Filecoin - Lotus存储证明了什么?
- Star Li
- 发布于 2020-02-24 15:33
- 阅读 7566
Filecoin - Lotus存储证明了什么?
2019年,Filecoin算是火热的区块链项目。3月份,Filecoin公开了相关的代码后,第一时间看了看Filecoin的代码。
区块链部分的代码,比较简单,偏功能验证。个人对存储证明的部分比较感兴趣,也就是FPS。采用零知识证明技术,对存储进行证明是个大胆的尝试。
Filecoin团队,在2019年下半年出了个Lotus(莲花)测试版本。测试网络的硬件配置比较高,256G内存 + Nvidia 2080TI的显卡。测试网络的节点排行榜,也成了竞赛场。算力增长,出块效率,是主要的指标。
Lotus的电路逻辑比较复杂,电路规模达到了1亿。证明生成的时间也非常长。整个证明计算过程,有很大的提升空间。对Lotus的证明性能提升感兴趣的小伙伴,欢迎和我交流。
别光看Filecoin在国内的热度,深入介绍Filecoin/Lotus相关零知识证明的技术文章寥寥无几。最近有点时间,梳理了一下Lotus的PoREP的数据处理(包括Sector处理以及采用零知识证明)的相关逻辑。
01 Lotus整体模块

简单的说,Lotus/Filecoin项目由三部分组成:
1/ Lotus Blockchain部分 - 实现区块链相关逻辑(共识算法,P2P,区块管理,虚拟机等等)。注意的是,Lotus的区块链相关的数据存储在IPFS之上。go语言实现。
2/ RUST-FIL-PROOF部分 - 实现Sector的存储以及证明电路。也就是FPS(Filecoin Proving Subsystem)。Rust语言实现。
3/ Bellman部分 - 零知识证明(zk-SNARK)的证明系统,主要是基于BLS12_381椭圆曲线上,实现了Groth16的零知识证明系统。Lotus官方推荐采用Nvidia的2080ti显卡,也主要做这部分的性能加速。Rust语言实现。
这篇文章,主要介绍第二部分(也就是Sector的存储以及证明)的核心逻辑。
02 Stacked DRG
解释具体的逻辑之前,介绍一下两个基本术语:一个是Stacked DRG,一个是Sector。Sector相对比较简单,就是一次数据处理的单位。知道硬盘结构的小伙伴都知道,硬盘的最小的存储单元就叫“Sector”。Lotus采用的Sector的比较大,目前测试网络采用的是32G。
Stacked DRG是Sector数据处理的算法。对存储数据进一定的处理,并进行相应的证明是为了说明存储服务方,确实如实地存储了一些数据,而不是造假(攻击)。Filecoin很早之前采用的是“Zig Zag DRG”算法。可能因为太复杂(太慢),Lotus采用的是“简化”的Stacked DRG算法。两种算法的区别示意如下:
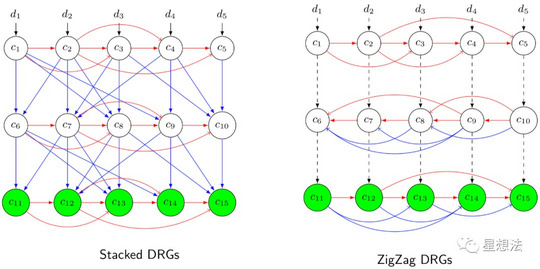
有两点需要说明:
1/ Stacked DRG的每个节点以及每层之间不采用Zig Zag的依赖关系。也就是说,每个节点和其他节点的依赖关系是固定的。
2/ 在每层(Layer)之间增加节点的依赖关系。
03 Sector处理(Precommit)过程
Sector处理,也就是传说中的precommit阶段,主要由如下的数据处理组成:
a. 针对原始数据构造默克尔树tree_d(sha256),树根为comm_d。
b. Label & Encode计算:
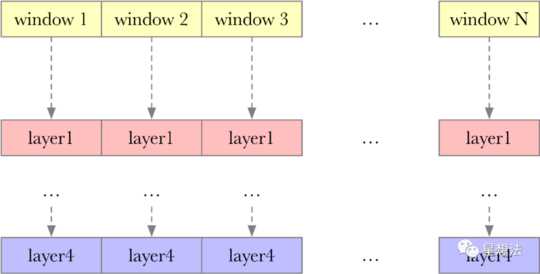
原始数据,每32个字节,称为一个Node。每128M分为一个Window。32G的Sector有256个Window。每个Window,按照Stacked DRG算法,生成4个layer的数据。从上一个Layer,通过Encode计算生成下一个Layer的数据。Encode计算,目前就是模加操作。将Window的编号和Stacked DRG的节点关系通过sha256算法,生成“key”。将Key和原始数据进行模加生成Encode计算的结果。
c. Layer4的生成数据,构造默克尔树tree_q(pedersen),树根为comm_q。Layer4的生成数据,再经过一层exp的依赖关系,构造默克尔树tree_r_last(pedersen),树根为comm_r_last。
