使用solidity实现一个printf函数
- jackson
- 发布于 2022-03-14 16:06
- 阅读 5593
字符串格式化函数在应用开发时经常用到,而在合约中使用场景似乎没有那么多,然而要实现这个函数,则需要先解决一些问题,本文就探讨一下如何来解决这些问题。
字符串格式化函数在应用开发时经常用到,而在合约中使用场景似乎没有那么多,然而要实现这个函数,则需要先解决一些问题,本文就探讨一下如何来解决这些问题。先看其用法:
printf("name=%s, age=%u, height=%u", n, a, h);第一个问题,就是printf函数的参数类型和个数是动态变化的,然而solidity编译器目前并没有提供这种支持,如何解决这个问题呢?
方法一
使用数组。使用数组是一种比较直接的想法,但是数组中的元素类型必须相同,这样的话,怎么传字符串呢?
在计算机中,一切都是数据,可以考虑将字符串转为数值来传递,对于以太坊,一个uint是256位,32个字节,拿出一位来保存长度,可以用uint表示最长31个字符的字符串,代码如下:
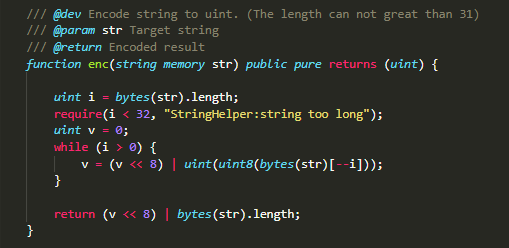
方法二
利用内置函数。虽然solidity不支持定义可变参数的函数,但是一些内置函数可以,例如abi.encode(),可以传入可变参数,并将这些参数编码成字节数组。然后在printf函数里面,按照对应的方式解码就可以了。下面是解码uint和string的代码。
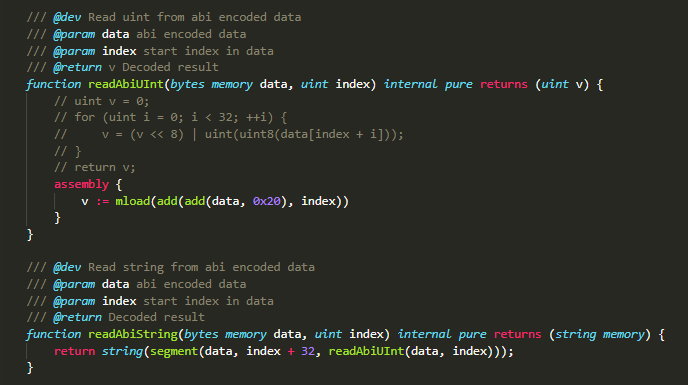
readAbiUInt()用于从abi.encode()编码后的字节数组的指定位置读取一个uint,其中被注释掉的代码是基本实现,通过循环读取数据按规则解码实现,但是此方法效率较低,因此可以更改勇敢下面的方式实现,提高效率。
readAbiString()则是从abi.encode()编码后的字节数组的指定位置读取一个string。至于为什么要这么实现,则是由于abi.encode()的编码规则确定的,如果有需要,我后面再写一篇文章详细介绍其编码规则。
通过以上两种方法,可以解决传参数的问题了,接下来就是要解析格式化字符串了,这涉及到一个算法,可以考虑使用“有限状态机”的方式来实现。
有限状态机看起来很神秘,但其实逻辑非常简单,在解析时,按照需要解析的逻辑定义一些状态,然后确定每种状态遇到什么条件就会进入另外一个状态,如此就可以将一个字符串按照指定的逻辑进行解析。
下面是格式化字符串需要定义的几个状态: 0:初始状态,解析开始,或者完成一个格式描述串的处理,就回到初始状态。 1:遇到描述符开始%。在0状态下,遇到%就进入此状态。 2:描述符结束。在1状态下,如果遇到u,d,s,%,就算描述符结束,这四个描述符分别对应:无符号整数、整数、字符串、%转义。分别按照对应的位置从前面传入的参数表中按照指定的含义读出数据,写入到输出,然后状态回到0。
下面是实现代码
/// @dev Format to memory buffer
/// @param buffer Target buffer
/// @param index Start index in buffer
/// @param format Format string
/// @param abiArgs byte array of arguments encoded by abi.encode()
/// @return New index in buffer
function sprintf(
bytes memory buffer,
uint index,
bytes memory format,
bytes memory abiArgs
) internal pure returns (uint) {
uint i = 0;
uint pi = 0;
uint ai = 0;
uint state = 0;
uint w = 0;
while (i < format.length) {
uint c = uint(uint8(format[i]));
// 0. Normal
if (state == 0) {
// %
if (c == 37) {
while (pi < i) {
buffer[index++] = format[pi++];
}
state = 1;
}
++i;
}
// 1. Check if there is -
else if (state == 1) {
// %
if (c == 37) {
buffer[index++] = bytes1(uint8(37));
pi = ++i;
state = 0;
} else {
state = 3;
}
}
// 3. Find width
else if (state == 3) {
while (c >= 48 && c <= 57) {
w = w * 10 + c - 48;
c = uint(uint8(format[++i]));
}
state = 4;
}
// 4. Find format descriptor
else if (state == 4) {
uint arg = readAbiUInt(abiArgs, ai);
// d
if (c == 100) {
if (arg >> 255 == 1) {
buffer[index++] = bytes1(uint8(45));
arg = uint(-int(arg));
} else {
buffer[index++] = bytes1(uint8(43));
}
c = 117;
}
// u
if (c == 117) {
index = writeUIntDec(buffer, index, arg, w == 0 ? 1 : w);
}
// x/X
else if (c == 120 || c == 88) {
index = writeUIntHex(buffer, index, arg, w == 0 ? 1 : w, c == 88);
}
// s/S
else if (c == 115 || c == 83) {
index = writeAbiString(buffer, index, abiArgs, arg, w == 0 ? 31 : w, c == 83 ? 1 : 0);
}
// f
else if (c == 102) {
if (arg >> 255 == 1) {
buffer[index++] = bytes1(uint8(45));
arg = uint(-int(arg));
}
index = writeFloat(buffer, index, arg, w == 0 ? 8 : w);
}
pi = ++i;
state = 0;
w = 0;
ai += 32;
}
}
while (pi < i) {
buffer[index++] = format[pi++];
}
return index;
}这样,就可以实现一个printf函数了,又找回了C编程的感觉,虽说使用场景不多,但是并不代表没有,比如当我们需要按照某些规则来给一系列合约创建的代币生成名字的时候,就可以用这个方法了。
本文引用的代码来自:https://github.com/FORT-Protocol/FORT-V1.1/blob/nest4.0/contracts/libs/StringHelper.sol#L443





