Solana 程序安全搭便车指南
- dwong
- 发布于 2024-03-22 21:36
- 阅读 7704
本文探讨了开发人员在创建 Solana 程序时可能遇到的常见漏洞。我们首先介绍了攻击者利用 Solana 程序的思维方式,涵盖了 Solana 的编程模型、Solana 设计的固有的受攻击者控制、潜在的攻击向量和常见的缓解策略。
本文由 bl0ckpain 共同撰写,他是一位安全研究员和智能合约开发者,曾与 Kudelski Security 和 Halborn 合作。
介绍
Solana 程序安全不仅仅是防止黑客窃取项目资金,而是确保程序按预期行为,符合项目规范和用户期望。
Solana 程序安全可能会影响 dApp 的性能、可扩展性和互操作性。因此,在构建面向消费者的应用程序之前,开发人员必须了解潜在的攻击向量和常见漏洞。
本文探讨了开发人员在创建 Solana 程序时可能遇到的常见漏洞。我们首先介绍了攻击者利用 Solana 程序的思维方式,涵盖了 Solana 的编程模型、Solana 设计的固有的受攻击者控制、潜在的攻击向量和常见的缓解策略。
然后,我们涵盖了各种不同的漏洞,提供了漏洞的解释以及不安全和安全的代码示例(如果适用)。
请注意,本文面向中级或高级读者,因为它假定读者了解 Solana 的编程模型和程序开发。本文不会介绍构建程序或 Solana 特定概念的过程 — 我们专注于检查常见漏洞并学习如何缓解它们。如果你是 Solana 的新手,我们建议你在阅读本文之前阅读以下先前的博客文章:
攻击者利用 Solana 程序的思维方式
Solana 的编程模型
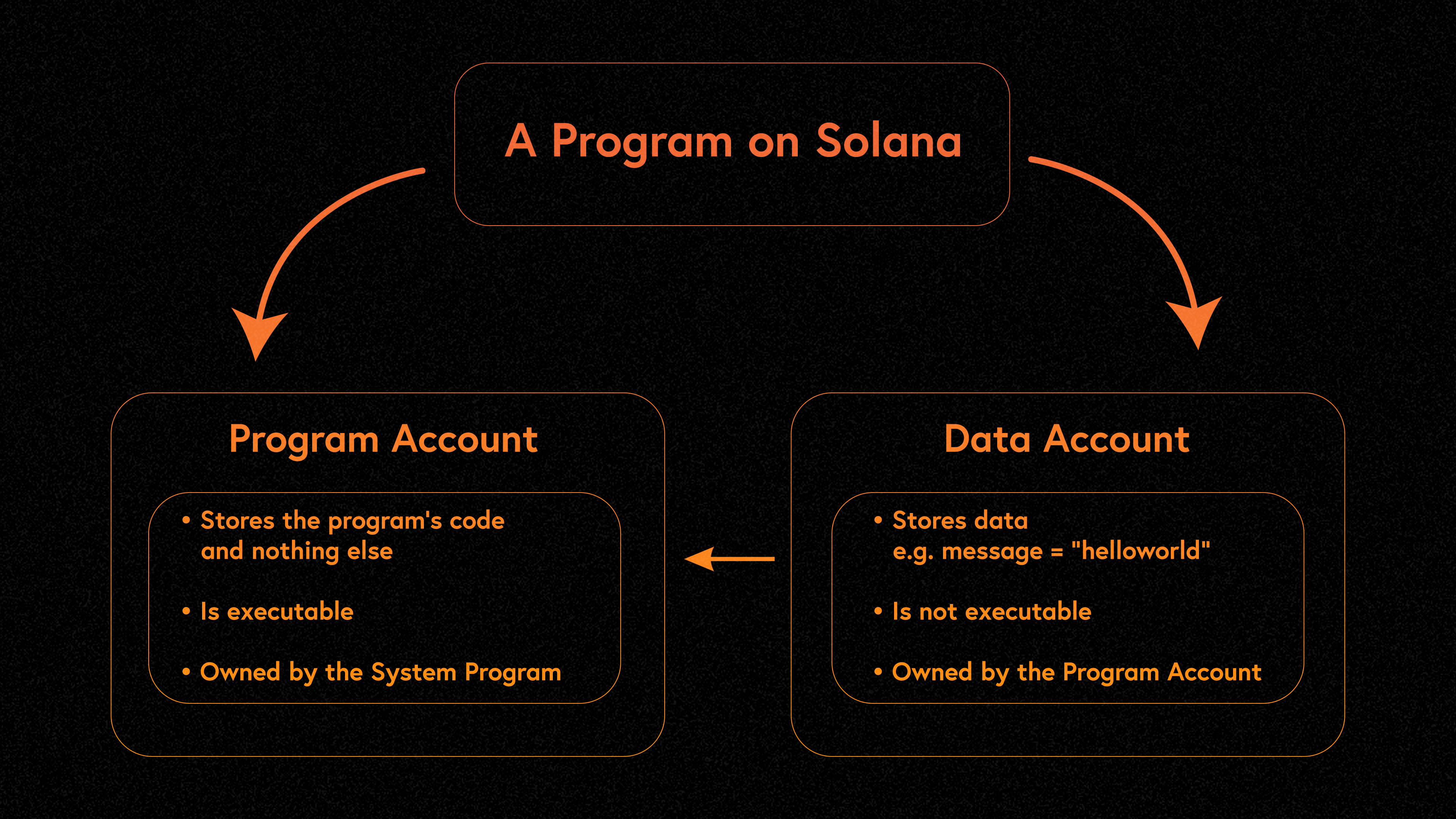
Solana 的编程模型塑造了构建在其网络上的应用程序的安全景观。在 Solana 上,账户充当数据的容器,类似于计算机上的文件。我们可以将账户分为两种一般类型:可执行和不可执行。可执行账户,或程序,是能够运行代码的账户。不可执行账户用于存储数据,但无法执行代码(因为它们不存储任何代码)。
代码和数据的解耦意味着程序是无状态的 —— 它们与在交易期间通过引用传递的其他账户中存储的数据进行交互。
Solana 是受攻击者控制的
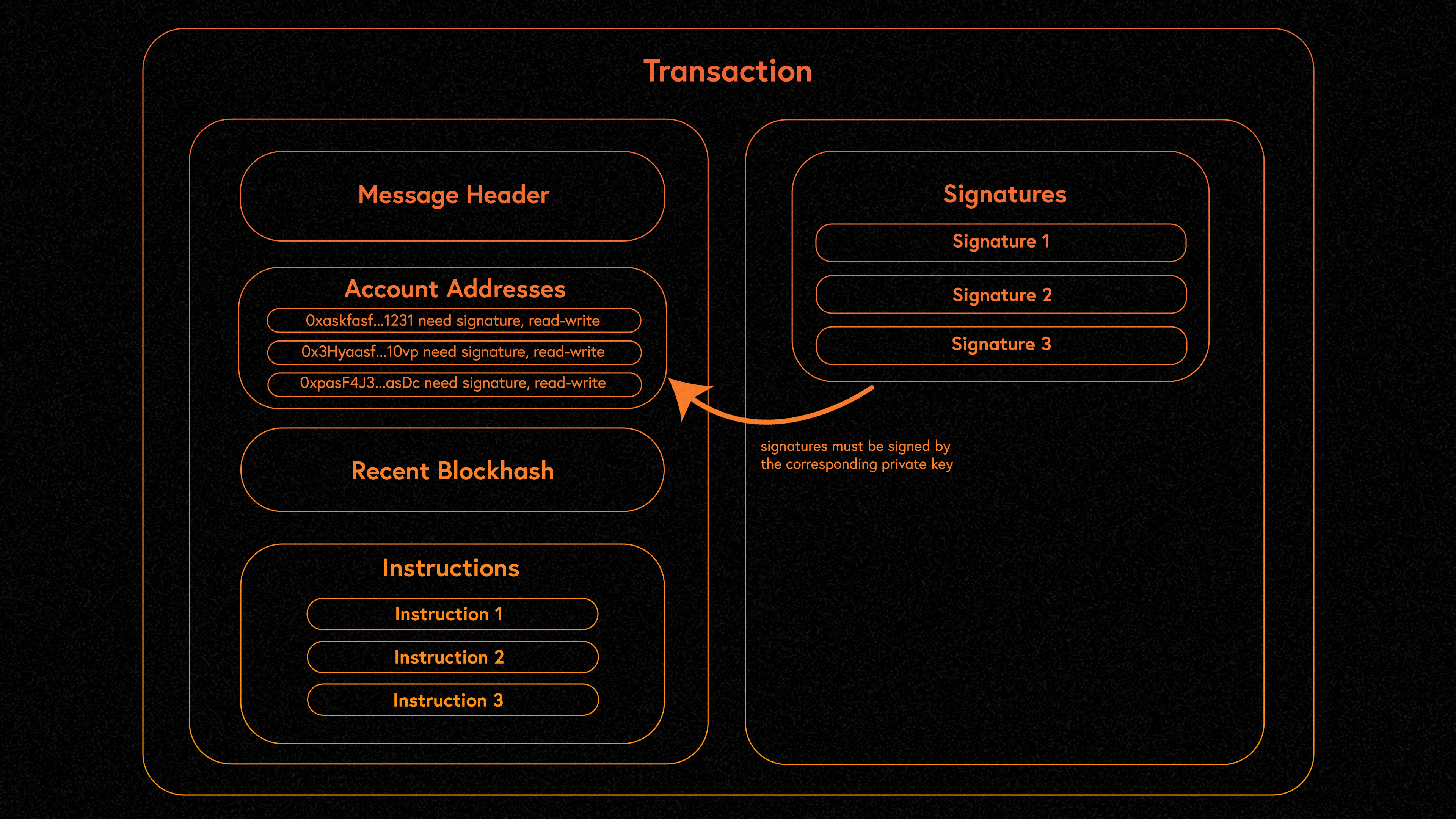
交易指定要调用的程序、账户列表和指令数据的字节数组。这个模型依赖于程序来解析和解释给定交易提供的账户和指令。
允许将任何账户传递到程序的函数中赋予攻击者对程序将操作的数据的重大控制权。了解 Solana 固有的受攻击者控制的编程模型对于开发安全程序至关重要。
鉴于攻击者能够将任何账户传递到程序的函数中,数据验证成为 Solana 程序安全的基本支柱。开发人员必须确保他们的程序能够区分合法和恶意输入。 这包括验证账户所有权,确保账户属于预期类型,以及账户是否是签名者。
潜在的攻击向量
Solana 独特的编程模型和执行环境产生了特定的攻击向量。了解这些向量对于开发人员来说是至关重要的,以保护他们的程序免受潜在的利用。这些攻击向量包括:
- 逻辑漏洞:程序逻辑中的缺陷可能被操纵以导致意外行为,例如资产损失或未经授权的访问。这还包括未能正确实现项目规范 —— 如果一个程序声称执行 x,那么它应该执行 x 及其所有特性
- 数据验证缺陷:不充分验证输入数据可能允许攻击者传入恶意数据并操纵程序状态或执行
- Rust 特定问题:尽管 Rust 具有安全特性,但不安全的代码块、并发问题和 panic 可能引入漏洞
- 访问控制漏洞:未能正确实现访问控制检查,例如验证账户所有者,可能导致恶意行为者进行未经授权的操作
- 算术和精度错误:溢出/下溢和精度错误可能被利用以获取财务利益或导致程序故障
- 跨程序调用(CPI)问题:处理 CPI 的缺陷可能导致意外的状态更改或错误,如果被调用的程序表现恶意或出乎意料
- 程序派生地址(PDAs)误用:不正确地生成或处理 PDAs 可能导致漏洞,攻击者可以劫持或伪造 PDAs 以获取未经授权的访问或操纵程序控制的账户
请注意,由于其执行模型的限制,Solana 上的递归性受到固有的限制。Solana 运行时将 CPI 限制为最大深度为四,并强制执行严格的账户规则,例如只允许账户的所有者修改其数据。 这些约束通过限制直接自递归并确保程序不能在中间状态下被无意中调用来防止递归攻击。
缓解策略
为了缓解这些潜在的攻击,开发人员应该采用严格的测试、代码审计和遵循最佳实践的组合:
- 实施全面的输入验证和访问控制检查
- 充分利用 Rust 的类型系统和安全特性,避免不必要的不安全代码
- 遵循 Solana 和 Rust 的安全最佳实践,并及时了解新的发展动态
- 在程序开发过程中进行内部代码审查,并使用自动化工具识别常见漏洞和逻辑错误
- 由知名第三方进行代码库审计,包括安全公司和独立安全研究人员
- 为你的程序创建漏洞赏金平台,以激励报告漏洞,而不是依赖灰帽黑客
接下来的章节将按字母顺序探讨不同的漏洞。每个章节将描述一个潜在的漏洞,解释如何缓解该漏洞,并在可能的情况下给出示例场景。
账户数据匹配
漏洞
当开发人员未能检查存储在账户上的数据是否与预期的一组值匹配时,就会出现账户数据匹配漏洞。在没有适当的数据验证检查的情况下,程序可能会意外地使用不正确或恶意替换的账户进行操作。
在涉及权限相关检查的情况下,这种漏洞尤为严重。
示例场景
考虑一个程序,用户可以将代币存入流动性池。该程序必须验证存入的代币属于存款人,并且代币所有者授权了存款。然而,该程序未能验证存款人是否拥有存入的代币:
pub fn deposit_tokens(ctx: Context<DepositTokens>, amount: u64) -> Result<()> {
let depositor_token_account = &ctx.accounts.depositor_token_account;
let liquidity_pool_account = &ctx.accounts.liquidity_pool_account;
// Missing the check to ensure depositor is the token account owner
// Token transfer logic
Ok(())
}
#[derive(Accounts)]
pub struct DepositTokens<'info> {
#[account(mut)]
pub depositor: Signer<'info>,
#[account(mut)]
pub depositor_token_account: Account<'info, TokenAccount>,
#[account(mut)]
pub liquidity_pool_account: Account<'info, TokenAccount>,
pub token_program: Program<'info, Token>
}推荐的缓解措施
为了缓解这一漏洞,开发人员可以实现显式检查,比较账户密钥和存储的数据与预期值。例如,验证存款人的公钥是否与用于存款的代币账户的所有者字段匹配:
pub fn deposit_tokens(ctx: Context<DepositTokens>, amount: u64) -> Result<()> {
let depositor_token_account = &ctx.accounts.depositor_token_account;
let liquidity_pool_account = &ctx.accounts.liquidity_pool_account;
// Ensure depositor is the token account owner
if depositor_token_account.owner != ctx.accounts.depositor.key() {
return Err(ProgramError::InvalidAccountData);
}
// Token transfer logic
Ok(())
}开发人员还可以使用 Anchor 的 has_one 和 constraint 属性来声明性地强制执行数据验证检查。使用我们上面的示例,我们可以使用 constraint 属性来检查存款人的公钥和存款代币账户的所有者是否相等:
#[derive(Accounts)]
pub struct DepositTokens<'info> {
#[account(mut)]
pub depositor: Signer<'info>,
#[account(
mut,
constraint = depositor_token_account.owner == depositor.key()
)]
pub depositor_token_account: Account<'info, TokenAccount>,
#[account(mut)]
pub liquidity_pool_account: Account<'info, TokenAccount>,
pub token_program: Program<'info, Token>
}账户数据重新分配
漏洞
在 Anchor 中,AccountInfo 结构提供的 realloc 函数引入了与内存管理相关的微妙漏洞。该函数允许重新分配账户数据大小,这对程序内的动态数据处理可能很有用。然而,不正确使用 realloc 可能导致意外后果,包括浪费计算单元或潜在地暴露陈旧数据。
realloc 方法有两个参数:
- new_len:指定账户数据的新长度的 usize
- zero_init:确定新内存空间是否应进行零初始化的 bool
realloc 定义如下:
pub fn realloc(
&self,
new_len: usize,
zero_init: bool
) -> Result<(), ProgramError>账户数据分配的内存在程序入口点已经进行了零初始化。这意味着在单个交易内将数据重新分配到更大的大小时,新的内存空间已经被清零。
重新清零这些内存是不必要的,并导致额外的计算单元消耗。相反,在同一交易内将数据大小减小然后再次增加时,如果 zero_init 为 false,可能会暴露陈旧数据。
示例场景
考虑一个代币质押程序,在单个交易内,质押信息的数量(例如,质押者地址和金额)可以动态增加或减少。这可能发生在批处理场景中,其中多个质押根据某些条件进行调整:
pub fn adjust_stakes(ctx: Context<AdjustStakes>, adjustments: Vec<StakeAdjustments>) -> ProgramResult {
// Logic to adjust stakes based on the adjustments provided
for adjustment in adjustments {
// Adjust stake logic
}
// Determine if we need to increase or decrease the data size
let current_data_len = ctx.accounts.staking_data.data_len();
let required_data_len = calculate_required_data_len(&adjustments);
if required_data_len != current_data_len {
