如何解码原始 EVM Calldata 数据
- 翻译小组
- 发布于 2023-12-26 10:49
- 阅读 5067
如何解码原始 EVM Calldata 数据
- 原文链接:https://jbecker.dev/research/decoding-raw-calldata
- 译文出自:登链翻译计划
- 译者:翻译小组 > 校对:Tiny 熊
- 本文永久链接:learnblockchain.cn/article…

随着 heimdall-rs 0.7.0 的发布,该工具包获得了解码原始 EVM calldata 为其组成类型的能力,无需合约 ABI 或签名解析。在这篇技术文章中,我们将深入探讨 EVM calldata 的内部工作原理,它是如何编码的,以及我们如何解码它。
注:假定了对 EVM 和 Solidity/Vyper 的了解,但不是必需的。
免责声明: 本文中提出的方法并不完美,在解码类型时可能仍存在一些歧义。然而,没有 ABI 或函数签名下,这是我们能做到的最好。
简介:EVM Calldata
与 EVM 合约交互时,调用者必须提供一组参数以调用函数调用。这些参数被编码为称为 calldata 的字节数组,作为交易的一部分传递给合约。合约随后可以访问 calldata,并将其解码为其组成的类型。
EVM 有三个用于访问 calldata 的操作码:CALLDATASIZE、CALLDATALOAD和CALLDATACOPY。这些操作码允许合约访问 calldata,但不提供有关 calldata 结构或其包含的参数类型的任何信息。
作为练习,让我们构建一个简单函数调用的 calldata。考虑以下 Solidity 函数:
// snippet.sol
function balanceOf(address who) public view returns (uint256) {
return balances[who];
}函数签名和选择器
calldata 的前四个字节通常用于标识被调用的函数。这些字节称为函数选择器,是通过取函数签名的keccak256哈希的前四个字节生成的。
我们的balanceOf函数具有以下签名:
//snippet.sol
balanceOf(address)该签名的keccak256哈希为:
snippet.asm
0x70a08231b98ef4ca268c9cc3f6b4590e4bfec28280db06bb5d45e689f2a360be因此,函数选择器是此哈希的前四个字节:0x70a08231,我们可以开始构建 calldata:
snippet.asm
70a08231编码参数
calldata 中的参数根据 ABI 规范进行编码。参数的编码取决于其类型,函数参数的编码只是每个参数编码的连接(我们稍后会触及一些例外情况)。
编码静态类型
对于基本类型,编码很简单:
| 类型 | 编码 |
|---|---|
bool |
00...00表示false,00...01表示true |
uint<N> |
整数的十六进制大端表示 |
address |
编码为uint160 |
bytes<N> |
十六进制编码的字节,左填充 |
int<N> |
大端表示的十六进制编码,如果为负则填充ff字节,如果为正则填充00字节 |
enum |
编码为uint8 |
这些类型在 calldata 中被编码为单个字(32 字节),如果需要,左侧用零填充。
因此,对于我们的balanceOf函数,参数是一个address,它被编码为uint160。我们要查询的地址是0xd8da6bf26964af9d7eed9e03e53415d37aa96045(vitalik.eth),因此编码为:
snippet.asm
000000000000000000000000d8da6bf26964af9d7eed9e03e53415d37aa96045我们可以将这个添加到我们的 calldata 中:
snippet.asm
70a08231
000000000000000000000000d8da6bf26964af9d7eed9e03e53415d37aa96045现在 calldata 已经完成,我们可以使用 Foundry 的 cast 将其传递给合约:
snippet.sh
cast call 0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2 --data 70a08231000000000000000000000000d8da6bf26964af9d7eed9e03e53415d37aa96045然后我们得到了预期的结果:
snippet.asm
0x000000000000000000000000000000000000000000000001794bd6ed99652e51编码动态类型
编码动态类型要复杂一些,因为它们的编码取决于被编码数据的长度。动态类型的编码如下:
-
第一个字是从
context的起始字节到数据的偏移量。我们将其称为offset。- 在大多数情况下,
context是 calldata 参数块的起始(即函数选择器之后的 calldata 的第一个字)。但是,如果动态类型嵌套在另一个动态类型中,则context是外部动态类型数据块的起始。 - 偏移量被编码为
uint256,如果需要,左侧用零填充。
- 在大多数情况下,
-
context[offset]处的字是数据的长度(以字节为单位)。我们将其称为length。长度被编码为uint256,如果需要,左侧用零填充。- 对于
bytes和string,length是编码数据占用的字节数。如果需要,编码本身右填充零,并且如果长度大于 32 字节,则可能跨越多个字。 - 对于动态长度数组(即
T[]),length是数组中的元素数量。然后编码是按顺序连接每个元素的编码。
- 对于
注:上述是 ABI 规范的简化。对于本文的目的,我认为这已经足够了。
再次,我们将使用示例来说明。让我们编码以下签名f(uint256,uint32[],bytes10,bytes)(选择器为0x8be65246),参数为(0x123, [0x456, 0x789], "1234567890", "Hello, world!")。
- 第一个参数是
uint256,这是一个简单的基本类型。这个编码很简单:
snippet.asm
0000000000000000000000000000000000000000000000000000000000000123- 第二个参数是
uint32的动态长度数组。
snippet.asm
0000000000000000000000000000000000000000000000000000000000000002 - 数组长度为 2
0000000000000000000000000000000000000000000000000000000000000456 - 编码第一个元素
0000000000000000000000000000000000000000000000000000000000000789 - 编码第二个元素- 第三个参数是
bytes10,它是一个长度为 10 字节的静态类型。编码为:
snippet.asm
3132333435363738393000000000000000000000000000000000000000000000- 第四个参数是
bytes,这是一个动态类型。编码为:
snippet.asm
000000000000000000000000000000000000000000000000000000000000000d - 编码数据的大小 (13)
48656c6c6f2c20776f726c642100000000000000000000000000000000000000 - 右填充现在我们可以连接这些编码以获得最终的 calldata:
snippet.asm
0x8be65246
0000000000000000000000000000000000000000000000000000000000000123 - 第一个参数
(a) - 第二个参数偏移量占位符
