深入了解 Solidity - 堆栈
- 翻译小组
- 发布于 2023-02-20 15:09
- 阅读 7242
探讨 EVM 堆栈机器,以及如何在堆栈中推入和弹出数据
探讨 EVM 堆栈机器,以及如何在堆栈中推入和弹出数据

图片来源:Iva Rajović on Unsplash
这是"深入Solidity数据存储位置"系列的第四篇,其他三篇:
在今天的文章中,我们将看一下EVM的第四个数据位置:堆栈。在Solidity中,其实我们一直在使用它,当我们给变量赋值时,就是使用到堆栈,但是 EVM 的堆栈是如何在内部工作的?
我们将看到EVM堆栈的布局,以及哪些操作码被用来与它进行底层次的交互。然后我们将解释什么是块作用域(被大括号{ }包裹的代码块),它们是如何工作的,它们的好处,以及如何在Solidity中使用它们。
最后,我们将深入讨论不受欢迎的 "堆栈太深(stack too deep)"错误。与其说我们在研究避免这个错误的技巧,不如说我们将研究如何重构你的代码以最小化堆栈项目并防止这个错误。
简介
在深入研究EVM堆栈的特性之前,我们需要了解虚拟机架构的一些基本知识。
虚拟机(VM)是在本地操作系统之上的一个高级抽象。它模拟了一个物理机,并使其能够在多个操作系统和硬件架构上运行同一个平台。
有两种主要类型的虚拟机架构:
- 基于寄存器的虚拟机
- 基于堆栈的虚拟机
这两种架构的主要区别如下:
- 在执行汇编语言定义的指令时,虚拟机如何存储、检索和使用参数(例如,算术运算的操作数)。
- 用来存储这些参数的数据结构不同
基于寄存器的虚拟机
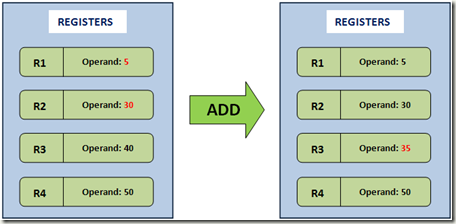
基于寄存器的虚拟机使用注册表来存储操作数。
可以把注册表的数据结构看作是一种 "字典(map)的形式"。
- 键是注册表的地址。
- 值是我们存储的值(例如,一个算术操作的操作数)。
执行一些计算的指令,如算术运算,需要包含注册表地址,以便从中获取参数。
基于寄存器的虚拟机的一些流行的例子是:
- Erlang VM:BEAM
- Lua 虚拟机
- Dalvik VM
因为基于注册表的虚拟机使用注册表来存储数值,这意味着作为指令参数的数值用地址"显示(explicitly)"。
VM指向特定的注册表地址来检索参数。
注意:这里的术语 "显式 "对于理解与堆栈机的区别很重要。
基于堆栈的虚拟机
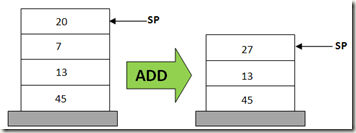
堆栈机使用一个堆栈作为数据结构来存储操作数。
操作是通过从堆栈中弹出数据,进行处理,并将结果推回堆栈中来完成的。这些操作通常使用PUSH和POP指令进行。
这意味着推入堆栈的最后一个项目总是第一个被弹出堆栈的项目。这种机制被称为LIFO(Last in, First Out)。
在软件世界中,一些流行的虚拟机例子是:
- Java虚拟机
- 微软.NET架构,代码被编译成CLR(通用语言运行时)的中间语言
基于堆栈的虚拟机模型通过堆栈指针隐含地处理操作数。与基于寄存器的机器不同,虚拟机不需要知道操作数所在的 "地址"。
默认情况下,虚拟机采取堆栈的顶部来检索参数。
EVM的堆栈
EVM是一个基于堆栈的虚拟机。除了使用基于堆栈而不是寄存器的虚拟机,这对EVM来说还意味着什么呢?