ctx.accounts.staking_data.realloc(required_data_len, false)?;
}
Ok(())
}
#[derive(Accounts)]
pub struct AdjustStakes<'info> {
#[account(mut)]
staking_data: AccountInfo<'info>,
// Other relevant accounts
}在这种情况下,adjust_stakes 可能需要重新分配 staking_data 以适应调整所需的大小。如果数据大小被减小以移除质押信息,然后在同一交易内再次增加,将 zero_init 设置为 false 可能会暴露陈旧数据。
推荐的缓解措施
为了缓解这个问题,谨慎使用 zero_init 参数至关重要:
- 在在先前减少后增加数据大小时,将 zero_init 设置为 true。这样可以确保任何新的内存空间都经过零初始化,防止暴露陈旧数据
- 在同一交易调用中增加数据大小而没有先前减少时,将 zero_init 设置为 false,因为内存已经被零初始化
开发人员应该使用地址查找表(ALTs) 来代替重新分配数据以满足特定大小要求。
ALTs 允许开发人员通过在单个链上账户中存储多达 256 个地址来压缩交易数据。然后,表中的每个地址可以由 1 字节索引引用,大大减少了给定交易中地址引用所需的数据量。ALTs 对于需要动态账户交互而无需频繁调整内存大小的场景更加有用。
账户重新加载
漏洞
当开发人员在执行 CPI 后未更新反序列化账户时,会出现账户重新加载漏洞。Anchor 在执行 CPI 后不会自动刷新反序列化账户的状态。
这可能导致程序逻辑基于陈旧数据运行,从而导致逻辑错误或不正确的计算。
示例场景
考虑一个协议,用户可以质押代币以随时间获得奖励。促进此功能的程序包括根据某些条件或外部触发器更新用户质押奖励的功能。
通过 CPI 到奖励分配程序来计算并更新用户的奖励。然而,该程序在 CPI 后未更新原始质押账户以反映新的奖励余额:
pub fn update_rewards(ctx: Context<UpdateStakingRewards>, amount: u64) -> Result<()> {
let staking_seeds = &[b"stake", ctx.accounts.staker.key().as_ref(), &[ctx.accounts.staking_account.bump]];
let cpi_accounts = UpdateRewards {
staking_account: ctx.accounts.staking_account.to_account_info(),
};
let cpi_program = ctx.accounts.rewards_distribution_program.to_account_info();
let cpi_ctx = CpiContext::new_with_signer(cpi_program, cpi_accounts, staking_seeds);
rewards_distribution::cpi::update_rewards(cpi_ctx, amount)?;
// Attempt to log the "updated" reward balance
msg!("Rewards: {}", ctx.accounts.staking_account.rewards);
// Logic that uses the stale ctx.accounts.staking_account.rewards
Ok(())
}
#[derive(Accounts)]
pub struct UpdateStakingRewards<'info> {
#[account(mut)]
pub staker: Signer<'info>,
#[account(
mut,
seeds = [b"stake", staker.key().as_ref()],
bump,
)]
pub staking_account: Account<'info, StakingAccount>,
pub rewards_distribution_program: Program<'info, RewardsDistribution>,
}
#[account]
pub struct StakingAccount {
pub staker: Pubkey,
pub stake_amount: u64,
pub rewards: u64,
pub bump: u8,
}在这个示例中,update_rewards 函数尝试通过 CPI 调用到奖励分配程序来更新用户质押账户的奖励。最初,程序在 CPI 后记录 ctx.accounts.staking_account.rewards(即奖励余额),然后继续使用陈旧的 ctx.accounts.staking_account.rewards 数据的逻辑。问题在于,在 CPI 后质押账户的状态未自动更新,这就是数据陈旧的原因。
推荐的缓解措施
为了缓解这个问题,显式调用 Anchor 的 reload 方法来从存储中重新加载给定账户。在 CPI 后重新加载账户将准确反映其状态:
pub fn update_rewards(ctx: Context<UpdateStakingRewards>, amount: u64) -> Result<()> {
let staking_seeds = &[b"stake", ctx.accounts.staker.key().as_ref(), &[ctx.accounts.staking_account.bump]];
let cpi_accounts = UpdateRewards {
staking_account: ctx.accounts.staking_account.to_account_info(),
};
let cpi_program = ctx.accounts.rewards_distribution_program.to_account_info();
let cpi_ctx = CpiContext::new_with_signer(cpi_program, cpi_accounts, staking_seeds);
rewards_distribution::cpi::update_rewards(cpi_ctx, amount)?;
// Reload the staking account to reflect the updated reward balance
ctx.accounts.staking_account.reload()?;
// Log the updated reward balance
msg!("Rewards: {}", ctx.accounts.staking_account.rewards);
// Logic that uses ctx.accounts.staking_account.rewards
Ok(())
}任意 CPI
漏洞
当程序调用另一个程序而不验证目标程序的身份时,就会发生任意 CPI。
这种漏洞存在是因为 Solana 运行时允许任何程序调用另一个程序,只要调用者具有被调用程序的程序 ID 并遵守被调用程序的接口。
如果程序基于用户输入执行 CPI 而不验证被调用程序的程序 ID,它可能在受攻击者控制的程序中执行代码。
示例场景
考虑一个根据参与者对项目的贡献分发奖励的程序。在分发奖励后,程序记录详细信息在一个单独的分类帐程序中以进行审计和跟踪。
假定分类帐程序是一个受信任的程序,提供公共接口以跟踪来自授权程序的特定条目。程序包括一个用于分发和记录奖励的功能,该功能接受分类帐程序作为账户。
然而,该功能在进行 CPI 到分类帐程序之前未验证提供的 ledger_program:
pub fn distribute_and_record_rewards(ctx: Context<DistributeAndRecord>, reward_amount: u64) -> ProgramResult {
// Reward distribution logic
let instruction = custom_ledger_program::instruction::record_transaction(
&ctx.accounts.ledger_program.key(),
&ctx.accounts.reward_account.key(),
reward_amount,
)?;
invoke(
&instruction,
&[
ctx.accounts.reward_account.clone(),
ctx.accounts.ledger_program.clone(),
],
)
}
#[derive(Accounts)]
pub struct DistributeAndRecord<'info> {
reward_account: AccountInfo<'info>,
ledger_program: AccountInfo<'info>,
}攻击者可以通过将恶意程序的 ID 作为 ledger_program 传递来利用这一点,导致意外后果。
推荐的缓解措施
为了防范这种问题,开发人员可以添加一个检查,验证分类帐程序的身份后再执行 CPI。这个检查将确保 CPI 调用是针对预期的程序,从而防止任意 CPI:
pub fn distribute_and_record_rewards(ctx: Context<DistributeAndRecord>, reward_amount: u64) -> ProgramResult {
// Reward distribution logic
// Verify the ledger_program is the expected custom ledger program
if ctx.accounts.ledger_program.key() != &custom_ledger_program::ID {
return Err(ProgramError::IncorrectProgramId.into())
}
let instruction = custom_ledger_program::instruction::record_transaction(
&ctx.accounts.ledger_program.key(),
&ctx.accounts.reward_account.key(),
reward_amount,
)?;
invoke(
&instruction,
&[
ctx.accounts.reward_account.clone(),
ctx.accounts.ledger_program.clone(),
],
)
}
#[derive(Accounts)]
pub struct DistributeAndRecord<'info> {
reward_account: AccountInfo<'info>,
ledger_program: AccountInfo<'info>,
}如果程序是使用 Anchor 编写的,那么它可能具有一个公开可用的 CPI 模块。这使得从另一个 Anchor 程序中调用程序变得简单和安全。 Anchor CPI 模块会自动检查传入的程序地址是否与存储在模块中的程序地址匹配。另外,硬编码地址可以是一个可能的解决方案,而不是让用户传递它。