d. Column Hash计算
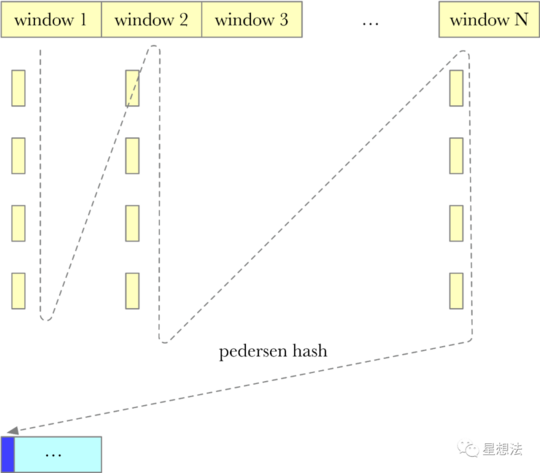
Layer4的256个Window的数据中,同一位置上的Node,拼接在一起,hash后生成Column Hash的结果。注意,Column Hash的计算结果只有一个Window大小。针对Column Hash的计算结果,构造默克尔树tree_c,树根为comm_c。
需要上链的数据是以上所有的默克尔树的树根:comm_d以及comm_r。其中comm_r是(comm_c|comm_q|comm_r_last)的pedersen hash的结果 。
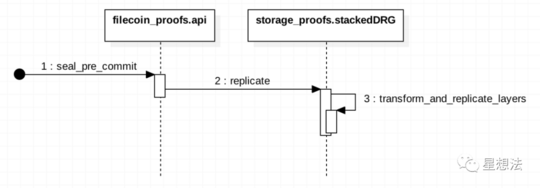
核心代码在rust-fil-proofs/storage-proofs/src/stacked/proof.rs的transform_and_replicate_layers函数中。感兴趣的小伙伴,可以根据下面的调用关系查看具体的代码。
04 Sector证明(Commit)过程
在Sector处理后,需要对处理后的数据进行“证明”,毕竟不能把所有处理后的数据全部提交到区块链上。Lotus使用Bellman的零知识证明库,采用Groth16算法进行数据处理的证明。
RUST-FIL-PROOF(FPS)实现了StackedCompound,专门用来实现Stacked DRG的数据处理证明。StackedCompound,将两部分整合在一起,一部分是电路(Stacked Circuit),另一部分是Stacked Drg,实现电路数据的准备。这些部分又分成一个个的子功能(Window,Wrapper,ReplicaColumn等等)。在调用Bellman生成证明时,相应电路的synthesize接口就会被调用,从而完成整个电路生成R1CS的过程。
话说,Lotus的Sector的数据证明证明了什么呢?Lotus的数据证明了如下的事实:
1/ 结合链上生成的随机数,随机挑选50个处理后数据Node,也就是在replica(复制数据)中,随机挑选50个Node数据。
2/ 证明这些数据是从原始数据一步步处理生成的。而且,能构造出之前处理过程中生成的4个默克尔树的树根。
3/ 重复步骤1和2,10次。
步骤1/2的证明,如下图所示:
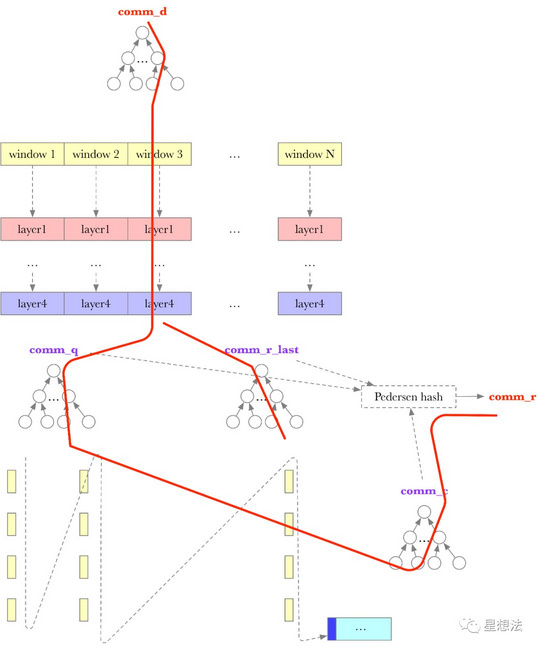
简单的说,从链上获取了随机信息后(和区块高度有关),随机选择了500个处理后的Node数据,并证明这些数据是通过Stacked DRG算法从原始数据计算而来。并且,这些数据能构成之前递交到链上的四个默克尔树的树根。
Lotus的电路逻辑比较复杂,电路规模达到了1亿。证明生成的时间也非常长。
05 Sector证明链上验证
提交到链上的数据包括:comm_d,comm_r以及proof证明数据。链上的miner智能合约会验证提交的证明是否正确:
func ValidatePoRep(ctx context.Context, maddr address.Address, ssize uint64, commD, commR, ticket, proof, seed []byte, sectorID uint64) (bool, ActorError)具体的代码在lotus/chain/actors/actor_miner.go文件。其中ticket和seed就是链上提供的随机信息。验证过程就是RUST-FIL-PROOF模块调用Bellman验证零知识证明是否正确。验证过程比较快,毫秒级的计算。相对来说,存储证明的生成过程时间比较长,有比较大的提升空间。
总结:
Lotus(莲花),采用Stacked DRG算法对存储的数据进行处理,并采用Groth16零知识证明算法对数据处理过程进行证明。Lotus的零知识证明,证明了随机抽选的500个节点数据是正确地通过Stacked DRG算法生成,并能生成指定的默克尔树的树根。Lotus的电路逻辑比较复杂,电路规模达到了1亿,证明生成时间比较长。整个计算性能有很大的提升空间。
我是Star Li,我的公众号星想法有很多原创高质量文章,欢迎大家扫码关注。