EVM上的所有基本计算都是在一个叫做堆栈(=stack frame)的数据区进行的。EVM使用一个256位”字“的机器,这有利于Keccak256哈希模式和椭圆曲线计算。
EVM堆栈的概述
当涉及到作为EVM数据位置的 "堆栈 "时,有五个主要特征需要记住。牢记这五个要点将有助于你调试函数调用,优化你的合约,并了解你正在编写的智能合约在低层的行为。
关于堆栈和Solidity有两个主要规则:
-
最便宜的使用数据位置(在所有其他位置中)
-
堆栈只在函数范围内可用。
关于操作 "堆栈 "数据位置,有三个主要规则:
- EVM使用四个基本操作码来操作堆栈:
PUSH,POP,SWAP和DUP。 - 其他操作码参数总是取堆栈中最顶层的项目。
- 与 "storage(存储)"、"memory(内存)"和
calldata相关的操作码使用与每个数据位置相关的操作码从这些数据位置加载数值到堆栈中。
EVM的堆栈框架只在函数范围内可用。
由于EVM是一个基于堆栈的机器,堆栈是EVM的主要工作空间。所有从 "storage(存储)"、"memory(内存)"或 "calldata "加载的东西都是使用与每个数据位置相关的操作码(SLOAD用于存储,MLOAD用于内存,CALLDATALOAD用于calldata)加载到堆栈。
基本的堆栈操作码:PUSH, POP, SWAP, 和 DUP
EVM使用下列操作码来操作堆栈上的数据:
POP:移除堆栈顶部的第一个项目。PUSH:在堆栈顶部推送一个项目。PUSH指令可以是PUSH1...PUSH32,指示将1字节到32字节推到栈上。DUP:指示复制第n个堆栈项并将其放在堆栈顶部,其中n可以是1到16。SWAP: 指示将堆栈顶部的项目与第n个项目交换,其中n可以是1到16。
操作码如何从堆栈中消费、如何返回参数到堆栈中
任何操作或操作码都会占用堆栈中最顶端的项目。一般来说,操作码从堆栈中取一个、两个或多个元素,这取决于指令。操作码的结果被推回到堆栈的顶部。
举例来说,CREATE操作码从堆栈中获取元素作为其参数来创建/部署一个新的合约,并返回新创建的合约在堆栈顶部的地址。
任何带参数的EVM操作码都会从堆栈的顶部获取这些参数。例如,操作码 ADD从堆栈的顶部取两个项目,并将结果推回堆栈中。
所以,总的来说:
只有堆栈的顶部是可以访问的。
注意:如果堆栈中可用于执行操作码的项目数量不足,因为操作码需要的参数多于堆栈中的可用参数,EVM将以 "堆栈溢出 "的异常停止工作。
例如,
ADD从堆栈中获取两个参数,但堆栈中只有一个项目可用。
堆栈的布局
本节描述了堆栈中可以存储多少数据,以及在堆栈中访问这些数据的规则。
当涉及到理解堆栈的布局时,有三个主要方面需要学习:
- 栈上的元素是 256 比特(一个字长)。
- 栈大小有限 = 堆栈最多可以容纳1024个元素。
- 只有堆栈中最上面的16个项目可以被访问。
特别是,这一节回答了我们大多数作为Solidity开发者对堆栈的困惑。
为什么堆栈可以有1024个元素的深度(最多可容纳1024个元素),但solidity却在16个时报告 "堆栈太深(stack too deep)"的错误?
栈上的数据布局

堆栈是由字组成的(不像memory或calldata是由连续的字节组成)。正如黄皮书中所描述的,EVM的字大小为256位。意味着堆栈上的每个字都有256位长(=32字节)。每个字的大端位于左侧。
这也将我们引向一个重要的问题。堆栈是一个填充的数据位置。我们将在另一节中介绍填充的规则。
栈上可以存储多少数据
EVM堆栈最多可以容纳1,024个元素。

如果一个额外的项目被推到堆栈上,并且超过了这个限制,EVM将以一个 "堆栈溢出" 的异常停止(在EVM.codes中重现这个错误)。
你可以在网上找到这个与 "最大深度"一词有关的1024个数字。但这绝不能与最大可访问深度相混淆。
如何访问堆栈上的元素?