权限转移功能
漏洞
Solana 程序通常将特定的公钥指定为关键功能的权限,例如更新程序参数或提取资金。然而,无法将此权限转移至另一个地址可能会带来重大风险。 在团队变动、协议出售或权限被篡改等情况下,这种限制会变得棘手。
示例场景
考虑一个程序,其中全局管理员权限负责通过 set_params 函数设置特定协议参数。该程序没有包含更改全局管理员的机制:
pub fn set_params(ctx: Context<SetParams>, /* parameters to be set */) -> Result<()> {
require_keys_eq!(
ctx.accounts.current_admin.key(),
ctx.accounts.global_admin.authority,
);
// Logic to set parameters
}在这里,权限被静态定义,无法将其更新为新地址。
推荐的缓解措施
缓解此问题的安全方法是创建一个用于转移权限的两步流程。该流程允许当前权限提名新的 pending_authority,后者必须明确接受该角色。这不仅提供了权限转移功能,还可以防止意外转移或恶意接管。流程如下:
- 当前权限提名:当前权限通过调用 nominate_new_authority 提名新的 pending_authority,从而在程序状态中设置 pending_authority 字段
- 新权限接受:被提名的 pending_authority 调用 accept_authority 接受其新角色,将权限从当前权限转移至 pending_authority
这将看起来像这样:
pub fn nominate_new_authority(ctx: Context<NominateAuthority>, new_authority: Pubkey) -> Result<()> {
let state = &mut ctx.accounts.state;
require_keys_eq!(
state.authority,
ctx.accounts.current_authority.key()
);
state.pending_authority = Some(new_authority);
Ok(())
}
pub fn accept_authority(ctx: Context<AcceptAuthority>) -> Result<()> {
let state = &mut ctx.accounts.state;
require_keys_eq!(
Some(ctx.accounts.new_authority.key()),
state.pending_authority
);
state.authority = ctx.accounts.new_authority.key();
state.pending_authority = None;
Ok(())
}
#[derive(Accounts)]
pub struct NominateAuthority<'info> {
#[account(
mut,
has_one = authority,
)]
pub state: Account<'info, ProgramState>,
pub current_authority: Signer<'info>,
pub system_program: Program<'info, System>,
}
#[derive(Accounts)]
pub struct AcceptAuthority<'info> {
#[account(
mut,
constraint = state.pending_authority == Some(new_authority.key())
)]
pub state: Account<'info, ProgramState>,
pub new_authority: Signer<'info>,
}
#[account]
pub struct ProgramState {
pub authority: Pubkey,
pub pending_authority: Option<Pubkey>,
// Other relevant program state fields
}在此示例中,ProgramState 账户结构保存了当前 authority 和可选的 pending_authority。NominateAuthority 上下文确保当前权限签署交易,使其能够提名新权限。AcceptAuthority 上下文检查 pending_authority 是否与交易签署者匹配,使其能够接受并成为新的权限。这种设置确保了程序内权限的安全和受控转移。
Bump Seed 规范化
漏洞
Bump Seed 规范化是指在推导 PDA 时使用最高有效的 bump seed(即规范 bump)。使用规范 bump 是一种确定性和安全的方式,可以根据一组 seeds 找到地址。 未使用规范 bump 可能会导致漏洞,例如恶意行为者创建或操纵 PDAs,从而危及程序逻辑或数据完整性。
示例场景
考虑一个旨在创建唯一用户配置文件的程序,每个配置文件都使用 create_program_address 明确推导出一个相关的 PDA。该程序允许通过使用用户提供的 bump 来创建配置文件。然而,这是有问题的,因为它引入了使用非规范 bump 的风险:
pub fn create_profile(ctx: Context<CreateProfile>, user_id: u64, attributes: Vec<u8>, bump: u8) -> Result<()> {
// Explicitly derive the PDA using create_program_address and a user-provided bump
let seeds: &[&[u8]] = &[b"profile", &user_id.to_le_bytes(),&[bump]];
let (derived_address, _bump) = Pubkey::create_program_address(seeds, &ctx.program_id)?;
if derived_address != ctx.accounts.profile.key() {
return Err(ProgramError::InvalidSeeds);
}
let profile_pda = &mut ctx.accounts.profile;
profile_pda.user_id = user_id;
profile_pda.attributes = attributes;
Ok(())
}
#[derive(Accounts)]
pub struct CreateProfile<'info> {
#[account(mut)]
pub user: Signer<'info>,
/// The profile account, expected to be a PDA derived with the user_id and a user-provided bump seed
#[account(mut)]
pub profile: Account<'info, UserProfile>,
pub system_program: Program<'info, System>,
}
#[account]
pub struct UserProfile {
pub user_id: u64,
pub attributes: Vec<u8>,
}在这种情况下,程序使用 create_program_address 推导出 UserProfile PDA,其中包括一个用户提供的 bump。使用用户提供的 bump 是有问题的,因为它未能确保使用规范 bump。这将允许恶意行为者为相同的用户 ID 创建具有不同 bump 的多个 PDAs。
推荐的缓解措施
为了缓解此问题,我们可以重构我们的示例,使用 find_program_address 推导 PDA 并明确验证 bump seed:
pub fn create_profile(ctx: Context<CreateProfile>, user_id: u64, attributes: Vec<u8>) -> Result<()> {
// Securely derive the PDA using find_program_address to ensure the canonical bump is used
let seeds: &[&[u8]] = &[b"profile", user_id.to_le_bytes()];
let (derived_address, bump) = Pubkey::find_program_address(seeds, &ctx.program_id);
// Store the canonical bump in the profile for future validations
let profile_pda = &mut ctx.accounts.profile;
profile_pda.user_id = user_id;
profile_pda.attributes = attributes;
profile_pda.bump = bump;
Ok(())
}
#[derive(Accounts)]
#[instruction(user_id: u64)]
pub struct CreateProfile<'info> {
#[account(
init,
payer = user,
space = 8 + 1024 + 1,
seeds = [b"profile", user_id.to_le_bytes().as_ref()],
bump
)]
pub profile: Account<'info, UserProfile>,
#[account(mut)]
pub user: Signer<'info>,
pub system_program: Program<'info, System>,
}
#[account]
pub struct UserProfile {
pub user_id: u64,
pub attributes: Vec<u8>,
pub bump: u8,
}在这里,find_program_address 用于使用规范 bump seed 推导 PDA,以确保确定性和安全的 PDA 创建。规范 bump 存储在 UserProfile 账户中,允许在后续操作中进行高效和安全的验证。我们更喜欢 find_program_address 而不是 create_program_address,因为后者创建一个有效的 PDA,而无需搜索 bump seed。由于它不搜索 bump seed,它可能会对任何给定的 seeds 不可预测地返回错误,并且通常不适合创建 PDAs。find_program_address 在创建 PDA 时始终使用规范 bump。这是因为它通过各种 create_program_address 调用进行迭代,从 bump 为 255 开始,并且每次迭代递减。一旦找到有效地址,函数将返回推导出的 PDA 和用于推导它的规范 bump。
