AI + 法律 + 区块链:让人人都有律师用
- PermaDAO
- 发布于 2023-09-25 12:50
- 阅读 2437
和以往的技术发明不同,AI 的发展正在快速改变人类的日常生活,从工业机器人到各类 Chat Bot,无论虚实,都是 AI 席卷之处。
 作者: Spike @ Contributor of PermaDAO
作者: Spike @ Contributor of PermaDAO
审阅: Lemon @ Contributor of PermaDAO
和以往的技术发明不同,AI 的发展正在快速改变人类的日常生活,从工业机器人到各类 Chat Bot,无论虚实,都是 AI 席卷之处。
本轮 AI 的最大特点是 LLM (大模型)和 GAN(生成式对抗技术),大模型特点直如其名,突出参数量和训练数据之大,二者共同构成了 LLM 面对复杂问题的快刀斩乱麻之道,如果不能培养出各个行业都精通的专家,那就把所有行业的资料都背会。
GAN 指的是不断的微调模型的表现,通过奖对惩错机制来提高模型的精度,这样的思路并不足以解决全部的问题,但足以解决大部分问题。

当然,AI 的发展也不是一成不变,现存主要两个思路:
- 继续 All in LLM,希望培养出全人类的第二知识库,希望以此培育出硅基”智能“体,代替人类进行思考;
- 培育专精各领域的小模型,从各类优化方法入手,减轻大模型需要的参数量和训练资源,并且争取在某一特定领域取得更强的经济效益。
从目前的实践来看,两者皆有所长,但主要还是以 LLM 为主,原因在于 LLM 主要以文本数据输入和输出为主,相较于复杂的图片、音视频等数据格式更易于训练和应用。
1.1 AI 大模型(LLM)全解
AI大模型是指具有大规模参数和复杂结构的人工智能模型。它们通常由数十亿个参数组成,可以处理大量的数据和复杂的任务。这些模型通过深度学习算法进行训练,能够自动从数据中学习并进行预测、分类、生成等任务。
