搞懂缓存机制,从Gemma4到Claude Code省80%Token
- minlibuilds
- 发布于 1天前
- 阅读 77
文章通过本地运行 Gemma 4 的对比实验,深入探讨了大模型 KV 缓存的工作原理及 Transformer 注意力机制的底层逻辑。同时,通过逆向分析 Claude Code 源码,揭示了其精密的缓存工程实现,并为开发者提供了大幅节省 Token 消耗和优化响应速度的实用技巧。

早上打开 Claude Code,敲第一句话,2%~10% 的套餐额度没了。午休回来继续干活,又一句话,10% 的额度蒸发。你有没有想过,这 token 到底花在哪了?我带着这个疑问,在本地用 Gemma4 跑小模型做实验——发现同一段对话,有些轮次要等 30 秒,有些只要 0.2 秒。为了搞清楚为什么,我会从 Transformer 的注意力机制开始讲,再到 Claude Code 的代码实现, Anthropic 在缓存上做了一整套精密工程。理解了这套机制,你就知道怎么让同样的套餐多撑 3-5 倍。
导读
本文内容较长,建议按需阅读:
- 第一至二章:本地实验与原理揭秘(核心逻辑,推荐所有人阅读)
- 第三章:缓存的细节追问(适合想深入理解底层机制的读者)
- 第四至五章:逆向 Claude Code 源码(面向开发者及 Claude Code 深度用户)
- 第六至七章:使用姿势与省钱技巧(Claude Code 用户必看,时间紧迫者可直接跳转)
一、实验:同一段对话,为什么有时 30 秒有时 0.2 秒?
起因很简单:我想在本地体验一下大模型的 context caching(上下文缓存),看看到底能快多少。
我使用 Ollama 在 Mac (Apple Silicon, 16GB) 上运行 Gemma 4(8B 参数,约 9.6GB 模型),并编写了一个测试脚本进行多轮对话:首先输入一篇 670 token 的文章,随后连续追问 5 个问题。
每轮 API 返回两个关键指标:Prompt 处理时间(消化输入)和生成时间(吐出回答)。将 Prompt 处理时间单独提取出来,结果如下:
| 轮次 | Prompt 处理 | 生成 (Token 数) | 总耗时 |
|---|---|---|---|
| Turn 1 (喂文章) | 24,458ms | 5,095ms (68 tok) | 34s |
| Turn 2 (追问1) | 31,036ms | 22,653ms (365 tok) | 58s |
| Turn 3 (追问2) | 253ms | 2,511ms (46 tok) | 3.8s |
| Turn 4 (追问3) | 203ms | 2,029ms (36 tok) | 3.0s |
| Turn 5 (追问4) | 165ms | 1,870ms (37 tok) | 2.4s |
| Turn 6 (追问5) | 176ms | 1,235ms (26 tok) | 1.8s |
从 Turn 2 到 Turn 3,Prompt 处理时间从 31 秒直降到 0.25 秒,实现了 100 倍加速。而生成速度始终稳定在 13-20 tok/s,未受影响。
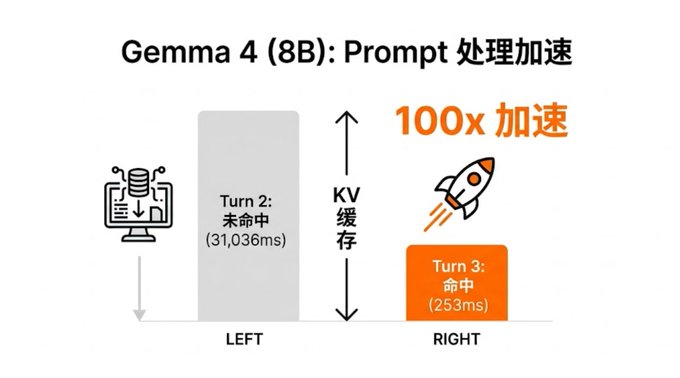
这说明加速仅发生在“消化输入”阶段,与“吐出回答”无关。
随后,我换用小模型 Qwen3.5(0.8B,约 1GB)进行同样的测试,观察模型大小的影响:
| 轮次 | Prompt 处理 |
|---|---|
| Turn 1 (喂文章) | 566ms |
| Turn 2 (追问1) | 173ms |
| Turn 3 (追问2) | 182ms |
| Turn 4 (追问3) | 212ms |
| Turn 5 (追问4) | 227ms |
| Turn 6 (追问5) | 240ms |
小模型全程维持在 200ms 左右,没有出现类似 Gemma 4 那种剧烈的速度变化。
这里有两个核心问题:
- 那个 100 倍加速的本质是什么?