请注意,Anchor 通过其 seeds 和 bump 约束强制执行 PDA 推导的规范 bump,简化了整个流程,以确保安全和确定性的 PDA 创建和验证。
关闭账户
漏洞
在程序中不正确关闭账户可能会导致多种漏洞,包括“关闭”账户被重新初始化或被误用的潜在风险。 问题出在未正确标记账户为关闭或未能阻止其在后续交易中的重复使用。这一疏忽可能允许恶意行为者利用给定账户,导致程序内未经授权的操作或访问。
示例场景
考虑一个允许用户创建和关闭数据存储账户的程序。该程序通过转移其剩余的 lamports 来关闭账户:
pub fn close_account(ctx: Context<CloseAccount>) -> ProgramResult {
let account = ctx.accounts.data_account.to_account_info();
let destination = ctx.accounts.destination.to_account_info();
**destination.lamports.borrow_mut() = destination
.lamports()
.checked_add(account.lamports())
.unwrap();
**account.lamports.borrow_mut() = 0;
Ok(())
}
#[derive(Accounts)]
pub struct CloseAccount<'info> {
#[account(mut)]
pub data_account: Account<'info, Data>,
#[account(mut)]
pub destination: AccountInfo<'info>,
}
#[account]
pub struct Data {
data: u64,
}这是有问题的,因为程序未将账户数据清零或标记为关闭。仅仅转移其剩余的 lamports 并不能关闭账户。
推荐的缓解措施
为了缓解此问题,程序不仅应该转移所有的 lamports,还应该将账户数据清零,并使用一个区分符(即 "CLOSED_ACCOUNT_DISCRIMINATOR")标记它。程序还应该实施检查,以防止关闭的账户在未来交易中被重复使用:
use anchor_lang::__private::CLOSED_ACCOUNT_DISCRIMINATOR;
use anchor_lang::prelude::*;
use std::io::Cursor;
use std::ops::DerefMut;
// Other code
pub fn close_account(ctx: Context<CloseAccount>) -> ProgramResult {
let account = ctx.accounts.data_account.to_account_info();
let destination = ctx.accounts.destination.to_account_info();
**destination.lamports.borrow_mut() = destination
.lamports()
.checked_add(account.lamports())
.unwrap();
**account.lamports.borrow_mut() = 0;
// Zero out the account data
let mut data = account.try_borrow_mut_data()?;
for byte in data.deref_mut().iter_mut() {
*byte = 0;
}
// Mark the account as closed
let dst: &mut [u8] = &mut data;
let mut cursor = Cursor::new(dst);
cursor.write_all(&CLOSED_ACCOUNT_DISCRIMINATOR).unwrap();
Ok(())
}
pub fn force_defund(ctx: Context<ForceDefund>) -> ProgramResult {
let account = &ctx.accounts.account;
let data = account.try_borrow_data()?;
if data.len() < 8 || data[0..8] != CLOSED_ACCOUNT_DISCRIMINATOR {
return Err(ProgramError::InvalidAccountData);
}
let destination = ctx.accounts.destination.to_account_info();
**destination.lamports.borrow_mut() = destination
.lamports()
.checked_add(account.lamports())
.unwrap();
**account.lamports.borrow_mut() = 0;
Ok(())
}
#[derive(Accounts)]
pub struct ForceDefund<'info> {
#[account(mut)]
pub account: AccountInfo<'info>,
#[account(mut)]
pub destination: AccountInfo<'info>,
}
#[derive(Accounts)]
pub struct CloseAccount<'info> {
#[account(mut)]
pub data_account: Account<'info, Data>,
#[account(mut)]
pub destination: AccountInfo<'info>,
}
#[account]
pub struct Data {
data: u64,
}然而,仅仅清零数据并添加关闭区分符是不够的。用户可以通过在指令结束前退还账户的 lamports,阻止账户被垃圾回收。这将使账户处于一种奇怪的悬而未决状态,无法使用或被垃圾回收。 因此,我们添加了一个 force_defund 函数来解决这种边缘情况;现在任何人都可以退还关闭的账户的 lamports。
Anchor 通过 #[account(close = destination)] 约束简化了此过程,通过一次操作转移 lamports、清零数据并设置关闭账户区分符,自动化了账户的安全关闭。
重复可变账户
漏洞
重复可变账户是指将同一账户作为可变参数多次传递给一个指令的情况。这发生在一个指令需要两个相同类型的可变账户时。 恶意行为者可以两次传入相同的账户,导致账户以意外的方式发生变化(例如,覆盖数据)。此漏洞的严重程度取决于具体的情况。
示例场景
考虑一个旨在根据用户在某种链上活动中的参与情况奖励用户的程序。该程序有一个指令用于更新两个账户的余额:一个奖励账户和一个奖金账户。 用户应该根据特定的预定标准在一个账户中获得标准奖励,在另一个账户中根据特定的预定标准获得潜在的奖金:
pub fn distribute_rewards(ctx: Context<DistributeRewards>, reward_amount: u64, bonus_amount: u64) -> Result<()> {
let reward_account = &mut ctx.accounts.reward_account;
let bonus_reward = &mut ctx.accounts.bonus_account;
// Intended to increment the reward and bonus accounts separately
reward_account.balance += reward_amount;
bonus_account.balance += bonus_amount;
Ok(())
}
#[derive(Accounts)]
pub struct DistributeRewards<'info> {
#[account(mut)]
reward_account: Account<'info, RewardAccount>,
#[account(mut)]
bonus_account: Account<'info, RewardAccount>,
}
#[account]
pub struct RewardAccount {
pub balance: u64,
}如果恶意行为者将 reward_account 和 bonus_account 设置为相同的帐户,则帐户余额将错误更新两次。
推荐的缓解措施
为了缓解这个问题,在指令逻辑中添加一个检查,以验证这两个帐户的公钥不相同:
pub fn distribute_rewards(ctx: Context<DistributeRewards>, reward_amount: u64, bonus_amount: u64) -> Result<()> {
if ctx.accounts.reward_account.key() == ctx.accounts.bonus_account.key() {
return Err(ProgramError::InvalidArgument.into())
}
let reward_account = &mut ctx.accounts.reward_account;
let bonus_reward = &mut ctx.accounts.bonus_account;
// Intended to increment the reward and bonus accounts separately
reward_account.balance += reward_amount;
bonus_account.balance += bonus_amount;
Ok(())
}开发人员可以使用 Anchor 的帐户约束来对帐户进行更明确的检查。这可以通过使用 #[account] 属性和 constraint 关键字来实现:
pub fn distribute_rewards(ctx: Context<DistributeRewards>, reward_amount: u64, bonus_amount: u64) -> Result<()> {
let reward_account = &mut ctx.accounts.reward_account;
let bonus_reward = &mut ctx.accounts.bonus_account;
// Intended to increment the reward and bonus accounts separately
reward_account.balance += reward_amount;
bonus_account.balance += bonus_amount;
Ok(())
}
#[derive(Accounts)]
pub struct DistributeRewards<'info> {
#[account(
mut,
constraint = reward_account.key() != bonus_account.key()
)]
reward_account: Account<'info, RewardAccount>,