AI大模型的定义可以从以下几个方面来理解:
- 参数规模:AI 大模型通常具有数十亿个参数,这使得它们能够对复杂的数据进行更准确的建模和预测。这些参数可以通过训练数据进行学习,并根据任务的需求进行调整和优化。
- 复杂结构:AI大模型的结构通常由多个层次和模块组成,可以处理不同类型的输入数据,并在不同的层次上进行特征提取和表示学习。这些结构可以通过深度学习算法进行训练,以提高模型的性能和泛化能力。
- 应用领域:AI大模型在各个领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别等。它们可以用于机器翻译、图像分类、语音生成等任务,为人们提供更智能、高效的解决方案。
以目前比较主流的大模型为例,GPT3 的参数量在 1750 亿个,GPT4 的参数量在万亿级别,国内主流的大模型,如百度的文心一言,参数量在 2600 亿左右,阿里的“通义千问”自称达到 10 万亿的级别。
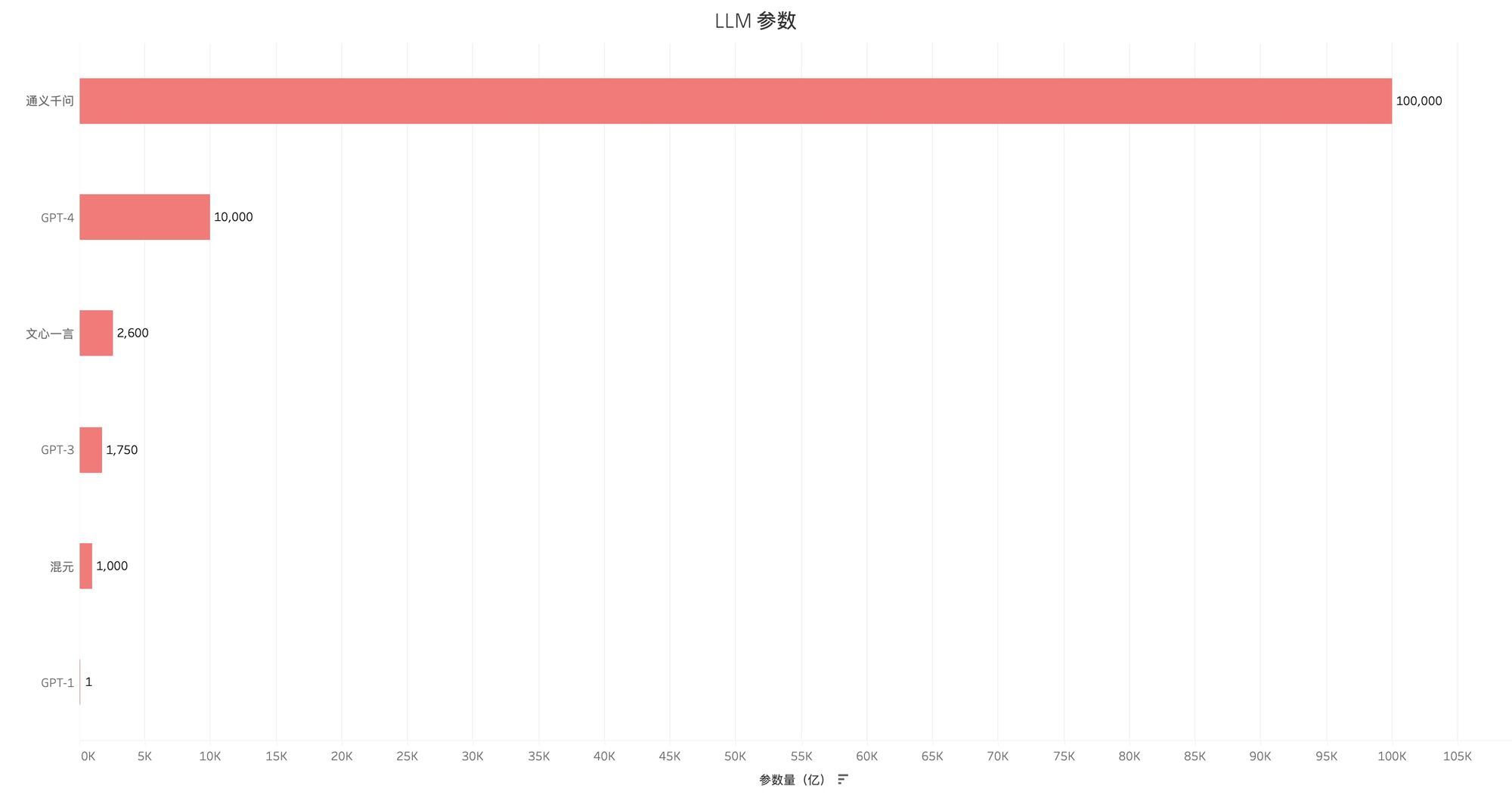
虽然参数量不能直接等同于模型计算能力,但是二者的正相关性是得到业内公认的,因为大模型的参数军备竞赛还将持续相当长的一段时间。
通常而言,AI 大模型具有以下几个问题,甚至在阻碍 LLM 进一步扩展应用场景,类似于边际效用递减,在过度提升参数之后,得到的效果并不会同步提升,GPT-4 的万亿级已经目前的极限。
- 过度复杂:AI 大模型通常由数百万甚至数十亿个参数组成,具有非常复杂的结构和功能,这些模型可以处理大量的输入数据,但是如何修改具体参数以取得更好的优化效果却难以量化,只能凭借“调整参数”,俗称炼丹的实践行为来进行。
- 需要海量数据:虽然可以通过大规模的训练数据进行训练,从而不断提高 LLM 性能和准确度,但是人类目前的文本数据已经无法满足 LLM 的需求,更广泛的非数值型数据也需要被纳入考虑,而其训练较为困难。