- 为什么大模型受益巨大,而小模型几乎无感?
二、原理:KV 缓存——注意力的 QKV 中的 KV
大模型生成文本时,基于 Transformer 的注意力机制。其核心公式为:
$$Attention(Q, K, V) = \text{softmax}\left(\frac{Q \cdot K^T}{\sqrt{d}}\right) \cdot V$$
其中 $Q$、$K$、$V$ 分别扮演以下角色:
- $Q$ (Query):当前新 token 的需求,“我要找什么?” —— 每次不同,不可缓存。
- $K$ (Key):历史 token 的索引,“我这有什么?” —— 计算后即固定,可以缓存。
- $V$ (Value):历史 token 的内容,“具体内容是什么?” —— 计算后即固定,可以缓存。
KV 缓存的本质是将历史 token 的 $Key$ 和 $Value$ 存储起来。当处理新 token 时,只需计算其自身的 $Q$,然后直接检索已有的 $KV$。
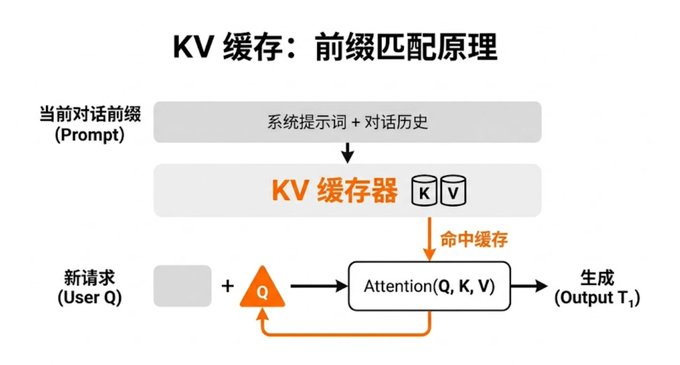
这种机制之所以可行,是因为主流大模型(如 Claude、GPT、Llama 等)多采用 Decoder-only 架构。这种架构使用单向注意力(因果掩码),每个 token 只能看到它之前的 token。因此,前面 token 的 $KV$ 一旦算出便不再改变。
回到实验数据:
- Turn 1-2 慢:模型在逐层计算 670 多个 token 的 $KV$ 张量,涉及巨量计算。
- Turn 3 变快:之前算好的 $KV$ 已被缓存,只需从内存加载,计算瓶颈从 GPU 计算转变为内存读取。
- 小模型无感:Qwen3.5 参数量极小,计算 $KV$ 本身就很快,缓存带来的提升不明显。
模型越大,$KV$ 计算越昂贵,缓存的收益就越显著:
| 指标 | Gemma 4 (4.5B active) | Qwen3.5 (0.8B) |
|---|---|---|
| 未命中耗时 | ~25,000ms | ~566ms |
| 命中耗时 | ~170ms | ~173ms |
| 加速比 | 148x | 3.3x |
| 命中时速度 | 3,000-5,000 tok/s | 3,200-3,900 tok/s |
三、缓存细节:无损性与生成结果的处理
缓存是无损的吗? 是的。Transformer 的计算是确定性的,从缓存加载 $KV$ 与现场计算的结果完全一致。
生成结果会进缓存吗? 生成结果(Output tokens)本身不进入 Prompt 缓存。因为每次生成的内容受 Temperature 等参数影响可能不同,直接缓存没有意义。
但有一个精妙的设计:在下一轮对话中,上一轮的生成结果会被拼接到 Prompt 中,作为“输入”的一部分。此时,这部分内容便会被缓存覆盖。
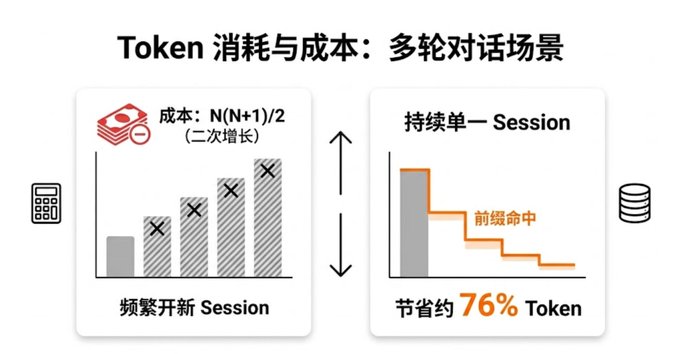
多轮对话的成本对比: 如果没有缓存,每轮对话都要重新计算所有历史,Token 消耗呈二次增长。有了缓存,情况则大不相同:
假设系统提示 20K tokens,每轮对话增加 1K tokens。
- 无缓存(每轮全价):10 轮总计约 255K tokens。
- 有缓存(前缀 1/10 价格):10 轮总计约 60K 等价 tokens。
结论: 缓存节省了约 76% 的成本。这就是为什么“在同一个 session 持续对话”比“频繁开启新 session”更省钱的原因。
四、Claude Code:一套精密的缓存工程
通过逆向 Claude Code 源码可以发现,Anthropic 在缓存上做了大量精细化处理。
