通过逆向和调试理解EVM #2 :部署智能合约
- 翻译小组
- 发布于 2022-10-24 15:31
- 阅读 7794
如何调试EVM智能合约 2 :部署智能合约
本文是关于通过逆向和调试理解EVM系列的第2篇,本系列包含 7 篇文章:
- 第1篇:理解汇编
- 第2篇:部署智能合约
- 第3篇:存储布局是如何工作的?
- 第4篇:结束/中止执行的5个指令
- 第5篇:执行流 if/else/for/函数
- 第6篇:完整的智能合约布局
- 第7篇:外部调用和合约部署
在第二部分(本文)中,我们将分析当你在区块链中部署一个智能合约时发生了什么,例如,在点击remix中的 "部署 "按钮时。
下面是我们要部署的合约示例:
pragma solidity ^0.8.0;
contract Test {
uint balance;
constructor() {
balance = 9;
}
}在深入学习本教程之前,不要忘记:
- 打开你的电脑并启动remix。
- 启动优化器,runs 为1,它可以帮助编译器产生更有效的代码。(点击 "高级配置 "和 "启用优化")
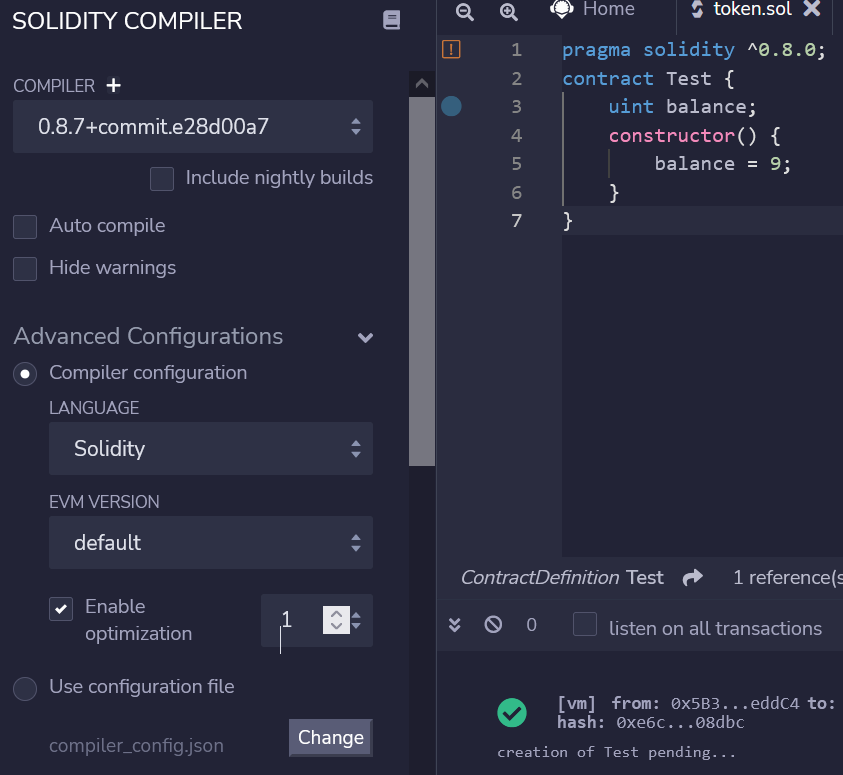
- 使用solidity版本0.8.7编译上述代码。(其他版本可能会产生稍微不同的代码)
- 在JavaScript EVM中部署智能合约(使用最新版本:London)
1. 开始调试
简要提示,要调试一个交易,必须在部署智能合约后按下面的 "调试 "按钮。

所有的调试信息都位于屏幕的左边,你可以看到堆栈、局部变量、状态、内存、存储、反汇编等等。
但是在开始调试之前,你能不能回答这个问题:
问:智能合约部署后,我们要调试的代码在哪里?