3132333435363738393000000000000000000000000000000000000000000000 - 第三个参数
(b) - 第四个参数偏移量占位符
0000000000000000000000000000000000000000000000000000000000000002 - length of array (2)
0000000000000000000000000000000000000000000000000000000000000456 - encoding of array element 1
0000000000000000000000000000000000000000000000000000000000000789 - encoding of array element 2
000000000000000000000000000000000000000000000000000000000000000d - number of bytes in encoded data (13)
48656c6c6f2c20776f726c642100000000000000000000000000000000000000 - right-padded bytes现在我们可以用第二个和第四个参数的偏移量填充占位符(a)和(b)。由于 calldata 的第四个字(从零开始索引)是第二个参数的起始位置,第二个参数的偏移量为 4∗32=128。同样,第四个参数的偏移量为 7∗32=224。
snippet.asm
0x8be65246
0000000000000000000000000000000000000000000000000000000000000123 - 第一个参数
0000000000000000000000000000000000000000000000000000000000000080 - 第二个参数偏移量 (128)
3132333435363738393000000000000000000000000000000000000000000000 - 第三个参数
00000000000000000000000000000000000000000000000000000000000000e0 - 第四个参数偏移量 (224)
0000000000000000000000000000000000000000000000000000000000000002 - length of array (2)
0000000000000000000000000000000000000000000000000000000000000456 - encoding of array element 1
0000000000000000000000000000000000000000000000000000000000000789 - encoding of array element 2
000000000000000000000000000000000000000000000000000000000000000d - number of bytes in encoded data (13)
48656c6c6f2c20776f726c642100000000000000000000000000000000000000 - right-padded bytes完成了!最终的 calldata 是:
snippet.asm
0x8be6524600000000000000000000000000000000000000000000000000000000000001230000000000000000000000000000000000000000000000000000000000000080313233343536373839300000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000e0000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000004560000000000000000000000000000000000000000000000000000000000000789000000000000000000000000000000000000000000000000000000000000000d48656c6c6f2c20776f726c642100000000000000000000000000000000000000你可能会注意到,对于任何函数 f(arg<sub>1</sub>, ... arg<sub>n</sub>),calldata 的前 n 个字要么是参数本身,要么是参数的偏移量。这一点以后会很重要。
解码 Calldata
在我们开始解码原始 calldata 之前,让我们做一些假设:
- calldata 是格式良好的。也就是说,它是一个有效的字节序列,可以根据 ABI 规范进行解码。另外,len(calldata) - 4≡<sub>32</sub> 0。
- 我们无法访问合约 ABI,也无法访问函数签名。我们所拥有的只是原始 calldata。
- 动态类型的偏移指针是有效的。也就是说,偏移>0,偏移≡<sub>32</sub>0。这是合理的,因为偏移指针必须指向一个字的起始位置。
辅助函数
我们将定义一些辅助函数,这些函数将在整个解码过程中使用。为简洁起见,我们将使用伪代码来描述这些函数,但对于感兴趣的人,完整的实现可以在这里找到。
如果你不关注辅助函数细节,可以跳过,直接看解码过程
首先,我们将定义一个名为get_padding的函数,该函数接受bytes: &[u8]参数,用于确定 calldata 中的字是左填充还是右填充。
snippet.rs
pub enum Padding {
Left,
Right,
None,
}
/// Given a string of bytes, determine if it is left or right padded.
fn get_padding(bytes: &[u8]) -> Padding {
// 1. find the indices of all null-bytes in the string
// 2. if any of the following are true, we cannot determine the padding (return None):
// - there are no null bytes
// - neither the first nor last byte is null
// 3. if the first byte of the string is null and the last byte is not, return Left
// 4. if the last byte of the string is null and the first byte is not, return Right
// 5. find indices of all non-null bytes in the string
// 6. count the number of null-bytes on the LHS and RHS of the string
// - if the number of null-bytes on the LHS is greater than the number of null-bytes on the RHS, return Left
// - if the number of null-bytes on the RHS is greater than the number of null-bytes on the LHS, return Right
// - otherwise, return None
}接下来,我们将定义一个名为get_padding_size的函数,该函数返回字符串中填充字节的数量。
snippet.rs
1/// Given a string of bytes, return the number of padding bytes.