- 通用化之路漫长:虽然 LLM 可用于多个领域,包括自然语言处理、图像识别、语音识别等,但是通用化的大模型仍未出炉,即使是 GPT-4,也无法在全部领域取得最优成绩;
- 资源消耗大:由于 AI 大模型的复杂性和规模,它们通常需要大量的计算资源来进行训练和推理。这包括高性能的计算设备、大规模的存储空间以及高速的网络连接。
- 隐私和安全性挑战:AI 大模型通常需要处理大量的敏感数据,如个人信息、商业机密等。因此,保护数据的隐私和确保模型的安全性成为了重要的挑战。
- 可解释性问题:AI 大模型的决策过程通常非常复杂,难以被人类理解和解释。这给模型的可信度和可靠性带来了一定的挑战,需要进一步研究和探索。
基于此,AI 的 LLM 时代并不是终局,而是新的开始,如何利用 LLM 的优势,并且解决或者规避以上问题便成为重中之重。
AI 简史:大模型胜出之前
目前,AI 大模型是最为知名的人工智能范式,但是从其发展史而言,也经历了多次的变革和沉淀,比如 Tansfomer 是目前所有 GPT 类应用的前提,鉴于此,稍微回顾下期发展史,便十分必要。
2.1 基于模型结构的分类
- 卷积神经网络(Convolutional Neural Network,CNN):卷积神经网络是一种常用的神经网络结构,主要用于处理图像和视频数据。它通过多层卷积和池化操作来提取图像中的特征,并通过全连接层进行分类。
- 循环神经网络(Recurrent Neural Network,RNN):循环神经网络是一种能够处理序列数据的神经网络结构。它通过在网络中引入循环连接,使得网络可以保持对过去信息的记忆,从而能够有效地处理序列数据,如自然语言处理和语音识别等任务。
