区块哈希) 的语义,现在用来返回信标区块根。这允许验证被打包进信标状态或区块的数据 (包括从前 256个 slot 到最近一个 slot 的数据)。
异步状态读取有一个主要的缺点。客户端必须要等待一个区块产生,才可以使用链接到该区块的证明或使用该区块的状态根创建一个事务。简单地说,异步状态访问至少要延迟一个 slot。
直接状态访问
假设 eth1-引擎可以访问代表整个信标状态的默克尔树。那么 EVM 可能可以凭借 READBEACONSTATEDATA(gindex) 操作码,以提供直接访问信标状态任何部分的功能。这个操作码有几个良好的属性。首先,这种读取复杂性取决于 gindex 值并且易于计算,因此可以轻松地计算 gas 费。第二,返回数据的容量为 32 字节,完全适合 EVM 的 32 字节字。
使用此操作码,就可以创建更高级别的信标状态访问库,从而为智能合约提供便捷的 API。如:
v = create_validator_accessor(index) # creates an accessor
v.get_balance() # returns balance of the validator
v.is_slashed() # returns the value of slashed flag该模型消除了状态访问延迟。因此,通过对信标链操作和 eth1 执行进行适当的排序 (eth1 执行在后),并且在 slot N上可以访问 slot N-1 分片数据的交联,可以允许 rollup 以最快的方式对数据打包进行证明。
此外,使用这个方法不需要将证明广播至网络并进一步由合约验证,从而减少了信标状态读取在数据和计算方面的复杂性。
注意:在一开始使 READBEACONSTATEDATA 操作码的语义独立于特定的承诺方案 (即默克尔树) 是有意义的,这有益于更轻松地实现升级。
直接访问的成本提高了 eth1-引擎的复杂性。读取信标状态可以通过不同的方式实现:
- 将可执行数据和状态一起传递。该方法的主要问题是处理大容量的状态副本。如果将直接访问限制为状态数据的一个子集,而该状态数据的子集需要将一小部分状态传递给执行,那么它可能会起作用。
- 双工通信通道。有了双工通道,eth1-引擎将能够同步向信标节点询问 EVM 请求的状态。根据通道设置的方式,延迟可能会成为执行那些具有信标状态读取的交易的瓶颈。
- 嵌入式的 eth1-引擎。如果将 eth1-引擎嵌入到信标节点中,它可以通过节点提供的托管功能从同一个内存空间读取状态。
分析
网络带宽
当前提案通过可执行数据的容量来扩大信标区块。不过,由于该提案允许使用更高级的存款方案,因此很有可能删除 Deposit 操作。
取决于区块利用率,根据 eth1 平均区块容量 (这略微影响网络接口的需求),预期的增长在 10% 到 20%之间。
值得注意的是,如果 CALLDATA 由 rollup 利用,那么在最坏的情况下,eth1 区块容量可能会增长到 200kb (gas limit 为 1200 万时),使得可执行信标区块容量增长 60% ,容量变为 300kb 。
区块处理时间
平均处理时间:
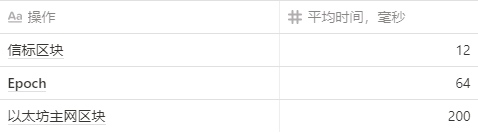
Toledo 上的 Lighthouse 有 1.6 万验证者,主网上的 Go-ethereum 的 gas limit 为 1200 万。
很难推断出信标链的处理时间,尤其是,特别是在验证者子集相对较大以及需要处理交联的情况下 (如果分片上线)。也许在某个时候,epoch 处理将与 eth1 执行几乎同时进行。
减少时段边界 (epoch boundary) 处理时间的方法是,提前处理 epoch,而不是等到下一个 slot 的开始,以防最近一个 epoch 的最后一个区块准时产生。
异步状态访问模型允许另一种优化方式。在这种情况下,process_executable_data 可能与主要的 process_block ,甚至 process_epoch 的有效负载并行运行。
固化该设计
有人可能会说,当前提案将执行模型固定下来,并削弱了引进更多可执行分片的能力 (一旦我们需要它们)。
另一方面,一些可执行分片会带来诸如跨分片通信、共享账户空间等问题。还有一些其他的问题,而这些问题与执行模型的预期转变同样重要且难以解决。
ECN的翻译工作旨在为中国以太坊社区传递优质资讯和学习资源,文章版权归原作者所有,转载须注明原文出处以及ethereum.cn,若需长期转载,请联系eth@ecn.co进行授权。