我们在上一小节中看到,堆栈最多可以容纳1024个元素,这是一个相当大的数字。
然而,EVM只能访问堆栈中最上面的16个项目。
这在Solidity的文档中解释如下。
对堆栈的访问被限制在顶部,方式如下:可以将最上面的16个元素之一复制到堆栈的顶部,或者将最上面的元素与它下面的16个元素之一交换。
让我们对这句话进行解构和说明,以便更好地理解它。
除了最上面的一项,EVM可以通过复制(使用DUP操作码)或与堆栈上最上面的一项交换(使用SWAP操作码)来访问堆栈上最上面的16项中的一项。
让我们通过一些插图来看看这两个例子。
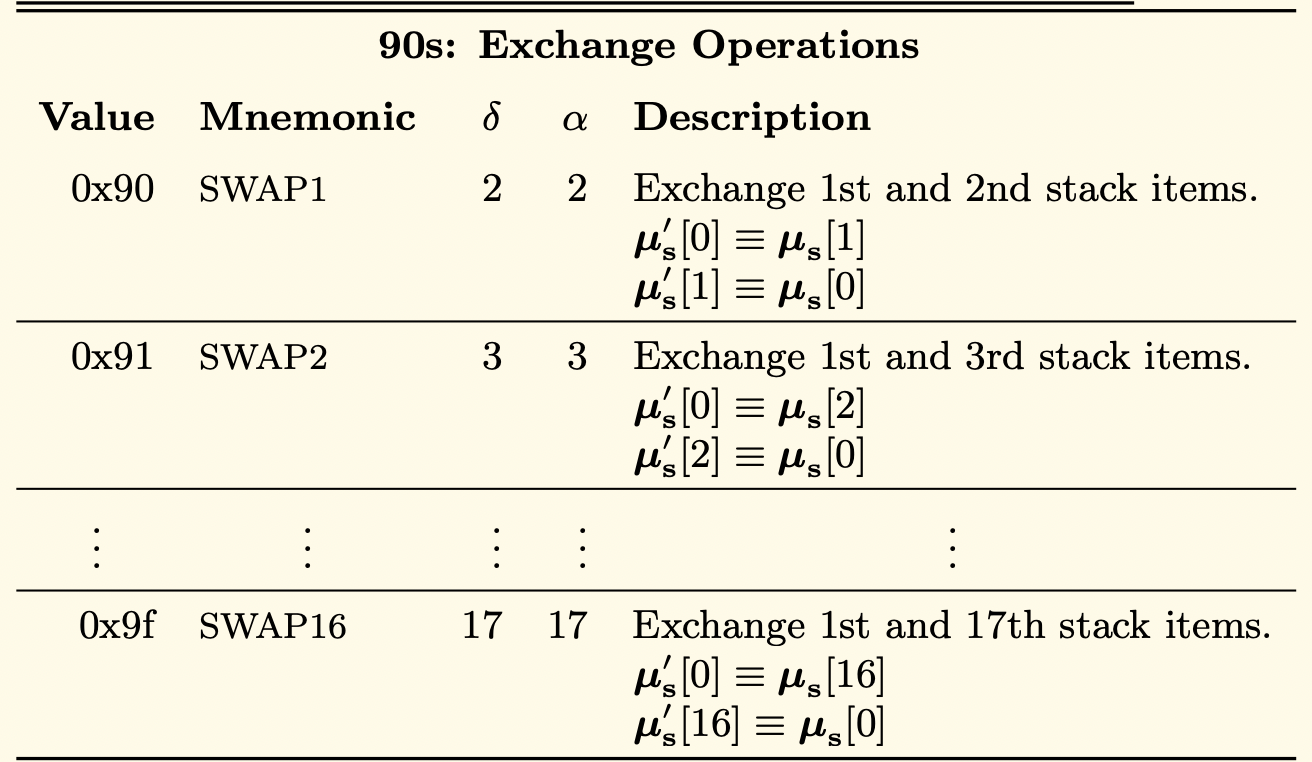
交换到从堆栈顶部开始的第16个元素
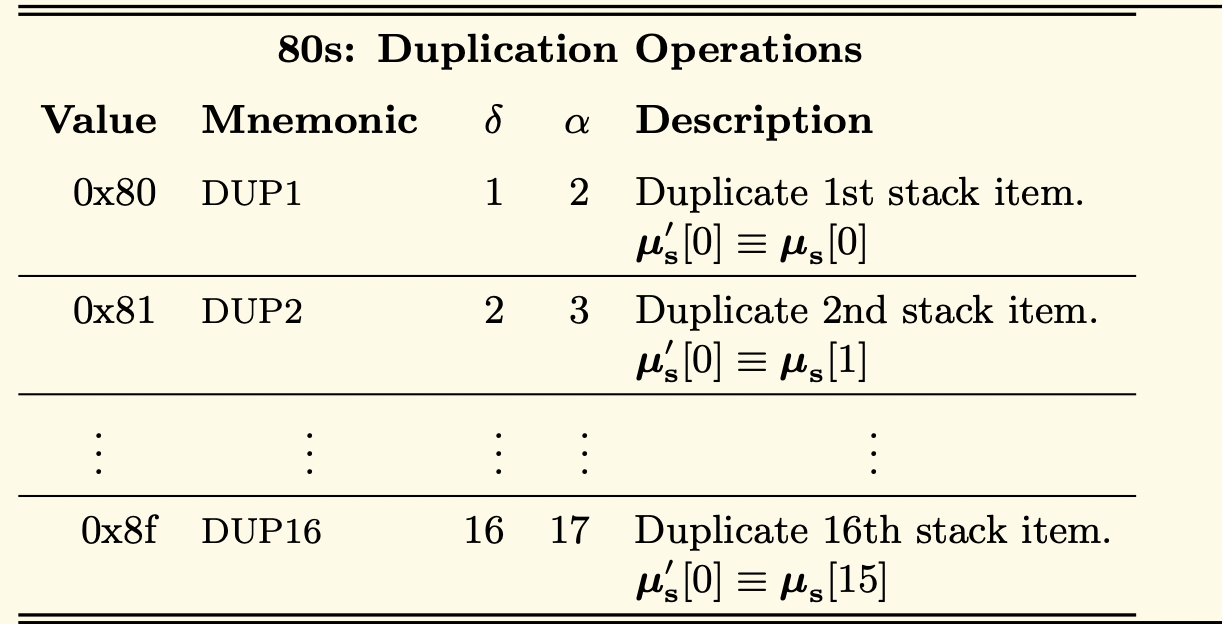
复制到堆栈顶部的第16个元素为止
注意:操作码
DUP和SWAP(必须有 1-16 编号)在内联汇编中不可用。
有什么变通方法可以访问超过第16个更深的元素?
可以将堆栈元素移动到存储或内存中,以获得对堆栈的更深的访问。但是,如果不首先从堆栈顶部移除元素,就不可能访问堆栈中更深的任意元素。
为了访问更深的元素,EVM必须使用POP操作码从堆栈中移除一些元素,或者在使用通过Yul IR的新代码生成管道时在内存中移动某些元素。
堆栈中的直接变量与指针类型
所有在函数中定义+分配的变量都存储在堆栈中。它们被称为局部变量。
但是有两种类型的变量可以存储在EVM堆栈中。
- 直接类型的变量
- 指针类型的变量,它们是对存储在其他数据位置(存储、内存或Calldata)的变量的引用。
存储在堆栈中的变量的填充规则
存储在堆栈中的值被填充(用0 扩展),这取决于Solidity类型(例如,address、bytesN、uintN,等等)。
我们之前已经涵盖了一个重要的观点:堆栈是一个被填充的数据位置。这意味着每个直接类型的变量(例如,address, uintN, bytesN, 等等)都被填充到堆栈中,占据一个完整的字。填充的内容根据类型的不同而不同。
bytesN是向右填充的。address,uintN是左边填充的。
外部函数类型的例外情况
外部函数在堆栈中占用了两个槽位。一个外部函数由一个20字节的地址和一个4字节的选择器表示。这些被存储在两个独立的字中,地址在底部的字中,选择器在顶部的字中。这两个字都是在左边置零,而不是[...