2fn get_padding_size(bytes: &[u8]) -> usize {
3 match get_padding(bytes) {
4 Padding::Left => {
5 // count the number of null bytes at the start of the string
6 }
7 Padding::Right => {
8 // count the number of null bytes at the end of the string
9 }
10 Padding::None => 0,
11 }
12}接下来,我们将定义一个名为byte_size_to_type的函数,该函数返回byte_size可能表示的所有潜在静态类型。例如,byte_size_to_type(1)返回vec!["bool", "uint8", "bytes1", "int8"])。
snippet.rs
1/// Given a byte size, return all potential static types that it could represent.
2fn byte_size_to_type(byte_size: usize) -> Vec<String> {
3 let mut potential_types = Vec::new();
4
5 match byte_size {
6 1 => potential_types.push("bool"),
7 15..20 => potential_types.push("address"), // We check for 15..20 because addresses may have leading null-bytes. This allows for up to 5 leading null-bytes.
8 _ => {},
9 }
10
11 // push standard types
12 potential_types.push(format!("uint{}", byte_size * 8));
13 potential_types.push(format!("bytes{byte_size}"));
14 potential_types.push(format!("int{}", byte_size * 8));
15
16 potential_types
17}我们还有一个简单的类型转换函数to_type,它将字符串转换为ParamType枚举变体。
snippet.rs
1/// A helper function that converts a string type to a ParamType.
2/// For example, "address" will be converted to [`ParamType::Address`].
3pub fn to_type(string: &str) -> ParamType {
4 ...
5}最后,我们将定义一个名为get_potential_types_for_word的函数,该函数返回 calldata 中字可能表示的所有潜在类型,以及字的最大字节数。
snippet.rs
1// Get minimum size needed to store the given word
2pub fn get_potential_types_for_word(word: &[u8]) -> (usize, Vec<String>) {
3 // get padding of the word, note this is a maximum
4 let padding_size = get_padding_size(word);
5
6 // get number of bytes padded
7 let data_size = word.len() - padding_size;
8 byte_size_to_type(data_size)
9}解码过程
现在我们有了辅助函数,我们可以开始解码原始 calldata。
- 解码过程的第一步是将 calldata 转换为字(分成 32 字节的块,删除函数选择器)列表。我们将这个列表称为
calldata_words。 - 现在我们创建一个名为
covered_words的HashSet<usize>。我们将使用它来跟踪我们已经覆盖的字,这样我们就不会意外地两次解码相同的字,错过解码字,或者错误地解码字。我们还将创建一个可变的名为potential_inputs的Vec<ParamType>,我们将使用它来跟踪函数输入的类型。
snippet.rs
// we're going to build a Vec<ParamType> of all possible types for each
let mut potential_inputs: Vec<ParamType> = Vec::new();
let mut covered_words: HashSet<usize> = HashSet::new();- 接下来,我们将使用
while循环来迭代calldata_words中的每个字。当calldata_words中的所有字都已被覆盖和解码时,循环将终止。以下是循环的每次迭代的样子:
let mut i = 0; // this is the current index in calldata_words
while covered_words.len() != calldata_words.len() {
let word = calldata_words[i];
// (1) try to decode the current word as an ABI-encoded dynamic type. if this succeeds,
// add the type to `potential_inputs` and add the indices of all words covered by this type
// to `covered_words`
if let Some(abi_encoded) = try_decode_dynamic_parameter(i, &calldata_words)? {
// convert the ABI-encoded type to a ParamType and add it to potential_inputs
let potential_type = to_type(&abi_encoded.ty);
potential_inputs.push(potential_type);
// extend covered_words with the indices of all words covered by this dynamic type
covered_words.extend(abi_encoded.coverages);
i += 1;
continue;
}
// (2) this is a static type, so we can just get the potential types for this word
let (_, mut potential_types) = get_potential_types_for_word(word);
// perform heuristics, since we can't determine the type of a word with 100% certainty