- 生成对抗网络(Generative Adversarial Network,GAN):生成对抗网络由生成器和判别器两个网络组成,通过对抗训练的方式来生成逼真的数据。生成器网络负责生成数据,而判别器网络负责判断生成的数据是否真实。通过不断的对抗训练,生成器网络可以逐渐提高生成数据的质量。
- Transformer:变换器是一种用于处理序列数据的神经网络结构,主要用于自然语言处理任务。它通过多层自注意力机制来捕捉序列中的依赖关系,并通过前馈神经网络进行特征的提取和分类。
- 图神经网络(Graph Neural Network,GNN):图神经网络是一种用于处理图数据的神经网络结构。它通过对节点和边进行特征的聚合和更新,从而能够有效地处理图数据,如社交网络分析和推荐系统等任务。
2.2 基于训练方式的分类
- 监督学习:监督学习是一种通过给定输入和对应的输出数据来训练模型的方法。在监督学习中,模型通过学习输入和输出之间的关系来进行预测。常见的监督学习算法包括线性回归、逻辑回归、决策树和神经网络等。例如,在金融行业中,可以使用监督学习来预测股票价格或者判断客户是否会违约。
- 无监督学习:无监督学习是一种在没有标记数据的情况下训练模型的方法。在无监督学习中,模型通过发现数据中的模式和结构来进行学习。常见的无监督学习算法包括聚类、降维和关联规则等。例如,在金融行业中,可以使用无监督学习来对客户进行分群分析或者发现异常交易。
- 半监督学习:半监督学习是一种介于监督学习和无监督学习之间的训练方式。在半监督学习中,模型同时使用有标记和无标记的数据进行训练。有标记的数据用于指导模型学习,无标记的数据用于发现数据的结构和模式。半监督学习在金融行业中的应用包括信用评分和欺诈检测等。
- 强化学习:强化学习是一种通过试错的方式来训练模型的方法。在强化学习中,模型通过与环境进行交互,根据反馈信号来调整自己的行为。强化学习在金融行业中的应用包括股票交易和风险管理等。