#[account(mut)]
bonus_account: Account<'info, RewardAccount>,
}
#[account]
pub struct RewardAccount {
pub balance: u64,
}抢先交易
漏洞
随着交易捆绑器的日益流行,抢先交易是 Solana 上建立的协议应该认真对待的一个问题。 随着 Jito 的内存池的移除 ,我们在这里提到抢先交易是指恶意行为者通过精心构造的交易来操纵预期值与实际值之间的差异。
示例场景
想象一个处理产品购买和竞价的协议,将卖方的定价信息存储在一个名为 SellInfo 的帐户中:
#[derive(Accounts)]
pub struct SellProduct<'info> {
product_listing: Account<'info, ProductListing>,
sale_token_mint: Account<'info, Mint>,
sale_token_destination: Account<'info, TokenAccount>,
product_owner: Signer<'info>,
purchaser_token_source: Account<'info, TokenAccount>,
product: Account<info, Product>
}
#[derive(Accounts)]
pub struct PurchaseProduct<'info> {
product_listing: Account<'info, ProductListing>,
token_destination: Account<'info, TokenAccount>,
token_source: Account<'info, TokenAccount>,
buyer: Signer<'info>,
product_account: Account<'info, Product>,
token_mint_sale: Account<'info, Mint>,
}
#[account]
pub struct ProductListing {
sale_price: u64,
token_mint: Pubkey,
destination_token_account: Pubkey,
product_owner: Pubkey,
product: Pubkey,
}要购买列出的 Product,买家必须传入与他们想要的产品相关的 ProductListing 帐户。但是如果卖方可以更改他们的 sale_price 会怎么样呢?
pub fn change_sale_price(ctx: Context<ChangeSalePrice>, new_price: u64) -> Result<()> {...}这将为卖方引入抢先交易的机会,特别是如果买家的购买交易不包括 expected_price 检查以确保他们支付的价格不超过他们想要购买的产品的预期价格。如果购买者提交一个交易来购买给定的 Product,卖方可以通过调用 change_sale_price,并且使用 Jito,确保这笔交易在购买者的交易之前被包含。恶意的卖方可以将 ProductListing 帐户中的价格更改为天价,使购买者不知情地被迫为 Product 支付比预期的要多得多的价格!
推荐的缓解措施
一个简单的解决方案是在交易的购买方包括 expected_price 检查,防止买家为他们想要购买的 Product 支付超出预期的价格:
pub fn purchase_product(ctx: Context<PurchaseProduct>, expected_price: u64) -> Result<()> {
assert!(ctx.accounts.product_listing.sale_price <= expected_price);
...
}不安全的初始化
与部署到 EVM 的合同不同,Solana 程序没有构造函数来设置状态变量。相反,它们是手动初始化的(通常是通过一个名为 initialize 或类似的函数)。初始化函数通常设置诸如程序的权限或创建构成部署的程序的基础的帐户(即,中央状态帐户或类似的东西)等数据。
由于初始化函数是手动调用的,而不是在程序部署时自动调用的,这个指令必须由程序开发团队控制的已知地址调用。 否则,攻击者可能会抢先初始化,可能使用攻击者控制的帐户设置程序。
一个常见的做法是使用程序的 upgrade_authority 作为授权地址来调用 initialize 函数,如果程序有升级权限的话。
不安全的示例及如何缓解
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
ctx.accounts.central_state.authority = authority.key();
...
}
#[derive(Accounts)]
pub struct Initialize<'info> {
authority: Signer<'info>,
#[account(mut,
init,
payer = authority,
space = CentralState::SIZE,
seeds = [b"central_state"],
bump
)]
central_state: Account<'info, CentralState>,
...
}
#[account]
pub struct CentralState {
authority: Pubkey,
...
}上面的示例是一个简化的初始化函数,用于为指令调用者设置 CentralState 帐户的权限。然而,这可以是任何调用 initialize 的帐户!如前所述,保护初始化函数的常见方法是使用程序的 upgrade_authority,在部署时已知。
下面是来自 Anchor 文档的示例,它使用约束来确保只有程序的升级权限可以调用 initialize:
use anchor_lang::prelude::*;
use crate::program::MyProgram;
declare_id!("Cum9tTyj5HwcEiAmhgaS7Bbj4UczCwsucrCkxRECzM4e");
#[program]
pub mod my_program {
use super::*;
pub fn set_initial_admin(
ctx: Context<SetInitialAdmin>,
admin_key: Pubkey
) -> Result<()> {
ctx.accounts.admin_settings.admin_key = admin_key;
Ok(())
}
pub fn set_admin(...){...}
pub fn set_settings(...){...}
}
#[account]
#[derive(Default, Debug)]
pub struct AdminSettings {
admin_key: Pubkey
}
#[derive(Accounts)]
pub struct SetInitialAdmin<'info> {
#[account(init, payer = authority, seeds = [b"admin"], bump)]
pub admin_settings: Account<'info, AdminSettings>,
#[account(mut)]
pub authority: Signer<'info>,
#[account(constraint = program.programdata_address()? == Some(program_data.key()))]
pub program: Program<'info, MyProgram>,
#[account(constraint = program_data.upgrade_authority_address == Some(authority.key()))]
pub program_data: Account<'info, ProgramData>,
pub system_program: Program<'info, System>,
}精度丢失
漏洞
精度丢失,尽管在外表上微不足道,却可能对程序构成重大威胁。它可能导致不正确的计算、套利机会和意外的程序行为。
算术运算中的精度丢失是错误的常见来源。在 Solana 程序中,尽可能使用定点算术是推荐的。这是因为程序只支持 Rust 浮点运算的有限子集 。如果程序尝试使用不受支持的浮点运算,运行时将返回一个未解析的符号错误。此外,与其整数等价物相比,浮点运算需要更多的指令。
使用定点算术和需要准确处理大量代币和分数金额可能会加剧精度丢失。
除法后的乘法
虽然结合律对大多数数学运算成立,但在计算机算术中应用它可能导致意外的精度丢失。
精度丢失的一个经典例子是在除法后进行乘法,这可能会产生与在除法前进行乘法不同的结果。例如,考虑以下表达式:(a / c) * b 和 (a * b) / c。从数学上讲,这些表达式是结合的 - 它们应该产生相同的结果。然而,在 Solana 和定点算术的背景下,操作的顺序非常重要。首先执行除法(a / c) 可能会导致精度丢失,如果商在乘以 b 之前被舍入到下一个整数。这可能导致比预期更小的结果。
相反,先乘以 (a * b) 再除以 c可能会保留更多的原始精度。这种差异可能导致不正确的计算,产生意外的程序行为和/或套利机会。
saturating_* 算术函数
虽然 saturating_* 算术函数通过将值限制在其最大或最小可能值来防止溢出和下溢,但如果意外达到了这个上限,它们可能导致微妙的错误和精度丢失。
当程序的逻辑假设仅仅通过饱和就能保证准确的结果,并忽略了潜在的精度或准确性丢失时,就会发生这种情况。
例如,想象一个旨在根据用户在特定期间内交易的代币数量计算和分发奖励的程序:
pub fn calculate_reward(transaction_amount: u64, reward_multiplier: u64) -> u64 {
transaction_amount.saturating_mul(reward_multiplier)
}考虑这样一个情景,transaction_amount 为 100,000 个代币,reward_multiplier 为每笔交易 100 个代币。将这两个值相乘将超过 u64 可以容纳的最大值。这意味着它们的乘积将被限制,导致用户被低估的大量精度丢失。
舍入误差
舍入操作是编程中常见的精度丢失。舍入方法的选择可能会显著影响计算的准确性和 Solana 程序的行为。try_round_u64() 函数将小数值四舍五入到最接近的整数。向上舍入是有问题的,因为它可能会人为地夸大值,导致实际计算和预期计算之间的差异。
考虑一个 Solana 程序,根据市场条件将抵押品转换为流动性。该程序使用 try_round_u64() 来对除法运算的结果进行四舍五入:
pub fn collateral_to_liquidity(&self, collateral_amount: u64) -> Result<u64, ProgramError> {
Decimal::from(collateral_amount)
.try_div(self.0)?