// - if we use right-padding, this is probably bytesN
// - if we use left-padding, this is probably uintN or intN
// - if we use no padding, this is probably bytes32
match get_padding(word) {
Padding::Left => potential_types
.retain(|t| t.starts_with("uint") || t.starts_with("address")),
_ => potential_types
.retain(|t| t.starts_with("bytes") || t.starts_with("string")),
}
// (4) convert the type with the highest potential to a ParamType and add it to `potential_inputs`
let potential_type =
to_type(potential_types.first().expect("potential types is empty"));
potential_inputs.push(potential_type);
// this word is now covered, so add it to `covered_words`
covered_words.insert(i);
i += 1;
}-
我们将尝试将当前字解码为 ABI 编码的动态类型。如果成功,我们将将该类型添加到
potential_inputs,并将由此类型覆盖的所有字的索引添加到covered_words。稍后我们将详细讨论这是如何工作的。 -
如果这不是动态类型,我们将尝试将此字解码为静态类型。稍后我们将详细讨论这是如何工作的。
注意: 如果f(arg1,...argn)是一个具有n个参数的函数,则 calldata 的前n个字要么是参数本身,要么是参数的偏移量。当我们解码了 calldata 的前n个字时,
covered_words将包含 calldata 中所有属于函数参数的字的索引。然后我们可以使用这个来确定函数的签名和其参数的类型。
解码静态类型
让我们从简单的情况开始:静态类型。给定一个不是 ABI 编码的动态类型的 calldata 字,我们可以使用我们之前定义的get_potential_types_for_word函数来确定字的潜在类型。
该函数将返回潜在类型的列表,以及字的最大字节数。我们将使用这个来通过执行一些简单的启发式方法来确定字的最可能类型:
-
bytesN和string始终是右填充的,因此如果这个字是右填充的,它很可能是bytesN或string。 -
uintN和intN始终是左填充的,因此如果这个字是左填充的,它很可能是uintN或intN。- 我们还可以检查填充是否为
00或ff,以指示数字是正数还是负数。如果填充是00,它很可能是uintN。如果填充是ff,它很可能是intN。
- 我们还可以检查填充是否为
-
如果这个字没有填充,它很可能是
bytes32。
解码动态类型
现在我们将转向更复杂的情况:ABI 编码的动态类型。让我们看看try_decode_dynamic_parameter在幕后是如何工作的:
pub fn try_decode_dynamic_parameter(
parameter_index: usize,
calldata_words: &[&str],
) -> Result<Option<AbiEncoded>, Error> {
// (1) initialize a [`HashSet<usize>`] called `word_coverages` with `parameter_index`
// this works similarly to `covered_words`, but is used to keep track of which
// words we've covered while attempting to ABI-decode the current word
let mut coverages = HashSet::from([parameter_index]);
// (2) the first validation step. this checks if the current word could be a valid
// pointer to an ABI-encoded dynamic type. if it is not, we return None.
let (byte_offset, word_offset) = match process_and_validate_word(parameter_index, calldata_words) {
Ok((byte_offset, word_offset)) => (byte_offset, word_offset),
Err(_) => return Ok(None),
};
// (3) the second validation step. this checks if the pointed-to word is a valid pointer to a word in
// `calldata_words`. if it is not, we return an [`Error::BoundsError`].
//
// note: `size` is the size of the ABI-encoded item. It varies depending on the type of the
// item. For example, the size of a `bytes` is the number of bytes in the encoded data, while
// for a dynamic-length array, the size is the number of elements in the array.
let size_word = calldata_words.get(word_offset.as_usize()).ok_or(Error::BoundsError)?;
let size = U256::from_str_radix(size_word, 16)?.min(U256::from(usize::MAX));
// (4) add the size word index to `word_coverages`, since this word is part of the ABI-encoded type
// and should not be decoded again
coverages.insert(word_offset.as_usize());
// (5) check if there are enough words left in the calldata to contain the ABI-encoded item.
// if there aren't, it doesn't necessarily mean that the calldata is invalid, but it does
// indicate that this type cannot be an array, since there aren't enough words left to store
// the array elements.