如果简要划分 AI 发展的代际和流派,那么则可大致划分为以下四个时代,其中 LLM 是深度学习的最新发展,是深度学习的子集。
- 符号主义时代:20世纪50年代到70年代,符号主义是机器学习的主导思想。这个时期的机器学习算法主要基于人类专家的知识和规则,通过编程将这些知识和规则转化为计算机可以理解的形式。然而,这种方法在处理复杂和模糊的问题上存在局限性。
- 连接主义时代:20世纪80年代到90年代,连接主义成为机器学习的新兴思想。连接主义通过模拟神经网络的方式,将机器学习问题转化为权重调整的问题。这种方法能够处理更复杂的问题,并且能够从数据中学习到模式和规律。
- 统计学习时代:20世纪90年代到2000年代,统计学习成为机器学习的主流。统计学习通过建立概率模型,利用统计方法来进行模型参数的估计和预测。这种方法在处理大规模数据和复杂问题上具有很大的优势,例如支持向量机和随机森林等算法。
- 深度学习时代:21世纪以来,深度学习成为机器学习的热门领域。深度学习通过构建深层神经网络,利用大量的数据进行训练和学习。深度学习在图像识别、自然语言处理和语音识别等领域取得了重大突破,使得机器学习在实际应用中更加广泛。
大模型 2.0:微调 VS 瘦身
以特定领域为例,其和 AI 的结合早已有之,在20世纪70年代,专家系统开始兴起,并在一些特定领域取得了显著的成就。其中一个著名的例子是 MYCIN 系统,它是一个用于诊断细菌感染的专家系统。MYCIN 系统通过将医学专家的知识转化为规则和推理机制,能够准确地诊断出细菌感染,并给出相应的治疗建议。这一成就引起了广泛的关注和研究,促进了专家系统在医学、工程、金融等领域的应用。然而,由于专家系统的知识表示和推理机制的局限性,以及对领域专家知识的依赖,专家系统在实际应用中也暴露出一些问题。尽管如此,专家系统的兴起为弱人工智能的发展奠定了基础,为后续的人工智能技术提供了宝贵的经验和启示。