答:代码位于数据字段。代码位于交易的数据字段中,它就是在部署智能合约时要执行的代码。他的作用是在区块链上部署智能合约并执行构造函数。
现在,我们可以继续了。
默认情况下,调试器显示的是第17字节的构造函数代码,为了了解第17字节之前的代码,让我们点击下图中的左箭头。
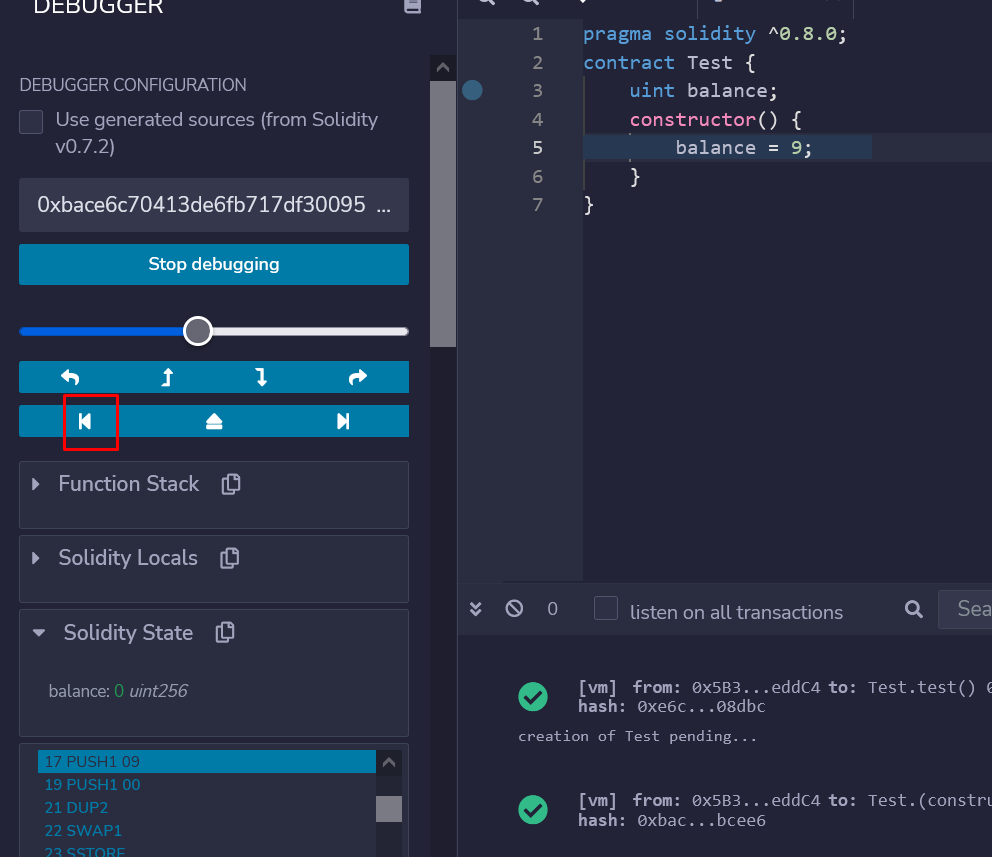
因此,我们回到第0字节。
000 PUSH 80 | 0x80 |
002 PUSH 40 | 0x40 | 0x80 |
004 MSTORE ||我们已经知道了前3条指令。
它将0x80存储在EVM内存的地址0x40,相当于内联汇编:
mstore(0x40,0x80)这是空闲内存指针,别担心,我们稍后会讲到这部分:)
接下来的操作码也已经知道了(参考本系列的第一篇)。
005 CALLVALUE |msg.value|
006 DUP1 |msg.value|msg.value|
007 ISZERO |0x01|msg.value|
008 PUSH1 0f |0x0f|0x01|msg.value|
010 JUMPI |msg.value|
011 PUSH1 00 |0x00|msg.value| (if jumpi don't jump to 0f)
013 DUP1 |0x00|0x00|msg.value|
014 REVERT
015 JUMPDEST基本上,它通过CALLVALUE操作码获得msg.value的值(发送到合约的以太币),如果返回值严格地大于0,则回退。
我们在本系列的第一篇中详细解释了发生了什么。
它等同于:
if (msg.value > 0) { revert() }由于我们的构造函数是不支付的,所以我们不能发送正常的资金! 事情与第一部分相同,至少到第14个字节为止。
2. 继续深入
现在发生了什么?
函数签名在哪里?我们的函数中心在哪里?当然不见了,在部署的时候,除了构造函数之外,没有任何可用的函数!