let data_start_word_offset = word_offset + 1;
let data_end_word_offset = data_start_word_offset + size;
match data_end_word_offset.cmp(&U256::from(calldata_words.len())) {
Ordering::Greater => try_decode_dynamic_parameter_bytes(
parameter_index,
calldata_words,
byte_offset,
word_offset,
data_start_word_offset,
size,
coverages,
),
_ => try_decode_dynamic_parameter_array(
parameter_index,
calldata_words,
byte_offset,
word_offset,
data_start_word_offset,
data_end_word_offset,
size,
coverages,
),
}
}- 我们使用
parameter_index初始化一个名为word_coverages(不要与covered_words混淆)的HashSet<usize>。我们将使用这个HashSet来跟踪我们在尝试 ABI 解码当前字时已经覆盖的字。如果我们成功解码了动态类型,这个HashSet将包含calldata_words中属于这种 ABI 编码类型的所有字的索引,并将在解码过程结束时与covered_words合并。 - 现在,我们将通过利用假设(3)来执行第一次验证步骤,该假设指出所有指向动态类型的指针都是:
- 大于零
- 可被 32 整除,因为这应该指向一个字的开头(动态类型的大小)。
- 接下来,我们将检查此指针是否实际有效,并指向
calldata_words中的有效字。如果不是,我们返回None。如果是,我们将解析字为U256,并将其称为size。我们还将添加word_offset到word_coverages,因为这个字(size)是 ABI 编码类型的一部分,不应再次解码。- 现在我们可以将
data_start_word_offset定义为word_offset + 1,因为在word_offset处的字是 ABI 编码类型的大小,数据从下一个字开始。这是这种动态类型的数据块的开始,我们稍后将使用它。data_end_word_offset是data_start_word_offset + size,因为数据块长为size个字。在bytes和string的情况下,我们稍后需要重新计算这个。
- 现在我们可以将
- 由于大小取决于项的类型,我们将执行一个简单的检查,看看 calldata 中是否还有足够的字来包含 ABI 编码的项目。如果没有,这并不一定意味着这不是一个有效的 ABI 编码类型,但它确实表明这种类型不能是数组,因为没有足够的字来存储数组元素。如果还有足够的字,我们将调用
try_decode_dynamic_parameter_array,稍后我们将介绍它。如果没有,我们将调用try_decode_dynamic_parameter_bytes。
解码bytes
让我们看看try_decode_dynamic_parameter_bytes在幕后是如何工作的:
fn try_decode_dynamic_parameter_bytes(
parameter_index: usize,
calldata_words: &[&str],
word: U256,
word_offset: U256,
data_start_word_offset: U256,
size: U256,
coverages: HashSet<usize>,
) -> Result<Option<AbiEncoded>, Error> {
let mut coverages = coverages;
// (1) join all words from `data_start_word_offset` to the end of `calldata_words`.
// this is where the encoded data may be stored.
let data_words = &calldata_words[data_start_word_offset.as_usize()..];
// (2) perform a quick validation check to see if there are enough remaining bytes
// to contain the ABI-encoded item. If there aren't, return an [`Error::BoundsError`].
if data_words.join("").len() / 2 < size.as_usize() {
return Err(Error::BoundsError);
}
// (3) calculate how many words are needed to store the encoded data with size `size`.
let word_count_for_size = U256::from((size.as_u32() as f32 / 32f32).ceil() as u32);
let data_end_word_offset = data_start_word_offset + word_count_for_size;
// (4) get the last word in `data_words`, so we can perform a size check. There should be
// `size % 32` bytes in this word, and the rest should be null bytes.
let last_word = data_words.get(word_count_for_size.as_usize() - 1).ok_or(Error::BoundsError)?;
let last_word_size = size.as_usize() % 32;
// if the padding size of this last word is greater than `32 - last_word_size`,
// there are too many bytes in the last word, and this is not a valid ABI-encoded type.
// return an [`Error::BoundsError`].
let padding_size = get_padding_size(last_word);
if padding_size > 32 - last_word_size {
return Err(Error::BoundsError);
}
// (5) we've covered all words from `data_start_word_offset` to `data_end_word_offset`,
// so add them to `word_coverages`.
for i in word_offset.as_usize()..data_end_word_offset.as_usize() {
coverages.insert(i);
}
Ok(Some(AbiEncoded { ty: String::from("bytes"), coverages }))
}- 首先,我们将连接从
data_start_word_offset(包含编码数据的calldata_words中的索引)到calldata_words末尾的所有字。这是编码数据可能存储的地方。我们将其称为data_words。这可能包含不是 ABI 编码类型的额外字,但没关系,因为我们稍后将检查编码数据的大小。 - 接下来,我们将执行一个快速验证检查,看看
data_words中是否有足够的剩余字节来包含 ABI 编码的项目。如果没有,我们将返回一个Error::BoundsError。 - 现在,我们将计算需要多少个字来存储大小为
size的编码数据。我们将其称为word_count_for_size。我们还将通过将word_count_for_size加上data_start_word_offset来计算data_words的末尾。我们将其称为data_end_word_offset。 - 现在,我们可以对
data_words中的最后一个字进行检查。这个最后一个字应该有size % 32个字节,并且其余部分应该是空字节。如果这个最后一个字的填充大小大于32 - last_word_size,则最后一个字中有太多的字节,这不是一个有效的 ABI 编码类型。我们将返回一个Error::BoundsError。 - 我们将
word_coverages扩展为data_start_word_offset到data_end_word_offset之间所有字的索引,因为我们现在已经覆盖了 ABI 编码类型的所有字。然后,我们将返回一个包含类型(bytes)和要在解码过程结束时与covered_words合并的覆盖范围的AbiEncoded结构体。
解码 string
解码 string 与解码 bytes 非常相似,只有一些细微的差异。让我们看看 try_decode_dynamic_parameter_string 是如何工作的:
fn try_decode_dynamic_parameter_string(
data_words: &[&str],
parameter_index: usize,
calldata_words: &[&str],
word: U256,
word_offset: U256,
data_start_word_offset: U256,
size: U256,
coverages: HashSet<usize>,
) -> Result<Option<AbiEncoded>, Error> {
let mut coverages = coverages;
// (1) check if the data words all have conforming padding
// we do this check because strings will typically be of the form:
// 0000000000000000000000000000000000000000000000000000000000000003 // length of 3
// 6f6e650000000000000000000000000000000000000000000000000000000000 // "one"
//
// so, if the data words have conforming padding, we can assume that this is not a string
// and is instead an array.