.try_round_u64()
}在这种情况下,向上舍入可能会导致发行的流动性代币多于抵押品所能证明的数量。恶意行为者可以利用这种差异进行套利攻击,通过有利的舍入结果从协议中提取价值。为了减轻风险,使用 try_floor_u64 进行向下舍入到最接近的整数。这种方法可以最大程度地减少人为膨胀的价值,并确保任何舍入都不会使用户在损害系统的情况下获得优势。
另外,可以实现逻辑来处理舍入可能明显影响结果的情况。这可能包括为舍入决策设置特定阈值或根据涉及的值的大小应用不同的逻辑。
缺失所有权检查
漏洞
所有权检查对于验证预期程序是否拥有参与交易或操作的账户至关重要。账户包括一个 owner 字段,该字段指示具有写入账户数据权限的程序。该字段确保只有授权的程序才能修改账户的状态。
此外,该字段对于确保传入指令的账户由预期程序拥有也非常有用。缺失所有权检查可能导致严重的漏洞,包括未经授权的资金转移和执行特权操作。
示例场景
考虑一个程序函数,定义为允许仅管理员从保险库中提取资金。该函数接收一个配置账户(即 config),并使用其 admin 字段来检查提供的管理员账户的公钥是否与存储在 config 账户中的公钥相同。然而,它未验证 config 账户的所有权,假设其是可信任的:
pub fn admin_token_withdraw(program_id: &Pubkey, accounts: &[AccountInfo], amount: u64) -> ProgramResult {
// Account setup
if config.admin != admin.pubkey() {
return Err(ProgramError::InvalidAdminAccount)
}
// Transfer funds logic
}恶意行为者可以通过提供一个他们控制的 config 账户,并具有与 config 账户中的 admin 字段匹配的账户,从而欺骗程序执行提取操作。
推荐的缓解措施
为了缓解这一问题,执行验证账户的 owner 字段的所有权检查:
pub fn admin_token_withdraw(program_id: &Pubkey, accounts: &[AccountInfo], amount: u64) -> ProgramResult {
// Account setup
if config.admin != admin.pubkey() {
return Err(ProgramError::InvalidAdminAccount)
}
if config.owner != program_id {
return Err(ProgramError::InvalidConfigAccount)
}
// Transfer funds logic
}Anchor 使用 Account 类型简化了此检查。Account<'info, T> 是 AccountInfo 的包装器,用于验证程序所有权并将底层数据反序列化为 T(即指定的账户类型)。这使开发人员可以轻松使用 Account<'info, T> 来验证账户所有权。开发人员还可以使用 #[account] 属性向给定账户添加 Owner trait。此 trait 定义了预期拥有账户的地址。此外,开发人员可以使用 owner 约束来定义应拥有给定账户的程序,如果它与当前执行的程序不同。例如,在编写预期账户为来自不同程序派生的 PDA 的指令时,这是有用的。owner 约束定义为 #[account(owner = <expr>)],其中 <expr> 是任意表达式。
只读账户
验证程序执行上下文中指定为只读的账户的有效性同样重要。这是至关重要的,因为恶意行为者可能传递具有任意或精心制作数据的账户,而不是合法账户。
这可能导致意外或有害的程序行为。开发人员仍应执行检查,以确保程序需要从中读取的账户是真实的且未被篡改。
这可能涉及将账户的地址与已知值进行验证,或者确认账户的所有者是否符合预期,特别是对于 sysvars(即只读系统账户,如 Clock 或 EpochSchedule)。使用 get() 方法访问 sysvars,该方法不需要任何手动地址或所有权检查。这是访问这些账户的更安全方法;然而,并非所有 sysvars 都支持 get() 方法。在这种情况下,使用它们的公共地址进行访问。
缺失签名者检查
漏洞
为了确保特定交易由特定钱包的私钥签名,交易使用钱包的私钥进行签名,以确保认证、完整性、不可否认性,并由特定钱包授权特定交易。通过要求交易使用发送方的私钥进行签名,Solana 的运行时可以验证正确的账户启动交易并且未被篡改。这种机制支撑着去中心化网络的无需信任的特性。 如果没有此验证,任何提供正确账户作为参数的账户都可以执行交易。这可能导致对特权信息、资金或功能的未经授权访问。 这种漏洞源于在执行某些特权功能之前未验证操作是否由适当账户的私钥签名。
示例场景
考虑以下函数:
pub fn update_admin(program_id: &Pubkey, accounts &[AccountInfo]) -> ProgramResult {
let account_iter = &mut accounts.iter();
let config = ConfigAccount::unpack(next_account_info(account_iter)?)?;
let admin = next_account_info(account_iter)?;
let new_admin = next_account_info (account_iter)?;
if admin.pubkey() != config.admin {
return Err(ProgramError::InvalidAdminAccount);
}
config.admin = new_admin.pubkey();
Ok(())
}该函数旨在更新程序的管理员。它包括一个检查,以确保当前管理员启动操作,这是良好的访问控制。然而,该函数未验证当前管理员的私钥是否签署了交易。 因此,调用此函数的任何人都可以传递正确的 admin 账户,使得 admin.pubkey() = config.admin,而不管调用此函数的账户是否实际上是当前管理员。这允许恶意行为者使用他们的账户作为新管理员传递执行指令,直接绕过当前管理员的授权需求。
推荐的缓解措施
程序必须包括检查以验证账户是否已由适当的钱包签名。这可以通过检查交易中涉及的账户的 AccountInfo::is_signer 字段来完成。程序可以通过检查执行特权操作的账户是否将 is_signer 标志设置为 true 来强制只有授权账户才能执行某些操作。
更新后的代码示例如下:
pub fn update_admin(program_id: &Pubkey, accounts &[AccountInfo]) -> ProgramResult {
let account_iter = &mut accounts.iter();
let config = ConfigAccount::unpack(next_account_info(account_iter)?)?;
let admin = next_account_info(account_iter)?;
let new_admin = next_account_info (account_iter)?;
if admin.pubkey() != config.admin {
return Err(ProgramError::InvalidAdminAccount);
}
// Add in a check for the admin's signature
if !admin.is_signer {
return Err(ProgramError::NotSigner);
}
config.admin = new_admin.pubkey();
Ok(())
}Anchor 使用 Signer<’info> 账户类型简化了整个流程。
溢出和下溢
漏洞
整数是没有分数部分的数字。Rust 将整数存储为固定大小的变量。这些变量由它们的 signedness(即有符号或无符号)和它们在内存中占用的空间量来定义。例如,u8 类型表示一个占用 8 位空间的无符号整数。它能够保存从 0 到 255 的值。存储超出该范围的值将导致整数溢出或下溢。 整数溢出是指变量超出其最大容量并环绕到其最小值。整数下溢是指变量低于其最小容量并环绕到其最大值。
Rust 在调试模式下编译时包括对整数溢出和下溢的检查。如果检测到这种情况,这些检查将导致程序在运行时panic。然而,在使用--release 标志编译释放模式时,Rust 不包括对整数溢出和下溢的检查。这种行为可能会引入潜在的漏洞,因为溢出或下溢会悄无声息地发生。 伯克利数据包过滤器(BPF) 工具链对 Solana 的开发环境至关重要,因为它编译 Solana 程序。cargo build-bpf 命令将 Rust 项目编译为 BPF 字节码以进行部署。问题在于它默认以释放模式编译程序。因此,Solana 程序容易受到整数溢出和下溢的影响。
示例场景
攻击者可以利用释放模式中潜在的溢出/下溢行为,特别是处理代币余额的函数。以以下示例为例:
pub fn process_instruction(
_program_id: & Pubkey,
accounts: [&AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
let account_info_iter = &mut accounts.iter();
let account = next_account_info(account_info_iter)?;
let mut balance: u8 = account.data.borrow()[0];
let tokens_to_subtract: u8 = 100;
balance = balance - tokens_to_subtract;
account.data.borrow_mut()[0] = balance;
msg!("Updated balance to {}", balance);
Ok(())
}该函数假设余额简单地存储在第一个字节中。它获取账户的余额并从中减去 tokens_to_subtract。如果用户的余额小于 tokens_to_subtract,将会导致下溢。例如,拥有 10 个代币的用户将下溢为 165 个代币的总余额。
推荐的缓解措施
overflow-checks
缓解此漏洞的最简单方法是在项目的 Cargo.toml 文件中将关键字 overflow-checks 设置为 true。在这种情况下,Rust 将在编译器中添加溢出和下溢检查。然而,添加溢出和下溢检查会增加计算成本 。在需要优化计算的情况下,将 overflow-checks 设置为 false 可能更有利。
checked_* 算术
在程序中使用 Rust 的 checked_* 算术函数,可以有策略地检查溢出和下溢。如果发生溢出或下溢,这些函数将返回 None。这使得程序可以优雅地处理错误。例如,你可以将先前的代码重构为:
pub fn process_instruction(
_program_id: & Pubkey,
accounts: [&AccountInfo],
_instruction_data: &[u8],
) -> ProgramResult {
let account_info_iter = &mut accounts.iter();
let account = next_account_info(account_info_iter)?;
let mut balance: u8 = account.data.borrow()[0];
let tokens_to_subtract: u8 = 100;
match balance.checked_sub(tokens_to_subtract) {
Some(new_balance) => {
account.data.borrow_mut()[0] = new_balance;
msg!("Updated balance to {}", new_balance);
},
None => {
return Err(ProgramErrorr::InsufficientFunds);
}
}
Ok(())
}在修改后的示例中,使用 checked_sub 从 balance 中减去 tokens_to_subtract。因此,如果 balance 足以 cover 减法,checked_sub 将返回 Some(new_balance)。程序将继续安全地更新账户余额并记录它。然而,如果减法会导致下溢,checked_sub 将返回 None,我们可以通过返回错误来处理它。
Checked Math Macro
Checked Math是一个过程宏 ,用于在不大幅改变这些表达式的情况下改变检查数学表达式的属性。checked_*算术函数的问题在于失去了数学符号。相反,必须使用笨拙的方法,如 a.checked_add(b).unwrap(),而不是 a + b。例如,如果我们想使用 checked 算术函数编写 (x * y) + z,我们将编写 x.checked_mul(y).unwrap().checked_add(z).unwrap()。
相反,使用 Checked Math 宏的以下表达式将如下所示:
use checked_math::checked_math as cm;
cm!((x * y) + z).unwrap()这样更方便编写,保留了表达式的数学符号,并且只需要一个 .unwrap()。这是因为该宏将正常的数学表达式转换为一个表达式,如果任何检查步骤返回 None,则返回 None。如果成功,将返回 Some(_),这就是为什么我们在最后展开表达式。
强制转换
同样,使用 as 关键字在不进行适当检查的情况下在整数类型之间进行强制转换可能会引入整数溢出或下溢漏洞。这是因为强制转换可能以意想不到的方式截断或扩展值。当从较大的整数类型转换为较小的整数类型(例如 u64 到 u32)时,Rust 将截断原始值中不适合目标类型的高位。当从较小的整数类型转换为较大的整数类型(例如 i16 到 i32)时,Rust 将扩展该值。对于无符号类型来说,这很简单。然而,这可能会导致有符号整数的符号扩展 ,从而引入意外的负值。
推荐的缓解措施
使用 Rust 的安全转换方法来缓解这种漏洞。这包括诸如 try_from 和from等方法。使用 try_from 将返回一个 Result 类型,允许明确处理值不适合目标类型的情况。使用 Rust 的 from 方法可以用于安全的、隐式的转换,用于保证无损失的转换(例如 u8 到 u32)。例如,假设程序需要安全地将 u64代币数量转换为 u32类型进行处理。那么,它可以这样做:
pub fn convert_token_amount(amount: u64) -> Result<u32, ProgramError> {
u32::try_from(amount).map_err(|_| ProgramError::InvalidArgument)
}在这个例子中,如果 amount 超过了 u32 可以容纳的最大值(即 4,294,967,295),转换将失败,程序将返回错误。这可以防止潜在的溢出/下溢发生。
PDA 共享
漏洞
PDA 共享是一种常见的漏洞,当相同的 PDA 在多个权限域或角色之间使用时会出现。这可能允许恶意行为者通过错误使用 PDAs 作为签名者而无需进行适当的访问控制检查,从而访问不属于他们的数据或资金。
示例场景
考虑一个旨在促进代币质押和分发奖励的程序。该程序使用单个 PDA 将代币转入给定池并提取奖励。PDA 是使用静态种子(例如,质押池的名称)派生的,使其在所有操作中都是通用的:
pub fn stake_tokens(ctx: Context<StakeTokens>, amount: u64) -> ProgramResult {
// Logic to stake tokens
Ok(())
}
pub fn withdraw_rewards(ctx: Context<WithdrawRewards>, amount: u64) -> ProgramResult {
// Logic to withdraw rewards
Ok(())
}
#[derive(Accounts)]
pub struct StakeTokens<'info> {
#[account(
mut,
seeds = [b"staking_pool_pda"],
bump
)]
staking_pool: AccountInfo<'info>,
// Other staking-related accounts
}
#[derive(Accounts)]
pub struct WithdrawRewards<'info> {
#[account(
mut,
seeds = [b"staking_pool_pda"],
bump
)]
rewards_pool: AccountInfo<'info>,
// Other rewards withdrawal-related accounts
}这是有问题的,因为质押和奖励提取功能依赖于从 staking_pool_pda 派生的相同 PDA。这可能允许用户操纵合约以未经授权地提取奖励或操纵质押。
推荐的缓解措施
为不同的功能使用不同的 PDA 来缓解此漏洞。确保每个 PDA 都服务于特定的上下文,并且是使用唯一的、特定于操作的种子派生的:
pub fn stake_tokens(ctx: Context<StakeTokens>, amount: u64) -> ProgramResult {
// Logic to stake tokens
Ok(())
}
pub fn withdraw_rewards(ctx: Context<WithdrawRewards>, amount: u64) -> ProgramResult {
// Logic to withdraw rewards
Ok(())
}
#[derive(Accounts)]
pub struct StakeTokens<'info> {
#[account(
mut,
seeds = [b"staking_pool", &staking_pool.key().as_ref()],
bump
)]
staking_pool: AccountInfo<'info>,
// Other staking-related accounts
}
#[derive(Accounts)]
pub struct WithdrawRewards<'info> {
#[account(
mut,
seeds = [b"rewards_pool", &rewards_pool.key().as_ref()],
bump
)]
rewards_pool: AccountInfo<'info>,
// Other rewards withdrawal-related accounts
}在上面的示例中,用于质押代币和提取奖励的 PDA 是使用不同的种子(staking_pool 和 rewards_pool)与特定账户的密钥相结合派生的。这确保了 PDA 与其预期功能的唯一绑定,从而减轻了未经授权操作的风险。
剩余账户
漏洞
ctx.remaining_accounts 提供了一种将额外账户传递到最初未指定的 Accounts 结构中的函数的方法。这为开发人员提供了更大的灵活性,使他们能够处理需要动态数量账户的情况(即,处理可变数量的用户或与不同程序交互的情况)。然而,这种增加的灵活性伴随着一个警告:通过 ctx.remaining_accounts 传递的账户不会经过与 Accounts 结构中定义的账户相同的验证。因为 ctx.remaining_accounts 不会验证传入的账户,恶意行为者可以通过传入程序未打算与之交互的账户来利用这一点,从而导致未经授权的操作或访问。
示例场景
考虑一个使用 ctx.remaining_accounts 接收用户 PDA 并动态计算奖励的奖励计划:
pub fn calculate_rewards(ctx: Context<CalculateRewards>) -> Result<()> {
let rewards_account = &ctx.accounts.rewards_account;
let authority = &ctx.accounts.authority;
// Iterate over accounts passed in via ctx.remaining_accounts
for user_pda_info in ctx.remaining_accounts.iter() {
// logic to check user activity and calculate rewards
}
// Logic to distribute calculated rewards
Ok(())
}
#[derive(Accounts)]
pub struct CalculateRewards<'info> {
#[account(mut)]
pub rewards_account: Account<'info, RewardsAccount>,
pub authority : Signer<'info>,
}
#[account]
pub struct RewardsAccount {
pub total_rewards: u64,
// Other relevant fields
}问题在于没有明确的检查来验证通过 ctx.remaining_accounts 传递的帐户,这意味着它未能确保只处理有效和符合条件的用户帐户以计算和分发奖励。 因此,恶意行为者可以传入他们不拥有的帐户,或者通过自己创建的帐户来获取比他们实际应得的更多奖励。
推荐的缓解措施