15 JUMPDEST |0x00|
16 POP ||
17 PUSH1 09 |0x09|
19 PUSH1 00 |0x00|0x09|
21 SSTORE ||在第16个指令,EVM弹出堆栈中的剩余值(0)。
之后我们把9和0推到堆栈中,并调用SSTORE,堆栈现在是:
|0x00|0x09|。
SSTORE操作码将Stack(1)存储到Stack(0)槽中(顾名思义)。(所以它使用了2个参数,因此在执行SSTORE的第21指令后,它们被从堆栈中移除了)
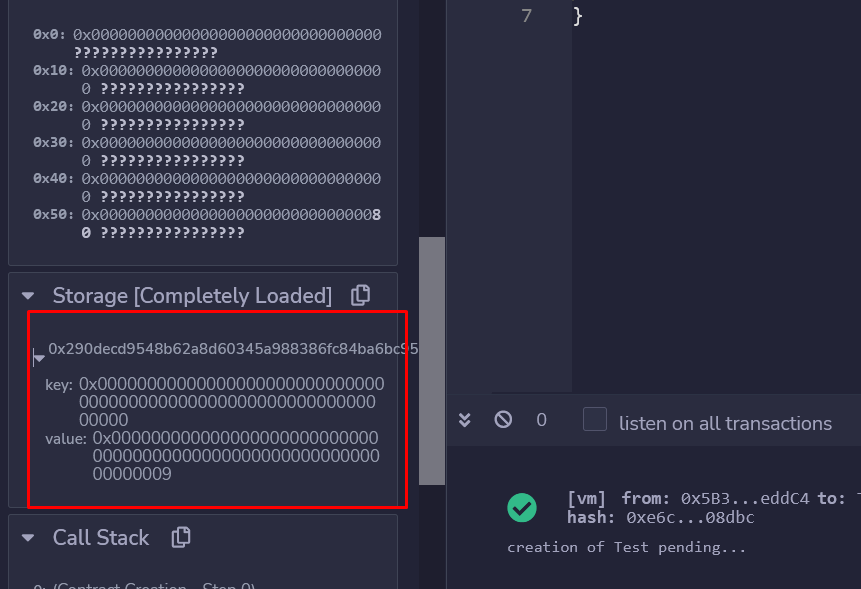
此时,EVM在第一个槽(槽号为0)中存储数值9,这相当于内联汇编:
sstore(0x00,0x09)这正是我们构造函数中的代码:
balance = 9它在变量 "balance"中存储了9,但是balance位于存储中。
由于balance是智能合约中第一个声明的变量,这意味着分配给 "balance"是第一个存储槽(slot 0)。你可以在 "存储(Storage)"部分看到这一点:
当合约部署时,在EVM中执行的代码是非常短的,我们已经到达了终点,也就是第32字节! (使用类似于STOP的REUTRN操作码)
22 PUSH1 3f |0x3f|
24 DUP1 |0x3f|0x3f|
25 PUSH1 22 |0x22|0x3f|0x3f|
27 PUSH1 00 |0x00|0x22|0x3f|0x3f|
29 CODECOPY |0x3f|
30 PUSH1 00 |0x00|0x3f|
32 RETURN ||堆栈现在在第21字节是空的(因为SSTORE不在堆栈中保留两个参数)
3f 被推入堆栈并重复,| 0x3f |之后推入22和00,在第27个指令堆栈现在是:| 0x00 |0x22 |0x3f |0x3f | 。
如果我们看一下文档,我们会发现CODECOPY是一个特殊的操作码,它可以EVM内存中复制当前智能合约代码。

它需要3个参数:
- 第一个是Stack(0),指令复制当前智能合约代码到EVM内存的Stack(0) 位置(这里Stack(0)=0),所以它将复制到内存的0x00槽。
- 更确切地说,复制智能合约代码从Stack(2)个字节到Stack(2)+Stack(1)个字节。 看一下堆栈,这是位于0x22(=34的十进制)和(22+3f=61,即97的十进制)之间的代码。
事实上,在执行这条指令后,如果我们在调试器中查看EVM的内存状态,会发现内存从0x00到0x3f被填满。
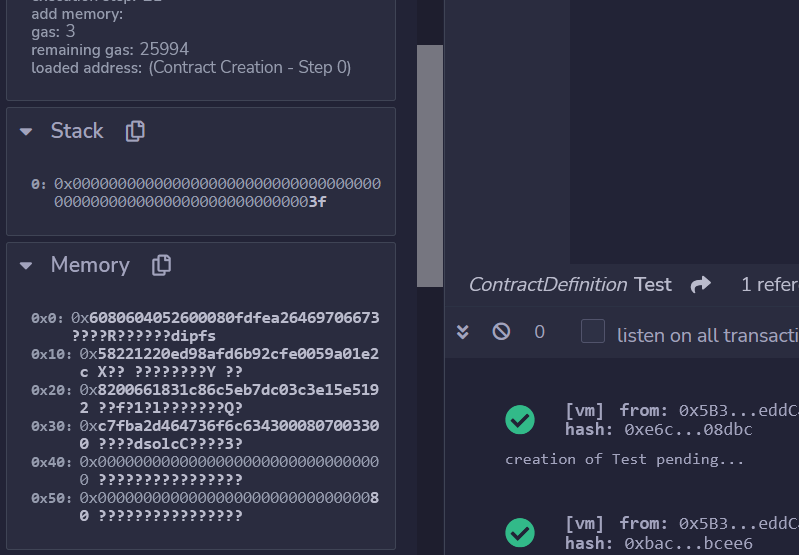
这是我们存储在EVM内存中的智能合约的代码。因此,交易数据的第0x22字节(十进制 34)之后的每一整块字节都是智能合约的代码!