1. Prompt 的多层结构
Claude Code 发送的 API 调用并非一整块,而是精心拼接的结构:
- Block 1 & 2:计费归因与 CLI 前缀(不缓存)。
- Block 3:静态指令(行为规则等),属于 Global 缓存,全球用户共享。
- Block 4:动态内容(如
CLAUDE.md),属于 Org 缓存。 - Tools:工具 Schema,Session 内固定。
- Messages:对话历史,最后一条消息会放置
cache_control标记。
2. 缓存的 TTL(生存时间)
- 默认:5 分钟。
- 扩展:1 小时(针对 Pro/Max 订阅用户且未超额者)。
3. 缓存断裂检测
Claude Code 会监控 cache_read_input_tokens。如果该值比上次下降超过 5% 且绝对值大于 2000 tokens,系统会判定为缓存断裂,并分析原因(如系统提示词变更、工具增减、TTL 过期等)。
五、缓存链条:断在哪里,后面全废
缓存遵循前缀匹配原则。只要从头开始的 token 序列发生变化,后续缓存将全部失效。
- 最贵(Block 3 失效):整个请求从头计算。
- 中等(Block 4 变更):Block 3 可复用,后续失效。
- 最省(仅追加消息):前面内容全部复用。
注意: 切换模型会导致缓存完全失效,因为不同模型的权重不同,$KV$ 张量无法互用。
Sub-agent 能复用主线程的缓存吗?
答案是:几乎不能。 每个 sub-agent(如 Explore agent)都是独立的 API 调用,且存在以下差异:
- 工具集不同:主线程与 agent 的工具 Schema 不同,导致前缀不匹配。
- 消息历史独立:对话上下文没有交集。
- 模型可能不同:主线程用 Opus,agent 可能用 Haiku。
因此,启动一个 sub-agent 基本等同于一次“冷启动”。
六、实战指南:如何保护你的缓存
理解了机制,就能通过优化习惯来省钱。
保护缓存的行为(推荐):
- 连续对话:保持前缀不变,利用增量缓存。
- 使用 btw:通过
btw共享 session 和缓存。 - 合理维护 CLAUDE.md:定期整理,但避免在任务执行中途频繁修改。
破坏缓存的行为(避免):
- 频繁开新 session:导致 20K 级别的系统提示词反复全价重算。
- 修改 CLAUDE.md:导致 Block 4 之后的缓存全部失效。
- 频繁增减 MCP 工具:工具 Schema 变化会导致缓存断裂。
- 频繁切换模型:每次切换都会导致上下文全价重算。
- 过度使用 /compact:改变消息历史会导致缓存断裂。
- 长时间发呆:超过 TTL 后缓存会过期。
成本差异: 同样 10 轮对话,持续对话的成本仅为频繁开新 session 的约 1/5。
七、进阶技巧:Cache Keep-Alive 续命
Pro/Max 用户的缓存 TTL 为 1 小时。如果因为午休或会议导致超过 1 小时未操作,缓存就会过期。
原理: 缓存 TTL 在每次读取时都会刷新。只要在过期前发送一次匹配前缀的请求,缓存就能无限续命。
方案设想: 可以利用脚本,每隔 55 分钟向 Claude Code 终端自动发送一条简单的 Prompt:
我断线了么?如果没断你只要简单说 ok。通过这种方式,可以有效维持缓存状态,避免昂贵的冷启动开销。
- 本文转载自: x.com/minlibuilds/status... , 如有侵权请联系管理员删除。
- 转载
- 学分: 4
- 分类: AI
- 标签: KV缓存 Transformer Claude Code 注意力机制 Token优化 上下文缓存