具体到法律领域,其直接相关是自然语言处理(NLP),指的是通过计算机将人类语言进行编码、解码,转化为机器指令,并进行对应分析的过程。法律文本和一般文本差别较大,其行文格式严谨,用词精准,并且具备高度的模式化和固定风格,因此较为容易被机器所掌握和分析。
NLP 的应用非常广泛,涵盖了很多领域。下面是一些常见的自然语言处理应用示例:
- 信息提取(Information Extraction):从大量的文本中提取出有用的信息,如从新闻文章中提取出人名、地名、时间等信息。
- 文本分类(Text Classification):将文本按照预定义的类别进行分类,如将电子邮件分类为垃圾邮件或非垃圾邮件。
- 机器翻译(Machine Translation):将一种语言的文本自动翻译成另一种语言的文本,如将英语翻译成中文。
- 情感分析(Sentiment Analysis):分析文本中的情感倾向,判断其是正面的、负面的还是中性的。
- 问答系统(Question Answering):根据用户提出的问题,从大量的文本中找到最相关的答案并返回给用户。
- 文本生成(Text Generation):根据给定的上下文生成新的文本,如根据一段文字生成新闻报道。
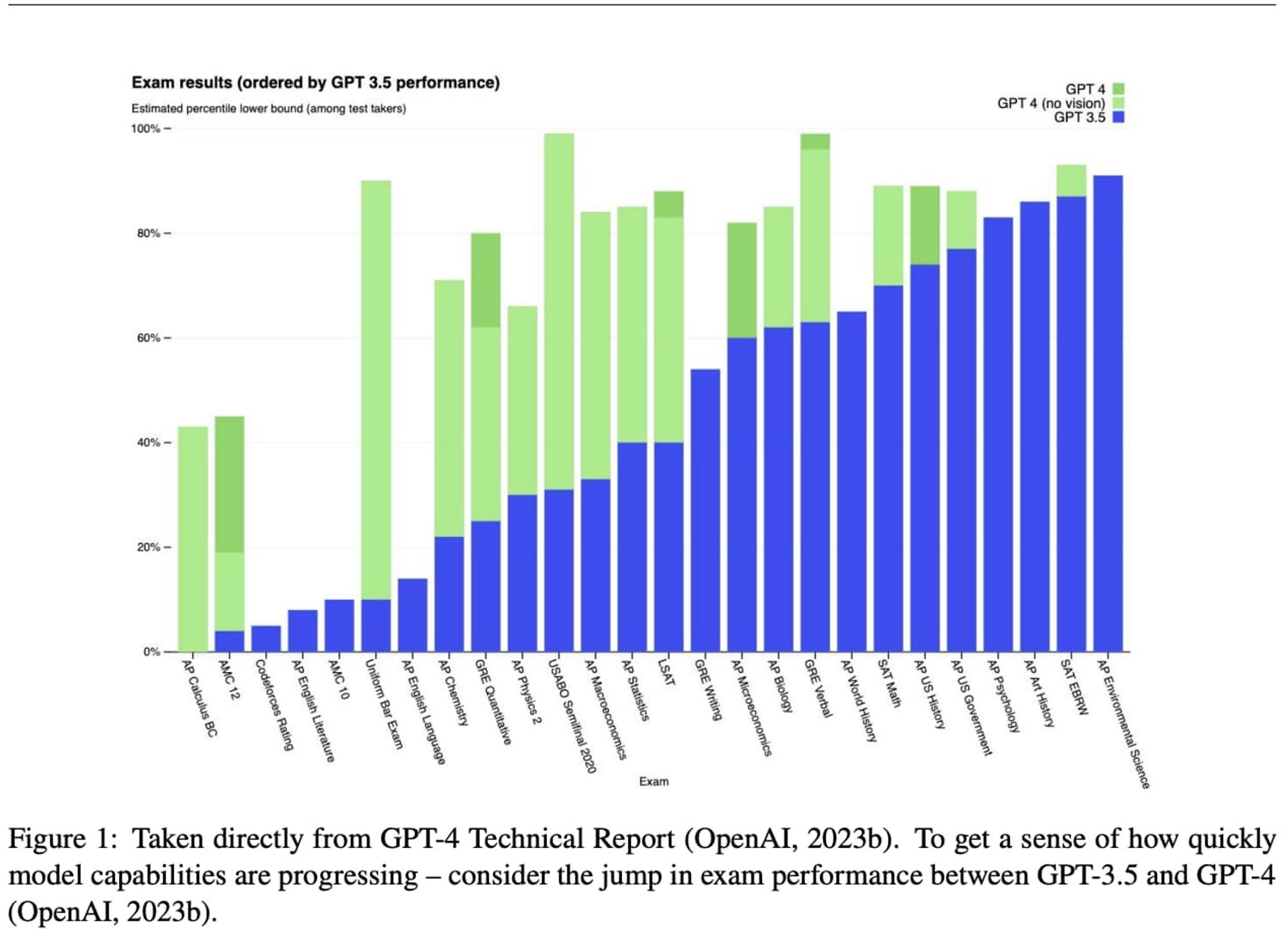
而根据 OpenAI 的论文,大部分法律工作者的工作都可被 AI 所取代,无论是标准化的司法类考试,还是案例检索和文书写作,AI 对人的优势都已经呈现全面碾压之势。
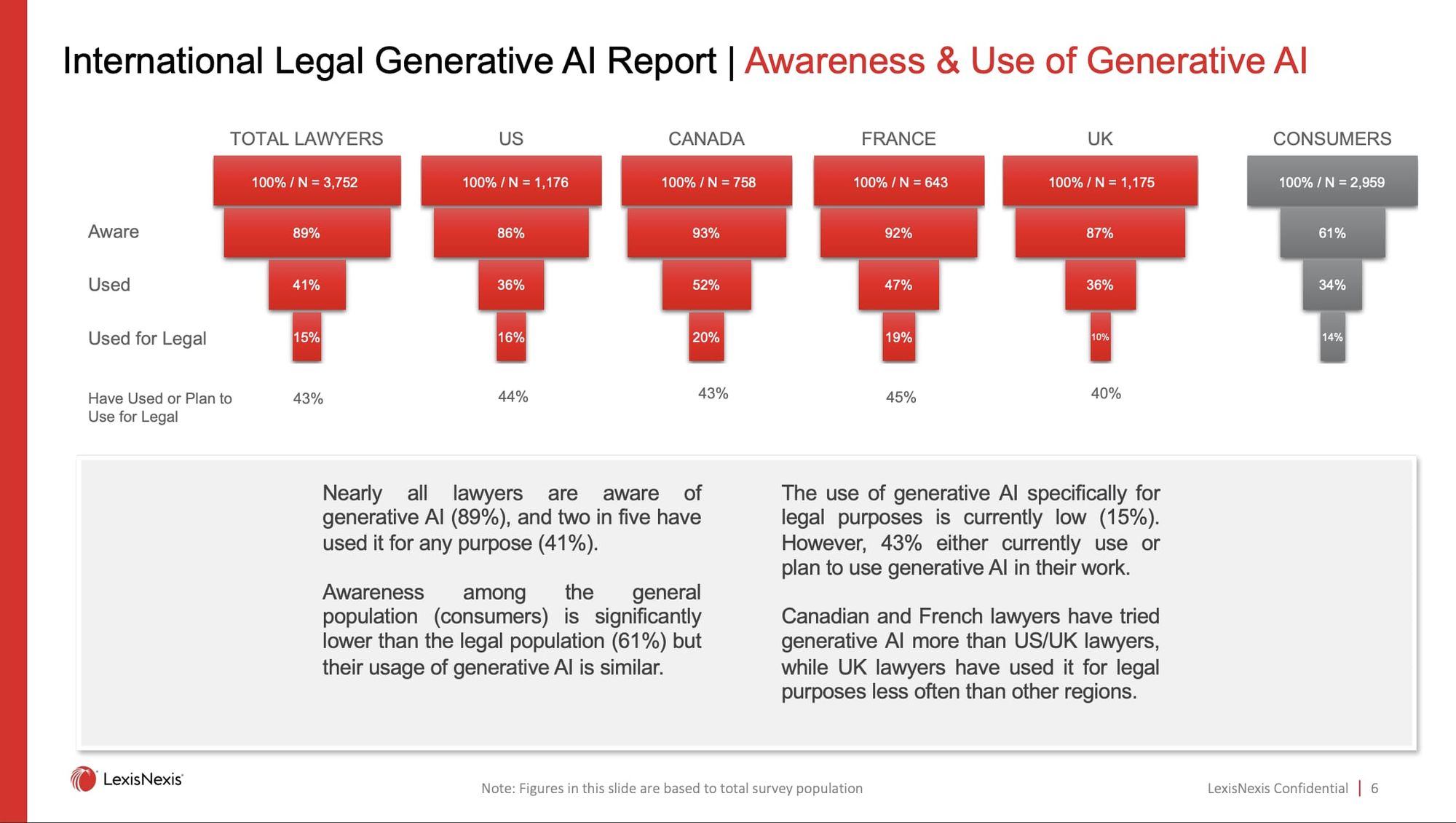
但是这并不意味着法律从业者就会抵制 AI 的加入,根据 LexisNexis 的调查报告,81% 的受访者(律师群体)已经知道生成式 AI 的存在,并且 40% 以上的律师使用过类似产品。