第32个指令,RETURN被调用,参数为Stack(0) = 0x00和Stack(1) = 0x3f。
RETURN停止代码的执行,并返回内存[Stack(0):Stack(0)+Stack(1)],这是[0x00:0x40]。
返回的这个值是存储在区块链中的。在我们的例子中,这就是智能合约的代码!。
总结一下这第一部分,这是为了在区块链中部署智能合约而执行的交易数据:
The code which deploy the smart contract (byte 0 to 33)
6080604052348015600f57600080fd5b506009600055603f8060226000396000f3fe-----------
The deployed smart contract (byte 34 to 97)
6080604052600080fdfea264697066735822122018fba077a8095159cac22a23ec0b3172b5ab77a14a3cf44bc3107e4049b7dcf264736f6c63430008070033
--------------现在你知道当你在区块链上部署一个智能合约时,EVM中到底发生了什么,这真是太棒了!
3. 使用payable构造函数
如果把构造函数写成可支付的(payable)呢?有什么不同吗?让我们来看看!
这是我们的新智能合约,与之前的智能合约差别不大,我们只是在构造函数中加入了 "payable"的修饰(不要改变设置, solidity: 0.8.7, optimizer: 1)
pragma solidity ^0.8.0;
contract Test {
uint balance;
constructor() payable {
balance = 9;
}
}不要忘记在部署时向智能合约发送1个以太币,在”value“域中选择以太币(如下图)。
下面是交易的完整拆解(只有20个字节):
00 PUSH1 80
02 PUSH1 40
04 MSTORE
05 PUSH1 09
07 PUSH1 00
09 SSTORE
10 PUSH1 3f
12 DUP1
13 PUSH1 16
15 PUSH1 00
17 CODECOPY
18 PUSH1 00
20 RETURN我想你已经认出了这段代码,没有必要显示堆栈。
我们的空闲内存指针仍然被设置,但之后并没有对msg.value进行任何验证,EVM直接进入构造器代码,随后复制/返回智能合约代码,这些代码将被部署到区块链上。
唯一的区别是,在第13行写的是PUSH 16,而不是push 22。
这是因为该交易是13个字节的大小。(0x20-0x13的十六进制= 32-19=13的十进制)然后EVM不是从35字节开始复制代码,而是从22字节开始,因为要部署的智能合约代码就在构造器的执行之后。
还要注意的是,汇编代码要短得多,但Gas成本是差不多的:89228 (没有 payable时) 对比89036(少188个Gas)。
4. 向构造函数添加参数
由于可支付和 "不可支付"的构造函数之间没有很大的区别,让我们继续前进!为什么不在构造函数中添加新参数呢?