if data_words
.iter()
.map(|word| get_padding(word))
.all(|padding| padding == get_padding(data_words[0]))
{
return Ok(None)
}
// (3) calculate how many words are needed to store the encoded data with size `size`.
let word_count_for_size = U256::from((size.as_u32() as f32 / 32f32).ceil() as u32);
let data_end_word_offset = data_start_word_offset + word_count_for_size;
// (4) get the last word in `data_words`, so we can perform a size check. There should be
// `size % 32` bytes in this word, and the rest should be null bytes.
let last_word =
data_words.get(word_count_for_size.as_usize() - 1).ok_or(Error::BoundsError)?;
let last_word_size = size.as_usize() % 32;
// if the padding size of this last word is greater than `32 - last_word_size`,
// there are too many bytes in the last word, and this is not a valid ABI-encoded type.
// return an [`Error::BoundsError`].
let padding_size = get_padding_size(last_word);
if padding_size > 32 - last_word_size {
return Err(Error::BoundsError);
}
// (5) we've covered all words from `data_start_word_offset` to `data_end_word_offset`,
// so add them to `word_coverages`.
for i in word_offset.as_usize()..data_end_word_offset.as_usize() {
coverages.insert(i);
}
return Ok(Some(AbiEncoded { ty: String::from("string"), coverages: coverages.clone() }));
}你可能会注意到这几乎与 try_decode_dynamic_parameter_bytes 完全相同,只有一些细微的差异:
- 首先,我们对
data_words进行填充一致性检查。如果data_words中的所有字具有相同的填充,我们可以假定这不是一个string,而是一个数组。这是因为字符串通常是这种形式的:
0000000000000000000000000000000000000000000000000000000000000003 // length of 3
6f6e650000000000000000000000000000000000000000000000000000000000 // "one"其中第一个字是字符串的长度,其余的字是字符串本身。如果字具有一致的填充,我们可以假定这不是一个字符串,而是一个数组。
- 字符串验证的其余步骤与
try_decode_dynamic_parameter_bytes相同,因为strings本质上就是bytes!
解码 T[]
最后,我们将介绍如何解码动态长度数组。让我们看看 try_decode_dynamic_parameter_array 是如何工作的:
fn try_decode_dynamic_parameter_array(
parameter_index: usize,
calldata_words: &[&str],
word: U256,
word_offset: U256,
data_start_word_offset: U256,
data_end_word_offset: U256,
size: U256,
coverages: HashSet<usize>,
) -> Result<Option<AbiEncoded>, Error> {
let mut coverages = coverages;
// (1) join all words from `data_start_word_offset` to `data_end_word_offset`. This is where
// the encoded data may be stored.
let data_words =
&calldata_words[data_start_word_offset.as_usize()..data_end_word_offset.as_usize()];
// (2) first, check if this is a `string` type, since some string encodings may appear to be arrays.
if let Ok(Some(abi_encoded)) = try_decode_dynamic_parameter_string(
data_words,
parameter_index,
calldata_words,
word,
word_offset,
data_start_word_offset,
size,
coverages.clone(),
) {
return Ok(Some(abi_encoded));
}
// (3) this is not a `string` type, so we can assume that it is an array. we can extend
// `word_coverages` with the indices of all words from `data_start_word_offset` to `data_end_word_offset`,
// since we've now covered all words in the ABI-encoded type.
