用自定义素材组合生成艺术NFT
- 翻译小组
- 发布于 2022-08-15 17:27
- 阅读 7185
用自定义素材,自定义的稀有度,层叠组合生成艺术NFT图片

简介
像Cryptopunks和Bored Ape Yacht Club这样的知名NFT项目已经创造了数亿美元的收入,并使其所有者成为百万富翁。
上述项目(以及当今大多数其他成功的NFT项目)的共同点是,它们是PFP(profile picture)项目。这意味着它们通常是10,000多个头像的集合,其中每个头像都是独特的,并有一系列的特征。
在本教程中,我将向你展示如何用自定义的稀缺性生成这样一个集合。我将使用Scrappy Squirrels团队创建的一个库来完成这个任务。在本教程的最后,你将生成你自己的带有相关元数据的自定义头像集合。
前置条件
安装Python和pip
库是用Python写的,所以你需要在电脑上安装Python,还需要安装pip,它用于安装重要的软件包。去Pytho 官方网站,下载最新版本的Python。
一个艺术家(加分项,但不是必须)
最好有一个熟悉数字艺术的艺术家来为你定制产品图片。然而,这并不是学习本教程的必要条件。我将为你提供测试图片,让你玩一玩。
Scrappy Squirrels 藏品
作为本教程的一部分,我将带领你完成创建Scrappy SquirrelsNFT的过程,这个教程(以及随后的教程)以使NFT和区块链更容易为人们所接受。
松鼠已经使用90多个特征生成。这里有几个例子:

生成过程
你在上面看到的松鼠是通过将PNG图像堆叠在一起生成的。虽然没有蓝筹NFT项目(指知名大项目)描述他们是如何生成艺术NFT的,但我们可以肯定他们也是这样做的。你看到的几乎每个NFT头像都是一组堆叠的PNG图像(非JPEG)。

从右上角开始,如果你顺时针堆叠每一个特质图像,一个接一个,你最终会得到中间的图像。这里有几件事需要注意。
- 每个特征图像(以及最后的松鼠头像)的尺寸完全相同。
- 除了背景特征(这是第一个特征),其他每个特征图像都有一个透明的背景。
- 特征图像必须叠加,以获得正确的松鼠头像(即从右上方顺时针方向)。
- 特征图像的绘制方式是使它们的位置相对于所有其他特征而言是合理的。
- 我们可以将任何特征与同一类别的另一个特征进行交换(例如,用红衬衫交换蓝衬衫)。因此,在这种情况下,如果我们对每一类特征有10个特征,理论上我们可以产生1亿只不同的松鼠。
因此,艺术家的工作是创造各种特征类别的多个图像。你可以有多少个特征类别,只要你想。但请记住,可能的组合数量会随着特征类别的增加而成倍增加。
在Scrappy Squirrels项目中,我们创建了8个特征类别。
每个特征类别都有不同数量的特质图像。例如,有11件不同的衬衫可以使用:
现在,轮到你了,你需要决定想做的特征类别,并为每个类别生成特征图像。确保它们满足上面提到的5 个条件(应该有相同的尺寸,有正确的位置等等)。另外,确保你给特征图像起一个适当的名字,你给图像起的名字就是将出现在元数据文件中的内容。
一旦你完成了这些,我们现在就可以使用这个库来自动生成我们的藏品。 如果你不是一个艺术家(或没有机会),不要担心!我们有一些样本图像,你可以用它来制作。
注意:目前,该库只能够处理PNG图像,之后将增加对其他媒体类型的支持。
下载代码库并安装所需软件包
我们的生成艺术品代码库在GitHub上是免费提供的,你可以自由克隆它。
一旦你克隆了代码库,打开你的终端或命令提示符,并运行以下命令:
pip install Pillow pandas progressbar2运行这个命令将安装我们的库所依赖的三个重要的Python包:
- Pillow:一个图像处理库,将帮助我们堆叠特征图像。
- Pandas: 一个数据分析库,将帮助我们生成和保存图像元数据。