让我们部署这个智能合约,参数a=1,b=2,msg.value=1 ether,设置与之前一样(启用优化器, runs设置为1,solidity 0.8.7)。
pragma solidity ^0.8.0;
contract Test {
uint balance;
constructor(uint a,uint b) payable {
balance = 9;
}
}在观察了调试标签后,字节0到4显然与期望的一样的相同。
提示:每个solidity智能合约都由mstore(0x40,0x80)开始,也就是十六进制的0x6080604052。
现在的输出略有不同:
005 PUSH1 40 |0x40|
007 MLOAD |0x80|
008 PUSH1 98 |0x98|0x80|
010 CODESIZE |0xd8|0x98|0x80|
011 SUB |0x40|0x80|MLOAD从内存中加载Stack(0)位置的值到堆栈,在内联汇编中是MLOAD(0x40)。因此80被推送到堆栈。(因为80在之前被存储在内存0x40处)
之后EVM推送98,堆栈现在是| 0x98 | 0x80 |。
CODESIZE不从堆栈中获取任何参数,但在堆栈中保存代码的大小,如果我们检查堆栈,我们应该看到堆栈中的新值是0xd8。(如果你编译了完全相同的代码,设置与我相同,因此代码的长度将是相等的)
它是执行的代码的大小(因此这也是交易数据的大小,因为如前所述,要执行的代码位于交易数据中),现在堆栈是:
| 0xd8 | 0x98 | 0x80 |。
调用SUB操作码,执行Stack(0)-Stack(1),现在的堆栈是
| 0x40 | 0x80 |。事实上,d8-98=40(十六进制)。
012 DUP1 |0x40|0x40|0x80|
013 PUSH1 98 |0x98|0x40|0x40|0x80|
015 DUP4 |0x80|0x98|0x40|0x40|0x80|
016 CODECOPY |0x40|0x80|在一系列的PUSH和DUP之后,CODECOPY在字节16处复制智能合约中执行的代码,下面是CODECOPY指令的参数(destOffset,offset,size)。 - Stack(0) 复制代码到哪个内存位置。 - Stack(1) 开始复制代码时,在已执行的代码中的偏移量(从哪个位置开始复制)。 - Stack(2) 要复制多少字节的代码?
所有在0x98和0x98+0x40之间的代码被复制到内存的0x80槽中。
你看到内存中的差异了吗?

我们看到,32字节的插槽memory[0x80:0x99]现在包含了第一个参数。(为1)
同样,memory[0xa0:0xbf]也包含了第二个参数。(为2)
因此,这段代码(从第5个指令到第16个指令)的目的是将构造函数的参数复制到内存中!
当你部署一个智能合约时,交易中只有两个字段是必须的(除了签名),那就是字段from和data。"from"包含你的地址,data包含智能合约代码(以及部署智能合约的代码,我们在这里分析)和参数。
下面是一个例子:
{
from: "0x1234....."
data: "[code to execute when deploying smart contract] [smart contract code to deploy] [constructor parameters]
}参数位于所有智能合约代码的数据之后(并以32字节编码,即16进制的0x20)。
注意,0x40的空闲内存指针不应该是0x80,因为0x80的内存不再是空闲的。
现在由于0x80是使用的,它包含了2个参数。当内存被释放时,0x40应该指向0xc0。
这就是17和23之间的代码的目的(它把40加到前面的
017 DUP2 |0x80|0x40|0x80|
018 ADD |0xc0|0x80| add 0x40 to 0x80 (previous free memory pointer loaded at byte7)
019 PUSH1 40 |0x40|0xc0|0x80| push 40 in the stack
021 DUP2 |0xc0|0x40|0xc0|0x80|
022 SWAP1 |0x40|0xc0|0xc0|0x80|
023 MSTORE |0xc0|0x80| store the result of the addition in 0x40 in memory空闲内存指针的目的只是指向内存中的一个空闲槽,每当内存使用这个槽时,指针就会改变到另一个空闲地址。让我们继续往下看。
024 PUSH1 1e |0x1e|0xc0|0x80|
026 SWAP2 |0x80|0xc0|0x1e|
027 PUSH1 29 |0x29|0x80|0xc0|0x1e|
029 JUMP |0x80|0xc0|0x1e| jump to 0x29 (41 in hex)代码无条件跳转到0x29(Dec中的41)
加载到堆栈中
让我们把注意力集中在代码的第三部分,因为参数1和2已经加载到内存中。
041 JUMPDEST |0x80|0xc0|0x1e|
042 PUSH1 00 |0x00|0x80|0xc0|0x1e|
044 DUP1 |0x00|0x00|0x80|0xc0|0x1e|