除此之外,AI + 法律创业也是经久不衰的赛道。从 2015 年的 DoNotPay 开始,引入 AI 写作法律文书便已经是成熟的商业模式,但是总体而言,目前的 AI 法律产品,大多数都是黑箱状态运行,希望以更多的数据采集工作,对冲其他竞品的市场攻势,而未能从较为可行的路径去全方位思考保护用户隐私,以及满足合规和确权本身的技术方案。
对此, Arweave 的隐私保护和数据永存特性便具备特殊意义,一方面,数据的永存并不必然和隐私保护相违背,完全可以实现既保护用户隐私又可实现商业运作;另一方面,用户的商业价值不取决于涉案金额,而是取决于调用服务次数,保证任何人都可以得到专业的律师服务,规避传统法律体系对弱势群体的排斥问题。
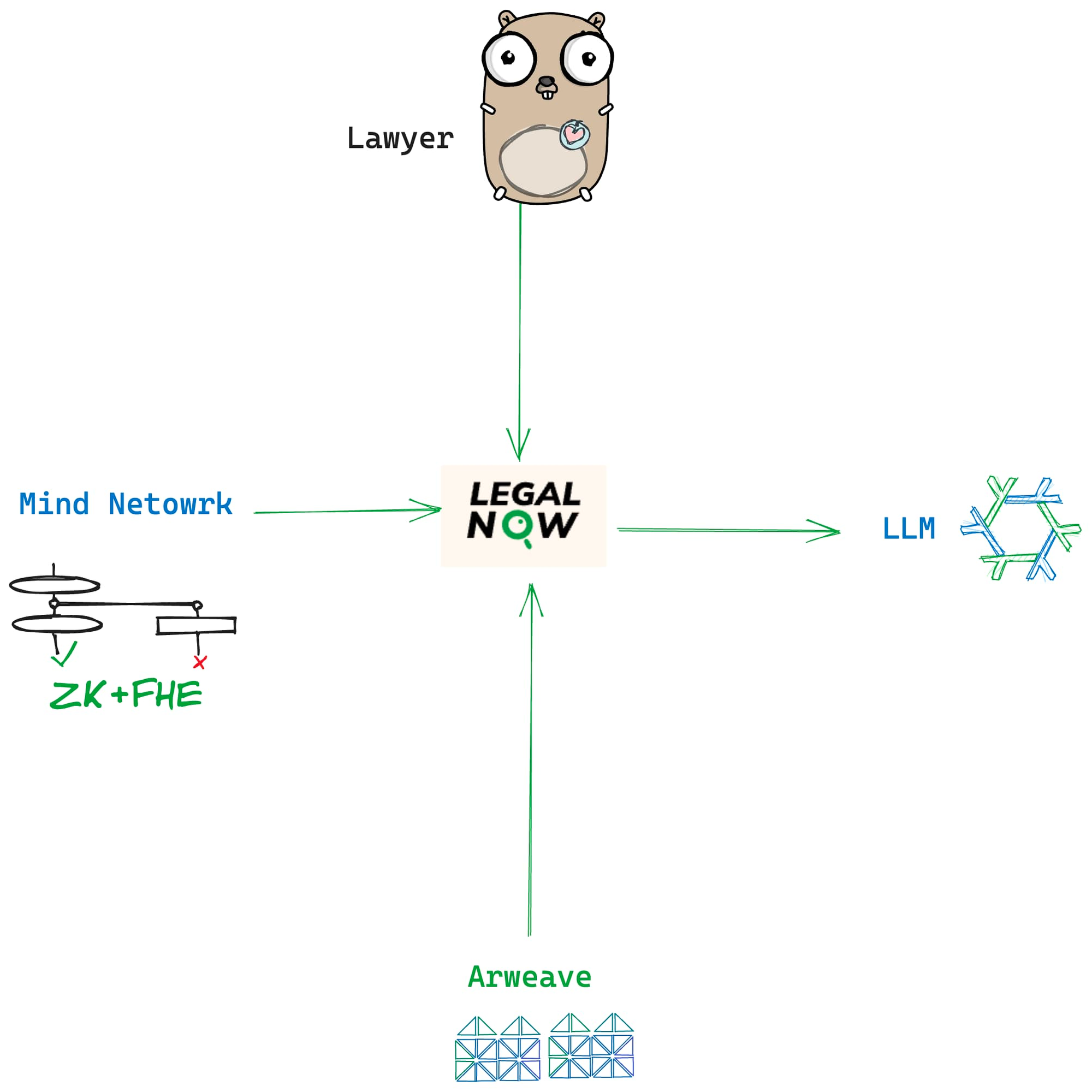
LEGALNOW:让人人用得起专业律师服务
如前文所述,AI 和法律的结合,笼罩在专家系统的阴影之下,而 GPT 横空出世后,人人都可以使用专业法律服务,但这种服务本身仍旧存在诸多限制:
- 通用模型无法聚焦。通用大模型是百事通,但是对于非常具体的细节,则往往需要提问人给予更多上下文提示,但是提问人往往不掌握这些专业知识,因此难以发挥大模型的最大威力;
- 数据安全存在隐患。法律信息一般都会涉及个人隐私,尤其是专业的合同、文书和备忘录等,会直接展现个人、公司机密或信息,而中心化的服务器无法从技术上严格保证信息的安全性;
- 特定需求的定制化服务。在部分业务场景下,比如涉及多个主体的法律合同,往往需要专业律师的亲自见证,以确保法律文本的合法性,以及不存在瑕疵,但是大模型背后的科技公司往往无法提供此类服务。
鉴于此,LegalNOW 提出了自己的解决方案:
- 后端基于目前最强大的 GPT-4 32k 模型,并且由 Top-tier 的资深律师训练和调校。为大模型补上最专业的反馈,在传统大模型训练过程中,反馈由工资较为低廉的第三世界居民来完成,面对专业的特定需求专业度略显不足,LegalNOW 由 LegalDAO 孵化而来,其上的数千名专业律师将亲自负责法律术语的反馈,力争做到开箱即用的水平。