for i in word_offset.as_usize()..data_end_word_offset.as_usize() {
coverages.insert(i);
}
// (4) get the potential type of the array elements. under the hood, this function:
// - iterates over each word in `data_words`
// - checks if the word is a dynamic type by recursively calling `try_decode_dynamic_parameter`
// - if it is a dynamic type, we know the type of the array elements and can return it
// - if it is a static type, find the potential types that can represent each element
// in the array
let potential_type = get_potential_type(
data_words,
parameter_index,
calldata_words,
word,
data_start_word_offset,
&mut coverages,
);
let type_str = format!("{potential_type}[]");
Ok(Some(AbiEncoded { ty: type_str, coverages }))
}-
首先,我们将从
data_start_word_offset到data_end_word_offset的所有字连接起来。这是编码数据可能存储的地方。我们将称之为data_words。这将具有长度size,因为size是数组中元素的数量。 -
接下来,我们将检查这是否是
string类型,因为某些字符串编码可能看起来像数组。如果是,我们将在这里停止,并返回包含类型string和在解码过程结束时与covered_words连接的覆盖的AbiEncoded结构。 -
如果这不是
string类型,我们可以假定它是一个数组。我们可以扩展word_coverages,其中包括从data_start_word_offset到data_end_word_offset的所有字的索引,因为我们现在已经覆盖了 ABI 编码类型中的所有字。 -
现在,我们将获取数组元素的潜在类型。在底层,此函数:
-
遍历
data_words中的每个字 -
通过递归调用
try_decode_dynamic_parameter检查字是否为动态类型- 如果它是动态类型,我们就知道数组元素的类型,并且可以返回它
- 如果它是静态类型,找到可以表示数组中每个元素的潜在类型
我们将称这个潜在类型为
potential_type。然后,我们将返回一个包含类型{potential_type}[]和在解码过程结束时与covered_words连接的覆盖的AbiEncoded结构。 -
一个快速示例
现在我们已经介绍了解码过程,让我们快速走一遍示例。假设我们有以下 calldata(我们之前构建的):
snippet.asm
0x8be6524600000000000000000000000000000000000000000000000000000000000001230000000000000000000000000000000000000000000000000000000000000080313233343536373839300000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000e0000000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000004560000000000000000000000000000000000000000000000000000000000000789000000000000000000000000000000000000000000000000000000000000000d48656c6c6f2c20776f726c642100000000000000000000000000000000000000我们将开始将其转换为字列表:
snippet.asm
0000000000000000000000000000000000000000000000000000000000000123
0000000000000000000000000000000000000000000000000000000000000080
3132333435363738393000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000000000000e0
0000000000000000000000000000000000000000000000000000000000000002
0000000000000000000000000000000000000000000000000000000000000456
0000000000000000000000000000000000000000000000000000000000000789
000000000000000000000000000000000000000000000000000000000000000d
48656c6c6f2c20776f726c642100000000000000000000000000000000000000我们还将跟踪 covered_words 和 potential_inputs:
snippet.rs
let mut potential_inputs: Vec<ParamType> = Vec::new();
let mut covered_words: HashSet<usize> = HashSet::new();现在,我们将遍历 calldata_words 中的每个字:
snippet.asm
i = 0
word = 0000000000000000000000000000000000000000000000000000000000000123这个字不是 ABI 编码的动态类型,因为 U256::from(word) % 32 != 0,因此这不是指向 calldata_words 中的字的指针。我们将尝试将此字解码为静态类型:
snippet.rs
potential_types = ["uint16", "bytes2", "int16"]
get_padding(word) = Padding::Left因此,这个字可能是 uint16 或 int16。我们将 uint16 添加到 potential_inputs,并将 i 添加到 covered_words:
snippet.rs
potential_inputs = [ParamType::Uint(16)]
covered_words = [0]现在,我们将增加 i 并继续:
snippet.asm
i = 1
word = 0000000000000000000000000000000000000000000000000000000000000080这个字通过了第一个验证步骤,因为 U256::from(word) % 32 == 0。我们将尝试将此字解码为 ABI 编码的动态类型:
snippet.rs
// (1) calculate byte_offset and word_offset
byte_offset = 128
word_offset = 4
// (2) check if word_offset is a valid pointer to a word in calldata_words
size_word = calldata_words[4] = "0000000000000000000000000000000000000000000000000000000000000002"
size = U256::from(size_word) = 2
// (3) are there enough words for this to be an array?
data_start_word_offset = 5
data_end_word_offset = 7
len(calldata_words) = 9 // yes, there are enough words
// (4) decode as an array!
data_words = [
"0000000000000000000000000000000000000000000000000000000000000456",
"0000000000000000000000000000000000000000000000000000000000000789",
]
// (5) get potential type of array elements
potential_type = get_potential_type(
data_words,
parameter_index,
calldata_words,
word,
data_start_word_offset,
&mut coverages,
) = "uint16"
word_coverages = {1,4,5,6}因此,这可能是一个 uint16 数组。我们将 uint16[] 添加到 potential_inputs,并将 word_coverages 添加到 covered_words:
snippet.rs
potential_inputs = [ParamType::Uint(16), ParamType::Array(Box::new(ParamType::Uint(16)))]
covered_words = {0,1,4,5,6}现在,我们将增加 i 并继续:
snippet.asm
i = 2
word = 3132333435363738393000000000000000000000000000000000000000000000这个字不是 ABI 编码的动态类型,因为 U256::from(word) % 32 != 0,因此这不是指向 calldata_words 中的字的指针。我们将尝试将此字解码为静态类型:
snippet.rs
potential_types = ["uint80", "bytes10", "int80"]
get_padding(word) = Padding::Right因此,这个字可能是 bytes10。我们将 bytes10 添加到 potential_inputs,并将 i 添加到 covered_words:
snippet.rs
potential_inputs = [ParamType::Uint(16), ParamType::Array(Box::new(ParamType::Uint(16))), ParamType::Bytes(10)]
covered_words = {0,1,2,4,5,6}现在,我们将增加 i 并继续:
snippet.asm
i = 3
word = 00000000000000000000000000000000000000000000000000000000000000e0这个字通过了第一个验证步骤,因为 U256::from(word) % 32 == 0。我们将尝试将此字解码为 ABI 编码的动态类型:
snippet.rs
// (1) calculate byte_offset and word_offset
byte_offset = 224
word_offset = 7
// (2) check if word_offset is a valid pointer to a word in calldata_words
size_word = calldata_words[7] = "000000000000000000000000000000000000000000000000000000000000000d"
size = U256::from(size_word) = 13
// (3) are there enough words for this to be an array?