045 PUSH1 40 |0x40|0x00|0x00|0x80|0xc0|0x1e|
047 DUP4 |0x80|0x40|0x00|0x00|0x80|0xc0|0x1e|
048 DUP6 |0xc0|0x80|0x40|0x00|0x00|0x80|0xc0|0x1e|
049 SUB |0x40|0x40|0x00|0x00|0x80|0xc0|0x1e|
050 SLT |0x00|0x00|0x00|0x80|0xc0|0x1e|
051 ISZERO |0x01|0x00|0x00|0x80|0xc0|0x1e|
052 PUSH1 3b |0x3b|0x01|0x00|0x00|0x80|0xc0|0x1e|
054 JUMPI |0x00|0x00|0x80|0xc0|0x1e|
055 PUSH1 00
057 DUP1
058 REVERT在用调试器分析了这个汇编后(在字节41和54之间),智能合约计算c0-80并验证它是否等于40。
如果减去的数字不相等,EVM就会回退,否则执行流程继续,EVM跳转到3b(十进制的59)。
80和c0是存储在内存中的2个参数的开始偏移和结束偏移。(即1和2)
由于EVM是按32个字节为一组工作的(十六进制为20)。我们的目的只是为了验证在构造函数中确实有2个参数被加载到内存中(总长度为40,十六进制)。通过将参数的结束偏移量减去内存中参数的开始偏移量。
如果不是这样,那么这意味着交易中的参数少于2个。所以EVM通过不跳转到59来还原指令55和58之间的情况
接下来在指令(我们的最后一段代码):
059 JUMPDEST |0x00|0x00|0x80|0xc0|0x1e|
060 POP |0x00|0x80|0xc0|0x1e|
061 POP |0x80|0xc0|0x1e|
062 DUP1 |0x80|0x80|0xc0|0x1e|
063 MLOAD |0x01|0x80|0xc0|0x1e| the first argument was loaded.
064 PUSH1 20 |0x20|0x01|0x80|0xc0|0x1e|
066 SWAP1 |0x01|0x20|0x80|0xc0|0x1e|
067 SWAP2 |0x80|0x20|0x01|0xc0|0x1e|
068 ADD |0xa0|0x01|0xc0|0x1e| add 20 to the offset in memory to load.
069 MLOAD |0x02|0x01|0xc0|0x1e| Our 2 arguments were loaded.
070 SWAP1 |0x01|0x02|0xc0|0x1e|
071 SWAP3 |0x1e|0x02|0xc0|0x01|
072 SWAP1 |0x02|0x1e|0xc0|0x01|
073 SWAP2 |0xc0|0x1e|0x02|0x01|
074 POP |0x1e|0x02|0x01|
075 JUMP |0x02|0x01| Swap stack to jump top 0x1e (30 in dec)在堆栈中弹出2个0x0后,我们在第61指令的堆栈中留下了| 0x80 | 0xc0 | 0x1e |。
EVM复制了80,并使用MLOAD在Stack(0)处加载,加载在80处内存数据,这是我们之前复制到内存的构造函数中的第一个参数。(即1)
现在由于我们加载的每一个值,都在堆栈中。
接下来,在指令64处,我们需要加载第二个参数,因为EVM是按32个字节(20)的十六进制分组工作的,EVM必须在80+20=a0处加载内存,以获得第二个参数。
这就是为什么EVM在堆栈中推入20,并在堆栈中交换一些数值,以使80成为第一个。
EVM在指令68处加上这两个数字,等于a0,并将它们加载到堆栈中。
总结一下,这段代码加载了存储在内存中的2个参数。
mload(0x80)
mload(0xa0)之后,EVM跳转到指令30,堆栈中有1和2,EVM继续执行,将余额设置为9(在第30和40指令之间执行构造函数)并将合约代码复制到区块链中。(在第76和89指令之间)
请注意,2个参数在第31和32指令之间被构造函数弹出了,因为我们在代码中没有使用它们 :)
030 JUMPDEST |0x02|0x01|
031 POP |0x01|
032 POP ||
033 PUSH1 09 |0x09|
035 PUSH1 00 |0x00|0x09|
037 SSTORE ||
038 PUSH1 4c (76 in dec)
040 JUMP
076 JUMPDEST
077 PUSH1 3f
079 DUP1
080 PUSH1 59
082 PUSH1 00
084 CODECOPY
085 PUSH1 00
087 RETURN.... 我们完成了! 智能合约结束了它的执行。
总结
最后总结一下合约部署情况:
-
它像每个智能合约一样存储了空闲内存指针。
-
它复制了由交易数据提供的2个参数,并将其存储到内存中。
-
它验证了我们在构造函数中至少输入了2个参数。(不能少)
-
它将内存中的2个参数复制到堆栈中。
-
它通过设置余额为9来执行构造函数。
-
它将代码复制到内存中并停止执行。
今天的工作已经很多了,但别担心,这个系列还没有结束。
本翻译由 Duet Protocol 赞助支持。



