理解智能合约元数据
- 翻译小组
- 发布于 2023-05-28 16:04
- 阅读 4601
理解智能合约字节码末尾的元数据
- 原文链接: https://www.rareskills.io/post/solidity-metadata
- 译文出自:登链翻译计划
- 译者:翻译小组 校对:Tiny 熊
- 本文永久链接:learnblockchain.cn/article…
当 solidity 为要部署的智能合约生成字节码时,会在字节码的末尾附加关于编译的元数据。这篇文章我们来了解一下这个字节码中包含的数据的含义。
一个简单的智能合约
让我们看看下面这个最简单的 Solidity 智能合约的编译器输出。
//SPDX-License-Identifier: MIT
pragma solidity 0.8.20;
contract Empty {
constructor() payable {}
}该合约实际上什么都没做。我们可以用solc --optimize-runs 1000 --bin C.sol来编译看查看原始字节码。我们得到以下输出:
======= C.sol:Empty =======
Binary:
6080604052603e80600f5f395ff3fe60806040525f80fdfea26469706673582212203082dbb4f4db7e5d53b235f44d3e38f839dc82075e2cda9df05b88e6585bca8164736f6c63430008140033对于一个什么都不做的合约来说,字节码似乎有点多,对吗?让我们了解一下这些字节码是什么。
当我们用solc --optimize-runs 1000 --bin --no-cbor-metadata C.sol编译代码时,我们得到以下输出:
======= C.sol:Empty =======
Binary:
6080604052600880600f5f395ff3fe60806040525f80fd这就小多了!那么,这些额外的信息是什么呢?
Solidity 元数据(Metadata)
默认情况下,solidity 编译器会在 "实际" initcode 的末尾添加元数据,当构造函数执行完毕后,这些元数据会被存储到区块链中。下面是 "额外"的代码:
fea26469706673582212203082dbb4f4db7e5d53b235f44d3e38f839dc82075e2cda9df05b88e6585bca8164736f6c63430008140033最后两个字节0033意味着 "向后看0x33字节,那是元数据"。这指的是前面的fe(也就是 INVALID 操作码)和后面的0033之间的所有代码。我们可以检查这确实是0x33字节。
# fe and 0033 are not included
>>>hex(len('a26469706673582212203082dbb4f4db7e5d53b235f44d3e38f839dc82075e2cda9df05b88e6585bca8164736f6c6343000814') // 2)
# '0x33'那么这个0x33(51位十进制)的字符串是什么呢?
如果我们对源代码做一个微小的、看起来无关紧要的改动,我们就可以得到一个提示。这个改动就是一个额外的注释。
//SPDX-License-Identifier: MIT
pragma solidity 0.8.20;
contract Empty {
// nothing
constructor() payable {}
}下面的截图是之前和之后的情况。
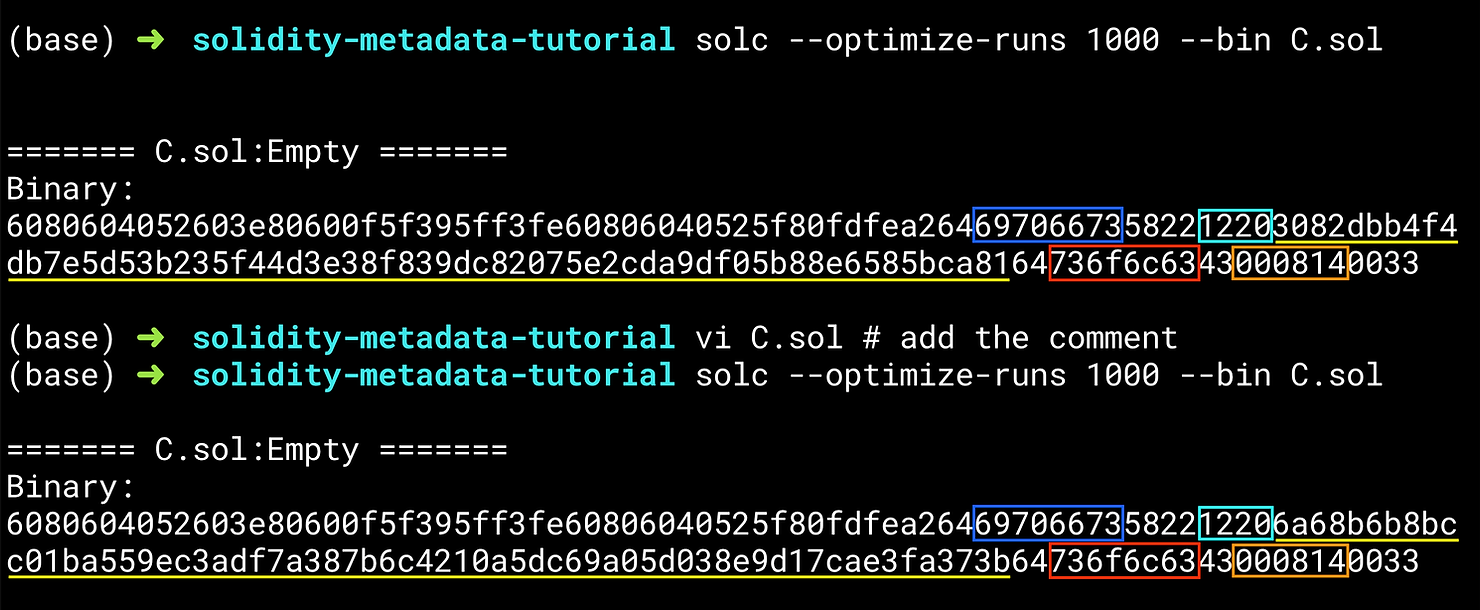
你可以看到,尽管代码功能没有改变,但下划线部分已经改变了。我们将在下一节解释方框内的代码。
解码元数据
一开始,我们似乎是在神奇地凭空选择一段字符,请耐心等待。
让我们来看看上面蓝框中的六位数:
>>> bytes.fromhex("69706673").decode("ASCII")
'ipfs'接下来让我们看看红框中的代码:
>>> bytes.fromhex("736f6c63").decode("ASCII")
'solc'这给了我们一个关于这个数据包含的线索:一个IPFS哈希值和solidity编译器版本。
IPFS 哈希值
黄色下划线的部分,以及绿松石色的方框可以放到下面的python脚本中(注意,我们使用的是//nothing的代码版本)。
import base58
hex_ipfs_hash = "12206a68b6b8bcc01ba559ec3adf7a387b6c4210a5dc69a05d038e9d17cae3fa373b"
bytes_str = bytes.fromhex(hex_ipfs_hash)
print(base58.b58encode(bytes_str).decode("utf-8"))
# QmVW2XyafSxDtiSqirJRauuT5SaQtGnQYsxxyYHrFmRTEaQm...RTEa是由编译器产生的元数据文件的IPFS哈希值。这一段代码(绿松石色和黄色)的编码方式与上面的方框不同。
具体来说,IPFS 哈希值(绿松石色和黄色)是十六进制数据 "1220...RTEa "的base58编码版本。
如果你把来自 Solidity 编译器的 JSON 文件放到 IPFS 上,这就是你将得到的 IPFS 哈希值。这里是相应的 JSON 文件:
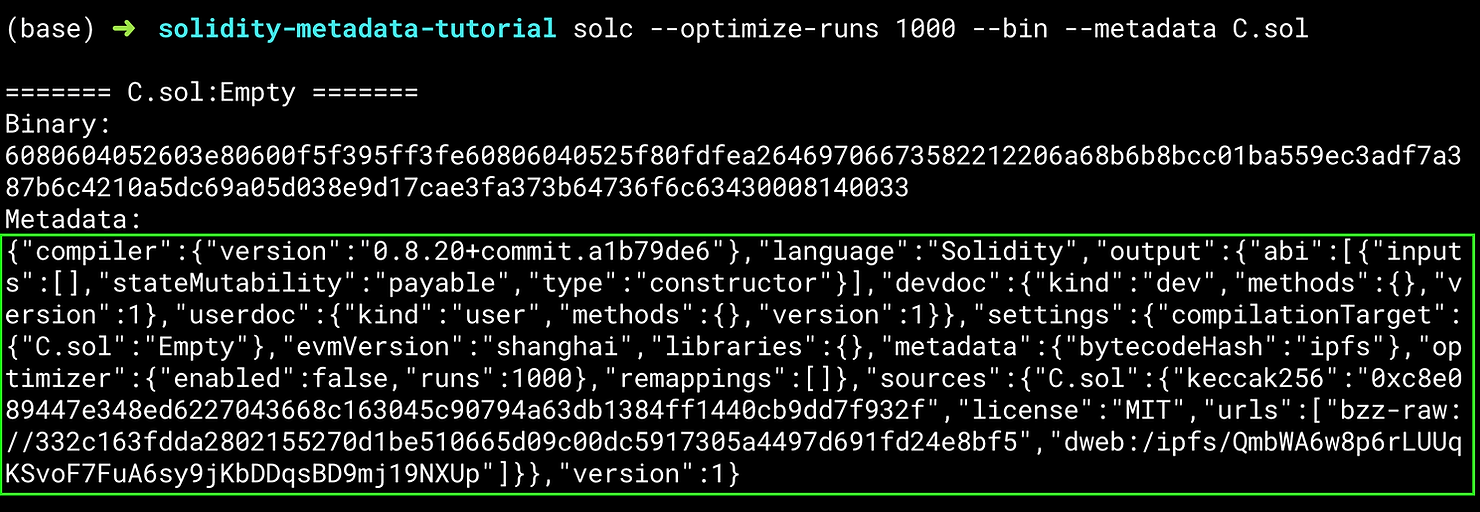
我们可以将 JSON 文件存储为一个实际的文件,然后验证哈希值是否与我们在上面的 python 中产生的哈希值一致。你将需要安装 ipfs 命令行工具(如何安装)。
mkdir out
solc --optimize-runs 1000 --bin --metadata C.sol --output-dir out
# Compiler run successful. Artifact(s) can be found in directory "out".
ipfs add -qr --only-hash out/Empty_meta.json
# QmVW2XyafSxDtiSqirJRauuT5SaQtGnQYsxxyYHrFmRTEa这与前面的哈希值相匹配。
这不会导致哈希值碰撞吗?
如果两个具有相同的源代码和编译器配置的合约将其验证的源代码存储在IPFS上,IPFS的哈希值会发生碰撞,但这是可取的,因为它实际上节省了存储空间。智能合约是由链ID和它们的地址组合来唯一识别的,而不是IPFS的内容。
获取 solidity 版本
最后,如果我们转换橙色框中的部分,我们会看到solidity版本:
>>> 0x00 # solidity is version 0
0
>>> 0x08 # major version
8
>>> 0x14 # minor version
20
# correct, we used solidity 0.8.20为什么智能合约需要元数据?
这个元数据给部署成本增加了53个字节,这意味着额外的10600个Gas(每个字节码200个)+ calldata成本(每个非零字节16个Gas,每个零字节4个Gas)。这意味着在calldata成本中最多有848个额外的Gas。
那么,为什么要包括它呢?
这使得智能合约代码能够得到严格的验证。编译器输出的元数据JSON包括源代码的哈希值。因此,如果源代码有一点变化,元数据JSON文件就会改变,其IPFS哈希值也会改变。
通过IPFS哈希值来降低Gas的一个奇怪的技巧
在部署时降低Gas成本的一个明显方法是使用--no-cbor-metadata选项。但是,如果你需要它来验证合约,那么你仍然可以通过挖掘IPFS哈希值来降低Gas成本,这些哈希值中有很多零字节。当合约被部署时,零字节将减少calldata的成本。因为源代码是Hash结果,包括注释,这意味着我们可以挑选注释,从而获得高效的IPFS散列,并将其附加到合约中。注意这意味着我们希望哈希值的十六进制表示有零,而不是base58的编码。
进一步的资源
你可以在相关的solidity 文档中看到操作该元数据的所有选项。
了解更多
请参阅我们的 Solidity Bootcamp 以了解更多高级智能合约主题
译者: 国内用户也可以学习 登链社区的区块链技术集训营
感谢 Chaintool 对本翻译的支持, Chaintool 是一个为区块链开发者准备的开源工具箱