data_start_word_offset = 8
data_end_word_offset = 21
len(calldata_words) = 9 // no, there are not enough words
// (4) decode as bytes!
data_words = [
"48656c6c6f2c20776f726c642100000000000000000000000000000000000000"
]
// (5) we pass the padding check, since 32 - 13 = 19, and the padding size of this word is 19
// (6) we've covered all words from `data_start_word_offset` to `data_end_word_offset`,
// so add them to `word_coverages`.
word_coverages = {3,7,8}因此,这是一个 bytes。我们将 bytes 添加到 potential_inputs,并将 word_coverages 添加到 covered_words:
snippet.rs
1potential_inputs = [ParamType::Uint(16), ParamType::Array(Box::new(ParamType::Uint(16))), ParamType::Bytes(10), ParamType::Bytes]
2covered_words = {0,1,2,3,4,5,6,7,8}现在,我们已经覆盖了 calldata_words 中的所有字,所以我们完成了!我们最终的 potential_inputs 是:
snippet.rs
potential_inputs = [ParamType::Uint(16), ParamType::Array(Box::new(ParamType::Uint(16))), ParamType::Bytes(10), ParamType::Bytes]现在,我们可以使用这个来确定函数的签名,并解码 calldata 的其余部分。
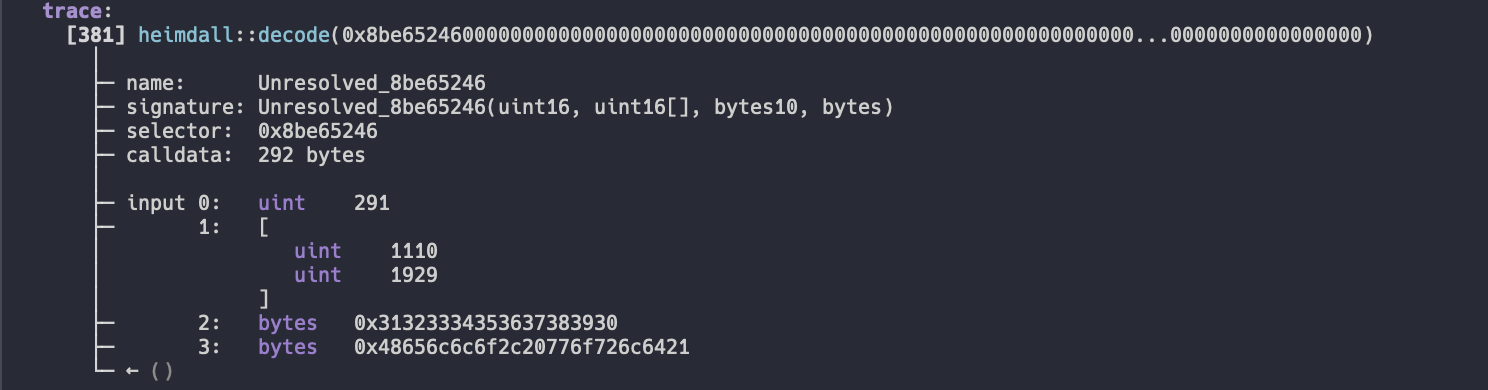
一切看起来很好!我们成功解码了原始 calldata,包括其中的动态类型!
注意:参数的大小,即第一个 uint16 和 uint16[] 比原始的 uint256 和 uint32[] 要小。这没问题,我们无能为力。
结论
在本文中,我们介绍了如何解码原始 calldata,包括动态类型,而无需合约 ABI 或签名解析。这个功能在 heimdall-rs 中是自动化的,我迫不及待想看到你用它创造出什么!
注意:这种方法可能并非 100%准确,并且可以进行迭代和改进。如果你注意到我遗漏的任何边缘情况或错误,请通过 提出问题或 PR 告诉我。
资源和引用
- Solidity 作者,“合约 ABI 规范” 文档:https://learnblockchain.cn/docs/solidity/abi-spec.html
- 这里宽松地使用了“解码”一词。EVM 并没有提供任何解码 calldata 的机制,
CALLDATALOAD/CALLDATACOPY只提供对原始字节的访问。例如,如果 calldata 包含一个address,将 calldata 转换为address的相应汇编代码是:
snippet.asm
AND(PUSH20(0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF), CALLDATALOAD(4))-
在大多数情况下是正确的。一些语言,如 huff,可能使用比四个字节更短的函数选择器。
-
签名是函数名称,后跟括号括起来的逗号分隔的参数类型列表。签名中不保留参数名称。
本翻译由 DeCert.me 协助支持, 在 DeCert 构建可信履历,为自己码一个未来。