- 进度条: 一个库,将告诉我们图像生成时的进度和ETA值。
添加你的自定义素材
在你下载的generative-art-nft代码库中,你会看到有一个assets文件夹。如果你有你的自定义特征素材,就把这个文件夹的内容替换成你的素材。在我们的例子中,assets文件夹有8个子文件夹,代表了适当命名的类别(见上文),每个子文件夹都有该特定类别的特征图片。
如果你没有自定义的特征作品,请保持默认的assets文件夹不变。
配置 config.py 文件
这是我们生成头像集合之前的最后一步(也许,也是最重要的一步)。打开config.py文件,按照下面的说明进行补充。
配置文件由一个叫做CONFIG的Python变量组成。CONFIG是一个Python列表(由[]封装)。它包含一个特征类别的列表,按照它们需要被堆叠的顺序。这里的顺序是非常重要的。下面是一个配置样本:
CONFIG = [
{
'id': 1,
'name': 'background',
'directory': 'Background',
'required': True,
'rarity_weights': None,
},
{
'id': 2,
'name': 'body',
'directory': 'Body',
'required': True,
'rarity_weights': 'random'
},
{
'id': 3,
'name': 'eyes',
'directory': 'Expressions',
'required': True,
'rarity_weights': None
},
{
'id': 4,
'name': 'head_gear',
'directory': 'Head Gear',
'required': False,
'rarity_weights': None
},
{
'id': 5,
'name': 'clothes',
'directory': 'Shirt',
'required': False,
'rarity_weights': None
},
{
'id': 6,
'name': 'held_item',
'directory': 'Misc',
'required': True,
'rarity_weights': None,
},
{
'id': 7,
'name': 'hands',
'directory': 'Hands',
'required': True,
'rarity_weights': None,
},
{
'id': 8,
'name': 'wristband',
'directory': 'Wristband',
'required': False,
'rarity_weights': [100, 5, 5, 15, 5, 5, 15, 15, 5, 1]
},
]每个特征类别都被表示为一个Python字典(由{}封装)。所有需要做的就是在 CONFIG 列表中按顺序定义这些特征类别字典。
一个特性分类字典有5个需要的键,它们是id、name、directory、required和rarity_weights。当创建一个新的层(或替换一个现有的层)时,要确保所有这些键都被定义了。
以下是每个键的方式,以便了解如何赋值:
- id: 层的编号。例如,如果身体是第二个需要堆叠的特征类别(或层),它的id将是2。请注意,层仍然必须按照正确的顺序定义。
- name(名称): 特性类别的名称。这可以是你定义的任何东西,它将出现在元数据中。
- directory(目录): 素材中包含该特定特征类别图像的文件夹名称。
- required(必须): 如果这个类别对每个图片都是必需的。某些特质类别(如背景、身体和眼睛)必须出现在每个头像中,而其他某些类别(如头饰、腕带或衣服)可以是可选的。我们强烈建议你将第一层的required值设置为true。
- rarity_weights(稀有性权重): 将决定特征有多常见(或罕见),请查看下一节以了解更多细节。
配置稀有性权重
rarity_weights键可以取三个值:None(无),random("随机"),或一个Python列表。
让我们逐一探讨每个值:
None(无)
如果你把rarity_weights的值设置为None,每个特征将被分配一个相等的权重。因此,如果你有5个特质,每个特质将出现在大约20%的头像中。
在required为False的情况下,将同样有可能完全没有得到那个特定的特征。在前面的案例中,如果required属性被设置为false,那么每个特质将出现在大约16.6%的头像中。另有16.6%的头像则不会有那个特定的特征。
random('随机')
将rarity_weights设置为'随机'(注意括号)将随机分配权重给每个类别。我们强烈建议你不要使用这个功能。最好使用平等分配或自定义稀有性。
列表
这可能是最常见的分配稀有度权重的方法。
首先要做的是到你的特征类别文件夹中,按名称对特征图像进行排序。例如,对Wristbands文件夹进行排序,我们会得到这个结果:
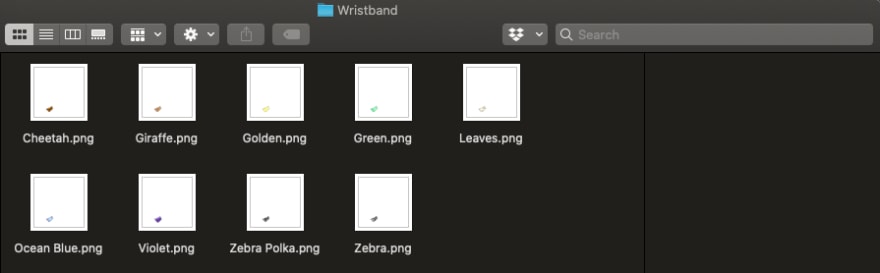
你可以看到,我们有9种不同的腕带。现在,我们需要定义一个Python列表(用[]封装),其中每个数字代表按升序分配给一个特定特征的权重。
如果required被设置为True,那么权重的数量应该等于该类别的特征的数量。如果required被设置为False,那么权重的数量应该等于特征的数量加1。
在我们的例子中,如果腕带是必须的,我们将在列表中定义九个权重,如果不是必须的,我们将定义十个权重。在后一种情况下,第一个权重将是与根本没有腕带相关的权重。
让我们看看我们为腕带定义的rarity_weights。
[100, 5, 5, 15, 5, 5, 15, 15, 5, 1]由于腕带不是必须的,我们设置了十个权重(九个加一个)。第一个权重是与根本没有腕带相关的权重。第二个权重与Cheetah带相关,第三个权重与Giraffe带相关,以此类推。注意这里的字母顺序。
权重越高,某一特征就越常见。例如,Cheetah的权重是5,而没有带的权重是100。这意味着拥有Cheetah带的情况比没有带的情况要稀少20倍。
生成集合
一旦你配置好了config.py文件,现在是时候生成你的集合了。打开你的终端(或命令提示符),定位到generative-art-nft文件夹(使用cd命令)。
现在,运行以下命令:
python nft.py运行该命令将启动图像生成程序。它首先会检查config.py文件是否有效。接下来,它将告诉你不同的可能组合的总数。
然后它会问你想创建多少个头像。我建议比你想创建的多20%,这样即使在删除了重复的头像后,你还有很多剩余的。在我们的案例中,我们选择创建12,000个头像,尽管我们想要10,000个。然后,它将要求你命名集合,然后开始生成过程。
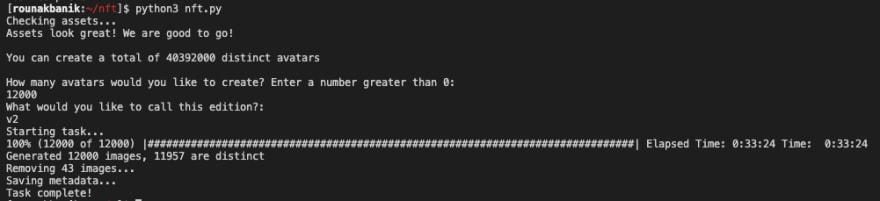
我花了大约30分钟生成了11,957个头像(在去除重复部分后)。这些图像及其相关的元数据将在输出文件夹中提供。
图像文件夹将看起来像这样(注意,这只是一个样本,而不是我们最终生成的松鼠)。
元数据文件是一个CSV文件,你可以将其导入Excel并进行分析(比如哪个特征是最稀有的,哪个特征组合是最常见的,头像稀有度排名,等等)。
结语
你已经生成了你自己的头像集。
那么我们现在准备好启动下一个大的NFT项目了吗?你还需要把这些图片上传到IPFS,并为它们制作成NFT,这是下一篇教程的内容。
本翻译由 Duet Protocol 赞助支持。