- 7/24 小时律师级法律支持。在单纯的大模型对话之外,LegalNOW 也在建设支持和服务系统,认知到法律的特殊性和专业性,LegalNOW 并不会将一切丢给机器,而是希望借助人工和机器的双轮驱动,共同补齐法律服务的全球性短板。
- 用户数据使用加密存储和区块链永久存储,Mind Network 将负责用户数据的隐私上链和流转,打消用户对个人数据被滥用的担忧, 其次 Arweave 将永久存储所有数据,避免纠纷。
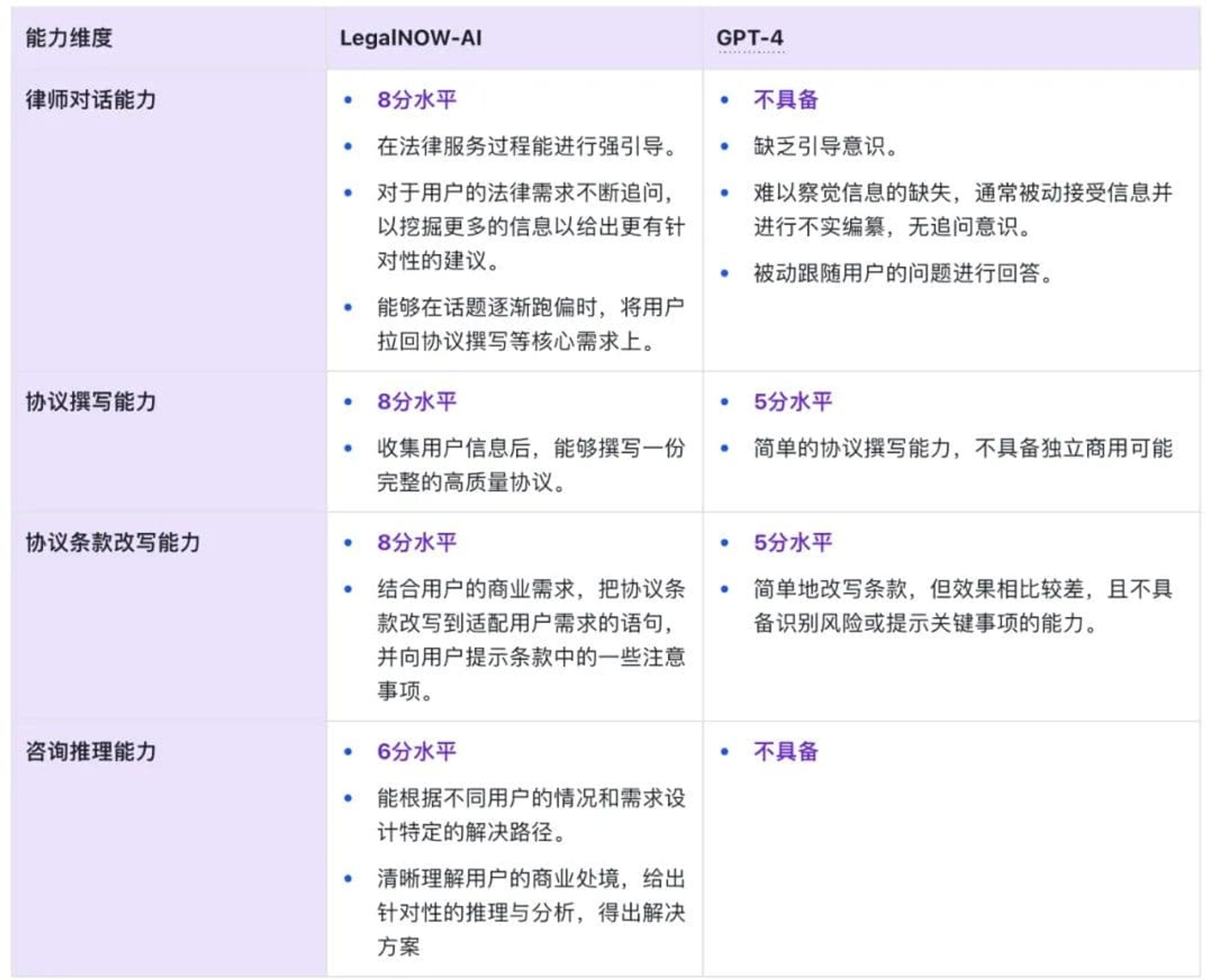
在业务方向上,目前 LegalNOW 聚焦于区块链领域的合同撰写,在以往之前,撰写此类合同需要耗时耗力,并且耗资巨大,但是在 LeaglNOW 服务模式下,用户可按照调用次数进行付费。
总结
AI 大模型的发展也已经数年有余,而目前仍旧集中在写作、绘画等创意领域,而非是更为格式化的场景,这算是 AI 给人类的一次“小小震撼”,与此同时,人们迫切希望 AI 可以发挥更多生产力场景的作用,比如专业的医疗、法律或者科学领域。
而 LegalNOW 本次的尝试算是一个开端,其致力于打造真正通用化的法律服务产品,而结合区块链的隐私组件,则可让 AI 变得更为安全可信,我们总不希望还没摆脱 Web2 巨头的隐私滥用,转身又将自己的数据免费送给 AI 公司,区块链几乎是这个问题唯一的解。
无论如何,AI 时代已经来临,至于我们如何和 AI 相处,这将是下一个时代每个人都要思考的问题,不如趁现在,从拟写一份法律文本开始。
关于 PermaDAO:Website | Twitter | Telegram | Discord| Medium | Youtube

- 原创
- 学分: 0
- 标签:





