云原生托管 Subgraph 子图,开启稳定高效的自定义Indexer
- Chainbase
- 发布于 2023-08-17 17:59
- 阅读 6108
Subgraph 是 The Graph 去中心化应用索引协议的具体实现, 能为各个智能合约创建索引引擎,提供 dataset 数据集供开发者快速查询使用。目前,Chainbase 正式上线并托管的核心 dataset subgraph 数量已经超过 100+。
作者:Liquid
一、背景
对于一些具有复杂智能合约的项目 Uniswap 或者 BAYC(NFT),其所有数据都存储在链上,我们只能通过链上读取到基本的合约数据,比如某只 BAYC 猿猴的所有者、根据其 ID 获取猿猴的内容 URI 或总提供量。但没办法做进一步更高级的聚合、搜索、关系查询:例如,我们想查询某个地址所拥有的猿猴,并根据其中一个特征进行筛选,就没办法直接通过与链上合约交互来获得这些信息。要获得这些信息,我们需要开发一个后端程序从 0 区块开始处理合约发出的所有 transfer 事件,然后使用Token ID 和 IPFS 哈希值从 IPFS读取元数据,汇总和计算后才能得出。这里的后端程序就是 Subgraph。
Subgraph 是 The Graph 去中心化应用索引协议的具体实现, 能为各个智能合约创建索引引擎,提供 dataset 数据集供开发者快速查询使用。

二、挑战
随着区块链生态发展,构建 Subgraph 成为了开发者越来越喜欢的用来获取和提供区块链数据的关键工具,但由于每一个 Subgraph 都只对应一个特定的智能合约,为了满足不同用户和场景,需要构建和托管的子图数量也会逐渐变多,我们托管支持了生态中大部分核心 Subgraph,也在规模化托管时为现有框架和运维方式带来不少的问题和挑战:
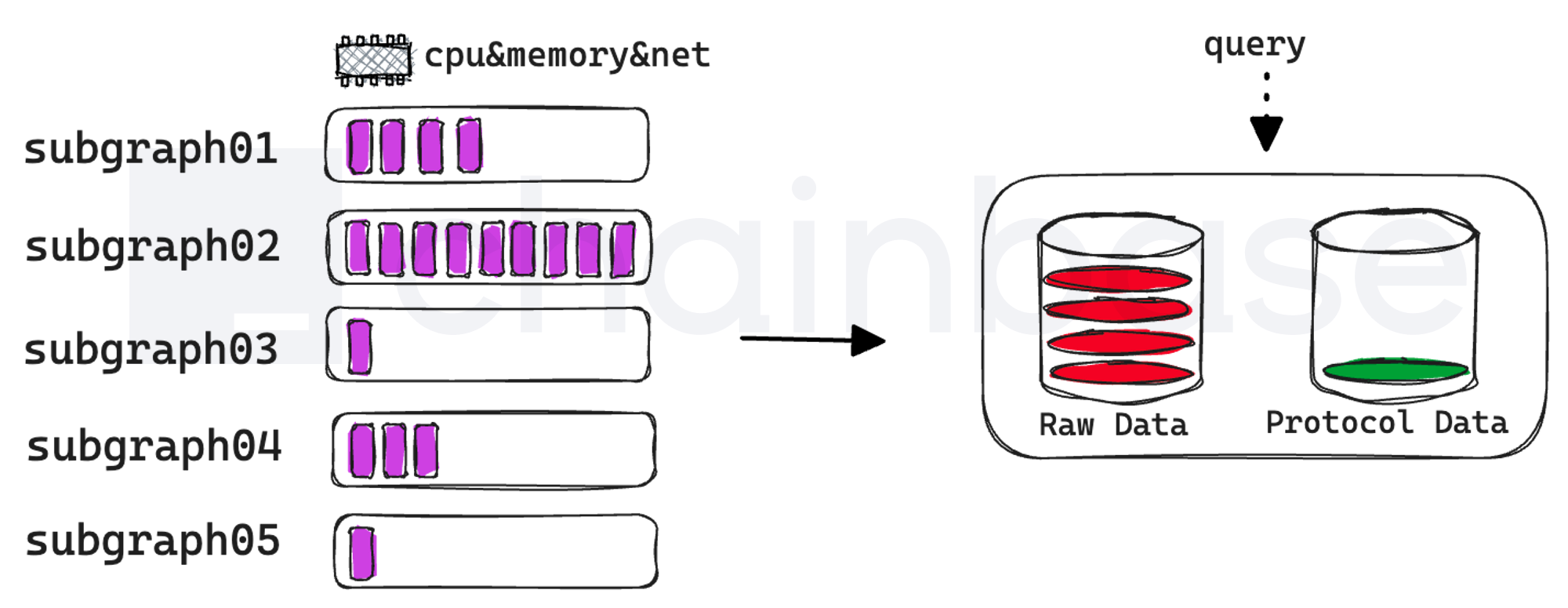
2.1 单体PostgreSQL数据库缓存大、读写不分离
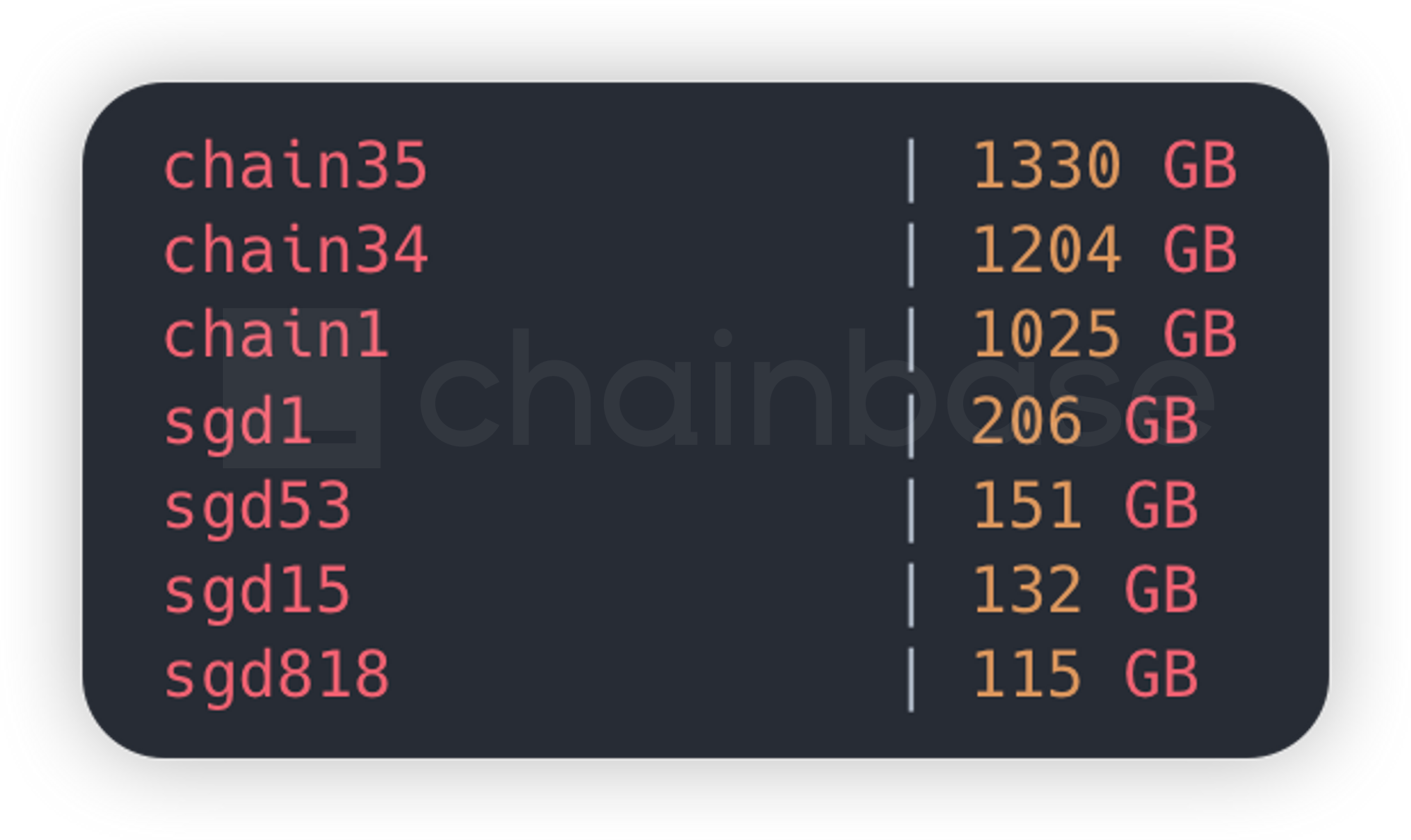
Graph Node 默认后端采用 PostgreSQL 作为关系型数据库,所有的子图共享一个数据库实例。并且会根据配置中指定的chains.provider强制缓存链上数据 Raw Data ,无法关闭。
如果在配置有多个provider 的情况下,数据库的大部分空间都会被Raw Data 占据,需要不断地进行数据库实例容量和 iops 扩容。最为致命的是随着数据库实例容量的增涨,会导致数据库的整体读写性能严重下降,最后不得不单独启动一个镜像只读数据库实例用于 query 请求读取,以降低查询延迟。如果每个 subgraph 都启动一个实例,会面临每个数据库都会缓存一份完整 Raw Data 的问题,造成严重的数据冗余和资源浪费。
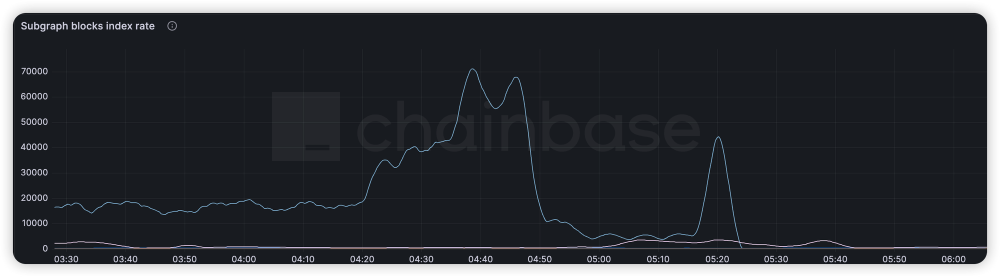
2.2 Subgraph子图任务资源易被抢占、资源不易扩展
在子图刚部署上线时,子图会从设置好的startBlock开始索引,由于前部分合约交易量小,索引速度相对较快,资源消耗少;但是到核心交易区块时,交易量增大,events 事件增多导致索引慢,资源消耗多。而单节点部署的 Graph Node 整体资源受限于部署的物理机资源,物理机资源利用率经常会出现波峰和波谷,导致在子图需要资源时无法及时扩容,在子图索引到最新区块后不需要过多资源时又无法缩容。
2.3 多个子图混部后监控日志难以区分
同一个 node 部署多个 Subgraph 后,子图的所有debug、info、warn、error 日志都混杂在一起,对日志采集后无法准确地判断发生的 error 日志具体属于哪个子图,特别是还在开发测试阶段的子图无法通过日志进行问题跟踪。
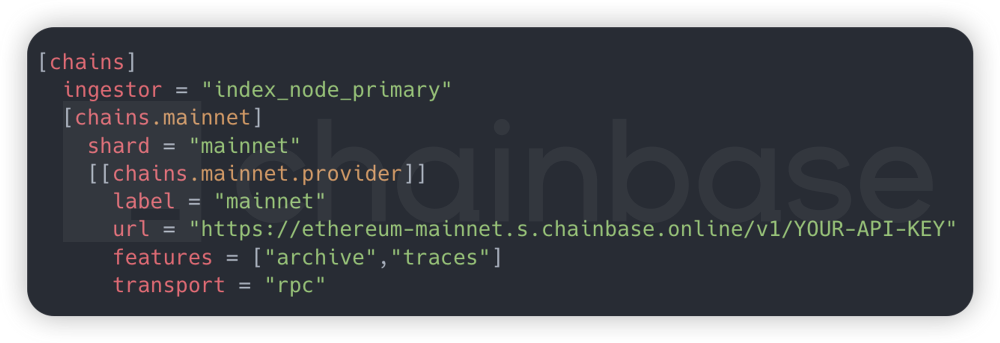
2.4 需要稳定的高性能 RPC 节点
Subgraph 索引性能很大程度取决与 RPC 节点的通信性能,RPC 节点请求延迟越低,子图的索引速度越快,新部署的子图数据追到最新区块时间越短。自我部署 RPC 节点成本高。
三、解决思路
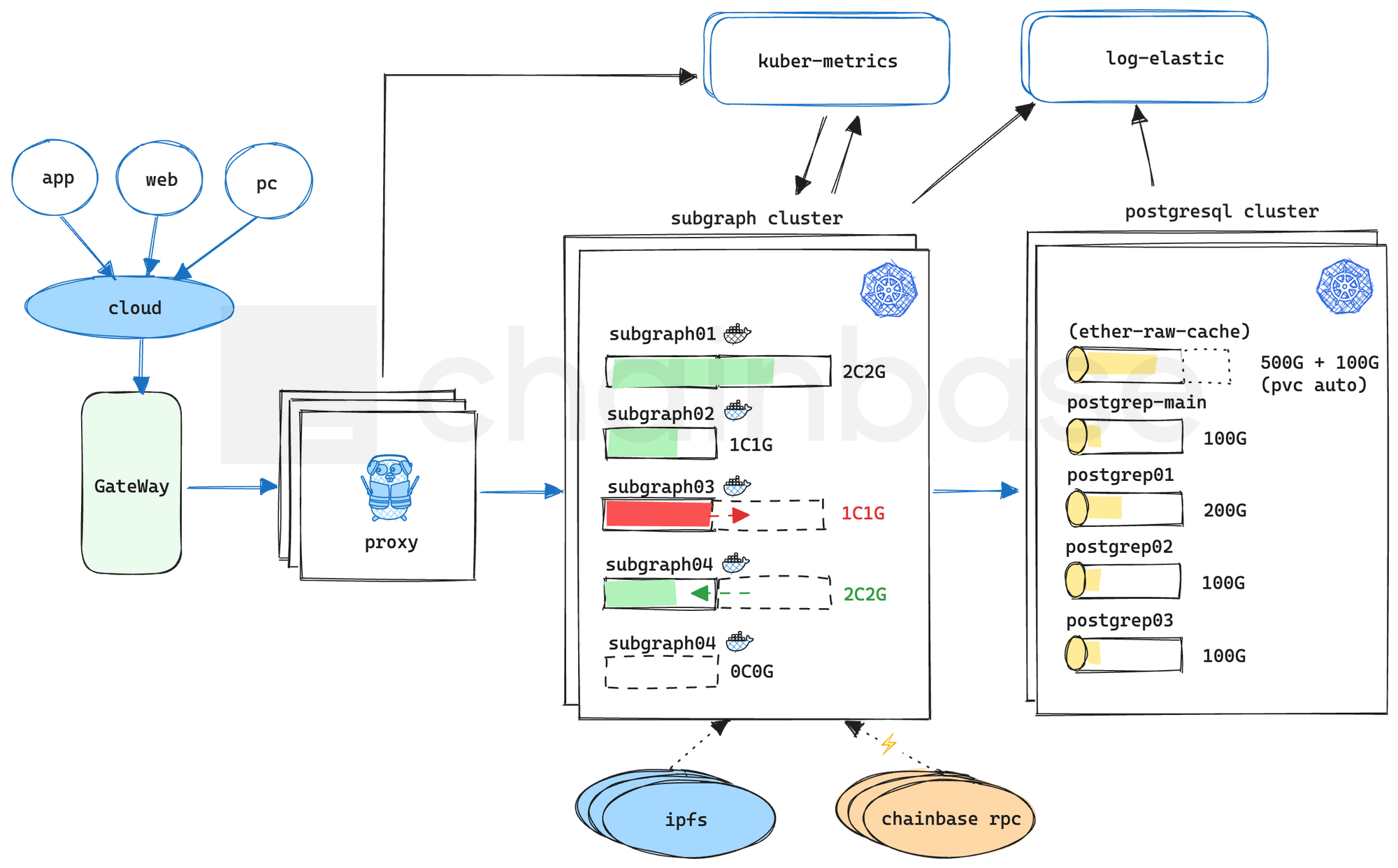
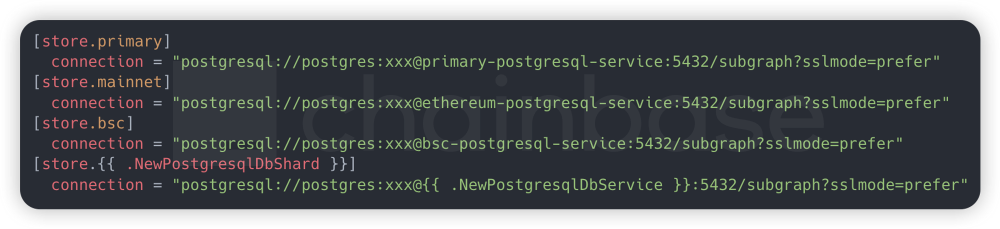
3.1 存算分离和PostgreSQL数据库集群
为了使得计算和存储可以独立扩展,提高系统的灵活性,我们需要将每个子图的数据库和各链上Raw Data Cache 区分开,比如 ethereum 和 polygon 单独一个数据库实例,在有新的子图部署时,检测属于哪条公链子图,自动为其分配对应的Cache 连接地址。这样做的好处是全局只要维护一份 Cache 数据,再也不用每个子图去缓存 Cache 数据,一份 Cache为所有其他子图共享,解决了数据冗余问题;其次,我们可以借助 kubernetes 中的 pvc 扩展为每个单独的数据库实例做资源扩容,每次扩容的比例按照子图索引数据量增涨幅度和其索引进度可以做到精细化控制,这样我们就能预测子图所需的资源总量。

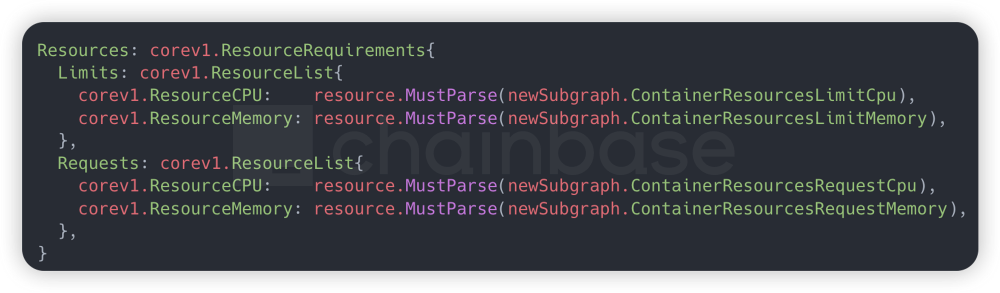
3.2 subgraph资源隔离和自动扩缩容
每个 subgraph使用deployment 抽象成无状态应用,连接后端 statefulset 有状态的 postgresql 数据库实例,将各个subgraph的计算、存储、网络资源进行充分隔离。subgraph会全局设置初始的资源 request 和 limit,在 limit 限制内,允许subgraph进行资源动态调节,资源利用率达到 80%以上进行扩容;利用率在 30%以下进行缩容。只不过由于现有的 subgraph版本只能单线程运行,并不支持并行索引,所以使用传统的 Horizontal Pod Autoscaler(HPA)水平扩容并不能提升索引速度,这里需要使用Vertical Pod Autoscaler (VPA)垂直扩容来动态提升资源 limit,以达到subgraph理想的索引性能。
3.3 Metrics 指标监控和日志采集
得益于容器化后subgraph 在 kubernetes 中的资源隔离特性,我们可以基于具体的 pod 采集到每个subgraph 具体的的监控指标数据,使用 kube-metrics 统一收集集群数据,用于subgraph 的稳定性监控告警和资源动态扩缩容。此时可以开启 debug 日志,使用 elastic 统一收集,暴漏出 api 后可以方便地查询各个子图的调试日志信息。
3.4 稳定的高性能RPC节点
PRC 节点不仅需要支持高并发、高可用、低延迟,还需要提供稳定的 SLA 服务。自我托管部署 RPC 节点不仅硬件成本高,后期节点也难以运维和优化。选择一家稳定的RPC 服务商是 subgraph 索引的基础保障。
四、收益效果
传统的部署架构中,如果我们需要部署一个 Ethereum 归档节点,目前最佳选择是使用 Erigon 客户端,但是至少需要的硬件资源配置(参考 AWS 云资源实例 i4i.4xlarge):

| 序号 | 名称 | 配置 |
|---|---|---|
| 1 | CPU | 16vCPU |
| 2 | ARM | 128GB |
| 3 | PCIE(SSD) | 3.4T + |
| 合计费用 | ≈936USD/M |
而采用来自 Chainbase 的 RPC 服务,只需要订阅基础套餐,成本节省 90%+。
而且在云原生托管 subgraph后,我们还解决了单体架构中数据库瓶颈造成的索引性能和缓存资源冗余问题;并借助 kubernetes 的生态能力解决了资源动态扩缩容,配合subgraph 索引资源需求大幅度提升了资源利用率。
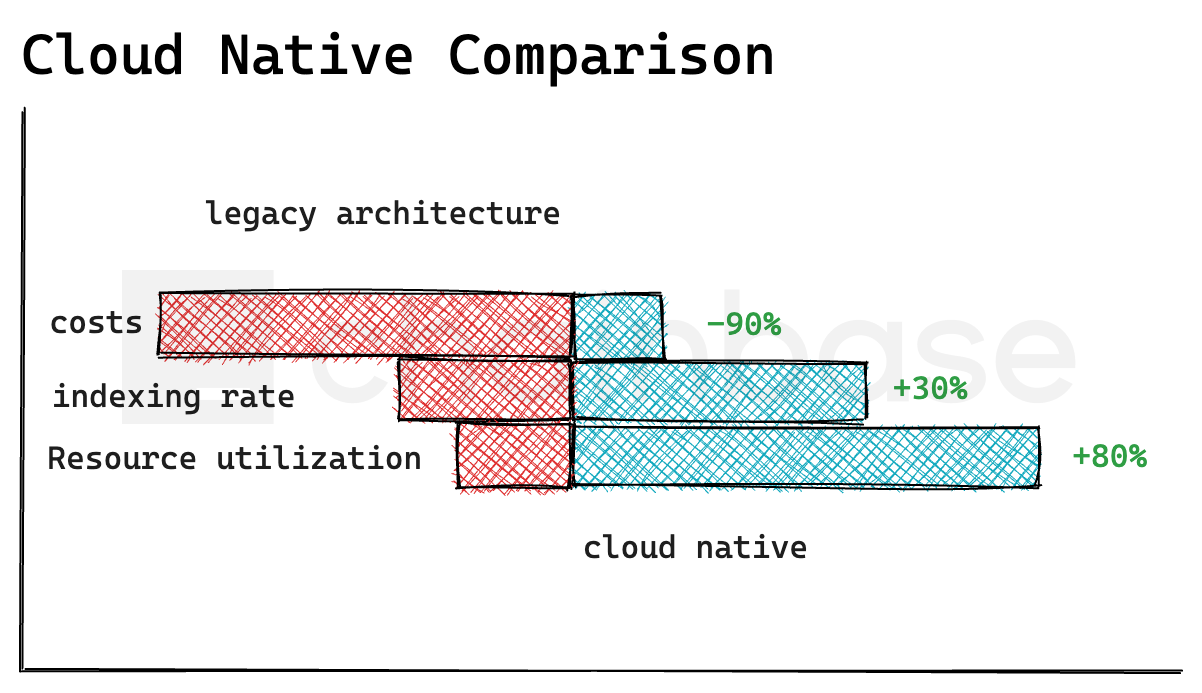
- 索引速度因为 RPC 节点和数据库读写性能提升 30%+
- 平均 Subgraph 资源利用率提升 80%+
五、未来
受限于 Subgraph只能串行索引区块的特点,暂时还无法突破性地提高一个全新的、从0 开始执行索引 Subgraph 的速度。Chainbse团队正积极寻找突破现有技术限制的方法,如支持高效流式引擎 Firehose、Substream,以便我们能够进一步加快Subgraph索引的速度。我们将不断改进我们的产品,满足客户的需求,并为整个行业的发展做出有意义的贡献。
我们期待与所有的客户和合作伙伴共同探索这一充满可能性的未来。
About Chainbase
Chainbase 是领先的 Web3 数据基础设施,帮助开发者轻松访问加密数据,并支持对数据的大规模索引、转换和使用。Chainbase 通过提供丰富的数据集和实时流计算技术,使开发人员能够以更少的精力完成更多的工作。