为了减轻这种漏洞,开发人员应在函数内手动验证每个帐户的有效性。这将包括检查帐户的所有者以确保其与预期用户匹配,并验证帐户内的任何相关数据。 通过整合这些手动检查,开发人员可以利用 ctx.remaining_acocunts 的灵活性,同时减轻未经授权的访问或操纵的风险。
Rust 特定错误
Rust 是 Solana 程序开发的通用语言。在 Rust 中开发会带来一系列独特的挑战和考虑,特别是围绕不安全代码和 Rust 特定错误。了解 Rust 的注意事项有助于开发安全、高效和可靠的程序。
不安全的 Rust
Rust 以其严格的所有权和借用系统实现内存安全性保证而备受赞誉。然而,这些保证有时可能会受到限制,因此 Rust 提供了 unsafe 关键字来绕过安全检查。unsafe Rust 主要用于以下四个上下文:
- 不安全函数:执行可能违反 Rust 安全性保证的操作的函数必须标记为 unsafe 关键字。例如,unsafe fn dangerous_function() {}
- 不安全块:允许进行不安全操作的代码块。例如,unsafe { // 不安全操作 }
- 不安全特性:暗示编译器无法验证的某些不变量的特性。例如,unsafe trait BadTrait {}
- 实现不安全特性:对 unsafe 特性的实现也必须标记为 unsafe。例如,unsafe impl UnsafeTrait for UnsafeType {}
不安全的 Rust 存在是因为静态分析是保守的。当编译器尝试确定代码是否遵守一定的保证时,最好拒绝一些有效代码的实例,而不是接受一些无效代码的实例。 尽管代码可能运行得很好,但是如果 Rust 编译器没有足够的信息来确信它是否遵守 Rust 的安全性保证,它将拒绝该代码。不安全代码允许开发人员自担风险地绕过这些检查。 此外,计算机硬件本质上是不安全的。开发人员必须允许进行不安全操作以使用 Rust 进行低级编程。
使用 unsafe 关键字,开发人员可以:
- 解引用原始指针:允许直接访问可以指向任何内存位置的原始指针,这可能不包含有效数据
- 调用不安全函数:这些函数可能不符合 Rust 的安全性保证,并可能导致潜在的未定义行为
- 访问可变静态变量:全局可变状态可能导致数据竞争
减轻不安全 Rust 的最佳方法是尽量减少 unsafe 块的使用。如果 unsafe 代码绝对必要,无论出于何种原因,确保它有很好的文档记录,定期审核,并且如果可能的话,封装在一个安全的抽象中,以便提供给程序的其余部分。
恐慌和错误管理
当 Rust 程序遇到不可恢复的错误并终止执行时,就会发生恐慌。恐慌用于未预料到的错误,不应该被捕获。 在 Solana 程序的上下文中,恐慌可能导致意外行为,因为运行时期望程序能够优雅地处理错误而不会崩溃。
发生恐慌时,Rust 开始展开堆栈并在进行清理时返回堆栈跟踪,其中包括有关涉及的错误的详细信息。这可能会向攻击者提供有关底层文件结构的信息。 虽然这并不直接适用于 Solana 程序,但程序使用的依赖项可能容易受到此类攻击的影响。确保依赖项保持最新,并使用不包含已知漏洞的版本。
常见的恐慌场景包括:
- 除零操作:尝试除以零时,Rust 会发生恐慌。因此,在执行除法之前始终检查零除数
- 数组索引越界:访问超出其边界的数组将导致恐慌。为减轻此问题,使用返回 Option 类型(如 get)的方法来安全访问数组元素
- 解包空值:对包含 None 值的 Option 调用 .unwrap() 将导致恐慌。在返回 Result 的函数中始终使用模式匹配或方法,如 unwrap_or、unwrap_or_else 或 ? 运算符
为减轻与恐慌相关的问题,至关重要的是避免引发恐慌的操作,验证可能导致问题操作的所有输入和条件,并对错误处理使用 Result 和 Option 类型。此外,编写全面的程序测试将有助于在部署之前发现和解决潜在的恐慌场景。
种子碰撞
漏洞
当用于生成 PDA 的不同输入(即种子和程序 ID)导致相同的 PDA 地址时,就会发生种子碰撞。 当 PDA 在程序中用于不同目的时,这可能会导致意外行为,包括拒绝服务攻击或完全妥协。
示例场景
考虑一个用于各种提案和倡议的去中心化投票平台的程序。为给定提案或倡议的每个投票会话创建唯一标识符,并且用户提交投票。程序同时使用 PDAs 进行投票会话和个别投票:
// Creating a Voting Session PDA
#[derive(Accounts)]
#[instruction(session_id: String)]
pub struct CreateVotingSession<'info> {
#[account(mut)]
pub organizer: Signer<'info>,
#[account(
init,
payer = organizer,
space = 8 + Product::SIZE,
seeds = [b"session", session_id.as_bytes()],
)]
pub voting_session: Account<'info, VotingSession>,
pub system_program: Program<'info, System>,
}
// Submitting a Vote PDA
#[derive(Accounts)]
#[instruction(session_id: String)]
pub struct SubmitVote<'info> {
#[account(mut)]
pub voter: Signer<'info>,
#[account(
init,
payer = voter,
space = 8 + Vote::SIZE,
seeds = [session_id.as_bytes(), voter.key().as_ref()]
)]
pub vote: Account<'info, Vote>,
pub system_program: Program<'info, System>,
}在这种情况下,攻击者将尝试精心制作一个投票会话,当与静态种子 "session" 结合时,会导致与另一个投票会话的 PDA 巧合。
故意创建与另一个投票会话的 PDA 相冲突的 PDA 可能会通过阻止对提案的合法投票或拒绝将新倡议添加到平台来扰乱平台的运作,因为 Solana 的运行时无法区分发生碰撞的 PDAs。
推荐的缓解措施
为了减轻种子碰撞的风险,开发人员可以:
- 在同一程序中对不同 PDA 使用唯一前缀的种子。这种方法将有助于确保 PDAs 保持不同
- 使用唯一标识符(例如时间戳、用户 ID、nonce 值)来确保每次生成唯一的 PDA
- 在程序中验证生成的 PDA 不会与现有的 PDA 发生碰撞
类型伪装
漏洞
类型伪装是一种漏洞,其中由于在反序列化期间缺乏类型检查,一个帐户类型被错误地表示为另一个帐户类型。
这可能导致未经授权的操作或数据损坏,因为程序将基于帐户的错误角色或权限假设进行操作。始终在反序列化期间明确检查帐户的预期类型。
示例场景
考虑一个管理基于用户角色的管理员操作访问权限的程序。每个用户帐户都包括一个角色判别器,用于区分普通用户和管理员。该程序包含一个用于更新仅供管理员使用的管理员设置的函数。
然而,该程序未检查帐户的判别器,并在未确认帐户是否为管理员的情况下反序列化用户帐户数据:
pub fn update_admin_settings(ctx: Context<UpdateSettings>) -> ProgramResult {
// Deserialize without checking the discriminator
let user = User::try_from_slice(&ctx.accounts.user.data.borrow()).unwrap();
// Sensitive update logic
msg!("Admin settings updated by: {}", user.authority)
Ok(())
}
#[derive(Accounts)]
pub struct UpdateSettings<'info> {
user: AccountInfo<'info>
}
#[derive(BorshSerialize, BorshDeserialize)]
pub struct User {
authority: Pubkey,
}问题在于 update_admin_settings 反序列化传入的用户帐户时未检查帐户的角色判别器,部分原因是 User 结构缺少一个判别器字段!
推荐的缓解措施
为了缓解这个问题,开发人员可以在 User 结构中引入一个判别器字段,并在反序列化过程中进行验证:
pub fn update_admin_settings(ctx: Context<UpdateSettings>) -> ProgramResult {
let user = User::try_from_slice(&ctx.accounts.user.data.borrow()).unwrap();
// Verify the user's discriminator
if user.discriminant != AccountDiscriminant::Admin {
return Err(ProgramError::InvalidAccountData.into())
}
// Sensitive update logic
msg!("Admin settings updated by: {}", user.authority)
Ok(())
}
#[derive(Accounts)]
pub struct UpdateSettings<'info> {
user: AccountInfo<'info>
}
#[derive(BorshSerialize, BorshDeserialize)]
pub struct User {
discriminant: AccountDiscriminant,
authority: Pubkey,
}
#[derive(BorshSerialize, BorshDeserialize, PartialEq)]
pub enum AccountDiscriminant {
Admin,
// Other account types
}Anchor 通过 Account<'info, T> 包装器简化了类型模仿漏洞的缓解,通过自动管理帐户时间的判别器来实现。Anchor 通过在反序列化过程中自动检查判别器来确保类型安全。这使开发人员可以更多地专注于其程序的业务逻辑,而不是手动实现各种类型检查。
结论
程序安全的重要性不言而喻。本文已经涵盖了常见漏洞的范围,从 Rust 特定错误到 Anchor 的 realloc 方法的复杂性。掌握这些漏洞以及程序安全的路径是持续的,并需要持续学习、适应和合作。
作为开发人员,我们对安全的承诺不仅仅是为了保护资产;它还涉及培养信任,确保我们应用程序的完整性,并为 Solana 的增长和稳定做出贡献。
如果你读到这里,谢谢你!请务必在下面输入你的电子邮件地址,这样你就不会错过 Solana 的最新动态。准备深入了解更多?浏览 Helius 博客上的最新文章,继续你的 Solana 之旅。





